https://zhuanlan.zhihu.com/p/507619114复制
记分牌和Tomasulo算法通过拷贝数据到保留站、广播计算结果和寄存器重命名等方法实现了计算指令的乱序执行,但是这两个算法均不涉及存储指令(load和store)。实际上,在一个乱序核中执行存储指令还需要一套独立的机制/方法。本文会介绍三种处理存储指令方法,这三种方法的性能和复杂度是递增的。
和对寄存器进行操作的的指令所遇到的困难一样,存储指令间也存在三种数据冒险——写后读、写后写、读后写。访问寄存器的指令可以通过寄存器重命名的方法来消除假冒险,并且可以通过旁路、阻塞和插入气泡等方式来处理写后读冒险,但是对存储指令而言,事情没这么简单。
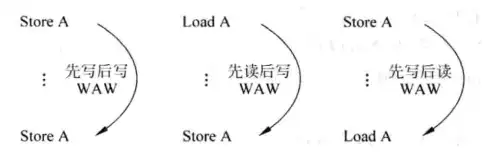
在RISC中,存储指令一般通过寄存器间接寻址的方式访问存储器,因此在地址计算出来之前,机器不知道存储指令将访问哪部分主存——这区别于访问寄存器,当指令只涉及寄存器时,在指令解码阶段机器就可以获知所有寄存器编号,从而为后续重命名、旁路、阻塞等操作做准备。
看下面这个例子,只有当ST和LD指令的目的地址不一样的时候,这两条指令才不存在写后读冒险,但目的地址在执行阶段之前是得不到的,因此当两条指令发生冒险,机器没法在发射阶段阻塞load指令(因为机器没有指令的目的地址,它不知道load实际上发生冒险了),只能任由load发射、执行,然后出错。

换句话说,因为存储指令的相关性隐藏得很深,机器没办法预先掌握存储指令之间的相关性,因此无法像处理计算指令一样处理存储指令。本文接下来会介绍三种处理存储指令的方法,第一种方法按程序顺序执行存储指令,而第二第三种方法则可以乱序执行部分/全部load指令。
在这种方法中,load和store指令完全按照程序顺序执行。这是一种最保守的做法,可以保证指令之间不发生冒险,但是这样会牺牲处理器的性能。
load和store指令起效果的时间点不一样,load指令的结果在执行结束的时候就可以获得,而store指令实际上要到提交的时刻才可以把数据存入到存储器,因此如果要完全按顺序执行,(在比较恶劣的情况下)load指令必须等到前面的store指令提交完才能发射,而且store指令有可能写空,如果数据块不在cache内,store就可能要把数据块从主存中调入cache,然后写入,这个过程是极漫长的。
因为“完全顺序执行”牺牲了指令的并行性,让指令付出了不必要的等待,所以顺序执行虽然省事,但是效果很不好,高性能的处理器核是不会使用这种方法的。
这种方法让store指令顺序执行,store和store之间的load指令乱序执行。下图是一个例子,指令A和E之间的BCD三条指令可以在A指令提交之后乱序执行。

这个方法的过程:
这里有一个问题,指令E是否可以在BCD指令没有发射完的情况下发射?
如果允许E在BCD之前发射,那么FG就可以和BCD一起被乱序地发射,但是这会带来另一个问题。如果AE同时存在于store buffer之中,那么BCD在查询store buffer的时候,就不仅要查看是否有和自己地址相同的store指令,还要查看同址指令是否是自己的前序指令——显然的,即使E指令和BCD指令的地址相同,也不会发生写后读冒险。
因此如果允许E提前发射,就要给各条指令附加年龄信息,以表明指令的先后顺序。这里先举一个例子,以演示“部分乱序”的过程。

在上图中,load指令计算完地址之后会拿着load addr查询store queue(也即store buffer),同时还会去访问D-cache;如果store queue中有同址指令,且“age比较模块”显示该指令比自己老,那么机器会根据match信号选出store buffer中的数据(即value)作为data out;如果store指令的数据还没到位,那就输出wait信号,表示load需要等待store的数据。
记录上面例子中的age信息有三种方法供选择:
在实际操作中,后面两种方法是可以使用的,但是比较复杂。 更简单的方法是禁止E指令越过前面的load指令。这样store buffer中就只存在前序的store指令,load在检查store buffer的时候只会碰到前序store,这样就不用标记彼此的年龄。但是这个方法显然会降低处理器的性能,没有很好地利用指令的并行性。
这里的全乱序指的是load全乱序,store仍是顺序的。在这种方法中load指令无需等待任何store指令,只要load自己的数据准备好,就可以发射出去。
很显然,这么做是会产生写后读冒险的,即store指令还没发射,load指令就已经发射、读数。如何解决这个问题?
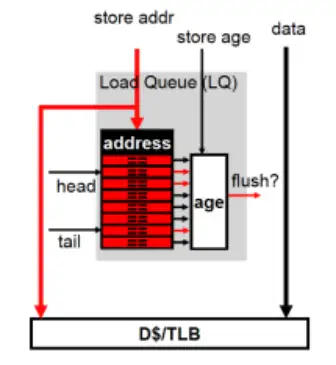
可以在执行单元中增加一个load buffer,其中储存着所有已经发射的load指令和其目的地址。当store指令发射,它会去查询load buffer,如果发现load buffer中有同址load指令,且该指令比自己年轻,那就说明该指令已经读取到错误的信息了,这种情况很麻烦,需要特别处理。
当store在load buffer中发现错误的load指令,因为指令的结果可能已经被后序计算指令使用,所以流水线在这个时候可能已经存有很多错误的结果。这个时候最简单的办法是立刻暂停执行段之前的流水线,然后继续执行store,等到store指令提交,就把store指令之后的所有指令(即ROB中的所有指令)都清除掉(同时还需要恢复处理器的状态,如寄存器映射表,因此对于store指令,也需要保存checkpoint,checkpoint的介绍见寄存器重命名),然后重新取指。Alpha 21264处理器把这称为排空流水线。
下图是store查询load buffer的结构示意。store指令在计算完地址之后会拿着store addr查询load queue(即store buffer),综合age信息之后,如果发现有load指令出错,机器会输出一个flush信号,即表示需要冲刷流水线(排空流水线)。
如果频繁地排空流水线,那处理器的效率就大大地降低了,因此我们不能让这种错误频繁出现。怎么做?
Alpha 21264使用load预测的方法来减少错误。什么是load预测?即预测一条load指令是否会和前序store指令发生读后写冒险,如果预测为“会发生冒险”,则该load指令就不会被唤醒电路从发射队列中唤醒,也就不会被发射到执行单元。
为什么可以这么做?load预测的依据是什么?其实在一个固定的程序里,store和load的关系是固定的,load不会无缘无故地取数,有时候load是去取我们事先存在主存中的数,而有时候load指令是去取刚刚store指令存进主存的数,一旦一条load指令去取了之前store存进主存的数据,那么之后它很有可能会继续这么干,因此可以用一个数据结构保存这个信息,只有当load指令被预测为“与前序store指令无关”,load指令才被允许唤醒、发射。
下面是Alpha 21264在load/store部分的微结构,用这个微结构来说明如何实现load预测。重点关注D-cache1和D-cache2,D-cache1段供load/store指令互相检查buffer,以及从cache中取数,D-cache2则进行tag比较,确定是否cache hit,另外,注意到Tag Compare有一条线连到一个叫做Wait Table的结构,这个结构是做什么用的?

这个Wait Table记录了load指令的预测信息。一旦发现一条load和前序store发生写后读冒险,机器就会在D-cache2段把这个错误指令的信息写进Wait Table;当一条load指令解码时,处理器会查询这个Table,并把Table中的预测信息附加到流水线中,当load指令等待发射,机器会检查这个附加信息,如果附加信息显示该指令“会发生写后读冒险”,那么处理器就不会发射该指令,直到该指令的所有前序store都发射完毕。
故事告一段落,上面主要讲解了如何解决load优先store发射所产生的问题。如果load指令老老实实地在store指令之后发射,那么事情就简单了。只需要load指令在发射之后查询store buffer,如果发现有同址store指令,就把该指令的数据取过来,而不去读D-cache,这个做法就是第三节所说的load forwarding。
这里我们再总结一下“全乱序”方法是如何高效、正确地执行load/store的:
本文讲解了处理load/store指令的三种常规方法,介绍了load buffer、store buffer、load forwarding、load 预测、Wait Table和排空流水线等概念。通过这些概念和记分牌、Tomasulo等乱序执行算法,我们可以正确、高效地执行大部分指令。