https://zhuanlan.zhihu.com/p/448261354复制
陈巍谈芯:
12月3日,阿里达摩院成功研发新型架构芯片,已经被证明能够在阿里推荐系统中发挥极大的应用价值,并受到技术圈的普遍关注。
据悉这颗芯片与数据中心的推荐系统对于带宽/存储的需求完美匹配,大幅提升带宽的同时还实现了超低功耗,充分展示了存算技术(第一代仅是近存计算)在数据中心场景的潜力。

让我们根据达摩院成员已公开的技术信息,来大胆解读这颗芯片的新科技。
据悉,该工作将发表在2022年ISSCC的Session 29的第一篇,堪称Session 29的扛鼎之作。需要说明的是,ISSCC( International Solid-State Circuits Conference)被业界视为芯片设计界的奥林匹克运动会,是芯片设计圈的顶级盛会。
根据该论文的信息,我们可以看到,这款存算芯片的设计合作方包括北美Sunnyvale、北京、上海三地的达摩院和西安紫光国芯。幕后大佬包括了达摩院的谢源教授和紫光国芯的CEO任奇伟。
该存算芯片的吞吐率能效达到184QPS/W,单位面积存储密度为64Mb/mm^2,使用了基于3D混合键合(3D Hybrid Bonding)近存计算技术,将逻辑单元与DRAM单元键合在一起。
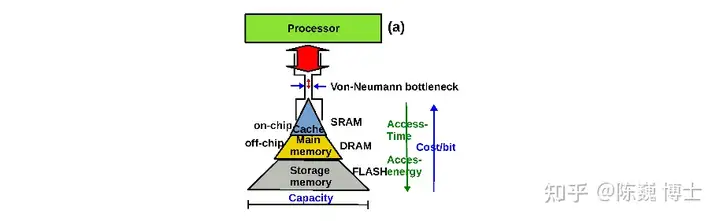
“冯·诺伊曼架构存储和计算分离的模型,已无法满足人工智能应用的需求,计算存储一体化将突破AI算力瓶颈。”这是达摩院判断的2020十大科技趋势中的技术趋势之一。
AI技术的快速发展,使得算力需求呈爆炸式增长。虽然多核(例如CPU)/众核(例如GPU)并行加速技术也能提升算力,但在后摩尔时代,存储带宽制约了计算系统的有效带宽,芯片算力增长步履维艰。
巨大的算力需求与实际算力有限增长之间的矛盾,将问题根源指向了冯·诺依曼架构存算分离的局限性。由于计算与存储分离,在计算的过程中就需要不断通过总线交换数据,将数据从内存读进CPU,计算完成后再写回存储。这一运转方式让冯·诺依曼架构无法适应新型计算的大算力需求。
分析显示,数据从内存传输到计算单元需要的功耗大约是计算本身的200倍,真正用于计算的时间和功耗占比大大降低。
为了从根本上解决冯·诺依曼架构瓶颈,就必须使用将计算和存储合二为一的存算技术。
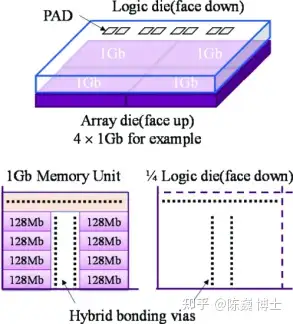
达摩院存算芯片的内存单元采用了异质集成嵌入式DRAM(SeDRAM),拥有超大带宽、超大容量等特点,片上内存带宽可高达 37.5GB/s/mm^2。
达摩院存算芯片所使用的SeDRAM 就是堆叠嵌入式DRAM(Stacked Embedded DRAM)。
在以往的HBM 使用硅中介层(interposer)和微凸块(microbump)来增加逻辑到内存接口的 I/O 连接数量,以在高数据速率下提供高带宽。然而,进一步提高每引脚数据速率需要 HBM 和复杂且耗电的 PHY 电路。而且TSV 和中介层连接具有较大的电阻和电容,从而导致高功耗。
在基于SeDRAM的存算芯片中,AI电路和外围电路,包括控制、I/O 和 DFT,被分立到一个逻辑芯片,并通过混合键合堆叠在存储阵列芯片上方,混合键合使用 Cu 到 Cu 直接熔合键合。DFT 模块则被设计为逻辑芯片中的 IP,用于为阵列芯片执行 BISR(内置自修复)。
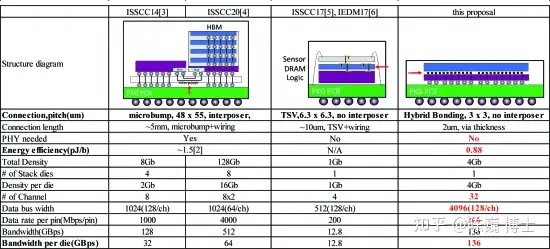
作为线路后端 (BEOL) 互连工艺的延伸,混合键合比微凸块和 TSV 的寄生电容小很多。因此,逻辑到存储器接口的功耗也可以降低 40%。
混合键合的PIN间距尺寸为3um,相反,microbump的间距约为50um ,TSV的间距约为6um。与使用微凸块和 TSV 技术的 HBM 相比,使用混合键合技术的 SeDRAM 可以达到 110,000/mm^2的最大通孔密度
仅就带宽而言,基于混合键合技术的SeDRAM比HBM效率更高。
当然,我们也看到,达摩院的这颗芯片仅仅是使用了近存计算技术,就已经获得了显著的性能,如果使用更先进的存算技术,则会产生更大的技术跃迁。
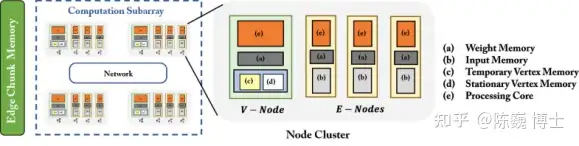
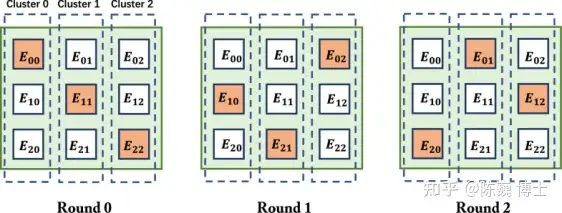
数据流架构是这颗芯片的另一个特色。
达摩院研发设计了基于数据流的定制化加速器架构,对推荐系统端到端进行加速,包括匹配、粗排序、神经网络计算、细排序等任务。
如数据流架构图所示,节点(Node Cluster)是构建整个架构的基本模块,每个检点的微架构包括多个存储块和一个处理核心。(例如权重存储和输入数据存储)
底层电路结构采用了同构设计,所有节点都可以灵活配置,每个节点有点像多处理器片上系统。
整个计算流程分为多轮(Round)。一轮可以进一步分为两个子轮。在计算子轮期间,存储在其本地缓冲区中的输入特征和神经权重被传送到处理数组中以进行计算。在每个通信子轮中,节点转发其输出特征,簇(Cluster)之间以循环方式交换存储的数据。
通过这种近存计算(基于SeDRAM)和数据流架构的耦合,可以大大减少访问外部内存的次数,提升整体计算能效和性能。
以搜索推荐为例,这一场景对内存带宽、功耗、时延等方面有很高的要求,如果用传统计算来实现,系统性能不易提高,但用存算的方式就能解决这些问题,同时降低成本。在实际推荐系统应用中,该芯片相对于传统CPU计算系统可以达到10倍以上性能提升和300倍的能效提升。
目前存算技术在按照以下路线在演进:
查存计算(Processing With Memory):GPU中对于复杂函数就采用了这种计算方法,是早已落地多年的技术。存储芯片内部的存储单元完成查表计算操作,存储单元和计算单元完全融合,没有一个独立的计算单元。
近存计算(Computing Near Memory):典型代表包括AMD的Zen系列CPU和达摩院本次发表的存算芯片。计算操作由位于存储区域外部的独立计算芯片/模块完成。这种架构设计的代际设计成本较低,适合传统架构芯片转入。
存内计算(Computing In Memory):典型代表是Mythic、闪忆、知存、九天睿芯。计算操作由位于存储芯片/区域内部的独立计算单元完成,存储和计算可以是模拟的也可以是数字的。这种路线适合算法固定的场景算法计算,目前主要用于语音等轻算力场景。
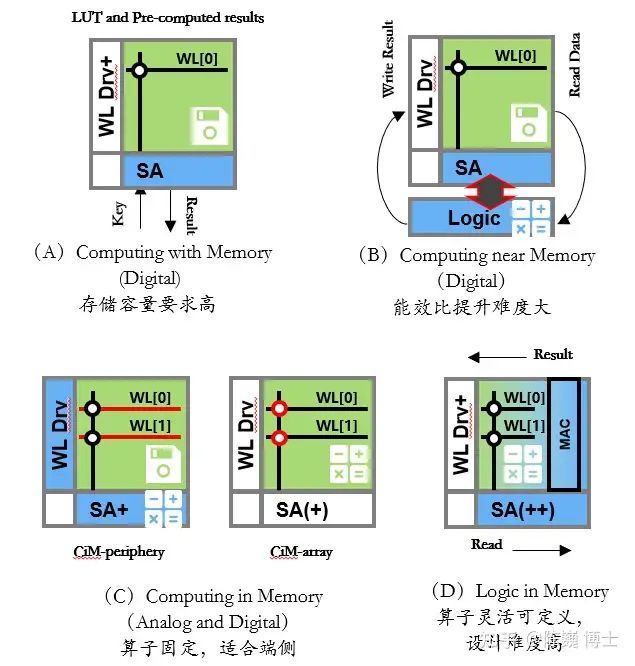
逻辑存储(Logic In Memory):通过在内部存储中添加计算逻辑,直接在内部存储执行数据计算,这种架构数据传输路径最短,同时能满足大模型的计算精度要求。典型代表包括TSMC(在2021 ISSCC发表)和千芯。
在达摩院前期的测试中,这颗存算芯片(目前还仅是近存计算)已经被证明能够在阿里推荐系统中发挥极大的应用价值。
可以看到,由于存算技术本身的高能效和大算力特点,可以打破传统计算架构的“存储墙”问题。
这次近存架构在数据中心推荐系统中的应用还只是小试牛刀。存算技术在海量数据计算场景中拥有天然的优势,将在云计算、自动驾驶、元宇宙等场景拥有广阔的发展空间。