https://zhuanlan.zhihu.com/p/568107004复制
设计一个可扩展系统(scalable system)的时候, 最重要的一点是要考虑到在多个服务器之间如何拆分(partition)数据, 还有如何复制(replicate)数据. 我们来看看这两点的具体定义:
数据拆分(data partitioning): 是一个把数据分布到一系列服务器上的过程. 这个过程可以提高系统的可扩展性, 以及提高系统的运行性能.
数据复制(data replication): 是一个把数据多次复制并保存到不同服务器的过程. 这个过程提高了数据在系统上的可获取性和可持续性.
如何进行数据拆分和数据复制是所有分布式系统的关键. 而由David Karger等人在1997年的论文上提出的一致性哈希算法, 可以有效地解决这两个问题.
论文地址:https://dl.acm.org/doi/10.1145/258533.258660
我们来看看这个一致性哈希算法怎么解决这两个问题的.
首先我们来看看怎么做数据拆分, 然后我们会看看一致性哈希怎么优化它.
做数据拆分有两个难点:
一个简单的做法就是对数据进行哈希计算, 给得到的哈希数值除以节点总数取余:
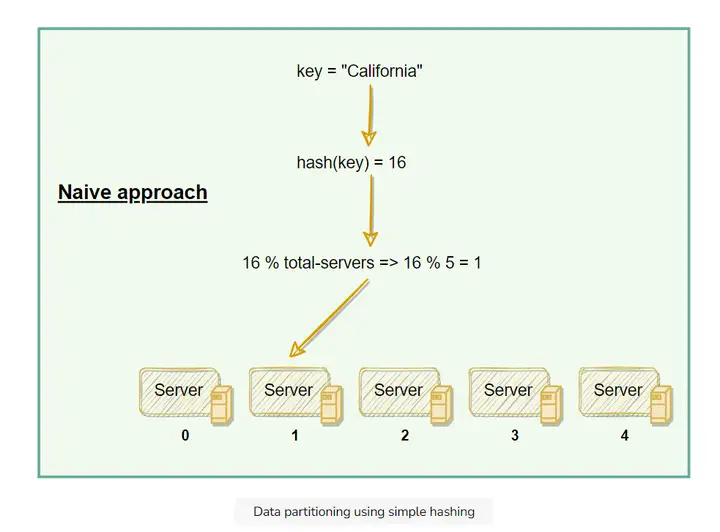
按上面的操作就可以存取数据了. 但是当我们增加/删除节点的时候, 大部分数据对节点的映射都会失效. 我们必须要根据现有的节点总数重新做一次映射. 这样就太麻烦了.
用一致性哈希算法把数据分映射到物理节点后, 当我们要增加/减少节点的时候, 它能保证只移动一小部分的数据.
一致性哈希的操作方法是把所有节点组成一个环(ring). 环上的每个节点接收一个区间的数据:
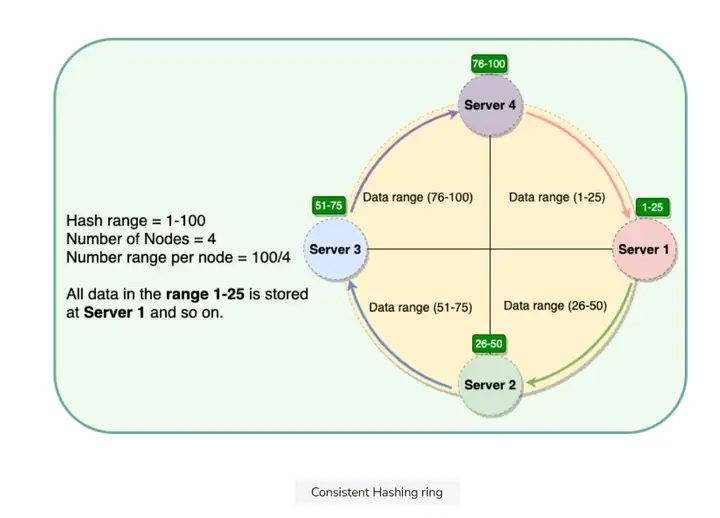
比如上图中在1-25区间的数据都可以存在节点1(服务器1).
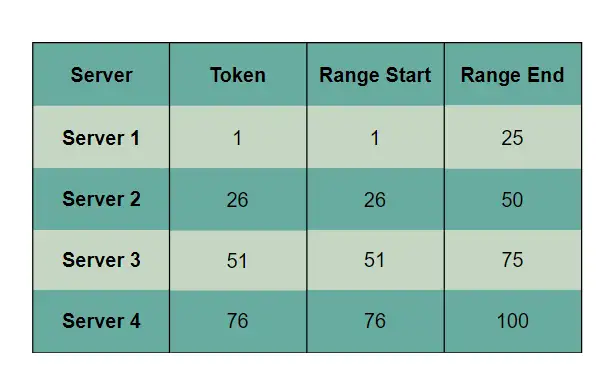
这些区间的起始点的数值叫"token". 每个节点都会有一个token值, 这样每个区间的范围就是[token, 下一个token-1], 上面那4个节点的token也就是1, 26, 51, 76. 范围如下:
每次我们在这个分布式系统上读写数据的时候, 我们先获得数据MD5哈希值. 通过哈希值我们就可以把数据分配到环上的一个节点:
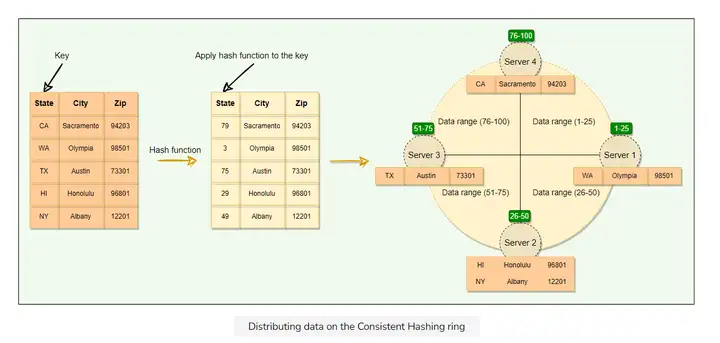
当我们添加/删除一个节点的时候, 一致性哈希算法会保证只有这个节点的下一个节点会受到影响.
比如我们删除一个节点, 它的下一个节点会接受它所有的数据. 显然这样也是会有问题的, 下一个节点岂不是要负责双倍的数据?
这就会导致不均衡的数据分配(non-uniform data and load distribution). 我们再看看这样的基础方案还会有什么问题.
基础方案是每个物理节点(服务器)负责一个数据区间(也就是一个token), 会出现的问题如下:
要解决上述问题, 一致性哈希引入了虚拟节点(virtual nodes, Vnodes)的概念.
在此之前我们是给每一个物理节点一个token(也就是存这一段哈希范围内的数据). 引入虚拟节点之后, 我们给每一个物理节点划分出很多虚拟节点, 负责很多token(负责很多段哈希范围内的数据). 如下图所示, 每一种颜色代表一段哈希范围, 之前一段范围内的数据储存在一个物理节点, 用了虚拟节点之后就均匀分散到不同物理节点去了.
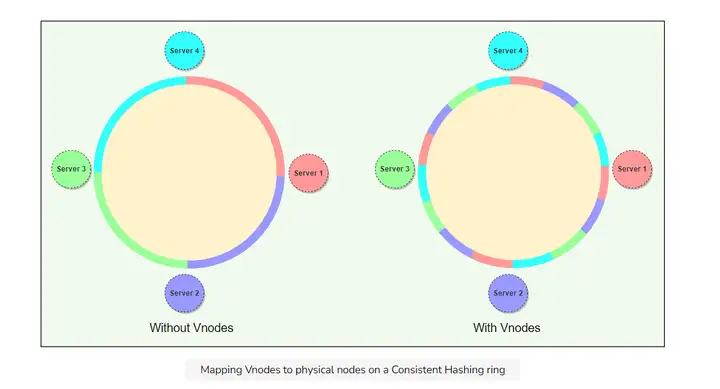
(我自己的疑问:那我们又要记每个小段具体在哪个物理节点? 否则每次搜索的时候都不知道到底在哪个物理节点? 答案可能就直接暴力搜索了, 轮询物理节点, 可能这样的开销不算大)
还有一些别的细节:
下图展示了物理节点A, B, C, D, E上的虚拟节点1-16组成的环. 每一个虚拟节点都被复制了一次存放在另一个物理节点.
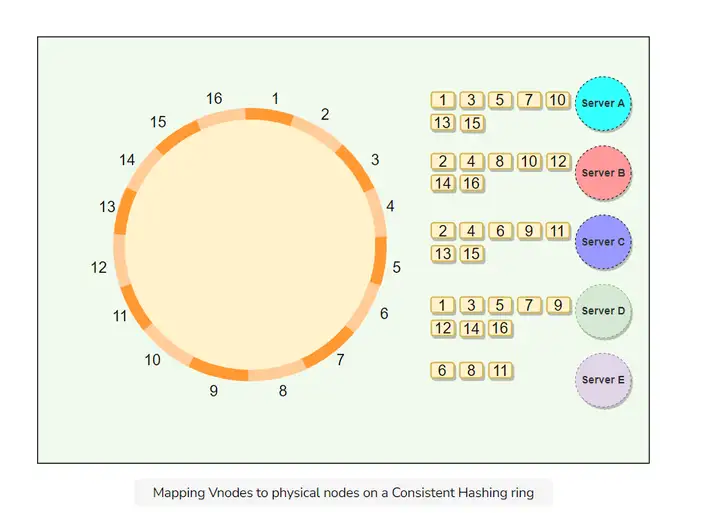
先来一些术语:
复制因子(replication factor): 是同样的数据被复制的次数, 复制因子是2的话就是同样的数据被复制/备份了1次, 也就是总共2份数据, 储存在不同的节点.
最终一致性(eventually consistent): 在这种系统里, 数据的备份不总是和原数据同步一致的, 但会保证最终同步完成, 也就是最终一致.
在我们保存数据的时候, 数据的哈希值落入环上哈希范围所指向的第一个虚拟节点, 该数据就会被保存在这个节点的物理节点/服务器上. 然后数据的备份就会被保存到顺时针的下N个节点(N=复制因子-1). 在最终一致的系统上, 数据的备份过程是在背后异步完成的.
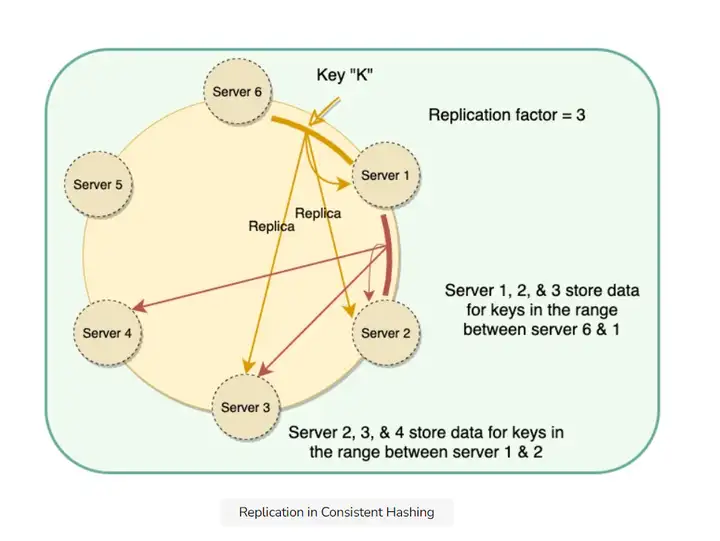
看下图案例:
复制因子是3, 所以会有两个备份操作. K数据经过计算被保存在了物理服务器1上, 它的备份分别就会在顺时针的2和3保存.
同理被保存在服务器2上的数据会被备份到3和4.
系统设计面试的时候, 如果在以下情况, 可以用一致性哈希:
实际案例: 亚马逊的Dynamo, Apache的Cassandra都用到了一致性哈希在不同节点分布和备份数据.