https://zhuanlan.zhihu.com/p/387117470复制
在2010年前后MySQL、PG、Oracle数据库在使用NUMA的时候碰到了性能问题,流传最广的这篇 MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture 描述了性能问题的原因(文章中把原因找错了)以及解决方案:关闭NUMA。 实际这个原因是kernel实现的一个低级bug,这个Bug在2014年修复了,但是修复这么多年后仍然以讹传讹,这篇文章希望正本清源、扭转错误的认识。
最近在做一次性能测试的时候发现MySQL实例有一个奇怪现象,在128core的物理机上运行三个MySQL实例,每个实例分别绑定32个物理core,绑定顺序就是第一个0-31、第二个32-63、第三个64-95,实际运行结果让人大跌眼镜,如下图
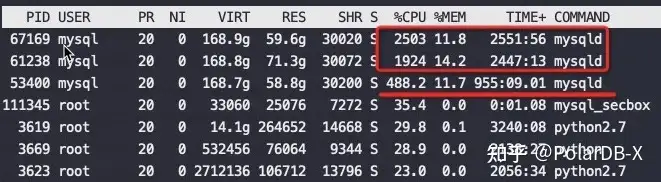
从CPU消耗来看差异巨大,高的实例CPU用到了2500%,低的才488%,差了5倍。但是神奇的是他们的QPS一样,执行的SQL也是一样
如下图,所有MySQL实例流量一样:
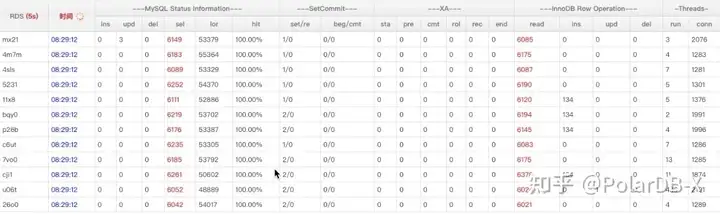
那么为什么在同样的机器上、同样的流量下CPU使用率差了这么多? 换句话来问就是CPU使用率高就有效率吗?
这台物理机CPU 信息:
#lscpu
Architecture: aarch64
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 1
Model: 3
BogoMIPS: 100.00
L1d cache: 32K
L1i cache: 32K
L2 cache: 2048K
L3 cache: 65536K
NUMA node0 CPU(s): 0-127
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid复制关于cpu为什么高但是没有产出的原因是因为CPU流水线长期stall,导致很低的IPC,所以性能自然上不去,可以看这篇文章 。
先来看看这两个MySQL 进程的Perf数据:
#第二个RDS IPC只有第三个的30%多点,这就是为什么CPU高这么多,但是QPS差不多
perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,iTLB-load-misses -a -p 61238
^C
Performance counter stats for process id '61238':
86,491,052 branch-misses (58.55%)
98,481,418,793 bus-cycles (55.64%)
113,095,618 cache-misses # 6.169 % of all cache refs (53.20%)
1,833,344,484 cache-references (52.00%)
101,516,165,898 cpu-cycles (57.09%)
4,229,190,014 instructions # 0.04 insns per cycle (55.91%)
111,780,025 L1-dcache-load-misses # 6.34% of all L1-dcache hits (55.40%)
1,764,421,570 L1-dcache-loads (52.62%)
112,261,128 L1-dcache-store-misses (49.34%)
1,814,998,338 L1-dcache-stores (48.51%)
219,372,119 L1-icache-load-misses (49.56%)
2,816,279,627 L1-icache-loads (49.15%)
85,321,093 branch-load-misses (50.38%)
1,038,572,653 branch-loads (50.65%)
45,166,831 dTLB-load-misses (51.98%)
29,892,473 iTLB-load-misses (52.56%)
1.163750756 seconds time elapsed
#第三个RDS
perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,iTLB-load-misses -a -p 53400
^C
Performance counter stats for process id '53400':
295,575,513 branch-misses (40.51%)
110,934,600,206 bus-cycles (39.30%)
537,938,496 cache-misses # 8.310 % of all cache refs (38.99%)
6,473,688,885 cache-references (39.80%)
110,540,950,757 cpu-cycles (46.10%)
14,766,013,708 instructions # 0.14 insns per cycle (46.85%)
538,521,226 L1-dcache-load-misses # 8.36% of all L1-dcache hits (48.00%)
6,440,728,959 L1-dcache-loads (46.69%)
533,693,357 L1-dcache-store-misses (45.91%)
6,413,111,024 L1-dcache-stores (44.92%)
673,725,952 L1-icache-load-misses (42.76%)
9,216,663,639 L1-icache-loads (38.27%)
299,202,001 branch-load-misses (37.62%)
3,285,957,082 branch-loads (36.10%)
149,348,740 dTLB-load-misses (35.20%)
102,444,469 iTLB-load-misses (34.78%)
8.080841166 seconds time elapsed复制从上面可以看到这两个承担了同样流量的进程的 IPC 差异巨大: 0.04 VS 0.14 ,也就是第一个MySQL的CPU效率很低,我们看到的CPU running实际是CPU在等待(stall)。
找到同一个机型,但是NUMA开着的查了一下:
#lscpu
Architecture: aarch64
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 16
Model: 3
BogoMIPS: 100.00
L1d cache: 32K
L1i cache: 32K
L2 cache: 2048K
L3 cache: 65536K
NUMA node0 CPU(s): 0-7
NUMA node1 CPU(s): 8-15
NUMA node2 CPU(s): 16-23
NUMA node3 CPU(s): 24-31
NUMA node4 CPU(s): 32-39
NUMA node5 CPU(s): 40-47
NUMA node6 CPU(s): 48-55
NUMA node7 CPU(s): 56-63
NUMA node8 CPU(s): 64-71
NUMA node9 CPU(s): 72-79
NUMA node10 CPU(s): 80-87
NUMA node11 CPU(s): 88-95
NUMA node12 CPU(s): 96-103
NUMA node13 CPU(s): 104-111
NUMA node14 CPU(s): 112-119
NUMA node15 CPU(s): 120-127
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid复制这告诉我们实际上这个机器有16个NUMA,跨NUMA访问内存肯定比访问本NUMA内的要慢很多。但是测试机器把NUMA关了,所以看不见NUMA结构默认没有发现这个问题。
如下图,是一个Intel Xeon E5 CPU的架构信息,左右两边的大红框分别是两个NUMA,每个NUMA的core访问直接插在自己红环上的内存必然很快,如果访问插在其它NUMA上的内存还要走两个红环之间上下的黑色箭头线路,所以要慢很多。
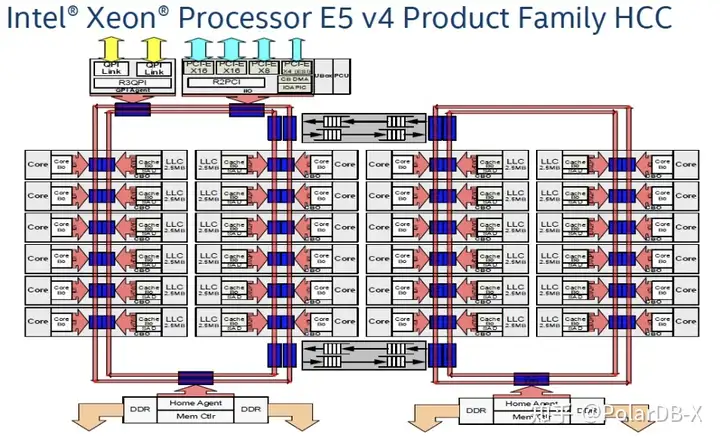
实际测试Intel的E5-2682和8269的CPU跨Socket(这两块CPU内部不再是上图的红环Bus,而是改用了Mesh Bus一个Die就是一个NUMA,服务器有两路,也就是一个Socket就是一个NUMA),测试数据表明跨NUMA访问内存的延迟是本Node延迟的将近2倍。测试工具
//E5-2682
Intel(R) Memory Latency Checker - v3.9
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1
0 85.0 136.3
1 137.2 84.2
//8269
Intel(R) Memory Latency Checker - v3.9
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1
0 78.6 144.1
1 144.7 78.5复制开启NUMA会优先就近使用内存,在本NUMA上的内存不够的时候可以选择回收本地的PageCache还是到其它NUMA 上分配内存,这是可以通过Linux参数 zone_reclaim_mode 来配置的,默认是到其它NUMA上分配内存,也就是跟关闭NUMA是一样的。
这个架构距离是物理上就存在的不是你在BIOS里关闭了NUMA差异就消除了,我更愿意认为在BIOS里关掉NUMA只是掩耳盗铃。
以上理论告诉我们:也就是在开启NUMA和 zone_reclaim_mode 默认在内存不够的如果去其它NUMA上分配内存,比关闭NUMA要快很多而没有任何害处。
对如下Intel CPU进行一些测试,在开启NUMA的情况下
#lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
Stepping: 1
CPU MHz: 2500.000
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 5000.06
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 40960K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch ida arat epb invpcid_single pln pts dtherm spec_ctrl ibpb_support tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt rdseed adx smap xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local cat_l3
#numastat
node0 node1
numa_hit 129600200 60501102
numa_miss 0 0
numa_foreign 0 0
interleave_hit 108648 108429
local_node 129576548 60395061
other_node 23652 106041复制我在这个64core的物理机上运行一个MySQL 实例,先后将MySQL进程绑定在0-63 core,0-31 core,0-15,32-47 core以及0-15 core上,然后进行sysbench测试对一亿条记录跑点查对比,数据都加载到内存中了。
测试结果2、3的截图数据:
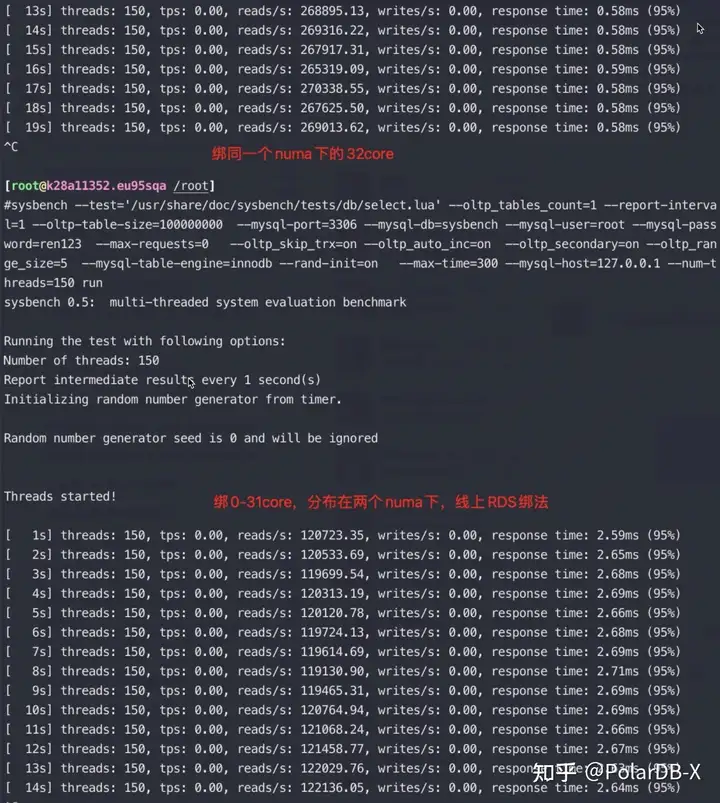
从这个数据看起来即使Intel在只有两个NUMA的情况下跨性能差异也有2倍,可见正确的绑核方法收益巨大,尤其是在刷榜的情况下, NUMA更多性能差异应该会更大。
实际在不开NUMA的同样CPU上,进行以上绑核测试测试,测试结果也完全一样。 测试数据说明了前面的理论分析是正确的。
原来是10年前几乎所有的运维都会多多少少被NUMA坑害过:
最有名的是这篇 MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture(以下简称为2010年的文章)
我总结下这篇2010年的文章的核心观点是:
所以2010年的文章给出的解决方案就是(三选一):
这就是这么多人在上面栽了跟头,所以干脆一不做二不休干脆关了NUMA 一了百了。
但真的NUMA有这么糟糕?或者说Linux Kernel有这么笨,默认优先去回收PageCache吗?
实际我们使用NUMA的时候期望是:优先使用本NUMA上的内存,如果本NUMA不够了不要优先回收PageCache而是优先使用其它NUMA上的内存。
事实上Linux识别到NUMA架构后,默认的内存分配方案就是:优先尝试在请求线程当前所处的CPU的Local内存上分配空间。如果local内存不足,优先淘汰local内存中无用的Page(Inactive,Unmapped)。然后才到其它NUMA上分配内存。
zone_reclaim_mode,它用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项:
Zone_reclaim_mode allows someone to set more or less aggressive approaches to reclaim memory when a zone runs out of memory. If it is set to zero then no zone reclaim occurs. Allocations will be satisfied from other zones / nodes in the system.
zone_reclaim_mode的四个参数值的意义分别是:
0 = Allocate from all nodes before reclaiming memory
1 = Reclaim memory from local node vs allocating from next node
2 = Zone reclaim writes dirty pages out
4 = Zone reclaim swaps pages
找台Linux服务器看看zone_reclaim_mode的值:
# cat /proc/sys/vm/zone_reclaim_mode
0复制我查了2.6.32以及4.19.91内核的机器 zone_reclaim_mode 都是默认0,也就是kernel会:优先使用本NUMA上的内存,如果本NUMA不够了不要优先回收PageCache而是优先使用其它NUMA上的内存。这也是我们想要的。
Kernel文档也告诉大家默认就是0,但是为什么会出现优先回收了PageCache呢?
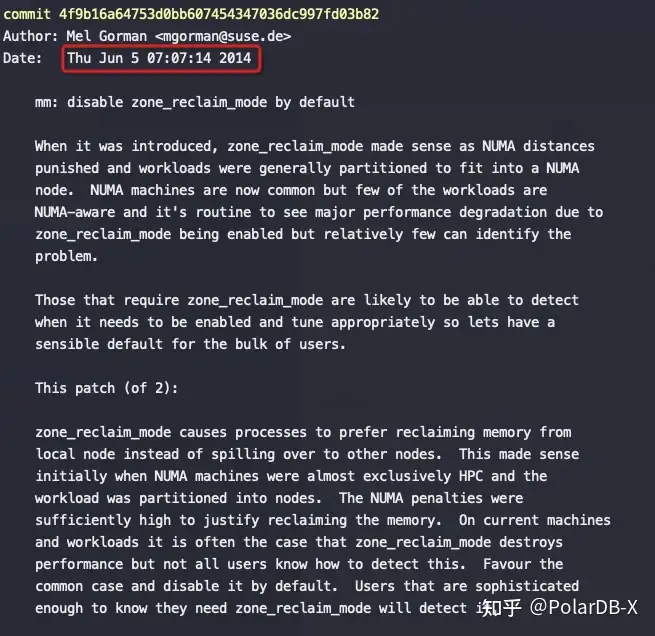
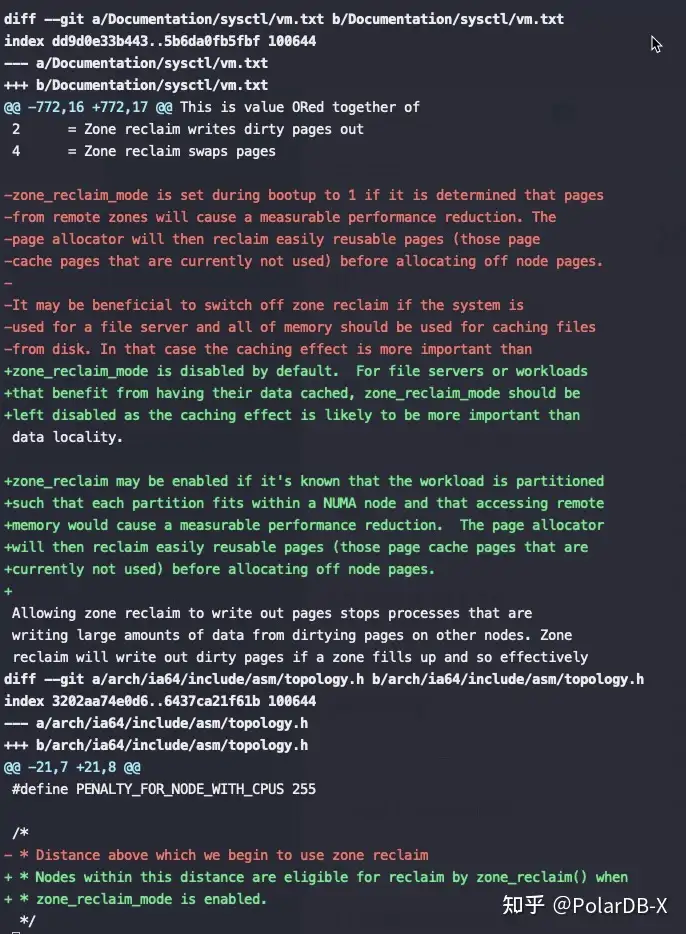
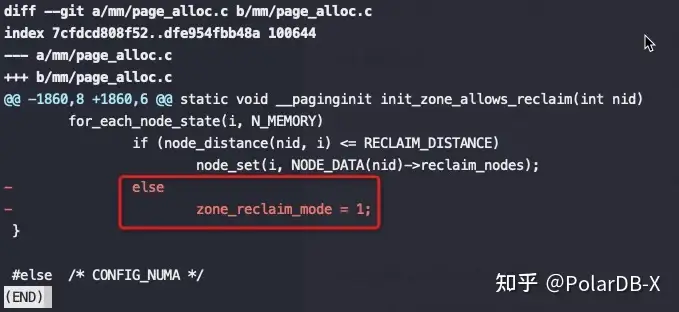
关键是上图红框中的代码,node distance比较大(也就是开启了NUMA的话),强制将 zone_reclaim_mode设为1,这是2014年提交的代码,将这个强制设为1的逻辑去掉了。
这也就是为什么之前大佬们碰到NUMA问题后尝试修改 zone_reclaim_mode 没有效果,也就是2014年前只要开启了NUMA就强制线回收PageCache,即使设置zone_reclaim_mode也没有意义,真是个可怕的Bug。
内核版本:3.10.0-327.ali2017.alios7.x86_64
先将一个160G的文件加载到内存里,然后再用代码分配64G的内存出来使用。
单个NUMA node的内存为256G,本身用掉了60G,加上这次的160G的PageCache,和之前的一些其他PageCache,总的 PageCache用了179G,那么这个node总内存还剩256G-60G-179G,
如果这个时候再分配64G内存的话,本node肯定不够了,我们来看在 zone_reclaim_mode=0 的时候是优先回收PageCache还是分配了到另外一个NUMA node(另外的这个NUMA node 有240G以上的内存空闲)
分配64G内存
# taskset -c 0 ./alloc 64
To allocate 64GB memory
Used time: 39 seconds复制观察内存分配使用情况:
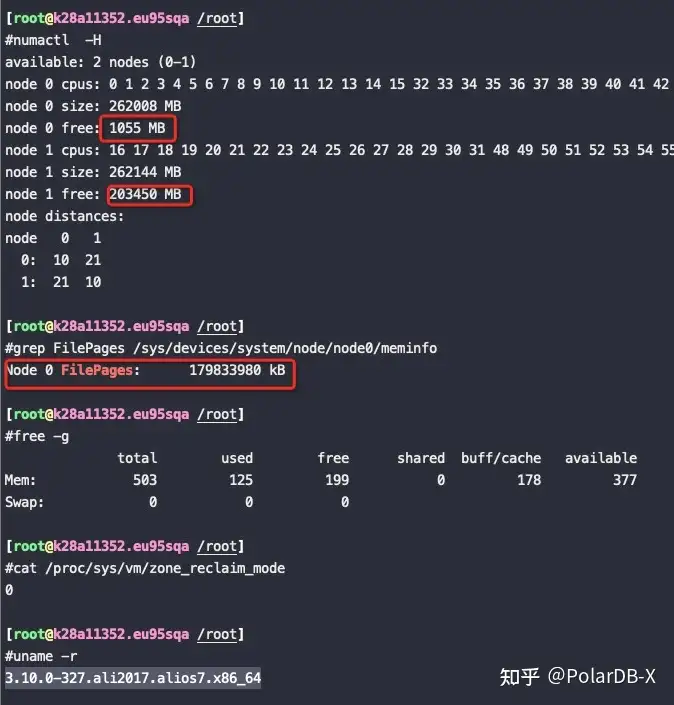
从如上截图来看,在分配64G内存的时候即使node0不够了也没有回收node0上的PageCache,而是将内存跨NUMA分配到了node1上,符合预期!
释放这64G内存后,如下图可以看到node0回收了25G,剩下的39G都是在node1上:
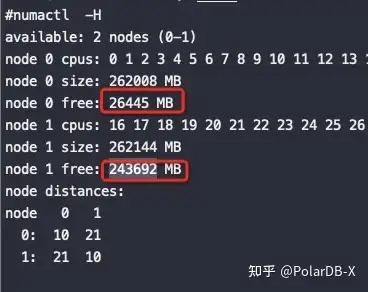
可以看到zone_reclaim_mode 改成 1,node0内存不够了也没有分配node1上的内存,而是从PageCache回收了40G内存,整个分配64G内存的过程也比不回收PageCache慢了12秒,这12秒就是额外的卡顿
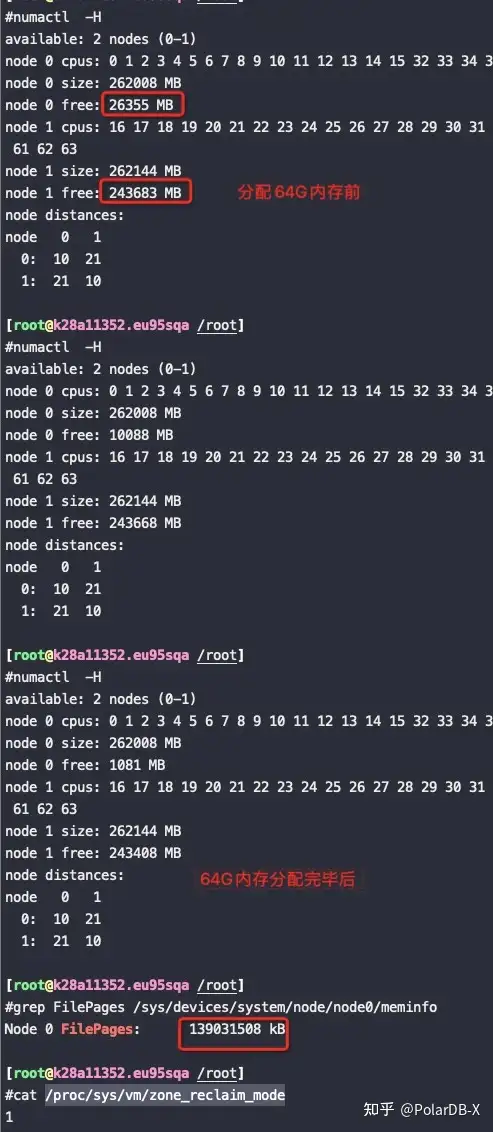
测试结论:从这个测试可以看到NUMA 在内存使用上不会优先回收 PageCache 了
从5.7开始,mysql增加了对NUMA的感知:innodb_numa_interleave
当开启了 innodb_numa_interleave 的话在为innodb buffer pool分配内存的时候将 NUMA memory policy 设置为 MPOL_INTERLEAVE 分配完后再设置回 MPOL_DEFAULT(OS默认内存分配行为,也就是zone_reclaim_mode指定的行为)。
innodb_numa_interleave参数是为innodb更精细化地分配innodb buffer pool 而增加的。很典型地innodb_numa_interleave为on只是更好地规避了前面所说的zone_reclaim_mode的kernel bug,kernel bug修复后这个参数没有意义了。
补充下,从评论来看,最容易误解的就是:如果关闭NUMA,就变成UMA了。这里大家首先要理解NUMA的引入是CPU核越来越多,内存条数也越来越多(总内存是由很多条一起组合起来的),这样带来的问题就是一部分内存插在一部分core上,另外一些内存插在剩下的core上,从而导致了core访问不同的内存物理距离不一样,所以RT也不一样,这个物理距离是设计CPU的时候就带来了的,无法改变!
那么BIOS层面关闭NUMA的意思是什么呢?关闭后OS无法感知CPU的物理架构,也就是没有办法就近分配内存,带来的问题就是没法让性能最优,或者用户能感知到RT上的抖动(如果是2个NUMA节点的话,平均会有50%的RT偏高)