简介#
上次解决了GC长耗时问题后,系统果然平稳了许多,这是之前的文章《GC耗时高,原因竟是服务流量小?》
然而,过了一段时间,我检查GC日志时,又发现了一个GC问题,如下: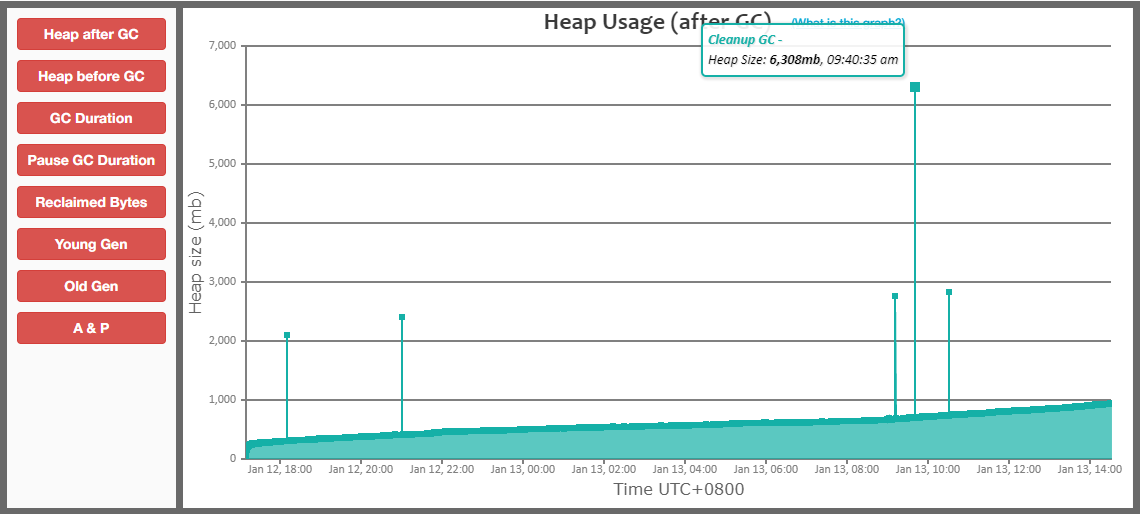
从这个图中可以发现,我们GC有一些尖峰,有时会突然有大量的内存分配。
查看GC日志,发现有大对象分配的记录,如下:
$ grep 'concurrent humongous allocation' gc.log | awk 'match($0,/allocation request: (\w+) bytes/,a){print a[1]}' |sort -nr
1941835784
1889656848
复制
可以看到,一次大对象分配,分配大小竟然有1.9G,这谁能抗得住啊!
async-profiler定位大对象分配#
上面提到的文章介绍过,使用async-profiler可以很容易的定位大对象分配的调用栈,方法如下:
./profiler.sh start --all-user -e G1CollectedHeap::humongous_obj_allocate -f ./humongous.jfr jps复制
然后使用jmc打开humongous.jfr文件,调用栈如下: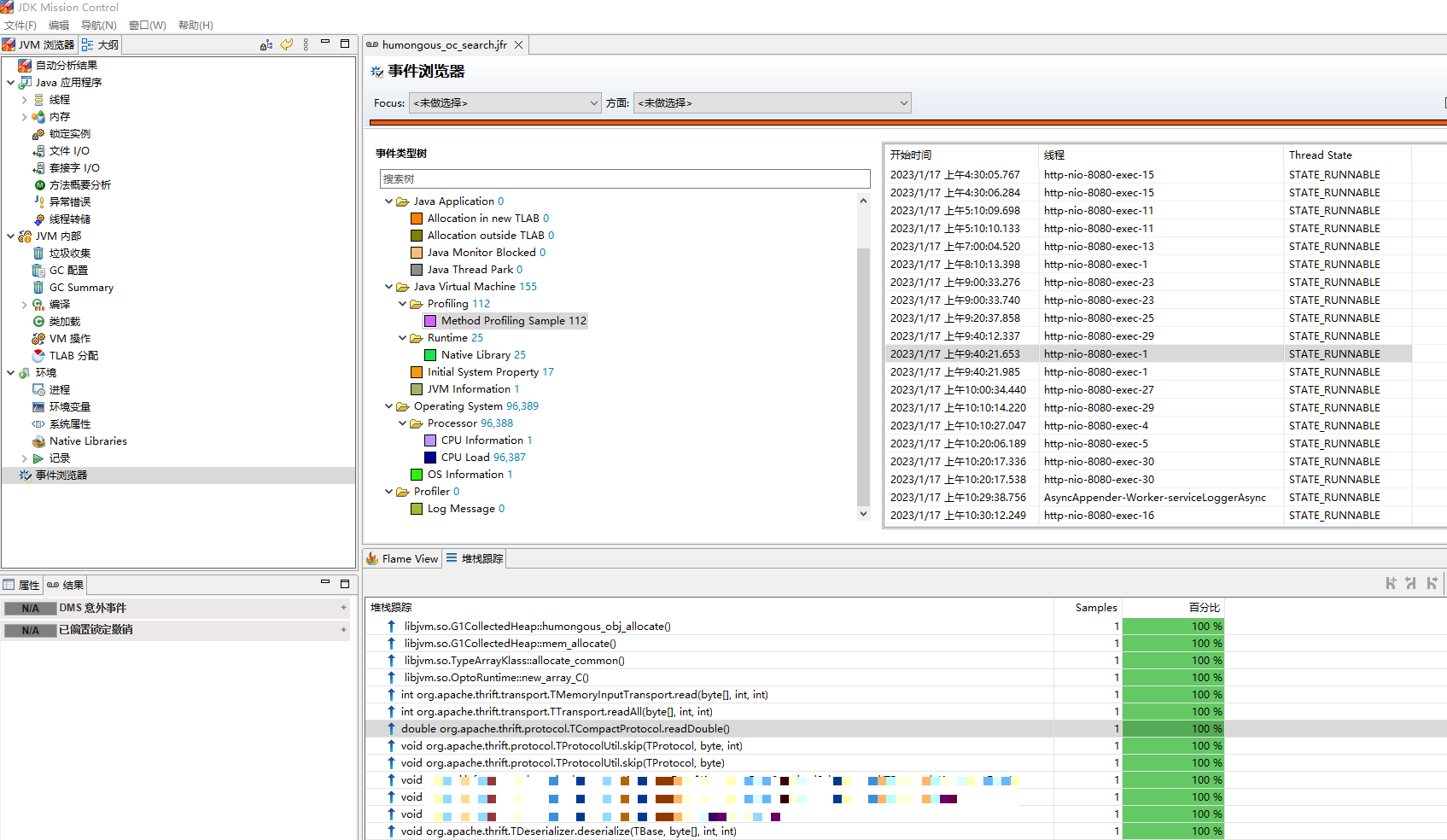
这是在做thrift反序列化操作,调用了TCompactProtocol.readDouble方法,方法代码如下: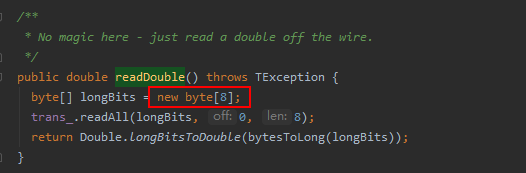
可是,这里只创建了8字节的数组,怎么也不可能需要分配1.9G内存吧,真是奇了怪了!
经过一番了解,这是因为async-profiler是通过AsyncGetCallTrace来获取调用栈的,而AsyncGetCallTrace获取的栈有时是不准的,Java社区有反馈过这个问题,至今未解决。
问题链接:https://bugs.openjdk.org/browse/JDK-8178287
寻找其它tracer#
linux上有很多内核态的tracer,如perf、bcc、systemtap,但它们都需要root权限,而我是不可能申请到这个权限的😔
在用户态上,基于ptrace系统调用实现的有strace、ltrace,我试了一下它们,并无法直接跟踪G1中的大对象分配函数G1CollectedHeap::humongous_obj_allocate。
我也在网上搜索了好几天,希望找到一个有用的纯用户态tracer,但可惜几天都没找到,最后,我只能将目标放在c/c++的调试工具gdb上,我想gdb既然是一个调试工具,那它必然能够查看指定函数的调用参数与调用栈,只要找到相应用法即可!
编写gdb脚本#
经过一番学习与探索(PS:其实花了我快2周😂),我终于编写出了实际可用的gdb脚本,如下:
handle all nostop noprint pass
handle SIGINT stop print nopass
break *(_ZN15G1CollectedHeap22humongous_obj_allocateEmh + 0x58c06f - 0x58c060)
while 1
continue
# 如果是Ctrl+c,则退出
if $_siginfo
if $_siginfo.si_signo == 2
detach
quit
end
end
printf "word_size is %d\n",$rsi
if $rsi > 100*1024*1024/8
# 打印当前时间
shell date +%FT%T
# 打印当前线程
thread
# 打印当前调用栈
bt
python import subprocess
# 向jvm发送kill -3信号,即SIGQUIT信号
python proc = subprocess.Popen(['kill','-3',str(gdb.selected_inferior().pid)], stdout=subprocess.PIPE, stderr=subprocess.PIPE, bufsize=1, universal_newlines=True)
python stdout, stderr = proc.communicate()
python print(stdout)
python print(stderr)
detach
quit
end
end
复制没学过gdb的同学可能看不明白,没关系,我们慢慢来。
handle all nostop noprint pass
handle SIGINT stop print nopass
复制这2句handle是处理Linux信号用的,由于我们并不需要调试信号问题,所以让gdb都不处理信号,保留SIGINT是为了按Ctrl+c时能退出gdb脚本。
break *(_ZN15G1CollectedHeap22humongous_obj_allocateEmh + 0x58c06f - 0x58c060)
复制这个break是给G1中的大对象分配函数G1CollectedHeap::humongous_obj_allocate设置断点,方法源码如下: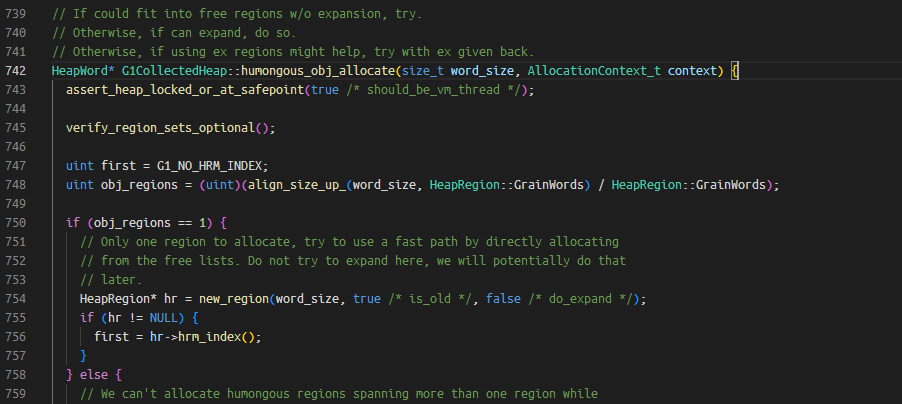
word_size参数表示分配多少字的内存,而在64位机器上,1字等于8字节,所以如果能追踪到这个参数值,就能知道每次分配大对象的大小了。
由于JVM是使用C++写的,而C++编译会做函数名改写(mangle)以兼容C的ABI,所以编译后的函数名就变成了奇奇怪怪的_ZN15G1CollectedHeap22humongous_obj_allocateEmh,通过nm查询二进制文件的符号表,可以获取这个名称。
$ which java
/usr/local/jdk/jdk1.8.0_202/bin/java
# jvm相关实现,都在libjvm.so动态库中
$ find /usr/local/jdk/jdk1.8.0_202 | grep libjvm.so
/usr/local/jdk/jdk1.8.0_202/jre/lib/amd64/server/libjvm.so
$ nm /usr/local/jdk/jdk1.8.0_202/jre/lib/amd64/server/libjvm.so |grep humongous_obj_allocate
000000000058c060 t _ZN15G1CollectedHeap22humongous_obj_allocateEmh
000000000058b1a0 t _ZN15G1CollectedHeap41humongous_obj_allocate_initialize_regionsEjjmh
复制再看回之前设置断点的脚本代码:
break *(_ZN15G1CollectedHeap22humongous_obj_allocateEmh + 0x58c06f - 0x58c060)
复制+ 0x58c06f - 0x58c060这个是在做地址偏移操作,了解过汇编的同学应该清楚,调用函数后,函数开头的一些汇编指令,一般是参数寄存器的相关操作,x86参数寄存器如下:
rdi 表示第一个参数
rsi 表示第二个参数
rdx 表示第三个参数
rcx 表示第四个参数
r8 表示第五个参数
r9 表示第六个参数
复制可以使用objdump反汇编libjvm.so,看看汇编代码,以确定断点该偏移到哪一行指令上,看官们坚持住,汇编相关内容就下面一点😁
$ objdump -d /usr/local/jdk/jdk1.8.0_202/jre/lib/amd64/server/libjvm.so |less -S
复制然后在less里面搜索_ZN15G1CollectedHeap22humongous_obj_allocateEmh函数,如下:
之所以要加偏移量,是因为在+ 0x58c06f - 0x58c060这个位置后,rsi寄存器(第二个参数)才会有值,之所以获取每二个参数的值,是因为C++对象编程中,第一个参数是this。
然后后面的逻辑就好理解了,如下:
首先是循环,然后continue表示让程序运行起来,当程序命中断点后,continue才会执行完。
中间是信号处理,主要是为了能Ctrl+c退出循环。
最后通过print将rsi的值打印出来,这样就追踪到了word_size参数的值。
再然后是打印线程与调用栈信息,如下:
当分配内存大于100M时,打印当前时间、当前线程与当前调用栈。
但gdb的bt命令打印的调用栈是这样子的,如下: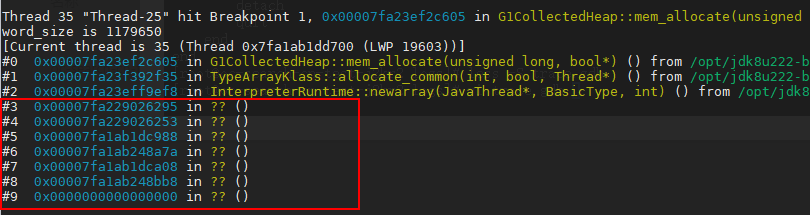
因为Java是解释执行的,java部分的调用栈bt是获取不到的。
没有java调用栈,这个追踪脚本就瘸了呀,我在这里卡了好久,也尝试了许多种方法🤣
对java比较熟悉的同学应该知道,jvm有一个隐藏的诊断功能,如果给jvm进程发SIGQUIT信号,jvm会在标准输出中打印线程栈信息,而SIGQUIT信号可以通过kill -3发送,因此就有了下面的代码: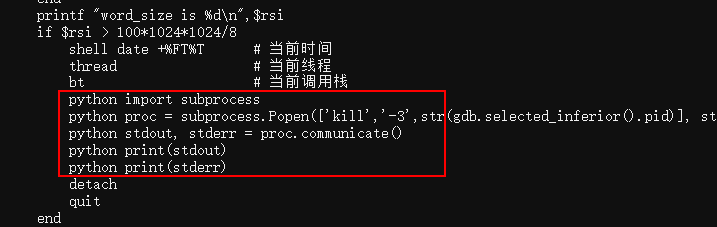
gdb真是强大,内嵌了python扩展,而通过python的subprocess包,就可以执行kill -3命令了。
后面的detach与quit,用于退出gdb的,不用深究。
运行gdb脚本追踪大对象#
把上面的gdb脚本命名为trace.gdb,然后就可以使用gdb命令运行它了,如下:
$ gdb -q --batch -x trace.gdb -p `pgrep java`复制
其中pgrep java用于获取java进程的进程号。
注:gdb本质上是基于ptrace系统调用的调试器,断点命中时对进程有不小切换开销,所以这种方式只能追踪调用频次不高的函数。
运行后,追踪到的参数与线程信息如下:
其中LWP后面的166就是线程号,转成十六进制就是0xa6。
然后到java进程的标准输出日志中,去找这个线程的Java调用栈,如下: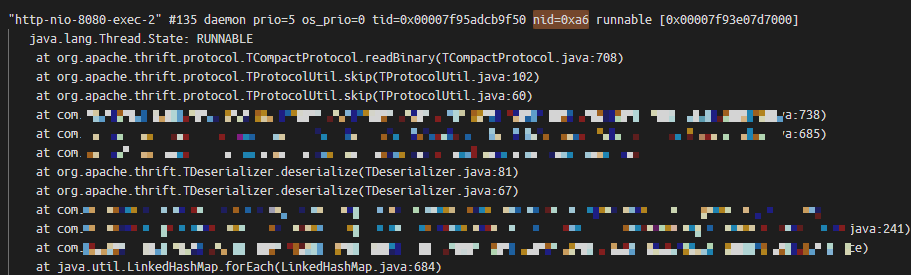
大对象分配由readBinary函数发起,调试下这个函数,如下:
妈呀,它创建了一个超大的byte数组,难怪会出现1.9G的大对象分配呢!
而readBinary的调用,由这个代码触发:
TProtocolFactory factory = new TCompactProtocol.Factory();
TDeserializer deserializer = new TDeserializer(factory);
deserializer.deserialize(deserializeObj, sourceBytes);
复制这是在做thrift反序列化,将sourceBytes字节数组反序列化到deserializeObj对象中。
当sourceBytes是由deserializeObj对象序列化出来时,反序列化就没有任何问题。
而当sourceBytes不是由deserializeObj对象序列化出来时,反序列化代码从sourceBytes中解析出字段长度时(length),可能是任意值,进而导致可能创建超大的字节数组。
但我们写这个代码,就是为了检测sourceBytes是否由deserializeObj序列化而来,所以sourceBytes确实有可能不是由deserializeObj序列化而来!
简单查看了一会thrift代码,发现可以限制字段的最大长度,如下: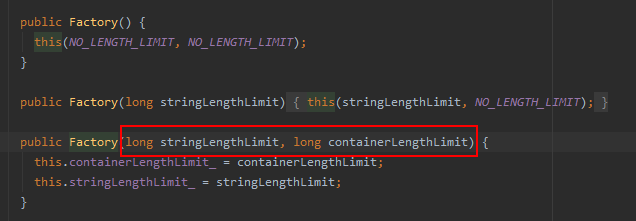
想一想,反序列的某个字段的长度,肯定不会有整个反序列化的数据长呀,因此使用sourceBytes.length来限制即可。
TProtocolFactory factory = new TCompactProtocol.Factory(sourceBytes.length, sourceBytes.length);
TDeserializer deserializer = new TDeserializer(factory);
deserializer.deserialize(deserializeObj, sourceBytes);
复制限制了后,若字段超长了会抛异常,所以若反序列化异常了,说明当前sourceBytes不是由deserializeObj序列化出来。
总结#
编写这个gdb脚本,确实花费了我相当多的时间,因为事前我也不知道gdb是否能够做到这个事情,且我不是C/C++程序员,对汇编相关知识并不熟悉,中途有好几次想放弃😣
好在最后成功了,并让我又Get到了一种新的问题解决路径,还是非常值得的😁