https://zhuanlan.zhihu.com/p/569553681复制
最近在看一些系统设计相关的知识, 按我自己的理解做些翻译和整理, 和原文不一样, 有问题欢迎指出, 细节以原文为主:
https://www.educative.io/courses/grokking-the-system-design-interview/3j6NnJrpp5p
这篇原文其实也没什么知识结构, 就是一些杂记.
其他一些资料参考自这个文章:
https://www.51cto.com/article/713035.html
缓存的思想是, 最近使用的数据很可能再次被使用. 缓存就像短期记忆, 虽然空间有限, 但通常比直接从数据源获取数据更快.
计算机的各个层面(硬件, 操作系统, 浏览器, 网页应用, 等等)都有用到缓存. 一般来说缓存都是在接近前端的位置使用, 就是储存常用的数据避免多次询问上游数据源.
如之前的负载均衡那边文章所说, 应用服务器(application server)是处于下图所在的位置:
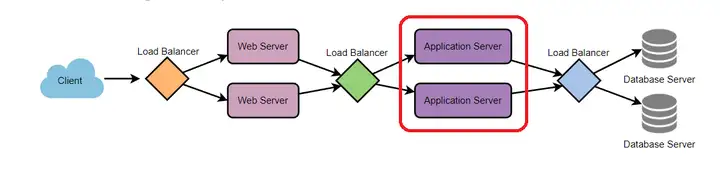
用户请求的数据缓存可以存于内存里, 这样就可以快速访问, 或者也可以存于硬盘里, 至少比从数据上游(图例里是从数据库服务器)重新获取数据要快.
但有一个问题就是, 在有多个节点(服务器)的情况下, 某个用户数据的缓存可能存在任意一个服务器节点, 但之后的用户请求又被随机发送到另一个服务器节点, 之前的缓存就浪费了.
所以之前文章说的负载均衡算法之一IP哈希(IP Hash)在这种情况挺有用的, 某个用户的请求只会被发送到特定服务器节点, 对应的数据缓存就可以再次被用到了.
另外还有两种方法:
内容分发网络(CDN)主要用于分发静态媒体数据(音乐, 图片, 视频, 应用程序). 同理CDN也就是一个缓存, 用户请求的时候, 如果本地有就直接从本地获取数据, 否则它会向后端获取数据再缓存.
如果我们建立的系统还不够大, 不需要CDN, 我们可以把静态媒体放于一个子域名下(比如http://static.yourservice.com), 然后用一个轻量级HTTP服务器比如Nginx, 之后再把这个子域名DNS转成CDN就好.
当数据源更新后, 它对应的缓存就应该失效. 而主要的应对措施有三种:
这种方式下, 数据同时被写入缓存和数据库. 这样可以快速读取缓存数据, 并且因为同样的数据也被永久储存(写入数据库), 缓存和永久储存的数据就有一致性.
同时这种方式保证服务器崩溃, 停电, 或者其他事故发生时数据不会丢失(比如暂时存于缓存的话, 缓存服务器崩了数据就丢失了)
和write-through cache类似, 但是数据先直接写进永久储存(数据库), 不写进缓存. 这可以避免大量数据涌入缓存但最后又不会被用到.
但这个问题是, 最近写入的数据不会被保存到缓存, 之后又马上要被用的时候就会出现"缓存丢失(cache miss)", 需要重新从后端读数据, 这样延迟会比较高.
这种方式是先写进缓存, 写完后立刻通知客户. 在之后特定时段或者特定条件下, 数据才会被写入永久储存(数据库).
这样的好处是低延迟, 高吞吐, 对于需要大量写入的应用比较友好.
但是这样的风险是在服务器崩溃或者其他事故时数据可能会丢失(没来得及永久储存).
这种方式是任何情况都直接写进永久储存(数据库), 如果缓存有数据, 就直接删除缓存的数据. 当某数据再次被请求的时候, 重新从数据库读取数据存到缓存. 这种方式适用于读多写少的情况, 比如用户信息、新闻报道等,一旦写入缓存,几乎不会进行修改。该模式的缺点是可能会出现缓存和数据库双写不一致的情况。
因为缓存的空间有限, 当缓存满了的时候总是会需要删除一些数据. 下面是一些删除方式: