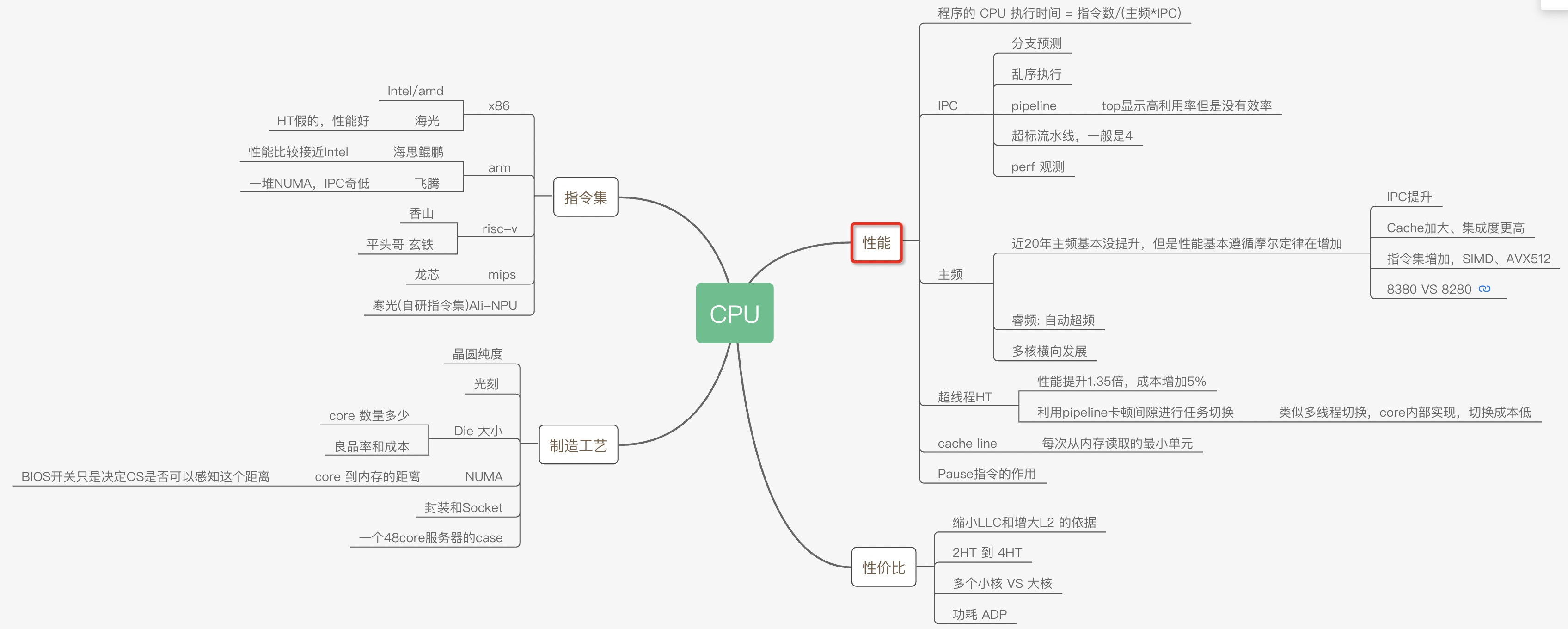
Perf IPC以及CPU性能
为了让程序能快点,特意了解了CPU的各种原理,比如多核、超线程、NUMA、睿频、功耗、GPU、大小核再到分支预测、cache_line失效、加锁代价、IPC等各种指标(都有对应的代码和测试数据)都会在这系列文章中得到答案。当然一定会有程序员最关心的分支预测案例、Disruptor无锁案例、cache_line伪共享案例等等。
这次让我们从最底层的沙子开始用8篇文章来回答各种疑问以及大量的实验对比案例和测试数据。
大的方面主要是从这几个疑问来写这些文章:
- 同样程序为什么CPU跑到800%还不如CPU跑到200%快?
- IPC背后的原理和和程序效率的关系?
- 为什么数据库领域都爱把NUMA关了,这对吗?
- 几个国产芯片的性能到底怎么样?
系列文章
Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的
程序性能
程序的 CPU 执行时间 = 指令数/(主频*IPC)
IPC: insns per cycle insn/cycles
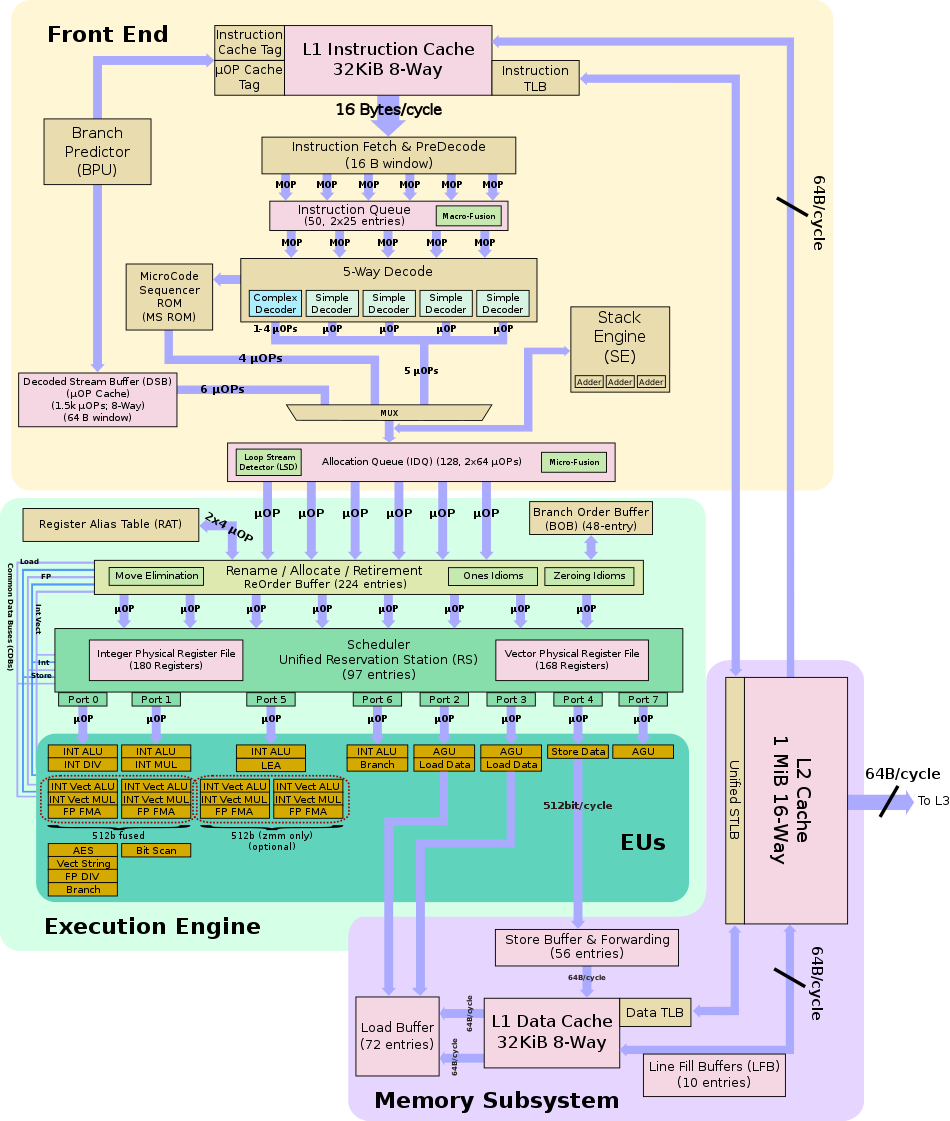
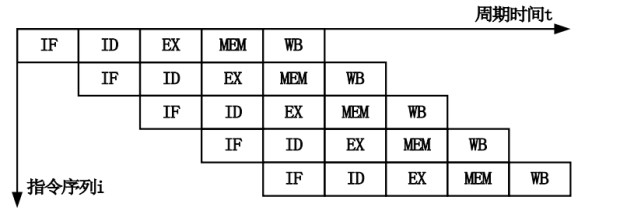
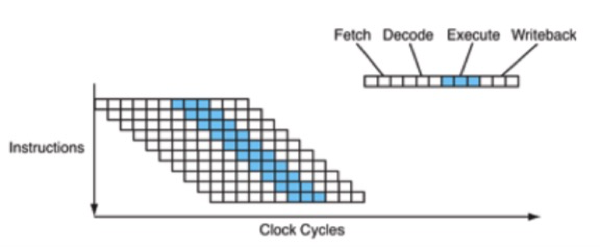
CPU 流水线工作原理
cycles:CPU时钟周期。CPU从它的指令集(instruction set)中选择指令执行。
一个指令包含以下的步骤,每个步骤由CPU的一个叫做功能单元(functional unit)的组件来进行处理,每个步骤的执行都至少需要花费一个时钟周期。
- 指令读取(instruction fetch, IF)
- 指令解码(instruction decode, ID)
- 执行(execute, EXE)
- 内存访问(memory access,MEM)
- 寄存器回写(register write-back, WB)
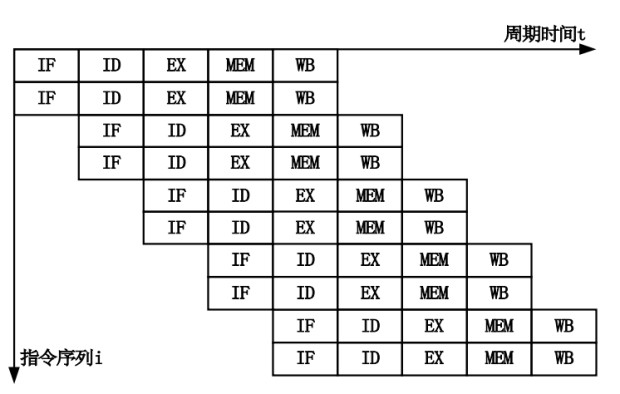
以上结构简化成流水线就是:

IF/ID 就是我们常说的前端,他负责不停地取指和译指,然后为后端提供译指之后的指令,最核心的优化就是要做好分支预测,终归取指是要比执行慢,只有提前做好预测才能尽量匹配上后端。后端核心优化是要做好执行单元的并发量,以及乱序执行能力,最终要将乱序执行结果正确组合并输出。
在流水线指令之前是单周期处理器:也就是一个周期完成一条指令。每个时钟周期必须完成取指、译码、读寄存器、 执行、访存等很多组合逻辑工作,为了保证在下一个时钟上升沿到来之前准备好寄存器堆的写数 据,需要将每个时钟周期的间隔拉长,导致处理器的主频无法提高。
使用流水线技术可以提高处 理器的主频。五个步骤只能串行,但是可以做成pipeline提升效率,也就是第一个指令做第二步的时候,指令读取单元可以去读取下一个指令了,如果有一个指令慢就会造成stall,也就是pipeline有地方卡壳了。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
$sudo perf stat -a -- sleep 10
Performance counter stats for 'system wide':
239866.330098 task-clock (msec) # 23.985 CPUs utilized /10*1000 (100.00%)
45,709 context-switches # 0.191 K/sec (100.00%)
1,715 cpu-migrations # 0.007 K/sec (100.00%)
79,586 page-faults # 0.332 K/sec
3,488,525,170 cycles # 0.015 GHz (83.34%)
9,708,140,897 stalled-cycles-frontend # 278.29% /cycles frontend cycles idle (83.34%)
9,314,891,615 stalled-cycles-backend # 267.02% /cycles backend cycles idle (66.68%)
2,292,955,367 instructions # 0.66 insns per cycle insn/cycles
# 4.23 stalled cycles per insn stalled-cycles-frontend/insn (83.34%)
447,584,805 branches # 1.866 M/sec (83.33%)
8,470,791 branch-misses # 1.89% of all branches (83.33%)
|
stalled-cycles,则是指令管道未能按理想状态发挥并行作用,发生停滞的时钟周期。stalled-cycles-frontend指指令读取或解码的指令步骤,而stalled-cycles-backend则是指令执行步骤。第二列中的cycles idle其实意思跟stalled是一样的,由于指令执行停滞了,所以指令管道也就空闲了,千万不要误解为CPU的空闲率。这个数值是由stalled-cycles-frontend或stalled-cycles-backend除以上面的cycles得出的。
另外cpu可以同时有多条pipeline,这就是理论上最大的IPC.
pipeline效率和IPC
虽然一个指令需要5个步骤,也就是完全执行完需要5个cycles,这样一个时钟周期最多能执行0.2条指令,IPC就是0.2,显然太低了。
- 非流水线:

如果把多个指令的五个步骤用pipeline流水线跑起来,在理想情况下一个时钟周期就能跑完一条指令了,这样IPC就能达到1了。
这种非流水线的方式将一个指令分解成多个步骤后,能提升主频,但是一个指令执行需要的时间基本没变
- 标量流水线, 标量(Scalar)流水计算机是只有一条指令流水线的计算机:
进一步优化,如果我们加大流水线的条数,让多个指令并行执行,就能得到更高的IPC了,但是这种并行必然会有指令之间的依赖,比如第二个指令依赖第一个的结果,所以多个指令并行更容易出现互相等待(stall).
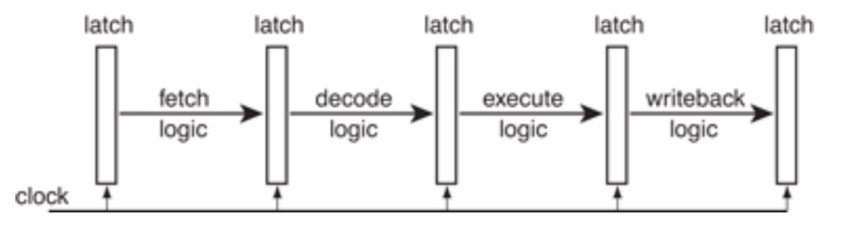
在每个时钟周期的开始,指令的部分数据和控制信息都保存在流水线锁存器中,并且该信息形成了下一个流水线的逻辑电路输入。在时钟周期内,信号通过组合逻辑传播,从而在时钟周期结束时及时产生输出,以供下一个pipeline锁存器捕获。
早期的RISC处理器,例如IBM的801原型,MIPS R2000(基于斯坦福MIPS机器)和原始的SPARC(来自Berkeley RISC项目),都实现了一个简单的5阶段流水线,与上面所示的流水线不同( 额外的阶段是内存访问,在执行后存放结果)。在那个时代,主流的CISC架构80386、68030和VAX处理器使用微码顺序工作(通过RISC进行流水作业比较容易,因为指令都是简单的寄存器到寄存器操作,与x86、68k或VAX不同)。导致的结果,以20 MHz运行的SPARC比以33 MHz运行的386快得多。从那以后,每个处理器都至少在某种程度上进行了流水线处理。
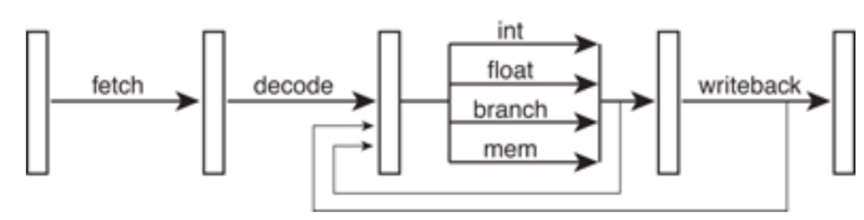
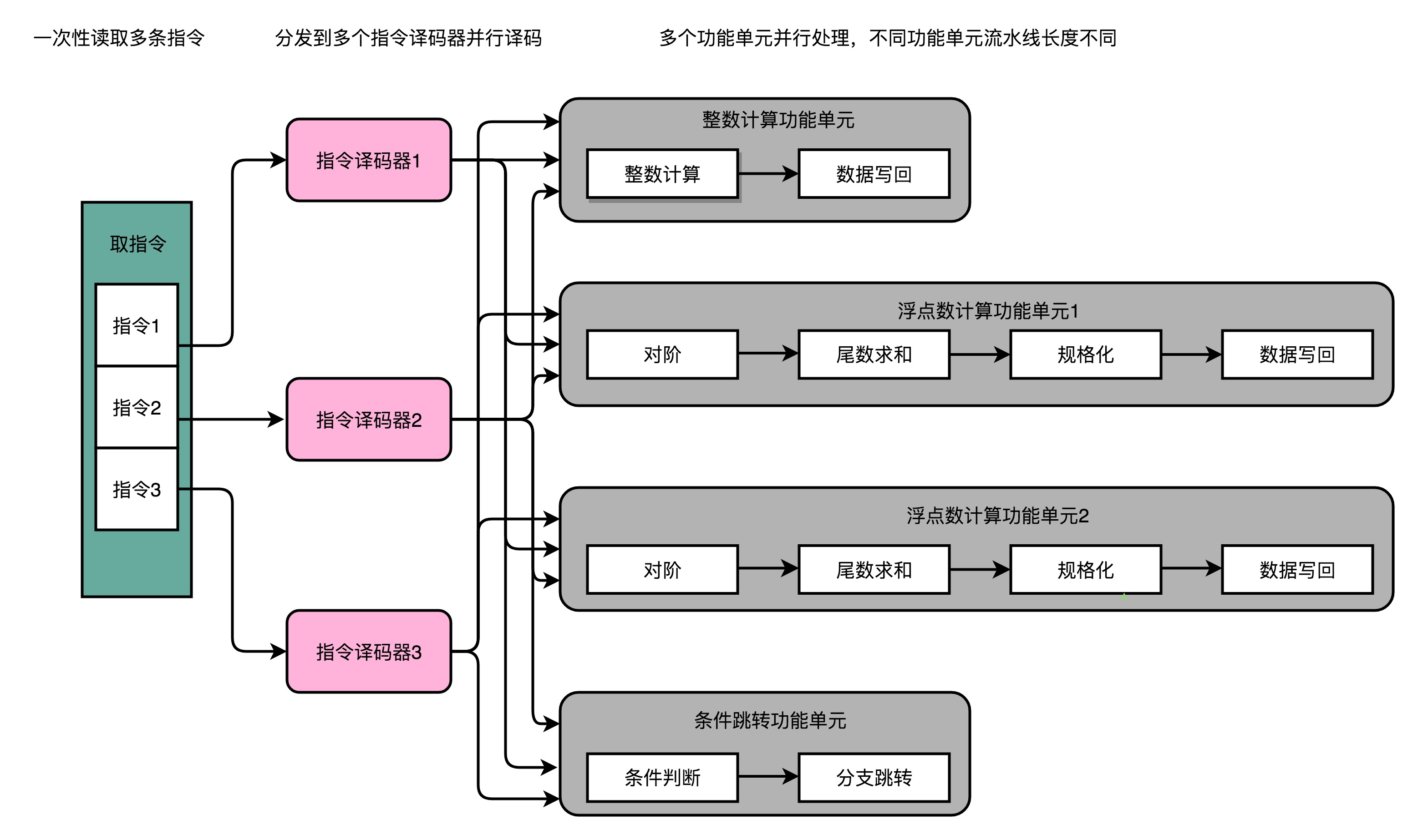
- 超标量流水线:所谓超标量(Superscalar)流 水计算机,是指它具有两条以上的指令流水线, 超标流水线数量也就是ALU执行单元的并行度
一般而言流水线的超标量不能超过单条流水线的深度
每个功能单元都有独立的管道,甚至可以具有不同的长度。 这使更简单的指令可以更快地完成,从而减少了等待时间。 在各个管道内部之间也有许多旁路,但是为简单起见,这些旁路已被省略。
下图中,处理器可能每个周期执行3条不同的指令,例如,一个整数,一个浮点和一个存储器操作。 甚至可以添加更多的功能单元,以便处理器能够在每个周期执行两个整数指令,或两个浮点指令,或使用任何其他方式。
鲲鹏的流水线结构:
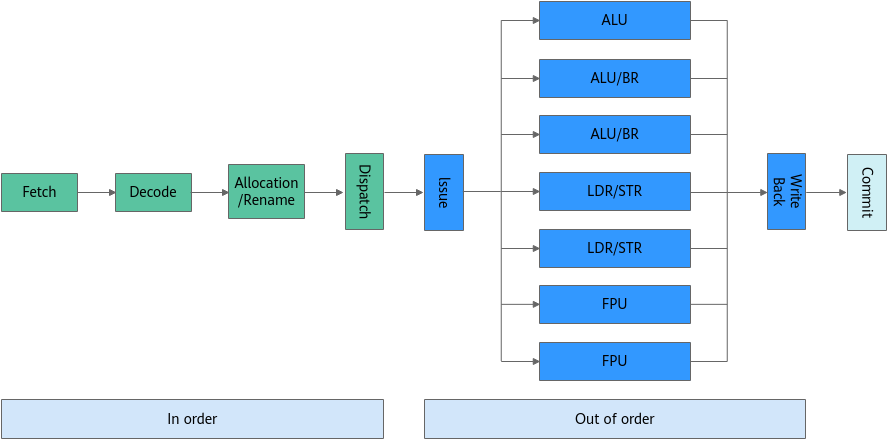
三级流水线的执行容易被打断,导致指令执行效率低,后面发展起来的五级指令流水线技术被认为是经典的处理器设置方式,已经在多种RISC处理器中广泛使用,它在三级流水线(取指、译码、执行)的基础上,增加了两级处理,将“执行”动作进一步分解为执行、访存、回写,解决了三级流水线中存储器访问指令在指令执行阶段的延迟问题,但是容易出现寄存器互锁等问题导致流水线中断。鲲鹏920处理器采用八级流水线结构,首先是提取指令,然后通过解码、寄存器重命名和调度阶段。一旦完成调度,指令将无序发射到八个执行管道中的一个,每个执行管道每个周期都可以接受并完成一条指令,最后就是访存和回写操作。
流水线的设计可以实现不间断取指、解码、执行、写回,也可以同时做几条流水线一起取指、解码、执行、写回,也就引出了超标量设计。
超标量处理器可以在一个时钟周期内执行多个指令。需要注意的是,每个执行单元不是单独的处理器,而是单个CPU内(也可以理解成单core)的执行资源,在上面图中也由体现。
三路超标量四工位流水线的指令/周期,将CPI从1变成0.33,即每周期执行3.33条指令,这样的改进幅度实在是令人着迷的,因此在初期的时候超标量甚至被人们赞美为标量程序的向量式处理。
理想是丰满的,现实却是骨感的,现实中的CPI是不可能都这样的,因为现在的处理器执行不同指令时候的“执行”段的工位并不完全一样,例如整数可能短一些,浮点或者向量和 Load/Store 指令需要长一些(这也是为什么AVX512指令下,CPU会降频的原因,因为一个工位太费时间了,不得不降速,频率快了也没啥用),加上一些别的因素,实际大部分程序的实际 CPI 都是 1.x 甚至更高。
多发射分发逻辑的复杂性随着发射数量呈现平方和指数的变化。也就是说,5发射处理器的调度逻辑几乎是4发射设计的两倍,其中6发射是4倍,而7发射是8倍,依此类推。
流水线案例
在Linux Kernel中有大量的 likely/unlikely
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
//ip 层收到消息后,如果是tcp就调用tcp_v4_rcv作为tcp协议的入口
int tcp_v4_rcv(struct sk_buff *skb)
{
...
if (unlikely(th->doff < sizeof(struct tcphdr) / 4))
goto bad_packet; //概率很小
if (!pskb_may_pull(skb, th->doff * 4))
goto discard_it;
//file: net/ipv4/tcp_input.c
int tcp_rcv_established(struct sock *sk, ...)
{
if (unlikely(sk->sk_rx_dst == NULL))
......
}
//file: include/linux/compiler.h
|
__builtin_expect 这个指令是 gcc 引入的。该函数作用是允许程序员将最有可能执行的分支告诉编译器,来辅助系统进行分支预测。(参见 https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html)
它的用法为:__builtin_expect(EXP, N)。意思是:EXP == N的概率很大。那么上面 likely 和 unlikely 这两句的具体含义就是:
- builtin_expect(!!(x),1) x 为真的可能性更大 //0两次取反还是0,非0两次取反都是1,这样可以适配builtin_expect(EXP, N)的N,要不N的参数没法传
- __builtin_expect(!!(x),0) x 为假的可能性更大
当正确地使用了__builtin_expect后,编译器在编译过程中会根据程序员的指令,将可能性更大的代码紧跟着前面的代码,从而减少指令跳转带来的性能上的下降。让L1i中加载的代码尽量有效紧凑
这样可以让 CPU流水线分支预测的时候默认走可能性更大的分支。如果分支预测错误所有流水线都要取消重新计算。
流水线的实际效果
假如一个15级的流水线,如果处理器要将做无用功的时间限制在 10%,那么它必须在正确预测每个分支的准确率达到 99.3%(因为错误一次,15级流水线都要重置,所以错误会放大15倍,0.7*15=10) 。很少有通用程序能够如此准确地预测分支。
下图是不同场景在英特尔酷睿 i7 基准测试,可以看到有19% 的指令都被浪费了,但能耗的浪费情况更加严重,因为处理器必须利用额外的能量才能在推测失误时恢复原来的状态。这样的度量导致许多人得出结论,架构师需要一种不同的方法来实现性能改进。于是多级流水线不能疯狂增加,这样只能往多核发展。
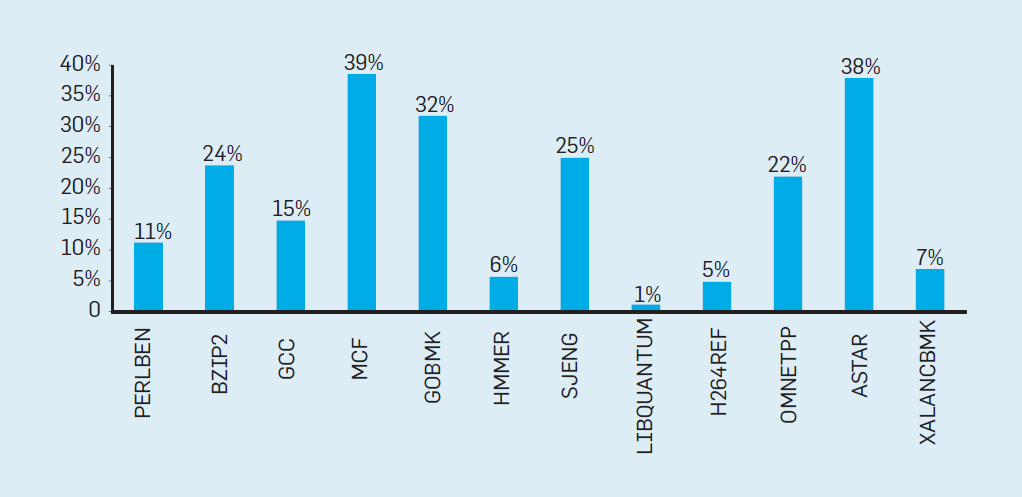
Deeper Pipelines深度流水线
由于时钟速度受流水线中最长阶段的长度的限制,因此每个级的逻辑门可以再细分,尤其是较长的逻辑门,从而将流水线转换为更深的深度流水线,各阶段的数量长度变小而阶段总数量变多,如下图。
这样整个处理器可以更高的时钟速度运行。当然,每个指令将需要更多的周期来完成(等待时间),但是处理器仍将在每个周期中完成1条指令,这样每秒将有更多的周期,处理器每秒将完成更多的指令。
Alpha架构师尤其喜欢这个深度流水线,这也是为什么早期的Alpha拥有非常深的流水线,并且在那个时代以很高的时钟速度运行。 当然还有Intel的NetBurst架构,唯主频论。
如今,现代处理器努力将每个流水线阶段的门延迟数量降低到很少(大约12-25个)。
在PowerPC G4e中为7-12,在ARM11和Cortex-A9中为8+,在Athlon中为10-15,在Pentium-Pro/II/III/M中为12+,在Athlon64/Phenom/Fusion-A中为12-17,在Cortex-A8中为13+,在UltraSPARC-III/IV中为14,在Core 2中为14+,在Core i*2中为14-18+,在Core i中为16+,在PowerPC G5中为16-25,在Pentium-4中为20+, 在奔腾4E中为31+。 与RISC相比,x86处理器通常具有更深的流水线,因为它们需要做更多的工作来解码复杂的x86指令。UltraSPARC-T1/T2/T3是深度流水线趋势的例外(UltraSPARC-T1仅6个,T2/T3是8-12,因为其倾向让单核简化的方式来堆叠核数量)。
不同架构的CPU流水线的级数(长度)存在很大差异,从几级到几十级不等,流水线级数越多,CPU结构就越复杂,功能也就越强大,同时功耗也会越大。相反地,流水线级数少,CPU结构简单,功耗就会降低很多。下表是一些典型的ARM流水线级别。
例如 Cortex-A15、Sandy Bridge 都分别具备 15 级、14 级流水线,而 Intel NetBurst(Pentium 4)、AMD Bulldozer 都是 20 级流水线,它们的工位数都远超出基本的四(或者五)工位流水线设计。更长的流水线虽然能提高频率,但是代价是耗电更高而且可能会有各种性能惩罚。
ARM指令集以及对应的流水线
| 型号 | 指令集 | 流水线 |
|---|---|---|
| ARM7 | ARMv4 | 3级 |
| ARM9 | ARMv5 | 5级 |
| ARM11 | ARMv6 | 8级 |
| Cortex-A8 | ARMv7-A | 13级 |
| 鲲鹏920/Cortex-A55 | ARMv8 | 8级 |
流水线越长带来的问题:
- 每一级流水线之间需要流水线寄存器暂存数据,存取需要额外的负担
- 功耗高
- 对分支预测不友好
指令延时
考虑一个非流水线机器,具有6个执行阶段,长度分别为50 ns,50 ns,60 ns,60 ns,50 ns和50 ns。
-这台机器上的指令等待时间是多少?
-执行100条指令需要多少时间?
指令等待时间 = 50+50+60+60+50+50= 320 ns
执行100条指令需 = 100*320 = 32000 ns
对比流水线延时
假设在上面这台机器上引入了流水线技术,但引入流水线技术时,时钟偏移会给每个执行阶段增加5ns的开销。
-流水线机器上的指令等待时间是多少?
-执行100条指令需要多少时间?
这里需要注意的是,在流水线实现中,流水线级的长度必须全部相同,即最慢级的速度加上开销,开销为5ns。
流水线级的长度= MAX(非流水线级的长度)+开销= 60 + 5 = 65 ns
指令等待时间= 65 ns
执行100条指令的时间= 65 6 1 + 65 1 99 = 390 + 6435 = 6825 ns
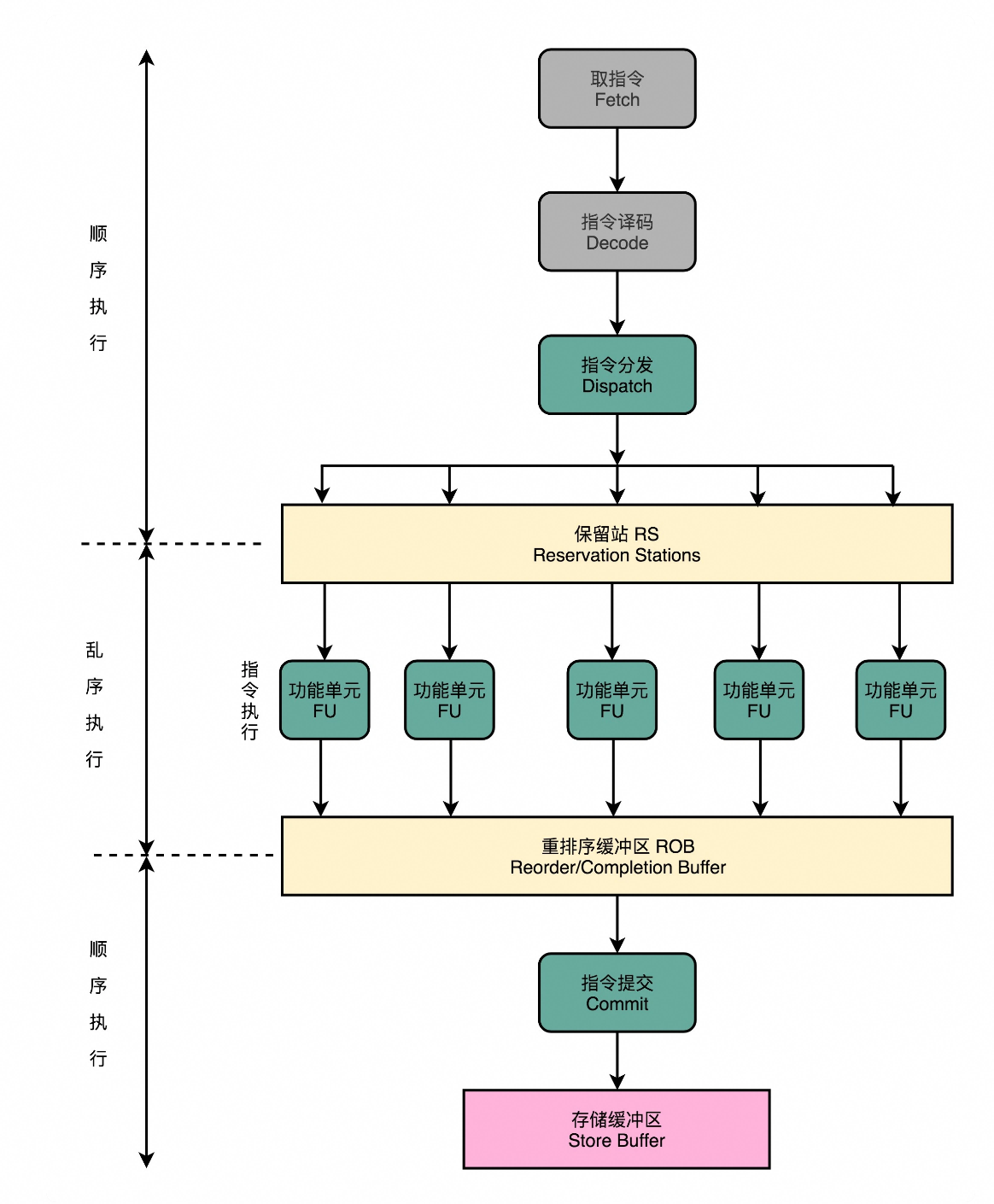
保留站和乱序执行
指令在做完取码、译码后一般先交由一个指令保留站,统一交给后面的多个执行单元(多发射),执行完后再次将结果排序就行,有依赖关系的需要等待。
保留站后面就是乱序执行技术,就好像在指令的执行阶段提供一个“线程池”。指令不再是顺序执行的,而是根据池里所拥有的资源,以及各个任务是否可以进行执行,进行动态调度。在执行完成之后,又重新把结果在一个队列里面,按照指令的分发顺序重新排序。即使内部是“乱序”的,但是在外部看起来,仍然是井井有条地顺序执行。
从流水线获得加速
加速是没有流水线的平均指令时间与有流水线的平均指令时间之比。(这里不考虑由不同类型的危害引起的任何失速)
假设:
未流水线的平均指令时间= 320 ns
流水线的平均指令时间= 65 ns
那么,100条指令的加速= 32000/6825 = 4.69,这种理想情况下效率提升了4.69倍。
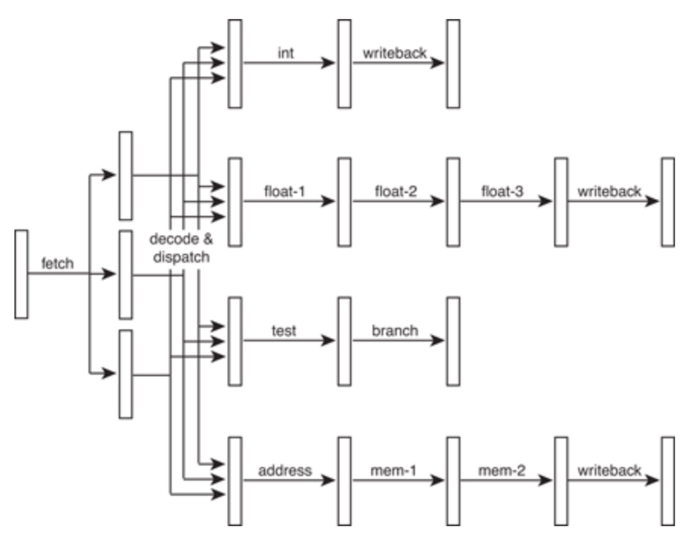
每一个功能单元的流水线的长度是不同的。事实上,不同的功能单元的流水线长度本来就不一样。我们平时所说的 14 级流水线,指的通常是进行整数计算指令的流水线长度。如果是浮点数运算,实际的流水线长度则会更长一些。
指令缓存(Instruction Cache)和数据缓存(Data Cache)
在第 1 条指令执行到访存(MEM)阶段的时候,流水线里的第 4 条指令,在执行取指令(Fetch)的操作。访存和取指令,都要进行内存数据的读取。我们的内存,只有一个地址译码器的作为地址输入,那就只能在一个时钟周期里面读取一条数据,没办法同时执行第 1 条指令的读取内存数据和第 4 条指令的读取指令代码。
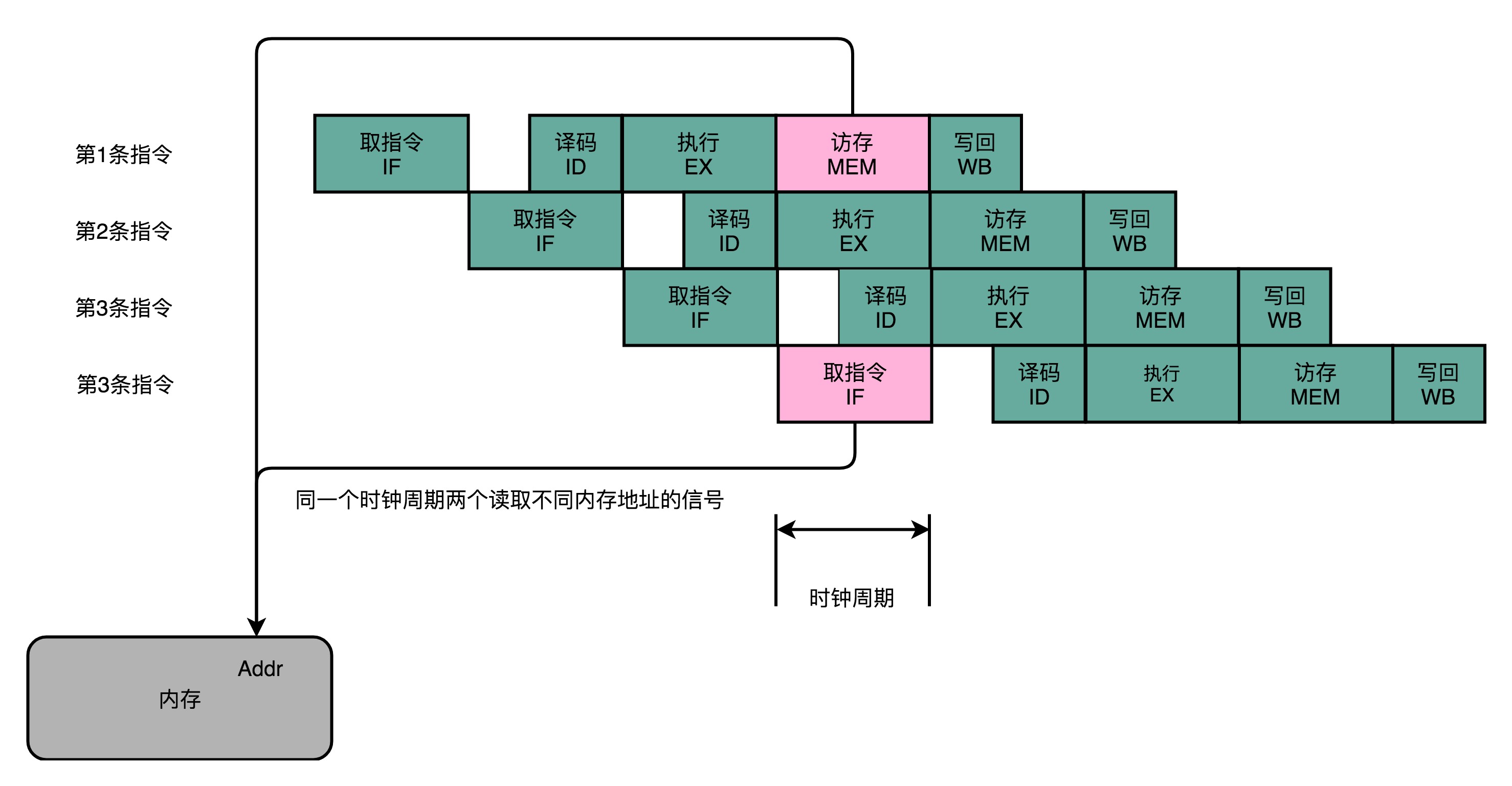
把内存拆成两部分的解决方案,在计算机体系结构里叫作哈佛架构(Harvard Architecture),来自哈佛大学设计Mark I 型计算机时候的设计。我们今天使用的 CPU,仍然是冯·诺依曼体系结构的,并没有把内存拆成程序内存和数据内存这两部分。因为如果那样拆的话,对程序指令和数据需要的内存空间,我们就没有办法根据实际的应用去动态分配了。虽然解决了资源冲突的问题,但是也失去了灵活性。
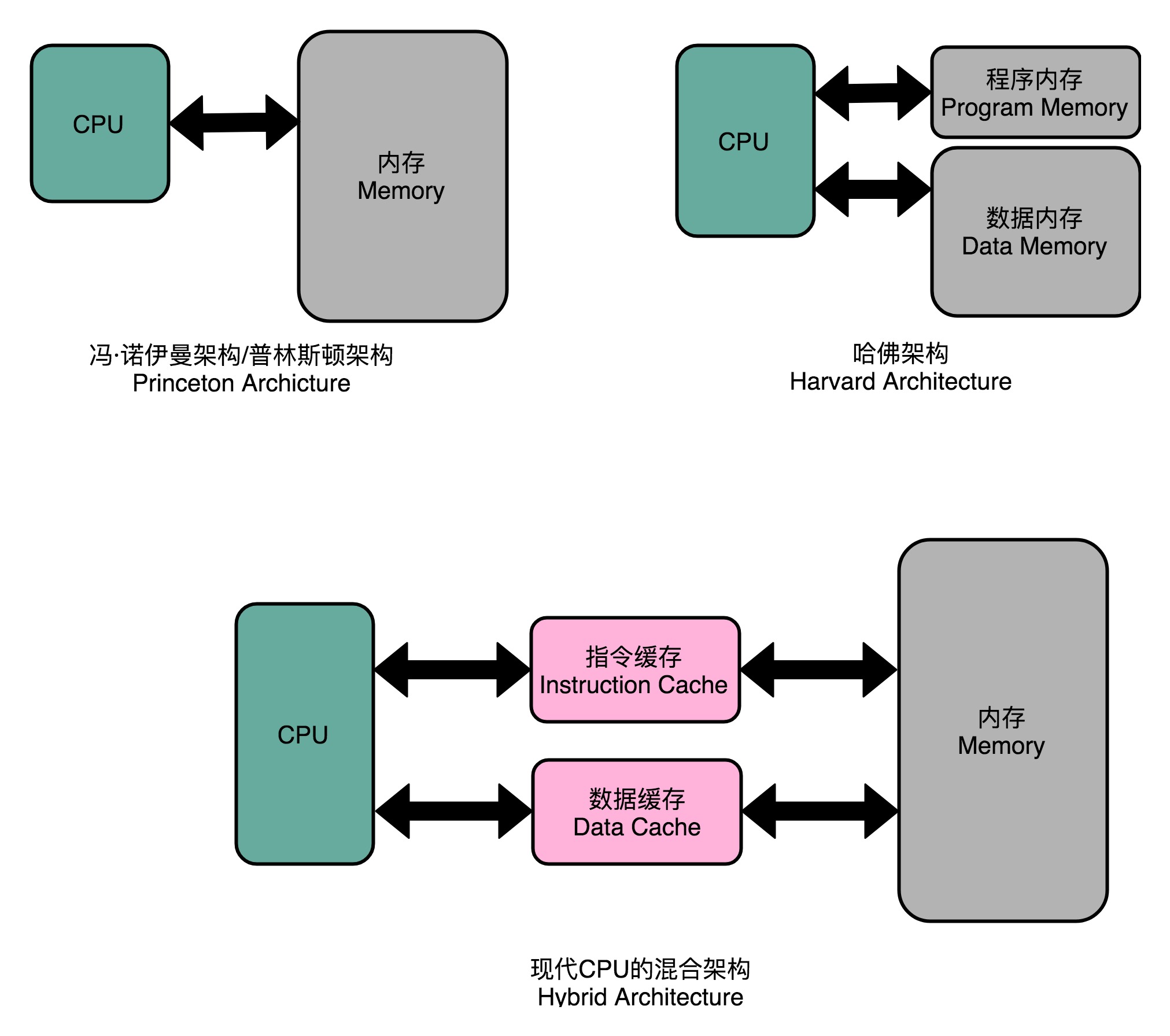
在流水线产生依赖的时候必须pipeline stall,也就是让依赖的指令执行NOP。
Intel X86每个指令需要的cycle
Intel xeon
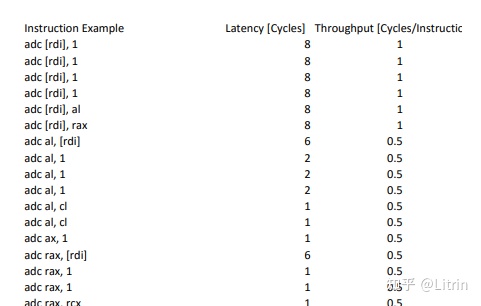
不同架构带来IPC变化:
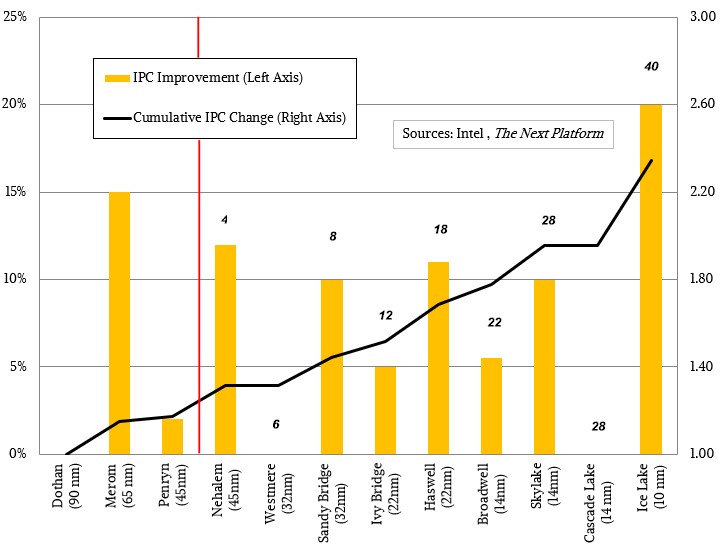
Intel 最新的CPU Ice Lake和其上一代的性能对比数据:
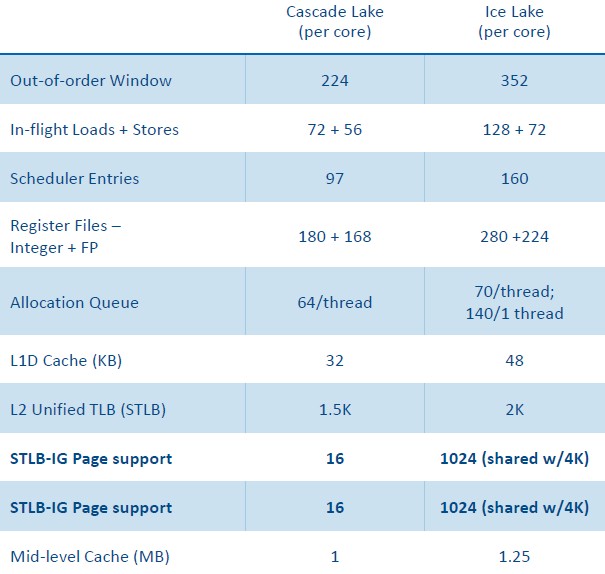
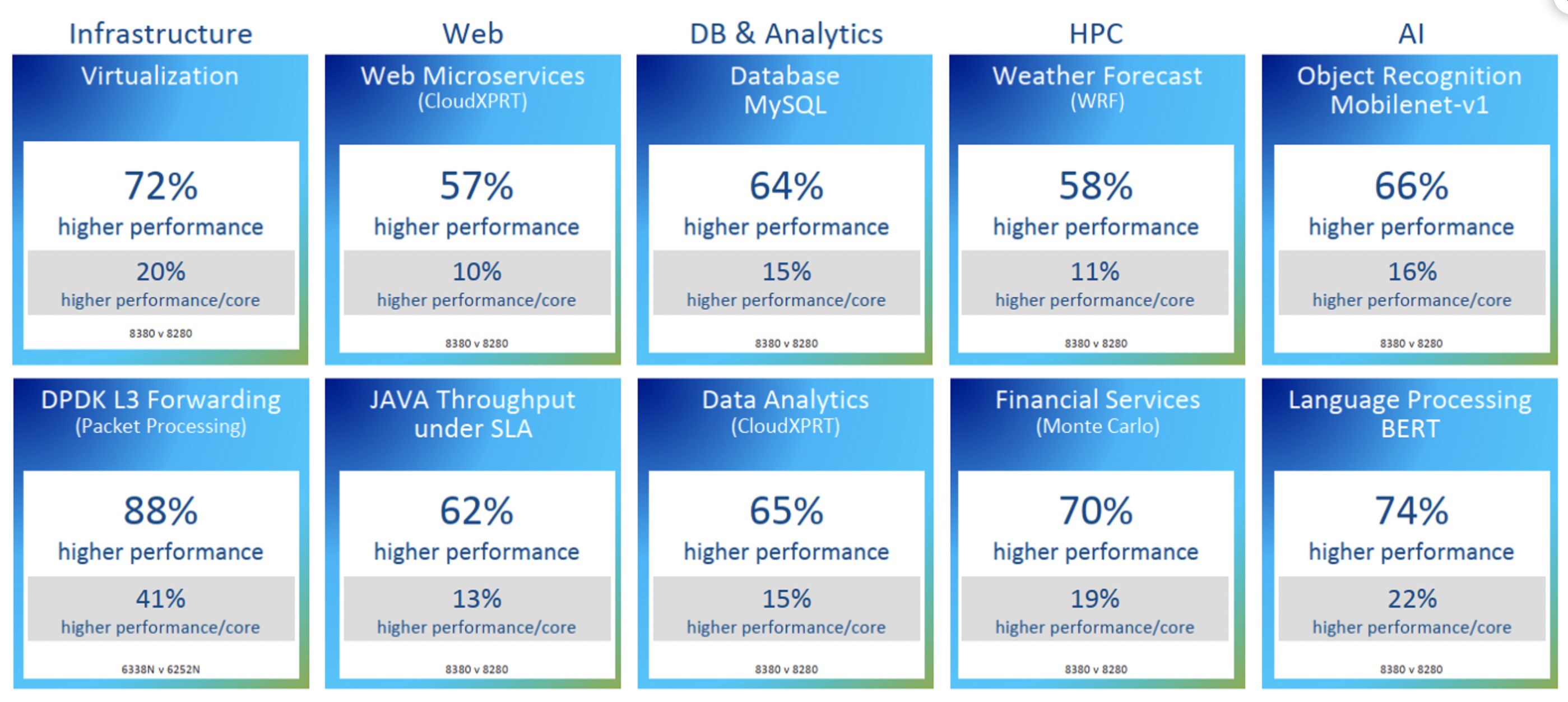
上图最终结果导致了IPC提升了20%,以及整体效率的提升:
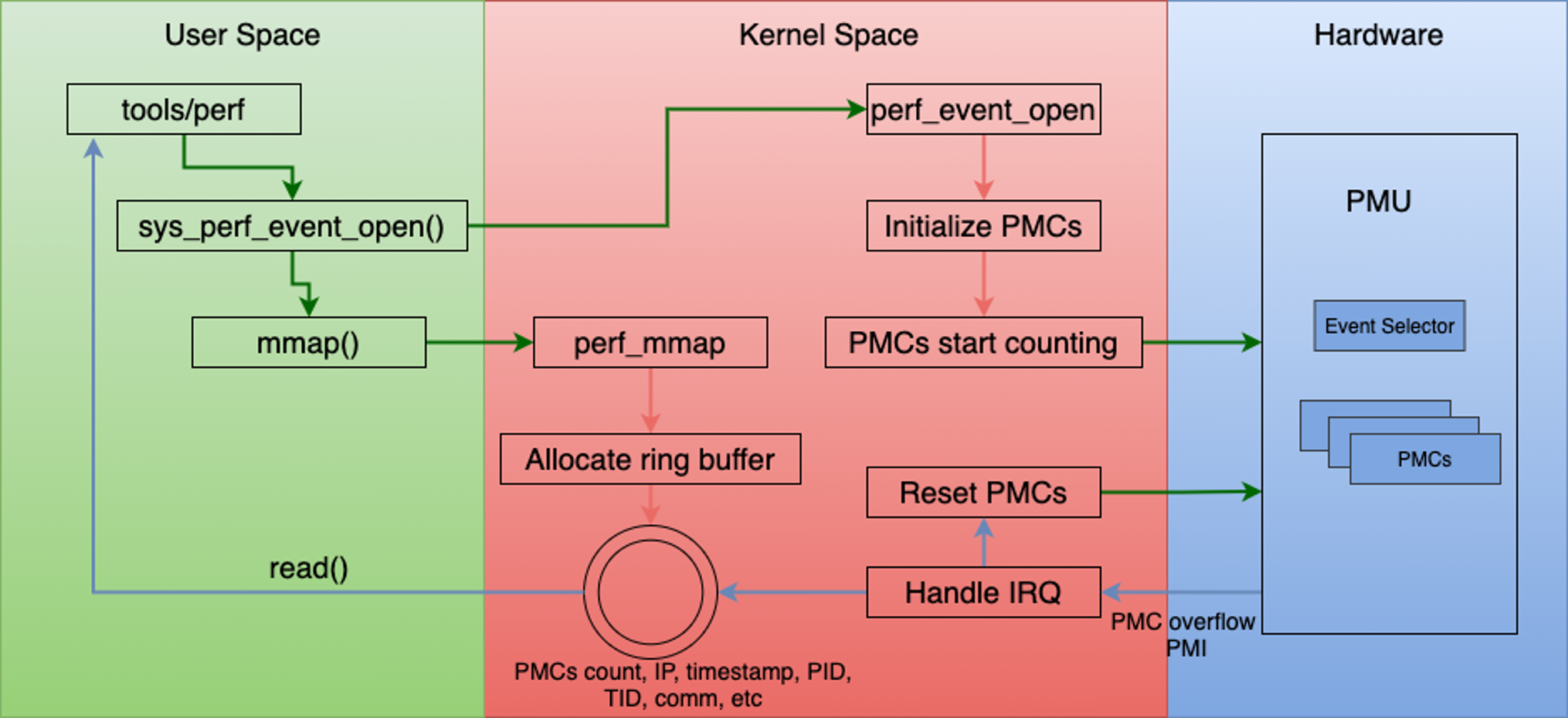
perf 使用
主要是通过采集 PMU(Performance Monitoring Unit – CPU内部提供)数据来做性能监控
Perf 是一个包含 22 种子工具的工具集,每个工具分别作为一个子命令。
annotate 命令读取 perf.data 并显示注释过的代码;diff 命令读取两个 perf.data 文件并显示两份剖析信息之间的差异;
evlist 命令列出一个 perf.data 文件的事件名称;
inject 命令过滤以加强事件流,在其中加入额外的信 息;
kmem 命令为跟踪和测量内核中 slab 子系统属性的工具;
kvm 命令为跟踪和测量 kvm 客户机操 作系统的工具;
list 命令列出所有符号事件类型;
lock 命令分析锁事件;
probe 命令定义新的动态跟 踪点;
record 命令运行一个程序,并把剖析信息记录在 perf.data 中;
report 命令读取 perf.data 并显 示剖析信息;
sched 命令为跟踪和测量内核调度器属性的工具;
script 命令读取 perf.data 并显示跟踪 输出;
stat 命令运行一个程序并收集性能计数器统计信息;
timechart 命令为可视化某个负载在某时 间段的系统总体性能的工具;
top 命令为系统剖析工具。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
sudo perf record -g -a -e skb:kfree_skb //perf 记录丢包调用栈 然后sudo perf script 查看 (网络报文被丢弃时会调用该函数kfree_skb)
perf record -e 'skb:consume_skb' -ag //记录网络消耗
perf probe --add tcp_sendmsg //增加监听probe perf record -e probe:tcp_sendmsg -aR sleep 1
sudo perf sched record -- sleep 1 //记录cpu调度的延时
sudo perf sched latency //查看
perf sched latency --sort max //查看上一步记录的结果,以调度延迟排序。
perf record --call-graph dwarf
perf report
perf report --call-graph -G //反转调用关系
展开汇编结果
占比 行号 指令
│ mov %r13,%rax
│ mov %r8,%rbx
0.56 │ mov %r9,%rcx
0.19 │ lock cmpxchg16b 0x10(%rsi) //加锁占89.53,下一行
89.53 │ sete %al
1.50 │ mov %al,%r13b
0.19 │ mov $0x1,%al
│ test %r13b,%r13b
│ ↓ je eb
│ ↓ jmpq ef
│47: mov %r9,(%rsp)
//如下代码的汇编
void main() {
while(1) {
__asm__ ("pause\n\t"
"pause\n\t"
"pause\n\t"
"pause\n\t"
"pause");
}
}
//每行pause占20%
│
│ Disassembly of section .text:
│
│ 00000000004004ed <main>:
│ main():
│ push %rbp
│ mov %rsp,%rbp
0.71 │ 4: pause
19.35 │ pause
20.20 │ pause
19.81 │ pause
19.88 │ pause
20.04 │ ↑ jmp 4
|
网络收包软中断
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
_raw_spin_lock_irqsave /proc/kcore
│ Disassembly of section load2:
│
│ ffffffff81662b00 <load2+0x662b00>:
0.30 │ nop
│ push %rbp
0.21 │ mov %rsp,%rbp
0.15 │ push %rbx
0.12 │ pushfq
0.57 │ pop %rax
0.45 │ nop
0.15 │ mov %rax,%rbx
0.21 │ cli
1.20 │ nop
│ mov $0x20000,%edx
│ lock xadd %edx,(%rdi) //加锁耗时83%
83.42 │ mov %edx,%ecx
│ shr $0x10,%ecx
0.66 │ cmp %dx,%cx
│ ↓ jne 34
0.06 │2e: mov %rbx,%rax
│ pop %rbx
│ pop %rbp
0.57 │ ← retq
0.12 │34: mov %ecx,%r8d
0.03 │ movzwl %cx,%esi
│3a: mov $0x8000,%eax
│ ↓ jmp 4f
│ nop
0.06 │48: pause
4.67 │ sub $0x1,%eax
│ ↓ je 69
0.12 │4f: movzwl (%rdi),%edx //慢操作
6.73 │ mov %edx,%ecx
│ xor %r8d,%ecx
│ and $0xfffe,%ecx
│ ↑ jne 48
0.12 │ movzwl %dx,%esi
0.09 │ callq 0xffffffff8165501c
│ ↑ jmp 2e
│69: nop
│ ↑ jmp 3a
|
可以通过perf看到cpu的使用情况:
$sudo perf stat -a -- sleep 10
Performance counter stats for 'system wide':
239866.330098 task-clock (msec) # 23.985 CPUs utilized /10*1000 (100.00%)
45,709 context-switches # 0.191 K/sec (100.00%)
1,715 cpu-migrations # 0.007 K/sec (100.00%)
79,586 page-faults # 0.332 K/sec
3,488,525,170 cycles # 0.015 GHz (83.34%)
9,708,140,897 stalled-cycles-frontend # 278.29% /cycles frontend cycles idle (83.34%)
9,314,891,615 stalled-cycles-backend # 267.02% /cycles backend cycles idle (66.68%)
2,292,955,367 instructions # 0.66 insns per cycle insn/cycles
# 4.23 stalled cycles per insn stalled-cycles-frontend/insn (83.34%)
447,584,805 branches # 1.866 M/sec (83.33%)
8,470,791 branch-misses # 1.89% of all branches (83.33%)
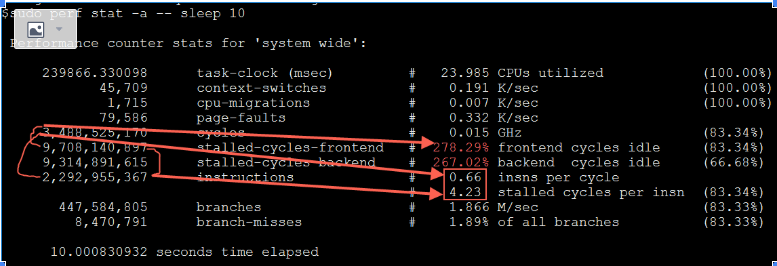
IPC测试
实际运行的时候增加如下nop到100个以上
|
1
2
3
4
5
6
7
|
void main() {
while(1) {
__asm__ ("nop\n\t"
"nop\n\t"
"nop");
}
}
|
如果同时运行两个如上测试程序,鲲鹏920运行,每个程序的IPC都是3.99
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#perf stat -- ./nop.out
failed to read counter branches
Performance counter stats for './nop.out':
8826.948260 task-clock (msec) # 1.000 CPUs utilized
8 context-switches # 0.001 K/sec
0 cpu-migrations # 0.000 K/sec
37 page-faults # 0.004 K/sec
22,949,862,030 cycles # 2.600 GHz
2,099,719 stalled-cycles-frontend # 0.01% frontend cycles idle
18,859,839 stalled-cycles-backend # 0.08% backend cycles idle
91,465,043,922 instructions # 3.99 insns per cycle
# 0.00 stalled cycles per insn
<not supported> branches
33,262 branch-misses # 0.00% of all branches
8.827886000 seconds time elapsed
|
intel X86 8260
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#perf stat -- ./nop.out
Performance counter stats for './nop.out':
65061.160345 task-clock (msec) # 1.001 CPUs utilized
46 context-switches # 0.001 K/sec
92 cpu-migrations # 0.001 K/sec
108 page-faults # 0.002 K/sec
155,659,827,263 cycles # 2.393 GHz
<not supported> stalled-cycles-frontend
<not supported> stalled-cycles-backend
603,247,401,995 instructions # 3.88 insns per cycle
4,742,051,659 branches # 72.886 M/sec
1,799,428 branch-misses # 0.04% of all branches
65.012821629 seconds time elapsed
|
这两块CPU理论IPC最大值都是4,实际x86离理论值更远一些. 增加while循环中的nop数量(从132增加到432个)IPC能提升到3.92
IPC和超线程
ipc是指每个core的IPC
超线程(Hyper-Threading)原理
概念:一个核还可以进一步分成几个逻辑核,来执行多个控制流程,这样可以进一步提高并行程度,这一技术就叫超线程,intel体系下也叫做 simultaneous multi-threading(SMT–wiki用的是simultaneous,也有人用 symmetric(29页),我觉得symmetric也比较能表达超线程的意思)。
Two logical cores can work through tasks more efficiently than a traditional single-threaded core. By taking advantage of idle time when the core would formerly be waiting for other tasks to complete, Intel® Hyper-Threading Technology improves CPU throughput (by up to 30% in server applications).
超线程技术主要的出发点是,当处理器在运行一个线程,执行指令代码时,很多时候处理器并不会使用到全部的计算能力,部分计算能力就会处于空闲状态。而超线程技术就是通过多线程来进一步“压榨”处理器。pipeline进入stalled状态就可以切到其它超线程上
举个例子,如果一个线程运行过程中,必须要等到一些数据加载到缓存中以后才能继续执行,此时 CPU 就可以切换到另一个线程,去执行其他指令,而不用去处于空闲状态,等待当前线程的数据加载完毕。通常,一个传统的处理器在线程之间切换,可能需要几万个时钟周期。而一个具有 HT 超线程技术的处理器只需要 1 个时钟周期。因此就大大减小了线程之间切换的成本,从而最大限度地让处理器满负荷运转。
ARM芯片基本不做超线程,另外请思考为什么有了应用层的多线程切换还需要CPU层面的超线程?
超线程(Hyper-Threading)物理实现: 在CPU内部增加寄存器等硬件设施,但是ALU、译码器等关键单元还是共享。在一个物理 CPU 核心内部,会有双份的 PC 寄存器、指令寄存器乃至条件码寄存器。超线程的目的,是在一个线程 A 的指令,在流水线里停顿的时候,让另外一个线程去执行指令。因为这个时候,CPU 的译码器和 ALU 就空出来了,那么另外一个线程 B,就可以拿来干自己需要的事情。这个线程 B 可没有对于线程 A 里面指令的关联和依赖。
CPU超线程设计过程中会引入5%的硬件,但是有30%的提升(经验值,场景不一样效果不一样,阿里的OB/MySQL/ODPS业务经验是提升35%),这是引入超线程的理论基础。如果是一个core 4个HT的话提升会是 50%
超线程如何查看
如果physical id和core id都一样的话,说明这两个core实际是一个物理core,其中一个是HT。
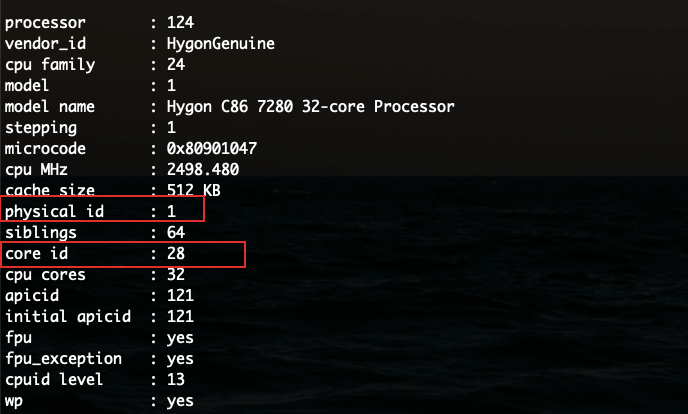
physical id对应socket,也就是物理上购买到的一块CPU; core id对应着每个物理CPU里面的一个物理core,同一个phyiscal id下core id一样说明开了HT
IPC和超线程的关系
IPC 和一个core上运行多少个进程没有关系。实际测试将两个运行nop指令的进程绑定到一个core上,IPC不变, 因为IPC就是该进程分到的circle里执行了多少个指令,只和进程业务逻辑相关。但是如果是这两个进程绑定到一个物理core以及对应的超线程core上那么IPC就会减半。如果程序是IO bound(比如需要频繁读写内存)首先IPC远远低于理论值4的,这个时候超线程同时工作的话IPC基本能翻倍
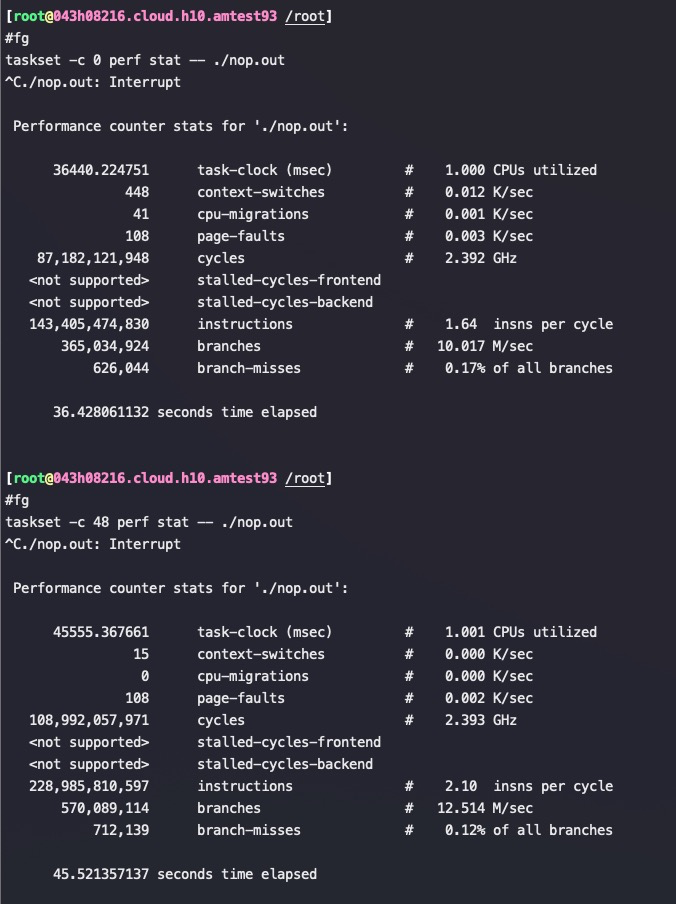
对应的CPU使用率, 两个进程的CPU使用率是200%,实际产出IPC是2.1+1.64=3.75,比单个进程的IPC为3.92小多了。而单个进程CPU使用率才100%
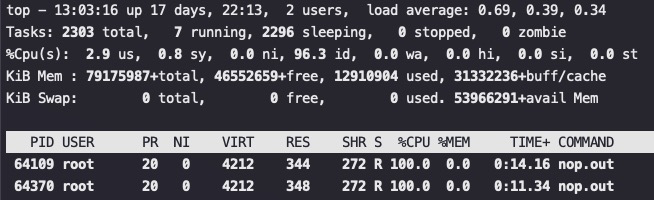
以上测试CPU为Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz (Thread(s) per core: 2)
再来看如下CPU上,0和64核是一对HT,单独跑nop、Pause指令的IPC分别是5/0.17(nop是一条完全不会卡顿的指令),可以得到这款CPU的最高IPC是5,一条 Pause 指令需要28-30个时钟周期。
如果在0/64上同时跑两个nop指令,虽然是两个超线程得到的IPC只有5的一半,也就是超线程在这种完全不卡顿的 nop 指令上完全没用;另外对比在0/64上同时跑两个Pause 指令,IPC 都还是0.17,也就是 Pause 指令完全可以将一个物理核发挥出两倍的运算能力
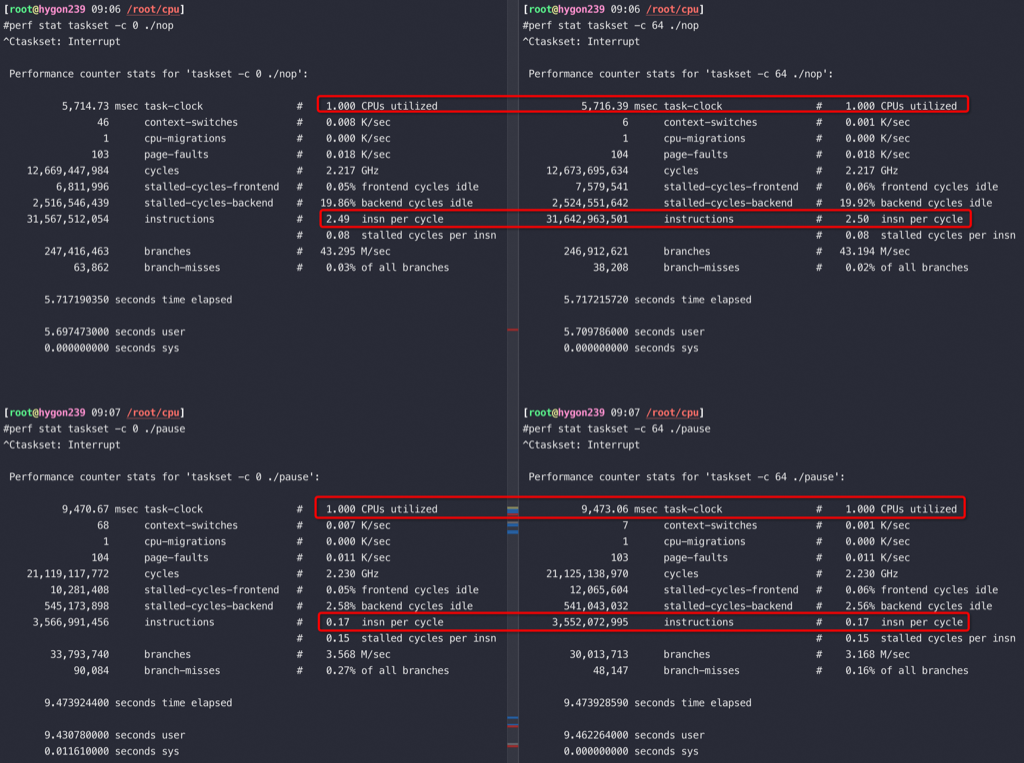
Pause指令和nop指令同时跑在一对HT上,nop基本不受影响,Pause降得非常低
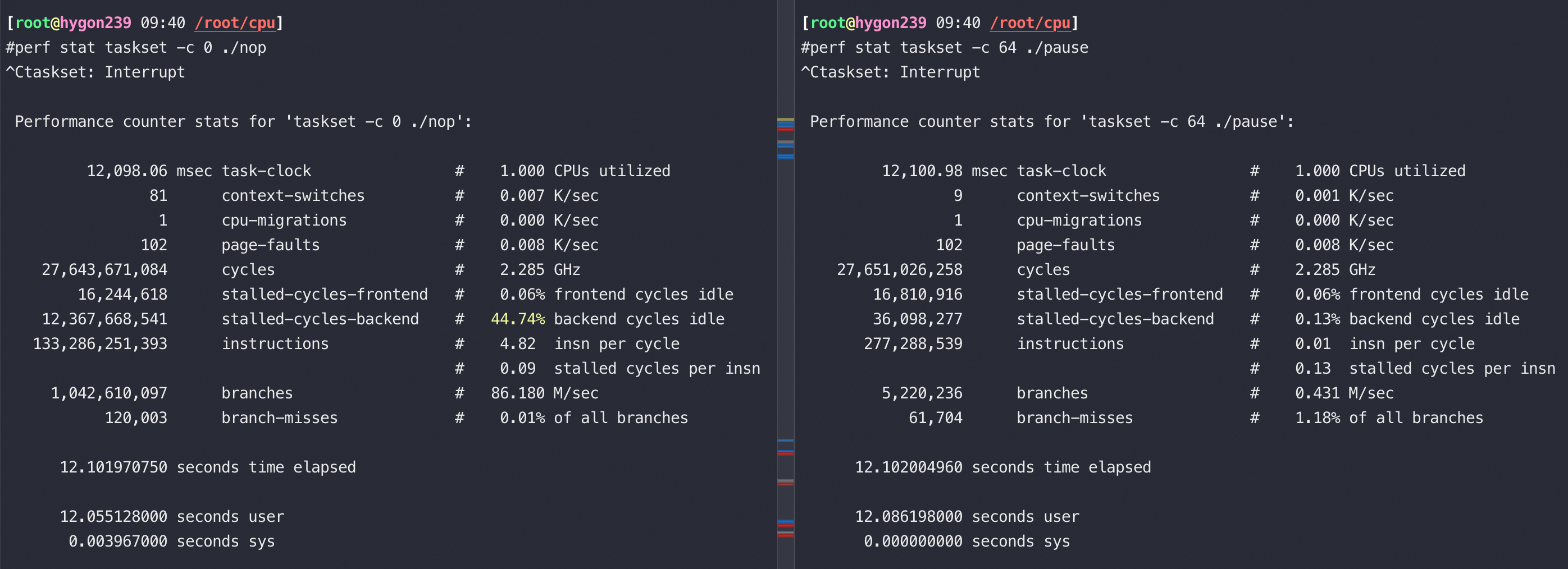
Pause指令和nop指令同时跑在一个核上,IPC 倒是各自保持不变,但是抢到的 CPU 配额相当于各自 50%(在自己的50%范围内独占,IPC也不受影响)
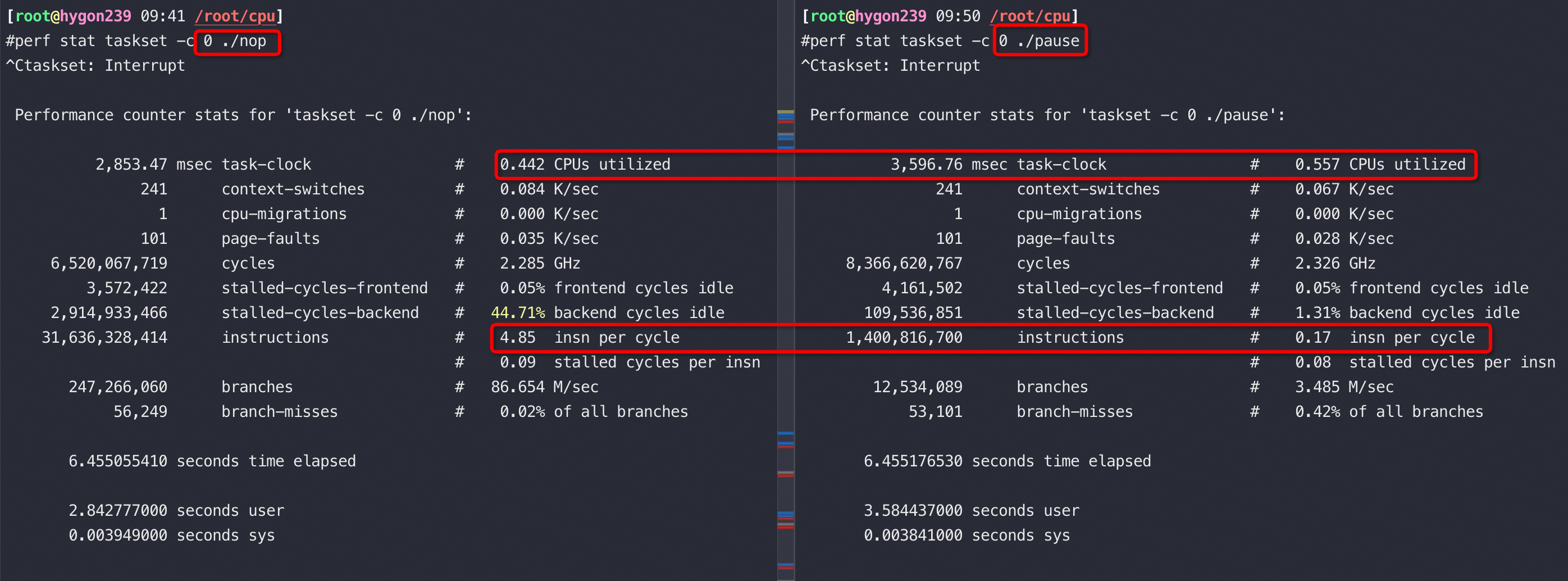
关掉如上CPU的超线程,从测试结果看海光如果开了超线程 Pause 是28个时钟周期,关掉超线程 Pause 是14个时钟周期
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
//关掉超线程后 Pause 的IPC 从0.17提升到了0.34
#perf stat taskset -c 0 ./pause
^Ctaskset: Interrupt
Performance counter stats for 'taskset -c 0 ./pause':
3,190.28 msec task-clock # 0.999 CPUs utilized
302 context-switches # 0.095 K/sec
1 cpu-migrations # 0.000 K/sec
99 page-faults # 0.031 K/sec
7,951,451,789 cycles # 2.492 GHz
1,337,801 stalled-cycles-frontend # 0.02% frontend cycles idle
7,842,812,091 stalled-cycles-backend # 98.63% backend cycles idle
2,671,280,445 instructions # 0.34 insn per cycle
# 2.94 stalled cycles per insn
21,917,856 branches # 6.870 M/sec
29,607 branch-misses # 0.14% of all branches
3.192937987 seconds time elapsed
3.190322000 seconds user
0.000000000 seconds sys
#lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 1
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 8
Vendor ID: HygonGenuine
CPU family: 24
Model: 1
Model name: Hygon C86 7260 24-core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 1070.009
CPU max MHz: 2200.0000
CPU min MHz: 1200.0000
BogoMIPS: 4399.40
Virtualization: AMD-V
L1d cache: 1.5 MiB
L1i cache: 3 MiB
L2 cache: 24 MiB
L3 cache: 128 MiB
NUMA node0 CPU(s): 0-5
NUMA node1 CPU(s): 6-11
NUMA node2 CPU(s): 12-17
NUMA node3 CPU(s): 18-23
NUMA node4 CPU(s): 24-29
NUMA node5 CPU(s): 30-35
NUMA node6 CPU(s): 36-41
NUMA node7 CPU(s): 42-47
|
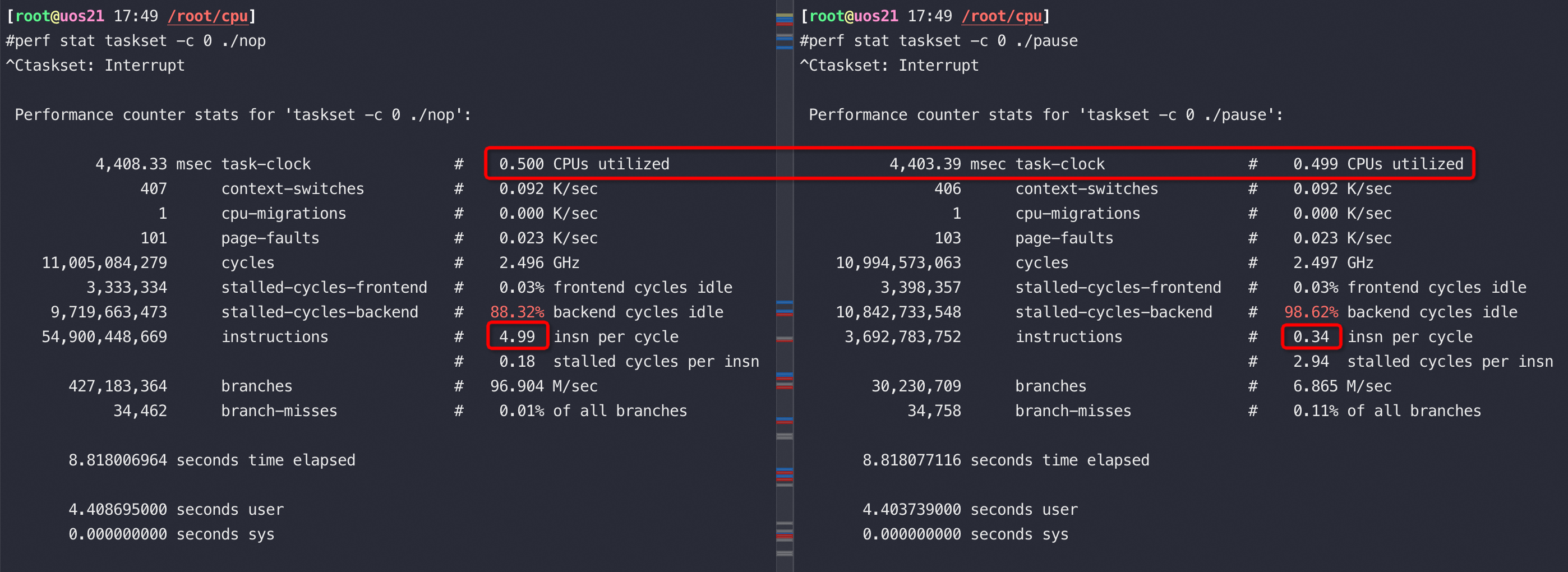
Intel和AMD单核以及HT性能比较
测试命令,这个测试命令无论在哪个CPU下,用2个物理核用时都是一个物理核的一半,所以这个计算是可以完全并行的
|
1
|
taskset -c 1,53 /usr/bin/sysbench --num-threads=2 --test=cpu --cpu-max-prime=50000 run //单核用一个threads,绑核, HT用2个threads,绑一对HT
|
测试结果为耗时,单位秒,Hygon 7280 就是Zen2架构
| Family Name | Intel 8269CY CPU @ 2.50GHz | Intel E5-2682 v4 @ 2.50GHz | Hygon 7280 2.1G |
|---|---|---|---|
| 单核 prime 50000 | 83 | 109 | 89 |
| HT prime 50000 | 48 | 74 | 87 |
主频和性价比
拿Intel 在数据中心计算的大核CPU IvyBridge与当时用于 存储系列的小核CPU Avoton(ATOM), 分别测试阿里巴巴(Oceanbase ,MySQL, ODPS)的workload,得到性能吞吐如下:
Intel 大小CPU 核心 阿里 Workload Output(QPS)
Avoton(8 cores) 2.4GHZ 10K on single core
Ivy Bridge(2650 v2 disable HT) 2.6GHZ 20K on single core
Ivy Bridge(2650 v2 enable HT) 2.4GHZ 25K on single core
Ivy Bridge(2650 v2 enable HT) 2.6GHZ 27K on single core
- 超线程等于将一个大核CPU 分拆成两个小核,Ivy Bridge的数据显示超线程给 Ivy Bridge 1.35倍(27K/20K) 的提升
- 现在我们分别评判 两种CPU对应的性能密度 (performance/core die size) ,该数据越大越好,根据我们的计算和测量发现:Avoton(包含L1D, L1I, and L2 per core)大约是 3~4平方毫米,Ivy Bridge (包含L1D, L1I, L2 )大约是12~13平方毫米, L3/core是 6~7平方毫米, 所以 Ivy Bridge 单核心的芯片面积需要18 ~ 20平方毫米。基于上面的数据我们得到的 Avoton core的性能密度为 2.5 (10K/4sqmm),而Ivy Bridge的性能密度是1.35 (27K/20sqmm),因此相同的芯片面积下 Avoton 的性能是 Ivy Bridge的 1.85倍(2.5/1.35).
- 从功耗的角度看性能的提升的对比数据,E5-2650v2(Ivy Bridge) 8core TDP 90w, Avoton 8 core TDP 20瓦, 性能/功耗 Avoton 是 10K QPS/20瓦, Ivy Bridge是 27KQPS/90瓦, 因此 相同的功耗下 Avoton是 Ivy Bridge的 1.75倍(10K QPS/20)/ (27KQPS/95)
- 从价格方面再进行比较,E5-2650v2(Ivy Bridge) 8core 官方价格是1107美元, Avoton 8 core官方价格是171美元。性能/价格 Avoton是 10KQPS/171美元,Ivy Bridge 是 27KQPS/1107美元, 因此相同的美元 Avoton的性能是 Ivy Bridge 的2.3倍(1 10KQPS/171美元)/ (27KQPS/1107美元)
从以上结论可以看到在数据中心的场景下,由于指令数据相关性较高,同时由于内存访问的延迟更多,因此复杂的CPU体系结构并不能获得相应性能提升,该原因导致我们需要的是更多的小核CPU,以此达到高吞吐量的能力,因此2014年我们向Intel提出需要将物理CPU的超线程由 2个升级到4个/8个, 或者直接将用更多的小核CPU增加服务器的吞吐能力,最新数据表明Intel 会在大核CPU中引入4个超线程,和在相同的芯片面积下引入更多的小核CPU。
预测:为了减少数据中心的功耗,我们需要提升单位面积下的计算密度,因此将来会引入Rack Computing的计算模式,每台服务器将会有4~5百个CPU core,如果使用4个CPU socket,每台机器将会达到~1000个CPU core,结合Compute Express Link (CXL), 一个机架内允许16台服务器情况下,可以引入共享内存,那么一个进程可以运行在上万个CPU core中,这样复杂环境下,我们需要对于这样的软件环境做出更多的布局和优化。
perf top 和 pause 的案例
在Skylake的架构中,将pause由10个时钟周期增加到了140个时钟周期。主要用在spin lock当中因为spin loop 多线程竞争差生的内存乱序而引起的性能下降。pause的时钟周期高过了绝大多数的指令cpu cycles,那么当我们利用perf top统计cpu 性能的时候,pause会有什么影响呢?我们可以利用一段小程序来测试一下.
测试机器:
CPU: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz * 2, 共96个超线程
案例:
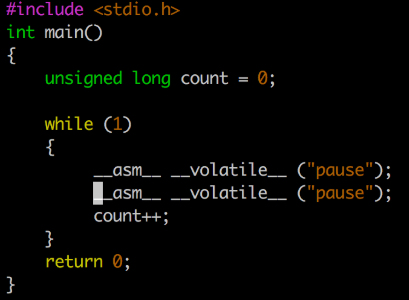
对如上两个pause指令以及一个 count++(addq),进行perf top:
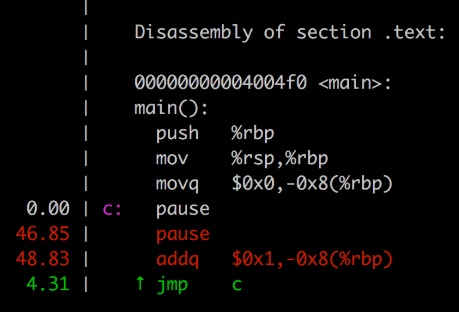
可以看到第一个pasue在perf top中cycles为0,第二个为46.85%,另外一个addq也有48.83%,基本可以猜测perf top在这里数据都往后挪了一个。
问题总结:
我们知道perf top是通过读取PMU的PC寄存器来获取当前执行的指令进而根据汇编的symbol信息获得是执行的哪条指令。所以看起来CPU在执行pause指令的时候,从PMU中看到的PC值指向到了下一条指令,进而导致我们看到的这个现象。通过查阅《Intel® 64 and IA-32 Architectures Optimization Reference Manual》目前还无法得知这是CPU的一个设计缺陷还是PMU的一个bug(需要对pause指令做特殊处理)。不管怎样,这个实验证明了我们统计spin lock的CPU占比还是准确的,不会因为pause指令导致PMU采样出错导致统计信息的整体失真。只是对于指令级的CPU统计,我们能确定的就是它把pause的执行cycles 数统计到了下一条指令。
补充说明: 经过测试,非skylake CPU也同样存在perf top会把pause(执行数cycles是10)的执行cycles数统计到下一条指令的问题,看来这是X86架构都存在的问题。
perf 和火焰图
调用 perf record 采样几秒钟,一般需要加 -g 参数,也就是 call-graph,还需要抓取函数的调用关系。在多核的机器上,还要记得加上 -a 参数,保证获取所有 CPU Core 上的函数运行情况。至于采样数据的多少,在讲解 perf 概念的时候说过,我们可以用 -c 或者 -F 参数来控制。
83 07/08/19 13:56:26 sudo perf record -ag -p 4759
84 07/08/19 13:56:50 ls /tmp/
85 07/08/19 13:57:06 history |tail -16
86 07/08/19 13:57:20 sudo chmod 777 perf.data
87 07/08/19 13:57:33 perf script >out.perf
88 07/08/19 13:59:24 ~/tools/FlameGraph-master/./stackcollapse-perf.pl ~/out.perf >out.folded
89 07/08/19 14:01:01 ~/tools/FlameGraph-master/flamegraph.pl out.folded > kernel-perf.svg
90 07/08/19 14:01:07 ls -lh
91 07/08/19 14:03:33 history
$ sudo perf record -F 99 -a -g -- sleep 60 //-F 99 指采样每秒钟做 99 次
执行这个命令将生成一个 perf.data 文件:
执行sudo perf report -n可以生成报告的预览。
执行sudo perf report -n –stdio可以生成一个详细的报告。
执行sudo perf script可以 dump 出 perf.data 的内容。
# 折叠调用栈
$ FlameGraph/stackcollapse-perf.pl out.perf > out.folded
# 生成火焰图
$ FlameGraph/flamegraph.pl out.folded > out.svg
ECS和perf
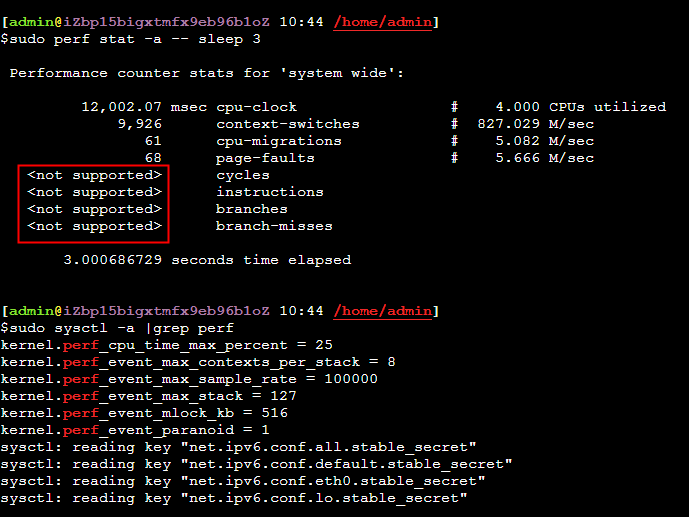
在ECS会采集不到 cycles等,cpu-clock、page-faults都是内核中的软事件,cycles/instructions得采集cpu的PMU数据,ECS采集不到这些PMU数据。
Perf 和 false share cache_line
从4.2kernel开始,perf支持perf c2c (cache 2 cahce) 来监控cache_line的伪共享
系列文章
飞腾ARM芯片(FT2500)的性能测试的性能测试/)
Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的
参考资料
震惊,用了这么多年的 CPU 利用率,其实是错的cpu占用不代表在做事情,可能是stalled,也就是流水线卡顿,但是cpu占用了,实际没事情做。
https://kernel.taobao.org/2019/03/Top-down-Microarchitecture-Analysis-Method/
What Every Programmer Should Know About Main Memory by Ulrich Drepper
How fast are Linux pipes anyway? 优化 pipes 的读写带宽,perf、hugepage、splice使用