https://zhuanlan.zhihu.com/p/490749315复制
影响现代处理器性能的两大关键因素是cache和分支预测,之前的文章介绍过cache的基础知识,现在来介绍分支预测。本文主要介绍分支预测的目的、分支方向的预测方法和分支地址的预测方法,如何检查分支预测是否正确,以及分支预测失败后如何恢复处理器状态,这两个重要问题留给将来的文章解答。
在冯诺依曼的存储指令结构下,指令的执行包含有三种冒险:结构冒险、数据冒险和控制冒险。结构冒险是指硬件部件不足导致指令无法继续执行;数据冒险是指指令所需要的数据受到前面指令的影响,暂时无法取用,从而导致指令无法继续执行;控制冒险是指分支指令在控制程序的过程中中断指令流,从而导致程序无法继续执行。
上面提到的三种冒险对于处理器的性能而言是巨大的威胁,其中结构冒险可以通过添加硬件(如增加存储单元,增加运算单元)来解决,数据冒险可以通过旁路转发技术来部分解决(load-use冒险仍旧没法解决,而且长流水线中旁路转发也不能完全解决load-use之外的数据冒险问题),而分支冒险最难解决。
分支指令有中断指令流的能力,而指令的持续流入是处理器发挥性能的基础。这就像做菜一样,指令就是做菜的原材料,没有原材料,一个厨师的厨艺(对应处理器的运算能力)再高也无法施展。换句话说,指令的吞吐率决定了处理器性能的上限,而分支指令降低了指令的吞吐率,降低了处理器性能的上限,因此控制冒险应该受到所有处理器设计者的重点关注。
遵循量化研究方法的思想,这里用数据来证明上面的说法。假如现在有一个经典五级流水线CPU,它没有分支预测功能,当遇到分支指令时,它停顿分支指令之后的所有流水段,直到分支指令运行到访存段才重新启动流水线。这种情况下每遇到一条分支指令,流水线损失三个周期,即分支指令之后三个周期处理器无法执行完任何一条指令。这样一来,当在一段代码中有20%的指令是分支指令时,处理器CPI从理想状况下的1降低到0.8+0.2*4=1.6,处理器的速度大大地降低了。
根据上一段的计算结果容易发现,如果对分支指令处理得不好,处理器的性能会受到很大影响,因此处理器的设计者们提出用“分支预测”的方法来应对这个问题。
分支预测技术是指处理器在遇到分支指令时不再傻傻地等待分支结果,而是直接在取指阶段预测分支“跳”或者“不跳”以及跳转目标地址,目的是根据预测结果来实现不间断的指令流,从而让处理器的CPI再度接近理想情况中的1 .
从上一段的表述中可以知道,分支预测要预测两件事:分支指令的跳转方向,分支指令的跳转目标地址。这两个信息的预测方法是不一样的,本文会分别介绍两个信息的常规预测方法。
要进行分支预测,就要预测分支跳还是不跳。最朴素的想法是预测一直跳或者一直不跳,这样的方法虽然简单,但是也比完全不预测要高明。完全不预测是100%地要阻断流水线,而预测一直跳或者预测一直不跳还有机会预测对,预测到就是赚到。预想一个1000次的for循环,这个循环前999次都是跳转而最后一次不跳转,如果处理器设置为预测一定跳转,那么在执行这段指令的时候其准确率高达99.9%,性能远远高于不做预测的处理器。
基于量化研究方法的思想,HP在他们的著作中说当前世界上大概有20%的代码是分支指令,其中跳转和不跳转的比例是1:1 。把这个数据代入到上一段说的预测方法中去,处理器的CPI = 0.8 + 0.1 × 1 + 0.1 × 4 = 1.3 ,效果显著优于完全不做预测的机器。
在上面的基础上略加思考,我们发现很多分支指令是有规律的,比如for代码段的最后一条分支指令,这条分支指令绝大部分时间是向后跳转的,而for代码又总是出现,因此提出这么一个方法:向后跳转的分支总是执行,向前跳转的分支总是不执行。这样的假设是基于实际代码情景的,事实证明这样做的效果不错。
静态分支预测的方法虽然比不预测要好,但是性能并不能让人满意。比如预测一定跳转,如果碰到分支指令执行情况为NNNNNN(N表示Not taken,不分支),那么错误率就高达100%,这样的情况是有可能发生的。静态就意味着不灵活,我们需要灵活一些的方法来解决问题,灵活的方法可繁可简,简单的方法就是根据上一次分支指令的执行情况来预测当前分支指令,如果上一次指令不跳转,那么下一次碰到这条指令就预测不跳转,用这个方法来预测NNNNNN的话,正确率可能高达100%,这样的结果让人满意。
根据最后一次结果进行预测确实有一些效果,但是当它碰到TNTNTN这样的情况,正确率又可能会下降到0%,还不如静态预测,静态预测还可能有50%及以上的正确率。
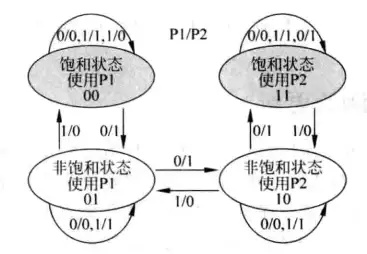
既要满足NNNNNN这样的情况,又要让TNTNTN这样的情况的结果不至于太难看,解决的办法是基于两位饱和计数器的预测。两位饱和计数器用一个状态机来表示,状态机如下图。
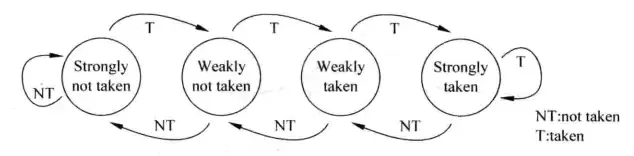
两位饱和计数器包含四个状态:00、01、10、11 。其中00、01表示不跳转,10、11表示跳转。00表示强不跳转,当计数器处于这个状态,分支预测不跳转,如果预测正确,计数器保持计数值,如果预测错误,那么状态转换成01,即弱不跳转,此时仍然预测分支不跳转,如果预测正确,状态转变回00,如果预测错误,状态转变为弱跳转10。在弱跳转10的状态下,分支预测跳转,如果预测正确,状态转变为强跳转11,如果预测错误,状态转变为弱不跳转01.在强跳转11的状态下,分支预测跳转,如果预测正确,状态保持不变,如果预测错误,状态转变为弱跳转10.
上述的两位饱和计数器只是一种预测方法,其他的预测方法包括修改两位计数器的状态转移情况、增大计数器位数,对于两位饱和计数器自身而言,我们也可以通过设置不同的初始状态来区别别的两位饱和计数器。
下图是两种不同的两位计数器。
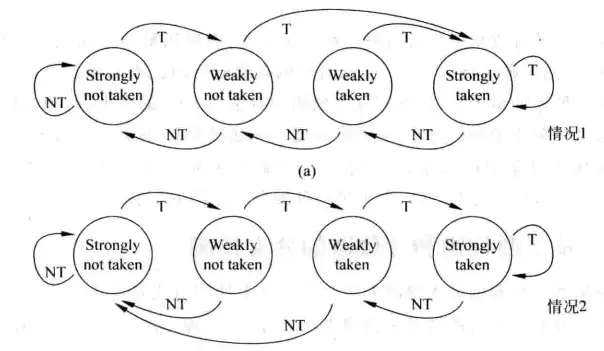
虽然计数器的变种很多,但是事实证明两位饱和计数器是最坚挺的。如果增加计数器的位数,如增加到三位,它在指令分支情况快速变化的情况下表现很不好,同时会迅速增加硬件复杂度和存储资源的消耗。这里要指出一点,两位饱和计数器是针对单条指令的,即每一条分支指令都要有一个独立的两位饱和计数器,因此扩大计数器位数会引起存储量的迅速攀升。而改变两位计数器的状态转移逻辑,其他的情况也不如饱和计数器更加优越,HP在他们的著作中做过测试,两位饱和计数器在测试代码中准确率最高、最稳定。
上文说到“每一条分支指令都要有一个独立的两位饱和计数器”,这并不是自然而然的。其实上文提到的所有预测方法都是基于指令的PC值提出的,因此实际操作中每一条指令都会拥有一个计数器,在32位机器中这就要求存储空间2^{30} * 2 = 2^{31} = 2 Gb = 0.25 GB,这么大的存储空间是没法接受的。
有人也许会提出不要为每条指令都配备一个计数器,只需要在判断指令为分支指令时才配备计数器就好了。这样的做法是比较难实现的,如果这样操作,在硬件实现预测的时候我们就需要用分支指令的PC值和所有的计数器标志位做比较,通过比较才能获取到当前指令的预测情况,而之前“一对一”式的做法就不用这么做,其实这两个做法的对比有点类似cache里面的全相联和直接映射,全相联/全比较的方法消耗巨量的硬件资源,而且严重拖慢运算的速度。
实际设计的时候为了解决上面提出的问题,设计人员提出类似cache直接映射的方法,即多条指令对应一个两位计数器,对应规则使用PC的部分值。
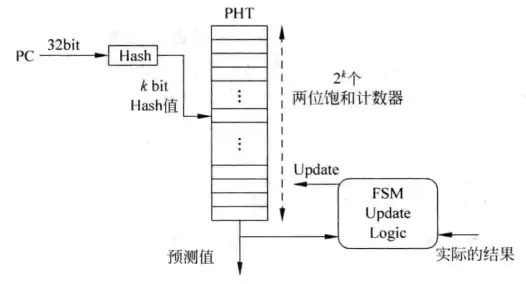
下图是一种解决办法,用PC的部分值来寻址计数器。图中的PHT是指Pattern History Table,即模式历史表,“模式”就是说饱和计数器的状态,PHT类似SRAM结构,里面存有2^{k}个两位饱和计数器供查询使用。图中的FSM update Logic是PHT更新模块,现在不用关心这个模块。

使用上图这种方式的好处是节省了计数器的存储空间,坏处是有可能出现这么一种情况,即多条分支指令同时寻址到一个entry(把PHT中的一个计数器称为一个entry)这种情况被称为“别名”,当多条指令寻址到一个entry,并且它们的实际分支情况互不一样的时候,这个entry的预测结果和更新状况就会变得混乱,这样的情况被称为“破坏性别名”,如果指令之间互不影响,这样的情况被称为“中立别名”。
“破坏性别名”对预测是不利的,需要想个办法来缓解问题。设计人员给出的办法是对整个PC进行变换,如hash(哈希)操作使之转换成k位数值,然后再用k位数值去寻址entry,这样操作之后分支指令再相撞的可能性就会降低,下图是示意图。
缓解的方法不一定要用hash,不同的公司有不同的算法,有的算法可能非常复杂。
以上讲解的是两位饱和计数器的概念和实现方法,在实际操作中两位饱和计数器的正确率可以高达98%,但是再高一点就变得十分困难,因此现代的处理器不会直接使用这种方法。
理论上讲,只要分支指令有规律,就应该可以进行预测,但是基于两位饱和计数器的分支预测方法并不是一个完美的方法,对于很有规律的分支指令两位饱和计数器还是会产生坏结果,考虑下图中的分支指令:
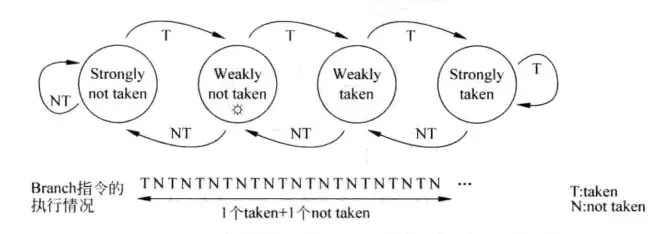
对于上面这条TNTN交替的分支指令,如果两位饱和计数器的初始值定为弱不跳转,那么预测正确率会跌至谷底——0%,如果初始值定为弱跳转,那么正确率是50%,这样的结果是不能接受的,因为这条branch指令明明是很有规律的,让一个小孩来看,他也能100%预测分支结果,因此需要更好的机制来捕捉指令的规律。
设计人员给出的答案是“记录历史”。小孩为什么能预测分支结果?因为他看到了这条指令之前都是跳和不跳交替循环的,所以他判断之后也会继续交替。因此设计人员会想到模拟这一个行动,用一个寄存器来记录一条指令再过去的历史状态,当这个历史状态很有规律时,就可以为分支预测提供一个可以利用的工具,这样的寄存器被称为“分支历史寄存器”,英文是Brach History Register(BHR),这种预测方法称为基于局部历史的预测方法。
对于一条指令而言,通过将它每次的结果移入BHR寄存器,就可以记录这条分支指令的历史状态了,如果这条分支指令很有规律,那么就可以使用BHR寄存器对这条分支指令进行预测,这种分支预测方法的工作机制如下图:
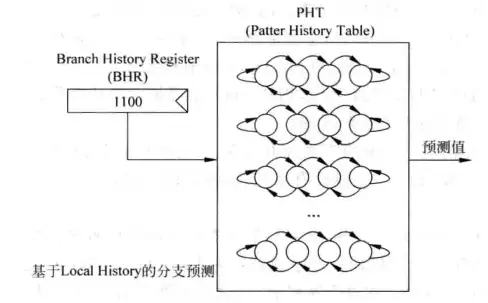
这种方法也被称为自适应的两级分支预测,一个位宽为n的BHR可以记录一条指令过去n次的执行情况,对一个BHR,用多个两位饱和计数器去捕捉规律,因此上图包含一个PHT,这里的PHT和之前不一样,之前的PHT含有全部指令的计数器,而这里的PHT保存的是针对一条指令的多个计数器,这些计数器由BHR寻址,根据BHR的不同可以选出不一样的计数器,从而捕捉到规律,下面举一个例子来说明它究竟是如何工作的:
考虑两位BHR,仍然查看TNTN循环交替的分支指令,在前两次执行情况为TN时,BHR的值为10,寻址第二个计数器,假设这个计数器的初始状态是弱不跳转,那么经过这一次的指令它的状态转换为弱跳转,然后BHR被更新为NT,寻址第一个计数器,假设这个计数器初始状态是弱跳转,那么经过这一次的指令它的状态转换为弱不跳转,继续执行分支,当前BHR指令是TN,再度寻址到第二个计数器,此时它的状态是弱跳转,这一次我们预测成功了,如果继续推演,容易发现接下来的每次预测我们都是正确的。
通过上面这个例子,相信读者已经彻底领悟了这个预测方法的意思。在实现这个方法的时候,还需要考虑一个关键性的参数——BHR的位数。在上面的例子中我们用两位BHR完美实现了预测,但是再观察一下,例子在找寻指令规律的时候实际上只用了两个计数器,即只用了第二个和第一个计数器,两位BHR对应四个计数器,所以还有两个计数器没有用到,这说明在针对这个例子的情况时BHR的位数多了,实际上只需要一位BHR就能实现上面例子的完美预测。那么怎么找到这个能完美预测指令的最小位数呢?《超标量处理器设计》告诉我们在一个有规律的执行序列里,完美的BHR位数就刚好等于序列里最长单数字序列的位数,举个例子,比如001111001111....这个循环例子,其中最长单数字序列是1111,位数为4,也即在这个循环例子里每四个数后面的数都是确定的,所以BHR的最小位数是4,读者如果心有疑虑的话可以用纸笔操演一番。
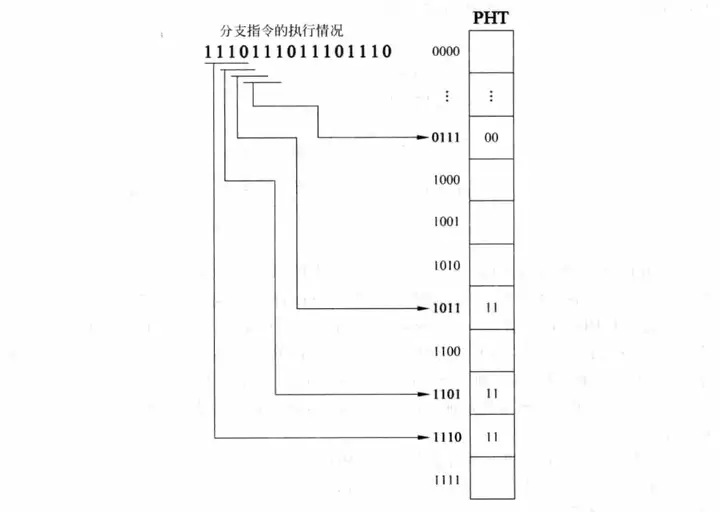
BHR的位数可以很长,只要位数比最长单数字序列的位数要多,BHR就可以完美实现预测。上图就是一个例子,它用了4位BHR来预测,按照上文的说法,这个序列里每三个数后面的数都是确定的,循环位数是三,但是把这个循环变长一点也没关系,用四做循环位数也是可以的。但是要注意,BHR太长会有坏处,BHR越长,需要的PHT就大,而且训练时间也长,训练时间是指从进入分支循环开始到能实现完美预测的时间。
到目前为止这个方法有个隐性的基础,就是每条指令都有属于自己的BHR和PHT,正如2.3节中说的一样,为每条指令都配备一组BHR、PHT太奢侈了,所以设计人员和操作两位饱和计数器方法一样操作本节的方法,下图说明了这一个操作过程:PHTs是多个PHT组合合成的存储单元,我们用PC的一部分来寻址PHT,即找到当前指令对应的模式历史表,然后再用PC的一部分来寻址BHR,即找到当前指令对应的分支历史寄存器,然后根据BHR的值在PHT中找到要使用的那个两位计数器。
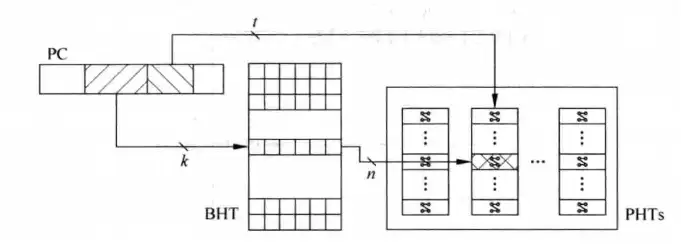
这么操作的优点和缺点和2.3节一样。优点是节省了BHR、PHTs的空间,缺点是使用PC的一部分来寻址容易发生多条指令寻址到同一个BHR或者PHT,如果发生这样的“别名”事件,就容易干扰到正常的预测工作,容易影响到处理器的处理效率。针对这样的情况,可以遵循2.3节的方法,即对PC整体进行hash(哈希)以产生两个比较短的数,用这两个数来寻址BHR、PHT即可以缓解“别名”的问题,这个处理算法根据个人和团队的不同而不同,可以很复杂,也可以很简单。
本节所讲述基于BHR的分支预测方法,由于只考虑被预测的分支指令自身在过去的执行情况,所以称之为基于局部历史的分支预测法。理论上讲,任何一条分支指令,只要它的执行是有规律的,那就可以用这种方法进行预测,但是现实情况是当一条指令的循环周期太大,就需要一个宽度很大的BHR才能实现完美预测,这会导致过长的训练时间,并且PHT也会占用过多的资源,在这真实世界中是无法接受的。比如对于一条跳转99次加不跳转1次的指令,这个方法无法实现完美预测,但是这种方法相比于两位饱和计数器方法已经进步了很多。不过在有些时候,一条分支指令的执行情况不仅和它自身有关,还和它前面的指令的执行情况有关,基于局部历史的预测方法不能捕捉到这种全局的规律,下面一节会讲述解决这个问题的方法。
考虑下面一段代码:
if(aa == 2)
aa = 0;
if(bb == 2)
bb = 0;
if(aa != bb)
cc = 0;复制分析这一段代码,容易发现当第一条、第二条分支指令不执行时(即操作aa = 0、bb = 0),第三条指令一定会执行(即不操作cc = 0),这样的关系用基于局部历史的分支预测方法是永远也发现不了的,因此要引入本节的方法——基于全局历史的分支预测。
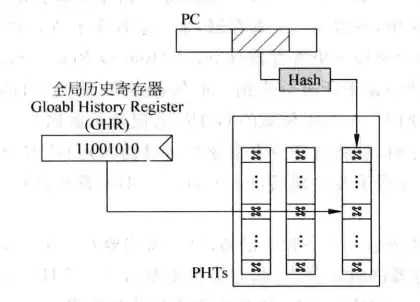
在基于局部历史的分支预测中,我们用很多的BHR来记录各条指令的历史记录,而在基于全局历史的分支预测中,只有一个历史记录寄存器,即Global History Register(GHR),用GHR替代BHR来寻址PHT。
用基于全局历史的预测方法来预测上面的代码:假设循环往复地执行上面的指令,GHR位数为三,那么经过一段时间的训练,GHR为x00时(假设数据从GHR右端移入),即第一条、第二条指令不跳转时,根据GHR寻址得到的两位饱和计数器一定是“跳转”,这时候就捕捉到了分支指令的规律。
下图是实现基于全局历史的分支预测的示意图,其中用PC部分做hash然后寻址的理由和前两节是一样的。
值得注意的是,基于全局历史的分支预测在预测如单条指令为TNTNTN循环的情况时,其表现很可能不如基于局部历史的预测,原因是该条指令对应的PHT可能受到前面分支指令的影响。出现这种问题的原因是不是所有分支指令都适合用全局的视角去看待,在真实世界中有些指令适合基于局部历史,有些指令适合基于全局历史,因此设计人员提出了更激进的预测方法,那就是“竞争的分支预测”。
到目前为止我们学习了“基于局部历史的分支预测”和“基于全局历史的分支预测”,但是实际情况中需要灵活使用两种方法,因此提出“竞争的分支预测”,即让两种方法互相竞争,最终决定对某一条分支指令使用“基于局部”还是“基于全局”。
其实现思想就像两位饱和计数器一样,两位饱和计数器用两位计数器来指示跳或不跳,竞争的分支预测可以使用两位数来指示使用“基于局部”或“基于全局”,使用的寄存器被称为Choice PHT(CPHT)。下图是一种结构图,图中的小圆圈代表对PC做hash等处理,其动作是用PC经过处理值来寻址CPHT,用寻到CPHT来选择一个预测结果。

和两位饱和计数器用状态机来表示状态迁移一样,CPHT同样有状态迁移规则,同样用状态转移图表示。下图中状态转移所用到的信息表示两种方法的预测情况,比如1/0就表示“基于全局”的方法正确,而“基于局部”的方法错误。在这个转移算法中只有一个方法连续错误两次,同时另一个方法连续正确两次,CPHT才会改变预测时选择的方法。
值得注意的是,在上面的实现结构中我们用GHR和PC的综合信息来寻址CPHT,这并不是规定的做法,实际上如何寻址CPHT也是因团队设计而异,不同团队设计的寻址方法不一样,其效果也不一样,而这正是架构师存在的意义。
有些人可能会感到奇怪,不明白为什么需要预测地址。首先明确分支指令大体上有两种,一种是基于PC的直接跳转,一种是基于寄存器值的间接跳转。直接跳转的地址是很明确的,只需要用当前指令PC加4再加上立即数偏移值,在一个五级流水线中,设计人员很可能会把这个计算过程放在取指阶段,因此他们可以在第一个周期就算出跳转地址,因此他们会认为对这种指令的地址预测是没有意义的。这里实际上有问题,首先这么做会加长电路的关键路径,取指令本身是一个消耗时间的事情,而取出指令之后还要加两次加法,路径大大增长,时钟频率可能会因此受到影响,其次是在现代处理器中这么做是会浪费时钟周期的。
现代处理器流水线更长,有可能取指段被分成两段、三段,如果等到指令彻底取出才能得到分支地址,那前面的取指周期就被浪费了,而且取指令是有可能cache miss的,一旦发生cache miss,被浪费的时间会长的夸张。假设一个处理器4发射,10段流水,其中取指段被分成两段,那么按照上面的做法,一旦碰到分支指令,在得到地址计算结果之前我们会少发射四条指令,这样的固定浪费是无法容忍的。
实际上在一段反复执行的程序中,代码的地址是固定的,因此直接跳转指令的跳转地址也就是固定的,如果我们在第一次执行分支指令的时候记录下它的跳转地址,那么当第二次碰到这条指令时,就可以直接根据PC寻找到跳转地址,从而实现“预测”。对于一条间接跳转指令,其跳转地址受寄存器值影响,而寄存器值是动态变化的,因此不好对分支地址做出预测,但是令人安心的是现代指令集不提倡程序员使用这样的分支指令,程序中大部分间接跳转的分支指令是用来处理子程序的CALL和Return指令,而这两种指令的目标地址是有迹可循的,因此可以对其进行预测。
对于直接跳转的分支指令而言,其目标地址有两种:
也即顺序取指和跳转取指。一条分支指令的跳转目标地址是不会改变的,因此可以记录下它的跳转目标地址,一旦执行到该条指令,就寻找记录值,从而实现“预测”。
由于分支预测是基于PC进行的,不可能对每一个PC都记录下它的目标地址,所以一般使用cache的形式,使多个PC共用一个空间来存储目标地址,这个cache被称为Branch Target Buffer(BTB),PC的部分值作为Tag,BTB中存放分支指令的目标地址。因为用cache来实现BTB,所以会出现多条指令的冲突并发生目标地址的更换,而这会影响分支预测的准确度。
为了缓解冲突问题,可以用组相联cache来实现BTB,这么做的代价是增加了设计的复杂度,使BTB占用的硅片面积增大,同时降低BTB访问速度,因此在真实世界中BTB的way个数(即组相联中一组cache line的个数)一般比较少。下图是组相联cache实现BTB的结构示意。

组相联的使用是为了减少指令的冲突,实际上如果代码得当,即使使用直接映射cache也可能不会出现冲突问题。
接下来这一段是《超标量处理器设计》的原文,我对其中的说法有质疑,因此以引用的方式贴出:
一般情况下,为了最大限度地利用BTB中有限的存储资源,只将发生跳转的分支指令对应的目标地址放到BTB中,那些预测不发生跳转的分支指令,它们的目标地址其实就是顺序取指令的地址,因此并不需要进行预测。
我对文段的质疑是即使当前这条指令不跳转,也许下一次执行它就会跳转,如果现在不存入它的跳转目标地址,那么下一次要跳转时在BTB中找不到跳转地址的话就会很麻烦,因此我认为不管直接跳转类型的分支指令是否跳转,我们都应该把跳转地址给记录下来,以备不测。
当一条分支指令的方向是预测发生跳转,而此时BTB发生确实,那么就无法对这条分支指令进行预测,这时候应该怎么办呢?处理器可以采用两种方法来解决这个问题。
方法一:停止执行
当BTB发生缺失,可以暂停流水线的取指令,知道这条分支指令的目标地址被计算出来为止。不同类型的分支指令导致流水线停止的周期数不同,直接跳转类型的分支指令一般可以在解码段获得分支地址,因此只需要停止一个周期,而间接跳转类型的分支指令则可能在访存阶段才算完分支地址,因此向流水线插入的气泡比较多。同时不管是直接跳转还是间接跳转,如果处理器的流水线较长,那么浪费的周期数都会变多。
下图是一个暂停流水线的例子,这个例子中处理器用两个周期来取指,第三个周期计算目标地址,第四个周期才能重新启动流水线。在这个例子中一旦BTB miss,就会浪费两个时钟周期。
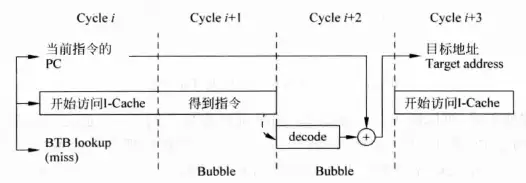
还有更加恐怖的情况,如果I-cache miss,目标地址的计算结果会来得更迟,如果间接跳转指令需要用到之前的ld指令,而ld指令又发生D-cache miss,那目标地址也会大大延迟。
方法二:继续执行
遵循“better later than never”的原则,一旦发生BTB miss,直接选用顺序指令地址继续往下取指,等到后面目标地址计算出来之后再来判断“继续执行”是否正确,虽然大概率继续执行是错误的,但是“better later than never”,万一瞎猫碰着死耗子了呢?不过从功耗的角度来看,这样做是更浪费功耗的,因为采用这种方法需要经常从流水线中抹掉指令,这等于是在做无用功,所以如果是对功耗比较敏感的设计,这种方法并不是一个好的选择。
对于间接跳转类型的分支指令来说,它的目标地址来自于通用寄存器,是经常变化的,所以无法通过BTB对它的目标地址进行准确地预测,所幸的是,大部分间接跳转类型的分支指令都是用来进行子程序调用的CALL/Return指令,而这两种指令是有规律可循的,任何有规律的事情都可以进行预测。
在一般的程序中,CALL指令用来调用子程序,使流水线从子程序中开始取指令执行,而在子程序中,Return指令一般是最后一条指令,它将使流水线从子程序中退出,返回到主程序的CALL指令之后继续执行。对于很多RISC处理器来说,在指令集中可能不存在直接的CALL/Return,而使用其他指令来模拟这一行为。比如MIPS中用JAL模拟CALL,用JR $31来模拟Return,JAL指令会把下一条指令的地址存到31号寄存器,JR指令直接使用31号寄存器的值进行跳转。对于程序中一条指定的CALL,它每次调用的子程序都是固定的,也就是说,一条CALL指令对应的目标地址是固定的,因此可以使用BTB对CALL指令的目标地址进行预测。
CALL指令的跳转地址固定,但是Return指令的跳转地址不固定,比如printf函数,程序中很多地方都可能使用printf函数,因此printf函数的最后一条Return返回的地方是会变化的,因此无法使用BTB对它的目标地址进行预测,但是可以知道,Return指令的目标地址总是等于最近一次执行CALL指令的下一条指令的地址。下图是一个演示。
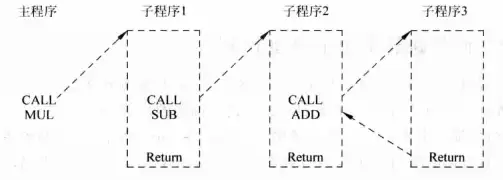
上图所示为一个三级嵌套的子程序调用,每个子程序都调用别的子程序,当执行到子程序3时,它的Return目标地址一定是子程序2中CALL指令的下一指令的地址,同理子程序2的Return目标地址一定是子程序1的CALL指令的下一指令的地址。也就是说,Return指令的目标地址是按照CALL指令执行的相反顺序排列的。
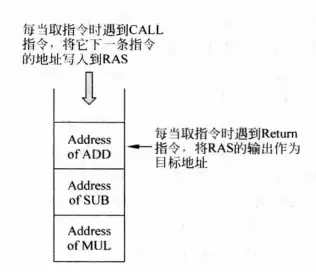
经过上面的分析,Return使用的返回地址就像是堆栈一样,每次调用一个CALL指令,相应的返回地址就被放入堆栈中,在执行Return的时候,总是取用堆栈顶的返回地址。把这个堆栈称为返回地址堆栈(Return Address Stack,RAS),下图是一个示意图,其中MUL、SUB、ADD分别是三条CALL指令之后的指令。
在具体实现这个堆栈时,我们还要处理几个问题,首先看看实现过程示意图:

看一看这个过程:当执行CALL指令时需要把下一条指令的地址存入堆栈顶,CALL指令自己从BTB中取得目标地址;执行Return指令时首先经过BTB,但是BTB中肯定不含有正确的跳转地址,因此需要辨认出当前指令时Return,并从堆栈顶取出返回地址。
通过这个过程就可以看出,要使RAS正确工作,需要如下两个前提条件:
(1)当遇到CALL指令,能够将下一条指令的地址放到RAS中,这需要辨别哪些指令是CALL指令,正常情况下需要到解码段才能知道是否是CALL,在现代处理器采用多个周期取指的情况下这么做太慢了,如果CALL后面很快接着Return指令,那么Return指令可能无法从RAS中取到正确目标地址,这样就造成分支预测失败,影响处理器效率。
如果可以在分支预测时就知道当前指令是否是CALL指令就可以解决这个问题。实现的方法就是在BTB中添加一项,用来标记分支指令的类型,当一条指令被写入BTB时,也会将指令类型(CALL、Return或其他)记录在BTB中,以后再遇到这条分支指令时,通过查询BTB就可以知道它的类型,从而就可以在分支预测阶段识别出CALL指令并把下一条指令的地址存进RAS。
(2)当执行Return指令时,需要能够选择RAS的输出作为目标地址的值,而不是选择BTB的输出,因此仍然需要在分支预测阶段知道指令类型,这可以使用(1)中提到的方法。
到目前为止,RAS可以实现对Return指令的预测,但是还有问题,如果嵌套层数太多,RAS堆栈栈满了怎么办?
有两种方法处理栈满情况:
(1)不对新的CALL指令进行处理,此时不修改RAS,最后执行的CALL指令产生的返回地址被抛弃掉,这样在下一次执行Return指令的时候肯定产生分支预测失败,不仅如此,这种做法还要RAS的指针不能变化,否则会引起后续Return指令无法找到对应返回地址,显然,这是一个比较差的做法。
(2)继续按照顺序写入RAS,此时RAS栈底的内容被覆盖掉,如下图所示,栈顶指针从栈顶指回栈底。

按照这样处理,后面执行的CALL指令都可以正确预测,但是对于最开始CALL指令对应的Return,就会产生不可避免的错误。
再考虑一个情况,如果一个程序是递归的呢?递归程序的返回地址总是一样的,因此没必要让它们占据整个RAS,如果让它们分别占据整个RAS,可能会产生几个坏的后果,一是它们有可能会影响到别的CALL指令的返回地址,二是如果递归层数超过了RAS的深度,那么递归程序在返回的时候就会丢失返回地址,从而造成Return预测失败。为解决这个问题,可以在RAS的地址内容前面增加一个计数器,用来计数该地址会被Return利用几次。这样可以有效解决前面提到的两个问题。
对于间接跳转类型的分支指令,如果它既不是CALL,又不是Return,那该如何预测目标地址呢?从理论上讲这种指令的地址可能性太多,是没办法预测的。虽然在有些很特殊的情况下仍然可以预测,但是出于硬件实现的复杂度考虑,这样发生概率较小的情况应该选择性地不予以优化。
到这里为止,本文对分支指令的方向和目标地址都进行了讲述:使用BHR、GHR和饱和计数器来对分支指令地方向进行预测,并使用BTB、RAS对目标地址进行预测,这些预测都是发生在取指令阶段,并基于PC值来进行的,将这些方法汇总起来就可以对分支指令进行完整的分支预测。
要注意的是,任何预测技术都可能出错,分支预测也不例外,因此需要一套机制对分支预测的正确性进行检查,并在分支预测错误的时候对操作进行撤销(这称为分支预测失败时的恢复),这些内容会是将来相关文章的关注重点。
本文参考了链接里推荐的几本体系结构方向的著作,重点参考了超标量处理器设计。