https://zhuanlan.zhihu.com/p/503257611复制
在 Tomasulo 一文中曾经提到过“寄存器重命名”这个概念。“寄存器重命名”的目的是消除指令间写后写、读后写这两种假数据冒险,在现代处理器中,“寄存器重命名”往往因为其实现的复杂性而被拿出来单独用一个周期(甚至两个周期)来完成。本文接下来会先回顾写后写、读后写两种数据冒险假在何处,然后正式地提出寄存器重命名的三种方式,并对其中“重命名映射表”的具体实现方法进行深入的分析。
一个程序的不同指令之间存在很多的数据相关性,这些相关性主要概括为三类:写后写、读后写、写后读。其中写后写、读后写两种相关是假相关,造成的数据冒险是假冒险。
在顺序发射、顺序执行的流水线处理器中,假冒险是不存在的,因为指令总是顺序执行,所以不存在前序指令在后序指令写回结果之后才写回结果,也不存在前序指令在后序指令写回结果之后才读取源数据。
但是在顺序发射、乱序执行的处理器里,就有可能发生上述两种假冒险——后序指令可能先写回结果,从而导致前序指令读到错误数据,或是前序指令更晚写回,从而导致最终结果出错。
为了避免在乱序执行中出现错误,处理器“必须”能识别两种假冒险,并让发生冒险的指令顺序执行。但这种方法会让乱序执行退化成顺序执行,在一个假数据冒险发生得特别频繁的程序段里,比如 for 累加程序,处理器会顺序地执行所有指令,而这实际上浪费了处理器的性能。
这里让我们审视一下图 1 的指令序列。在 WAW 、 WAR 两种数据冒险中,只要把目的寄存器换名即可消除相关冒险。对于 WAW ,只要把第三条指令的 R3 目的寄存器、第四条指令的 R3 源寄存器改写为 R10 ,就可以消除第一、第三条指令的 WAW 冒险,且程序执行的结果也是正确的。

之所以能这么修改寄存器名字而不改变程序的结果,是因为 WAW 实际上不涉及两个寄存器之间的数据流动——想象一个有向无环图,这两条指令的结果都指向 R3 ,而不指向彼此的源数据,因此这两条指令之间没有上下级,不必要有严格的先后顺序。与之相对应的是 RAW 相关,因为后序指令需要读取前序指令的结果,所以一定要前序指令写回完,后序指令才能取源数据,出现这种情况的原因就是两条指令之间有真正的数据流动。
WAW、WAR这种没有真正数据流动的数据相关就是假相关,对应的数据冒险也是假冒险。
因为 WAW 、 WAR 这种相关实际上不影响指令的并行执行(因为指令没有上下级关系,不必要顺序执行),所以设计人员就要想办法消除这种相关性,解决办法就像 1.1 节演示的一样——修改目的寄存器的名字。
处理器之所以会出现 WAW 、 WAR 冒险,是因为处理器的逻辑寄存器数量不足。执行指令的终极目的是得到执行结果,逻辑寄存器被设计用来暂放执行结果,而像MIPS这样的指令集只规定了32个逻辑寄存器,数量不多,所以在程序执行过程中经常出现指令结果没空闲地方存放的情况,因此需要重用寄存器,从而出现WAW、WAR冒险。
假想处理器拥有无限个逻辑寄存器,那么对每一个新的执行结果,可以用一个新的逻辑寄存器存放,后续的指令读这个新的逻辑寄存器即可,这样一来指令之间就不会出现 RAW 之外的数据冒险。
经过分析,设计人员要做的事情就是为处理器设计出一个“无限大”的逻辑寄存器堆,从而提供重命名的空间。当然了,这个无限大肯定不是真的无限大,就像 cache 也不是真的把内存全部搬到处理器内部,虚拟内存也不是真的让进程占据全部内存空间,为了实现这个看起来无限大的逻辑寄存器堆,我们需要一些技巧。第二节会正式介绍实现拓展寄存器堆、实现重命名的三种方法。不过在此之前,还需要先铺垫一下重命名的逻辑实现方法是什么样的。
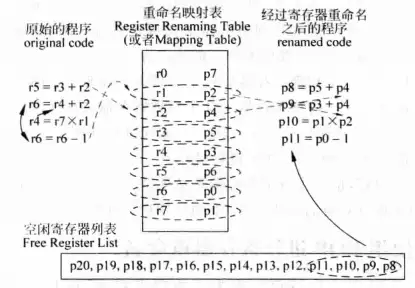
图 2 是一个实现重命名的例子。原始四条指令包含 WAW 和 WAR 冒险,所以需要使用重命名来解决问题。
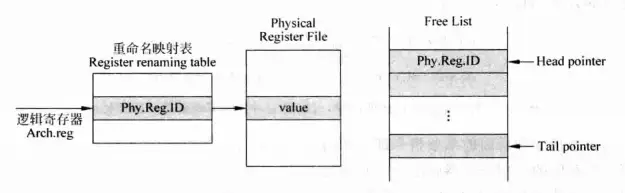
在重命名的过程中,处理器首先根据指令的源寄存器编号查询“重命名映射表”。重命名映射表记录了逻辑寄存器和物理寄存器的对应关系(物理寄存器是一些逻辑寄存器之外的、指令集规定之外的寄存器,设计来实现“无限大”的寄存器堆),这里假设我们拥有21个物理寄存器,指令集规定了8个寄存器,在实现的过程中8个逻辑寄存器被动态地分配到21个物理寄存器中,而重命名映射表就记录了这个映射关系。通过映射结果,指令可以找到源寄存器对应的物理寄存器,从而得到需要的数据。接下来,指令从空闲寄存器列表中找到4个空闲的物理寄存器,用来和指令的目的寄存器建立映射关系。经过这两步操作,指令之间的假相关就被消除了。
接下来第二节将介绍三种实现这个重命名过程的方法。
对于寄存器重命名,概括起来,有三种方式可以实现它,这三种方式分别是:
接下来将依次介绍这三种方法。
在 ROB 一文中提到过 ROB (重排序缓冲)起到了物理寄存器的效果,其每一个表项都可以作为物理寄存器。图3显示了一个案例。
当 LD(load) 指令被发射到ROB中, LD 指令就占据了 ROB 的第一行表项,获得了 #1 这个编号的使用权,并且会用 #1 这个编号与逻辑寄存器建立映射关系(见最下面的寄存器结果状态表)。图中 F6 逻辑寄存器被 #1 标记,表明 F6 逻辑寄存器的值实际上保存在 #1 物理寄存器中,不过这个值现在还没有计算出来。当后序指令的源寄存器是 F6 时,指令就不会从 F6 逻辑寄存器取值,因为它可以通过映射表“看到”F6 现在由 #1 暂代。这样的效果就和图 2 一样,处理器通过 ROB 表项编号来和逻辑寄存器建立重命名映射表,再通过发射指令到 ROB 的空闲行来模拟从空闲寄存器列表(见图 2 )中查找空闲物理寄存器的过程。
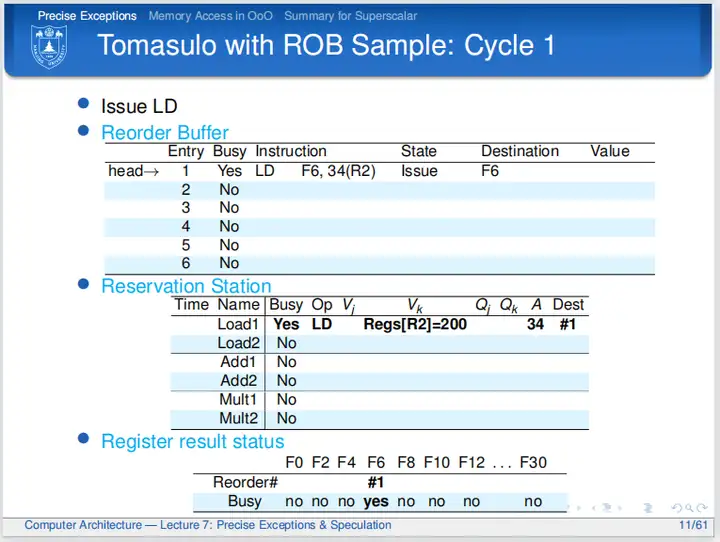
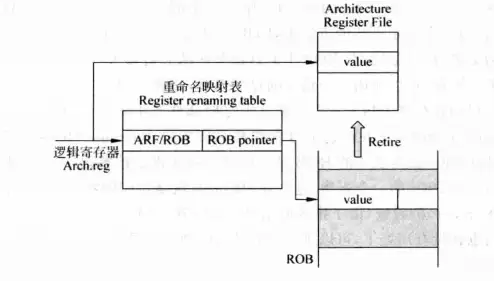
图 4 是一个结构上的演示:指令在发射到 ROB 和保留站的时候,查询寄存器结果状态表(也即重命名映射表),来获知自己的源数据是在逻辑寄存器堆中还是在 ROB 中,如果在 ROB 中,重命名映射表建立的映射关系会取得物理寄存器的编号,另外,在一条指令成为 ROB 中最老的指令且已经执行完毕时,指令的结果就可以从 ROB 的物理寄存器中写回到逻辑寄存器堆(即完成指令提交),此时ROB会空出一个表项,即释放出一个空闲的物理寄存器。
从上面的分析可以看出ROB确实实现了物理寄存器和寄存器重命名,但是ROB实现方法有其内在的缺点。
首先每一条指令都会占据ROB一个表项,但是不是每一条指令都有目的寄存器。如果一条没有目的寄存器的指令被发射到ROB中,那就相当于浪费了一个物理寄存器。
其次,对于一条指令而言,它即可能在逻辑寄存器堆中取数,也可能在ROB中取数,这就需要ROB也支持多端口读,对于一个4发射的处理器而言,这就要求ROB实现8个读端口,这对芯片的面积和延时造成了很大的影响。
总的来说,基于ROB的重命名实现虽然优缺点,但是胜在实现方法简单,相应的设计复杂度不高,因此可以获得不错的性能。市场上有不少处理器采用这种方法。
这种方法是对ROB方法的改进,在物理结构上比ROB更贴近图2的逻辑实现结构。实现方法就是在逻辑寄存器堆、ROB之外设计一组物理寄存器(PR),当存在目的寄存器的指令被解码之后,指令就会占据PRF中的一个空闲的物理寄存器,并把这个编号和目的寄存器之间的对应关系写进重命名映射表;等到指令执行完毕之后,执行结果就会写回到物理寄存器中;等到指可以提交,这条指令的结果被搬移到逻辑寄存器堆(ARF),然后物理寄存器被解放。
和ROB实现的乱序执行一样,如果PRF没有空闲的寄存器,那后序指令就不可以发射,重命名之前的流水段会被暂停,直到前序指令提交完结果并解放物理寄存器位置。
图5是相关的结构示意。可以看到这个结构和ROB没什么不同,只不过物理寄存器堆脱离了ROB。
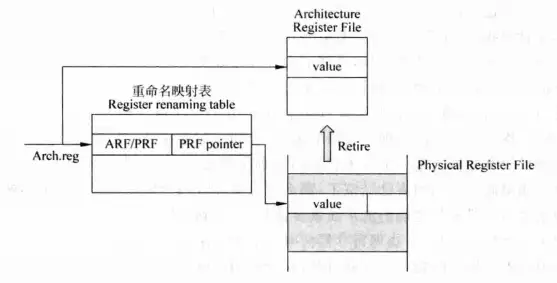
在第一、第二种方法中,物理寄存器堆总是和逻辑寄存器堆分离,这会造成一个问题——有寄存器被浪费了。因为逻辑寄存器一旦被重命名,处理器就会为其找到一个物理寄存器来存放数据,此时这个逻辑寄存器存放的值就是无用的数据,但这个数据还是占用了存储空间,即对应的逻辑寄存器这段时间没有存储有效数据,其存储空间被浪费了。
而使用统一的PRF进行重命名的方法,则把PRF和ARF混合在一起,处理器不会规定哪几个寄存器是逻辑寄存器,而是直接设计一堆寄存器,其中的每一个寄存器都可能成为逻辑寄存器。
在这种设计中,使用一个重命名映射表来表明寄存器的状况。在映射表榜上有名的,就是被当作了逻辑寄存器,而没有映射关系的寄存器都是处于空闲状态的物理寄存器,其编号都被存在空闲寄存器列表中。
当一条指令发射时,指令根据映射表找到源寄存器、获取数据,然后查询空闲列表并占据一个空闲的物理寄存器,并把占据的信息写进映射表。空闲列表可以用一个FIFO来实现,当空闲列表空了,就说明此时物理寄存器已经全部被占用,流水线重命名阶段之前的流水线就要被暂停,直到有指令提交并释放物理寄存器为止。图6是一个结构的演示。
故事还没有结束。映射表内每一个逻辑寄存器只能对应一个物理寄存器,这是毋庸置疑的,因为如果一个逻辑寄存器对应多个物理寄存器的话,后序指令会找不到自己需要的源数据。因此,当多个指令写同一个逻辑寄存器时,前序指令的映射关系就必须被后序指令覆盖。这样一来当程序员要查看处理器状态时,他就可能看到错误的映射表——因为存在这么一种情况:后序指令还没有提交,而前序指令提交了,此时程序员若要看逻辑寄存器的话就应该看前序指令当时映射的物理寄存器,但是这个信息已经被后序指令覆盖。为了解决这个问题,设计人员设计了第二个映射表,这个映射表只记录已经提交的指令的寄存器映射关系,这样当程序员要看处理器状态时就可以把第二个映射表展示给他。
这里还有一个问题,就是当多条指令写一个逻辑寄存器时,后序指令会覆盖前序指令的寄存器映射关系,即消除掉前序指令目的寄存器和物理寄存器之间的对应关系,那前序指令在提交的时候怎么知道结果该提交到那个物理寄存器中呢?这个问题由ROB解决。在指令重命名之后,指令进入ROB和发射队列中,此时指令会把目的寄存器映射信息存入ROB,这样当指令执行完毕时,根据ROB的信息,指令就知道自己该把结果写进哪一个物理寄存器。
上面这一段表述暗示了一个事实:对于前序指令,其映射关系被覆盖不意味着其对应的物理寄存器被释放。看一下下面这段代码:
add r1, r2, r3
add r4, r1, r5
add r1, r6, r7复制第一第三条指令都要写r1,因此第一条指令的映射关系会被第三条抹除,但是第二条还需要得到第一条指令的结果(这个结果会根据ROB保存的信息写回到原始映射关系中的物理寄存器),因此在第二条指令读到这个物理寄存器的结果之前,该物理寄存器还不能释放,即不能进入空闲列表,不能被其他逻辑寄存器使用。那么该寄存器何时释放呢?显然,在第三条指令执行完毕之后,后序指令不再需要第一条指令的结果,此时该寄存器就可以释放了。用一个更加普适的表述就是:当有相同目的寄存器的后序指令提交时,前序指令映射的物理寄存器就可以被释放。
怎么做到这一点?这需要指令在进入ROB的时候不仅记录自己的映射关系,还要记录目的寄存器之前的映射关系,如上面的代码段在执行第三条指令时,就应该记录下第一条指令的r1映射关系,等到第三条指令提交时,就根据记录的信息释放第一条指令映射的物理寄存器。
至此,基于统一PRF的实现方法解读完毕。使用这个方法有两个优点:
因为基于统一PRF进行重命名的方法具有上述优势,很多优秀的处理器,如MIPS R10000、Alpha 21264,都采用了这种方法。
在第2节说明的三种重命名方法中,都使用了重命名映射表这一数据结构。映射表负责记录逻辑寄存器和对应物理寄存器(如第2节所言,这可能是ROB表项,也可能是独立的物理寄存器)。当指令进入重命名阶段,指令会查询映射表以找到源寄存器对应的物理寄存器的编号,从而获得源数据;当指令存在目的寄存器时,指令查询空闲寄存器列表以获得空闲物理寄存器编号,并把目的逻辑寄存器映射到对应空闲物理寄存器中,这个映射关系会写入到映射表。实现过程可以回顾1.2节的结尾,这里再展示一次重命名的实现过程示意:
这个表格在具体物理实现方式上有两种方法:一是基于SRAM,二是基于CAM(content-addressable memory,内容可寻址存储器)。
宏观地说,基于SRAM的映射表速度快,资源消耗小(在大部分时间),而基于CAM的映射表速度慢,资源消耗大(尤其是当物理寄存器很多的时候),但是基于CAM的映射表更利于机器恢复状态(当分支指令执行错误的时候,需要恢复机器状态到错误路径之前的状态,而恢复状态需要恢复映射表,一般使用checkpoint方法实现,checkpoint后文会详细讲解),因此基于SRAM的映射表并不一定比基于CAM的更好。实际上,在Alpha21264这种高性能单核中,映射表就是由CAM组成的,其目的就是为了用更少的资源和更快的速度恢复机器状态。
接下来的两小节会详细讨论这两种方法。
假设指令集设计有32个逻辑寄存器,而处理器实际设置64个物理寄存器,那么基于SRAM的映射表就有32行,每一行对应一个逻辑寄存器,其长度log2(64)=6个比特。
当指令要查询映射表,就译码源寄存器编号,根据译码结果选通SRAM的某两行(假设每周期只有一条指令进行重命名,每条指令有两个源寄存器),然后获得SRAM的数据,该数据应该是一个6位的物理寄存器编号(64个物理寄存器需要6位寻址),根据此6位寄存器编号,就可以寻址到逻辑寄存器映射到的物理寄存器。
图7是一个示意图,sRAT的意思就是基于SRAM的映射表,Arch.Reg是逻辑寄存器,Phy.Reg.ID是物理寄存器编号。

基于SRAM的映射表是很好理解的,而且我们都知道SRAM速度快,优点突出,但是基于SRAM的映射表不利于机器处理分支错误,为什么这么说?
当处理器发射分支错误,我们需要把机器恢复到正确执行路径上,为此需要把映射表恢复到分支指令刚进入重命名阶段的那个时刻的状态,为此我们需要为映射表制作备份,以供恢复的时候使用,这个备份就是checkpoint。
在基于SRAM的映射表中,每个checkpoint都是一整个映射表,即每多存在一个checkpoint,就多一个32行每行6位的SRAM。当分支出现错误,就直接把checkpoint的信息全部复制到映射表中。图8是一个多checkpoint的映射表的示意图。
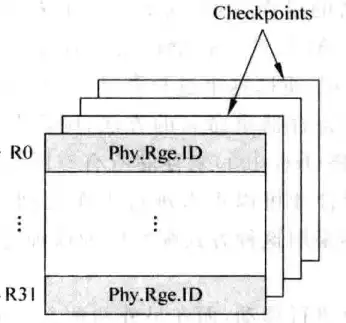
值得注意的是,在程序执行的过程中,分支可能是嵌套的,即分支中还有分支,因此checkpoint几乎不会只有一个,因此在基于SRAM的映射表中,机器需要多个和映射表一模一样的checkpoint,而维持大容量的checkpoint的消耗是巨大的(不仅是面积,而且功耗消耗也大),机器不可能保证太多checkpoint(之后会看到基于CAM的映射表可以做到这一点),另外,把checkpoint的值复制到映射表中,这个速度也比较慢,因此基于SRAM的映射表面临着checkpoint少、分支错误时处理速度慢的问题。
用这种方式实现的映射表和基于SRAM的映射表有很大的区别,虽然也是使用逻辑寄存器编号来寻址物理寄存器,但是它是内容寻址的,什么是内容寻址?让我们举一个例子。
一个地下党来到南京火车站站台,站台现在有二十个同志,其中有三个同志带来了三份不一样的情报,而地下党此时需要其中某一份,他现在有两种方法拿到情报:
以上例子中的第二种方法就是内容寻址。下面继续用这个例子来说明SRAM和CAM方法的区别:
在这个类比之中,“站台上的所有同志”就是物理寄存器,而“前来交换情报的同志”就是逻辑寄存器。
在基于SRAM的映射表中,映射表的行数等于逻辑寄存器的个数,机器会根据译码信息(显然,选通SRAM的时候使用的是独热码)选通其中一行,拿到对应逻辑寄存器的映射信息。
而在基于CAM的映射表中,映射表的行数等于物理寄存器的个数,映射表每一行都保存有一个有效位和一串编号,编号对应逻辑寄存器的编号,当指令的源寄存器编号来临,机器会用源寄存器编号和映射表的每一行做对比,如果和某一行的对比结果显示“相等”且该行数据有效,则说明该行和逻辑寄存器有映射关系,该行在映射表中的编号就是逻辑寄存器对应的物理寄存器的编号。
图9是基于CAM的映射表的一个结构示意图。暂时不用管GC0、GC1这些信息(这些信息保存的是有效位V)。cRAT的意思就是基于CAM的映射表。
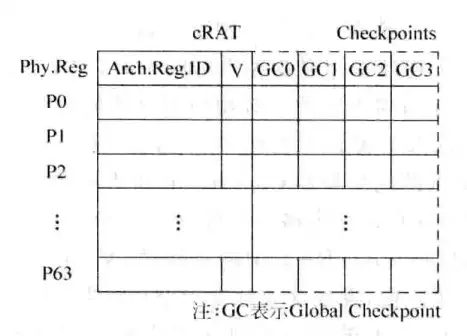
图10是基于CAM的映射表的物理实现方法。在物理实现基于CAM的映射表时,首先用SRAM保存信息,当指令进入重命名阶段,机器用源寄存器编号和SRAM的每一行信息做对比(对应图中的CAM0、CAM1.....),通过比较电路的结果和有效位V,就可以确定逻辑寄存器对应的物理寄存器编号。
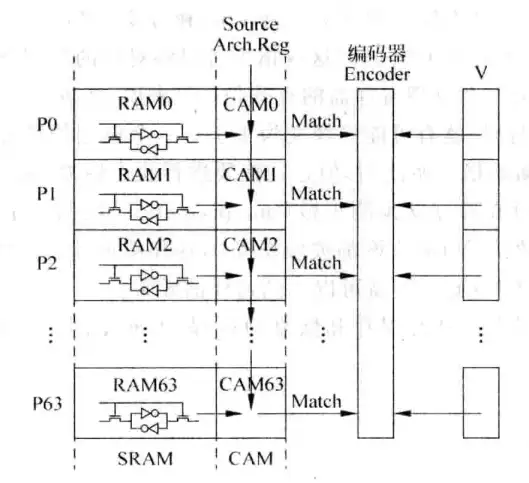
可以看到在这种方法中,实现映射表所花费的资源变多了。同样是32个逻辑寄存器和64个物理寄存器,SRAM方法只需要32行,而CAM方法则需要64行,且CAM方法需要大量的比较电路,这会显著降低机器的速度(大量比较电路会给源寄存器编号加大电路负载,从而拖慢充电速度),所以前文说SRAM比CAM更加优越。
3.2节末尾提到的“优越”只针对“查询”,在用checkpoint恢复机器状态时CAM表现出优秀的性能,为什么?
在SRAM方法中要恢复映射表状态,需要事先把分支指令来临时刻的映射表全份拷贝下来,然后在恢复时把备份复制回映射表,这使得在checkpoint数量增加的时候备份消耗的资源线性增加。
而在CAM方法中要恢复映射表关系,只需要保存分支指令来临时刻映射表的有效位状态,然后在恢复的时候把有效位置回,这使得在CAM方法中增加checkpoint数量是一件不费力的事情,alpha21264通过CAM方法实现了80个checkpoint,这在SRAM方法中是不可想象的。
为什么CAM只需要保存有效位信息?假想以下指令序列:
A: addi r5, r0, 1
B: addi r7, r0, 2
C: addi r6, r7, 3
D: add r7, r7, r1
E: add r7, r7, r2
F: beq r7, r3, TARGET1
G: add r9, r5, r6
H: add r7, r9, r8复制上面的汇编程序在基于CAM的映射表进行重命名时,执行过程是这样的:
(1)分支指令F在重命名时,需要进行checkpoint保存机器状态,此时映射表的内容如下图所示:
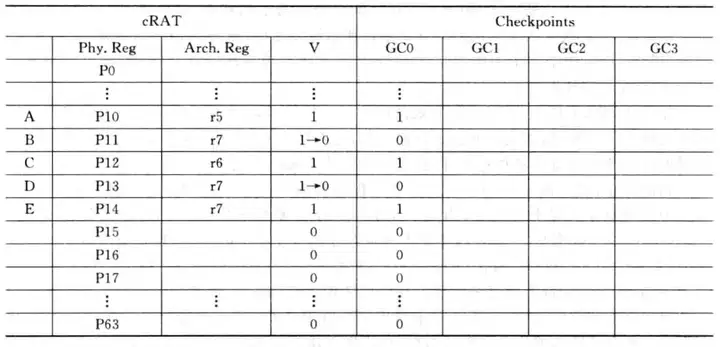
其中B、D的V显示1->0,在实际实现中这两位肯定是0,这里写1->0是想说明这两条指令还没有提交(这个信息体现在ROB和空闲寄存器列表中,这里没有显示,所以写0->1),因此P11、P13这两个对应的物理寄存器尚处在不能解放的状态,即P11、P13的映射关系不能被改写。
(2)在G、H指令重命名之后,机器发现分支预测错误,需要恢复机器状态,在恢复状态之前,映射表的内如如下:
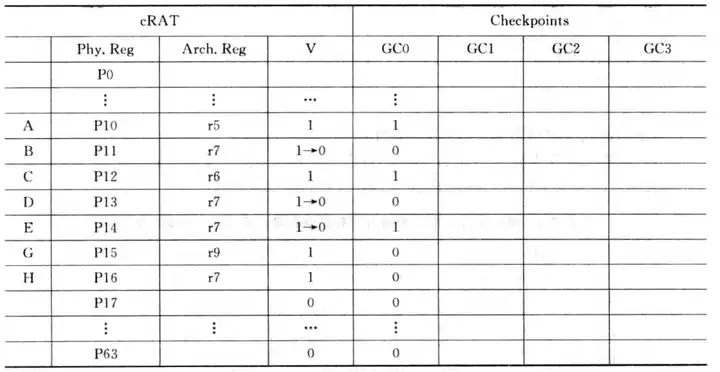
(3)在恢复映射表时,机器会将上图中的GC0复制到映射表的有效位V中,这样就可以恢复到分支指令F刚进入重命名阶段时的状态。
值得注意的是,此时P11、P13和(1)中一样是0,但是含义已经不一样。(1)中虽然V=0,但是BD指令没有提交,所以这两个物理寄存器不能释放,即没有进入空闲列表;但是在(3)中BD指令已经提交(假设机器的顺序提交的机器,那么当发现F指令预测错误且要处理错误信息时,BD大概率已经被提交掉),所以P11、P13已经是释放状态,可以被其他的逻辑寄存器占用。虽然这两个0含义不一样,但是不会导致程序出错。
这里可能有人会有疑虑,可能会假想这么一种情况:F指令之后的指令修改了P14的映射关系,而只恢复V不能置回P14的信息。实际上这是不可能的,时刻记得机器是一个顺序提交的机器,在分支指令F提交时,E指令之后的一切指令都没有提交,所以P14的有效位虽然可能被改写为0,但是它不会进入空闲列表,所以P14的映射关系不会被改写。
总结一下,CAM方法用checkpoint恢复机器状态时只需要恢复有效位V,而不需要恢复其他内容,SRAM方法则需要复制整个SRAM,这导致虽然SRAM方法在查询映射表时即快速又节约资源(SRAM行数等于逻辑寄存器个数,而CAM行数等于物理寄存器个数),但是在处理分支错误的时候慢于CAM方法,且上限也远低于CAM方法(能容纳的checkpoint少于CAM方法)。在实现映射表时选用哪种方法是一件值得设计人员权衡的事情。
在要求高性能的现代处理器中,寄存器重命名是一项重要,甚至是不可或缺的技术,本文主要讲解了寄存器重命名的概念、提出背景(消除假数据冒险)、逻辑实现方法(ROB、拓展ARF、统一ARF)和重命名映射表的实现方法(SRAM方法、CAM方法)。阅读本文时要重点理解重命名映射表、空闲列表的概念,和寄存器重命名的执行过程,另外,理解第3节的方法有助于加深对计算机微体系结构的理解。
本文大部分内容参考自姚永斌老师的《超标量处理器设计》。