简介#
一般来说,想检查磁盘I/O情况,可以使用iostat、iotop、sar等,但这些命令只能做一个整体的了解,没法具体到某一次io的详细情况,而今天介绍的blktrace就可以深入到Linux I/O栈的方方面面,把一切都搞得明明白白的!
Linux内核I/O栈#
先了解下Linux内核I/O栈,一般来说,我们对网络协议栈比较熟悉,比如网络协议分了5层,每一层都是干什么的,但对于I/O栈,则了解相对较少,如下: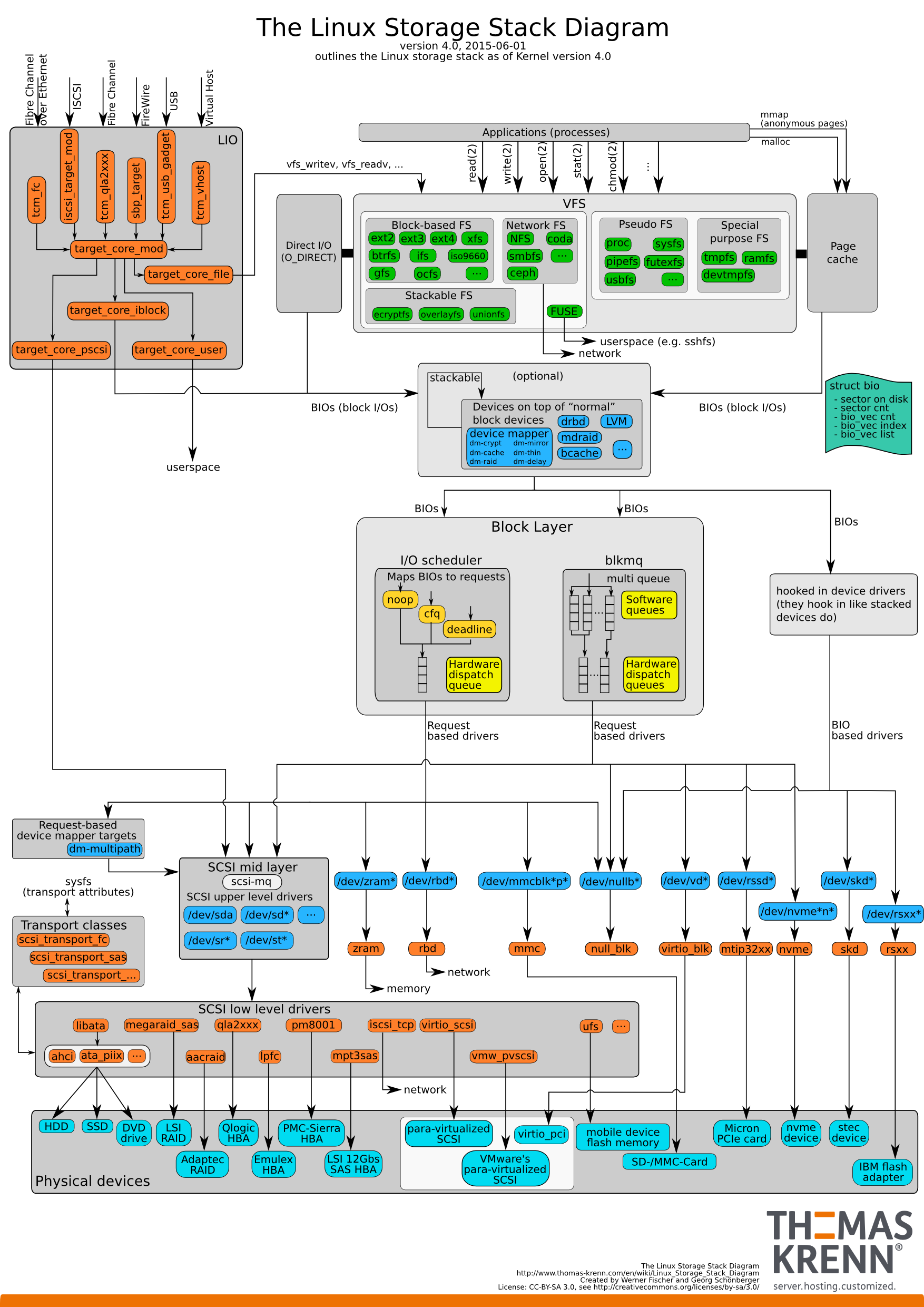
Linux内核I/O栈大概分了6层,如下:
- 文件系统层
提供了open、read、write等文件操作的系统调用给应用程序使用,并且Linux提供了文件系统的统一抽象vfs,使得Linux中可适配各种类型的文件系统,如ext4、btrfs、zfs、fat32、ntfs等,而我们常说的磁盘格式化,实际上就是在安装文件系统,重新写入相关文件系统的初始元数据信息到磁盘。 - 卷管理层
比如我们常听到的Device Mapper、LVM、soft raid就属于这一层,用于将多个磁盘合为一个,或将一个磁盘拆分为多个。 - 块存储层
这一层主要实现io调度逻辑,比如将一个大io请求拆分为多个小的io请求,将相邻的io请求合并,实现各种io调度算法等,常见io调度算法有CFQ、NOOP、Deadline、AS。 - 存储驱动层
每一个硬件都需要驱动程序,硬盘也不例外,如常听到的SCSI、ACHI、NVME等,且如/dev/sda这样的设备抽象文件,也由这一层实现。 - 硬件层
硬件层就是具体的硬盘实物了,但我们经常听到ATA、SATA、SCSI、PCIe、SAS等这样的名词,这是不同的硬盘接口规范,就像手机充电线有Type-A、Type-B、Type-C一样。
blktrace相关概念#
blktrace跟踪在块存储层(包括卷管理层),它的使用方法如下: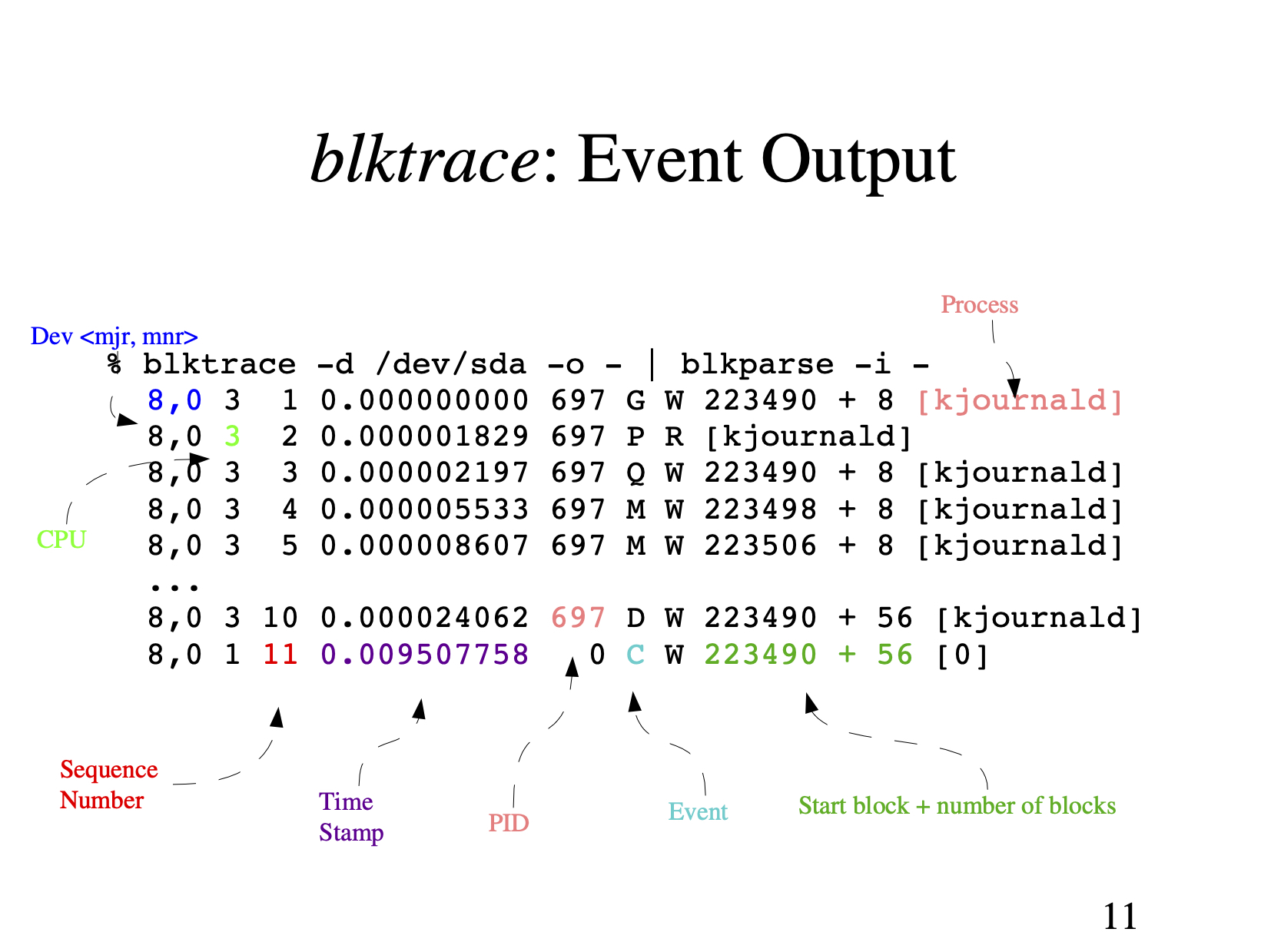
- 第一个字段:8,0 这个字段是设备号 major device ID 和 minor device ID。
- 第二个字段:3 表示 CPU
- 第三个字段:11 序列号
- 第四个字段:0.009507758 Time Stamp 是时间偏移
- 第五个字段:PID 本次 I/O 对应的进程 ID
- 第六个字段:Event,这个字段非常重要,反映了 I/O 进行到了哪一步
- 第七个字段:R 表示 Read, W 是 Write,D 表示 block,B 表示 Barrier Operation
- 第八个字段:223490+56,表示的是起始 block number 和 number of blocks,即我们常说的Offset 和 Size
- 第九个字段:进程名
其中第六个字段表示I/O事件,它代表了 I/O 请求进行到了哪一阶段,有如下这些事件:
- A : remap 对于栈式设备,进来的 I/O 将被重新映射到 I/O 栈中的具体设备。
- X : split 对于做了 Raid 或进行了 device mapper(dm) 的设备,进来的 I/O 可能需要切割,然后发送给不同的设备。
- Q : queued I/O 进入 block layer,将要被 request 代码处理(即将生成 I/O 请求)。
- G : get request I/O 请求(request)生成,为 I/O 分配一个 request 结构体。
- M : back merge 之前已经存在的 I/O request 的终止 block 号,和该 I/O 的起始 block 号一致,就会合并,也就是向后合并。
- F : front merge 之前已经存在的 I/O request 的起始 block 号,和该 I/O 的终止 block 号一致,就会合并,也就是向前合并。
- I : inserted I/O 请求被插入到 I/O scheduler 队列。
- S : sleep 没有可用的 request 结构体,也就是 I/O 满了,只能等待有 request 结构体完成释放。
- P : plug 当一个 I/O 入队一个空队列时,Linux 会锁住这个队列,不处理该 I/O,这样做是为了等待一会,看有没有新的 I/O 进来,可以合并。
- U : unplug 当队列中已经有 I/O request 时,会放开这个队列,准备向磁盘驱动发送该 I/O。这个动作的触发条件是:超时(plug 的时候,会设置超时时间);或者是有一些 I/O 在队列中(多于 1 个 I/O)。
- D : issued I/O 将会被传送给磁盘驱动程序处理。
- C : complete I/O 处理被磁盘处理完成。
这些Event中常见的出现顺序如下:
Q – 即将生成 I/O 请求
|
G – I/O 请求生成
|
I – I/O 请求进入 I/O Scheduler 队列
|
D – I/O 请求进入 Driver
|
C – I/O 请求执行完毕
复制由于每个Event都有出现的时间戳,根据这个时间戳就可以计算出 I/O 请求在每个阶段所消耗的时间,比如从Q事件到C事件的时间叫Q2C,那么常见阶段称呼如下:
Q------------>G----------------->I----------------------------------->D----------------------------------->C
|-Q time(Q2G)-|-Insert time(G2I)-|------schduler wait time(I2D)-------|--------driver,disk time(D2C)-------|
|------------------------------- await time in iostat output(Q2C) -----------------------------------------|
复制- Q2G – 生成 I/O 请求所消耗的时间,包括 remap 和 split 的时间;
- G2I – I/O 请求进入 I/O Scheduler 所消耗的时间,包括 merge 的时间;
- I2D – I/O 请求在 I/O Scheduler 中等待的时间,可以作为 I/O Scheduler 性能的指标;
- D2C – I/O 请求在 Driver 和硬件上所消耗的时间,可以作为硬件性能的指标;
- Q2C – 整个 I/O 请求所消耗的时间(Q2I + G2I + I2D + D2C = Q2C),相当于 iostat 的 await。
- Q2Q – 2个 I/O 请求的间隔时间。
ok,了解了这些关键概念后,就可以看懂blktrace命令的输出结果了,继续往下看...
blktrace用法#
安装blktrace#
# 安装blktrace包
$ sudo apt install blktrace
# blktrace依赖debugfs,需要挂载它
$ sudo mount -t debugfs debugfs /sys/kernel/debug
复制blktrace包安装后有blktrace、blkparse、btt、blkiomon这4个命令,其中blktrace负责采集I/O事件数据,blkparse负责将每一个I/O事件数据解析为纯文本方便阅读,btt、blkiomon负责统计分析。
实时查看#
$ sudo blktrace -d /dev/sda -o - | blkparse -i - 8,0 3 1 0.000000000 3064475 A W 367809144 + 8 <- (8,1) 367807096 8,0 3 2 0.000001498 3064475 Q W 367809144 + 8 [kworker/u256:3] 8,0 3 3 0.000013880 3064475 G W 367809144 + 8 [kworker/u256:3]^C复制
先采集后分析#
# 采集io事件数据
$ sudo blktrace -d /dev/sda
^C=== sda ===
CPU 0: 477 events, 23 KiB data
CPU 1: 1089 events, 52 KiB data
CPU 2: 216 events, 11 KiB data
CPU 3: 122 events, 6 KiB data
Total: 1904 events (dropped 0), 90 KiB data
# 数据保存在sda.blktrace.<cpu>中,每个cpu一个文件
$ ls -l *blktrace*
-rw-r--r-- 1 root root 22928 2022-02-12 16:11:37 sda.blktrace.0
-rw-r--r-- 1 root root 52304 2022-02-12 16:11:37 sda.blktrace.1
-rw-r--r-- 1 root root 10408 2022-02-12 16:11:37 sda.blktrace.2
-rw-r--r-- 1 root root 5864 2022-02-12 16:11:37 sda.blktrace.3
# 查看I/O事件
$ blkparse -i sda
8,0 3 1 0.000000000 3064475 A W 367809144 + 8 <- (8,1) 367807096
8,0 3 2 0.000001498 3064475 Q W 367809144 + 8 [kworker/u256:3]
8,0 3 3 0.000013880 3064475 G W 367809144 + 8 [kworker/u256:3]
8,0 3 4 0.000016012 3064475 P N [kworker/u256:3]
8,0 3 5 0.000025289 3064475 A W 367809136 + 8 <- (8,1) 367807088
8,0 3 6 0.000025867 3064475 Q W 367809136 + 8 [kworker/u256:3]
...
Total (sda):
Reads Queued: 14, 220KiB Writes Queued: 299, 1556KiB
Read Dispatches: 14, 220KiB Write Dispatches: 213, 1556KiB
Reads Requeued: 0 Writes Requeued: 0
Reads Completed: 14, 220KiB Writes Completed: 213, 1556KiB
Read Merges: 0, 0KiB Write Merges: 86, 348KiB
IO unplugs: 34 Timer unplugs: 39
Throughput (R/W): 4KiB/s / 30KiB/s
Events (sda): 1766 entries
Skips: 0 forward (0 - 0.0%)
复制由于I/O事件通常很多,一个个的分析并不容易,因此一般使用btt来进行统计分析。
btt#
- 首先需要使用blkparse将blktrace采集到的多个文件合并为一个,如下:
# 先合并为一个文件
$ blkparse -i sda -d sda.blktrace.bin
$ ll sda.blktrace.bin
-rw-rw-r-- 1 work work 90K 2022-02-12 16:12:56 sda.blktrace.bin
复制- 然后使用btt分析sda.blktrace.bin,如下:
$ btt -i sda.blktrace.bin
==================== All Devices ====================
ALL MIN AVG MAX N
--------------- ------------- ------------- ------------- -----------
Q2Q 0.000000410 0.165743313 5.193234517 312
Q2G 0.000000297 0.000169175 0.004261675 227
G2I 0.000000341 0.000023664 0.000284838 225
Q2M 0.000000108 0.000000336 0.000002798 86
I2D 0.000000716 0.000708445 0.003329311 227
M2D 0.000004063 0.000106955 0.000737934 84
D2C 0.000111877 0.000718769 0.004067916 313
Q2C 0.000134521 0.001402772 0.008234969 313
==================== Device Overhead ====================
DEV | Q2G G2I Q2M I2D D2C
---------- | --------- --------- --------- --------- ---------
( 8, 0) | 8.7464% 1.2126% 0.0066% 36.6269% 51.2391%
---------- | --------- --------- --------- --------- ---------
Overall | 8.7464% 1.2126% 0.0066% 36.6269% 51.2391%
==================== Device Merge Information ====================
DEV | #Q #D Ratio | BLKmin BLKavg BLKmax Total
---------- | -------- -------- ------- | -------- -------- -------- --------
( 8, 0) | 313 227 1.4 | 8 15 200 3552
==================== Device Q2Q Seek Information ====================
DEV | NSEEKS MEAN MEDIAN | MODE
---------- | --------------- --------------- --------------- | ---------------
( 8, 0) | 313 24620107.8 0 | 0(94)
---------- | --------------- --------------- --------------- | ---------------
Overall | NSEEKS MEAN MEDIAN | MODE
Average | 313 24620107.8 0 | 0(94)
==================== Device D2D Seek Information ====================
DEV | NSEEKS MEAN MEDIAN | MODE
---------- | --------------- --------------- --------------- | ---------------
( 8, 0) | 227 35300234.0 0 | 0(10) 8
---------- | --------------- --------------- --------------- | ---------------
Overall | NSEEKS MEAN MEDIAN | MODE
Average | 227 35300234.0 0 | 0(10)
...(more)
复制注意这里面的D2C与Q2C,D2C代表硬盘实际处理时间,不包含在I/O队列中的等待时间,而Q2C代表整个I/O在块层的处理时间。
可以看到上面Q2C(IO处理时间)平均耗时1.402ms,最大8.234ms,D2C(硬盘处理时间)平均耗时0.718ms,最大4.076ms,而旋转磁盘耗时一般在几毫秒到十几毫秒,所以这个磁盘表现正常,但如果D2C经常到100ms以上,则可能磁盘损坏了,需要尽快更换磁盘。
如果要检测磁盘情况,还有一些简便的工具,如ioping或fio等,如下:
$ ioping .
4 KiB <<< . (ext4 /dev/sda1): request=1 time=307.9 us (warmup)
4 KiB <<< . (ext4 /dev/sda1): request=5 time=818.9 us
4 KiB <<< . (ext4 /dev/sda1): request=6 time=381.2 us
4 KiB <<< . (ext4 /dev/sda1): request=7 time=825.4 us (slow)
4 KiB <<< . (ext4 /dev/sda1): request=8 time=791.7 us
4 KiB <<< . (ext4 /dev/sda1): request=11 time=837.8 us (slow)
4 KiB <<< . (ext4 /dev/sda1): request=12 time=815.6 us
...
^C
--- . (ext4 /dev/sda1) ioping statistics ---
23 requests completed in 17.0 ms, 92 KiB read, 1.35 k iops, 5.28 MiB/s
generated 24 requests in 24.0 s, 96 KiB, 1 iops, 4.00 KiB/s
min/avg/max/mdev = 381.2 us / 739.2 us / 842.7 us / 151.3 us
复制可以发现平均响应时间也在739.2us,和上面blktrace的结果基本一致。
blkiomon#
blkiomon也能分析I/O事件,对设备/dev/sda的io监控120秒,每2秒显示一次,如下:
$ sudo blktrace /dev/sda -a issue -a complete -w 120 -o - | blkiomon -I 2 -h -
time: Sat Feb 12 16:37:25 2022
device: 8,0
sizes read (bytes): num 0, min -1, max 0, sum 0, squ 0, avg 0.0, var 0.0
sizes write (bytes): num 2, min 4096, max 24576, sum 28672, squ 620756992, avg 14336.0, var 104857600.0
d2c read (usec): num 0, min -1, max 0, sum 0, squ 0, avg 0.0, var 0.0
d2c write (usec): num 2, min 659, max 731, sum 1390, squ 968642, avg 695.0, var 1296.0
throughput read (bytes/msec): num 0, min -1, max 0, sum 0, squ 0, avg 0.0, var 0.0
throughput write (bytes/msec): num 2, min 6215, max 33619, sum 39834, squ 1168863386, avg 19917.0, var 187744804.0
sizes histogram (bytes):
0: 0 1024: 0 2048: 0 4096: 1
8192: 0 16384: 0 32768: 1 65536: 0
131072: 0 262144: 0 524288: 0 1048576: 0
2097152: 0 4194304: 0 8388608: 0 > 8388608: 0
d2c histogram (usec):
0: 0 8: 0 16: 0 32: 0
64: 0 128: 0 256: 0 512: 0
1024: 2 2048: 0 4096: 0 8192: 0
16384: 0 32768: 0 65536: 0 131072: 0
262144: 0 524288: 0 1048576: 0 2097152: 0
4194304: 0 8388608: 0 16777216: 0 33554432: 0
>33554432: 0
bidirectional requests: 0
复制其它#
另外,发现一大佬基于blkparse写了一个shell脚本来分析I/O事件数据,如下:
========
summary:
========
total number of reads: 1081513
total number of writes: 0
slowest read : 0.032560 second
slowest write: 0.000000 second
reads
> 1ms: 18253
>10ms: 17058
>20ms: 17045
>30ms: 780
writes
> 1ms: 0
>10ms: 0
>20ms: 0
>30ms: 0
block size: Read Count
256: 93756
64: 98084
56: 7475
8: 101218
48: 15889
40: 21693
24: 37787
128: 97382
16: 399850
复制可以很方便地看到I/O请求耗时分布、I/O请求大小分布,具体脚本可去其博客页面 http://linuxperf.com/?p=227 获取。
本系列文章索引
Linux命令拾遗-入门篇
Linux命令拾遗-文本处理篇
Linux命令拾遗-软件资源观测
Linux命令拾遗-硬件资源观测
Linux命令拾遗-剖析工具
Linux命令拾遗-动态追踪工具
Linux命令拾遗-理解系统负载
Linux命令拾遗-top中的%nice是啥
Linux命令拾遗-网络抓包工具
Linux命令拾遗-查看系统信息
Linux命令拾遗-常用的辅助开发类命令
Linux命令拾遗-%iowait指标代表了什么
往期内容#
字符编码解惑
hex,base64,urlencode编码方案对比
mysql的timestamp会存在时区问题?
真正理解可重复读事务隔离级别
不容易自己琢磨出来的正则表达式用法