简介#
日常分析问题时,会频繁地查看分析日志,但如果蛮力去查看日志,耗时费力还不一定有效果,因此我总结了在Linux常用的一些日志查看技巧,提升日志阅读效率。
grep查找日志#
在我们查找某些异常日志时,经常需要同时查看异常前面或后面的一些日志,因为有时前面或后面的日志就已经标识出异常原因了,而grep的-A、-B、-C选项就提供了这种功能,如下:
# 查找ERROR日志,以及它的后10行
$ grep -A 10 ERROR app.log
# 查找ERROR日志,以及它的前10行
$ grep -B 10 ERROR app.log
# -C代表前10行和后10行
$ grep -C 10 ERROR app.log
复制查看某个时间段的日志#
有时,需要查看某个时间段的日志,比如凌晨2点15分系统出现报警,上班后我们想看看这段时间的日志,看能不能找到点线索,方法如下:
# 导出02:14到02:16分的日志
awk '/2022-06-24T02:14/,/2022-06-24T02:1[6-9]/' app.log > app0215.log
# 使用sed也是可以的
sed -n '/2022-06-24T02:14/,/2022-06-24T02:1[6-9]/p' app.log > app0215.log
复制注:awk与sed实际并不解析时间,它们只是按正则匹配,匹配到第一个正则时,开始输出行,直到遇到第二个正则关闭,所以如果你的日志中没有能匹配第二个正则的行,将导致一直输出到尾行!所以一般需要将第二个正则变宽松点,如上面的/2022-06-24T02:1[6-9]/,以避免出现这种情况
查看最后10条错误#
更多情况是,上班时发现系统有报警,于是想立马看看刚刚发生了什么,即查找最近的异常日志,如下:
# 最容易想到的是tail,但有可能最后1000行日志全是正常日志
$ tail -n 1000 app.log | less
# 最后10条异常, tac会反向读取日志行,然后用grep找到10个异常日志,再用tac又反向一次就正向了
$ tac app.log | grep -n -m10 ERROR | tac
复制还有一种是从刚报警的时间点开始导出到尾行,比如从2分钟前的5点15分开始导出,如下:
$ tac app.log | sed '/2022-06-24T17:15/q' | tac > app1715.log
复制原理与上面类似,只不过是换成了sed,sed默认会输出处理的每一行,而q指令代表退出程序,所以上面程序含义是从日志末尾开始输出日志,直到遇到正则/2022-06-24T17:15/停止输出。
awk分段查找#
对于像Java程序,异常日志一般会是一段一段的,且每段带有异常栈,如下: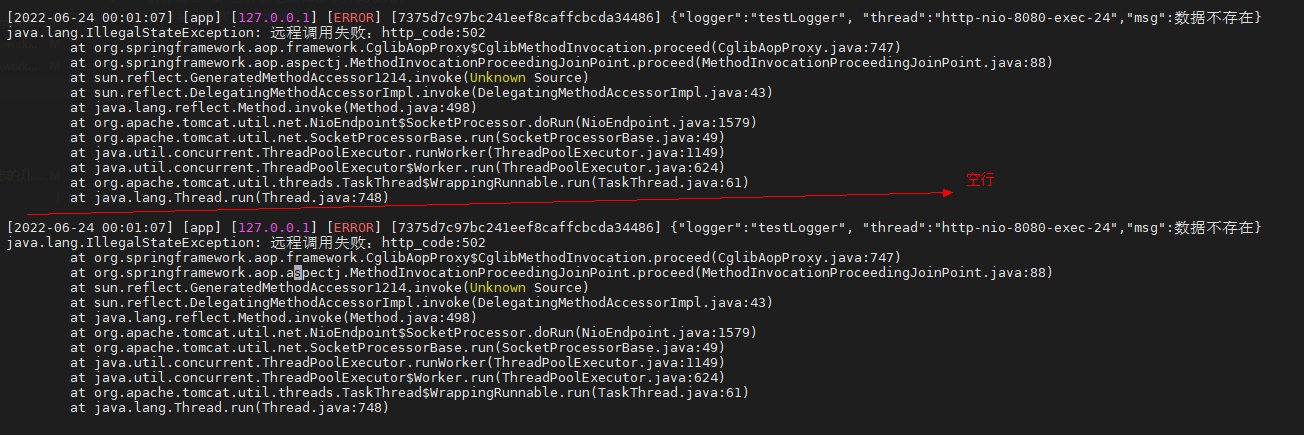
但grep是一行一行过滤的,如何一整段一整段的过滤异常栈呢?awk就提供了这种功能,当将awk中RS变量指定为空时,awk就会一段一段的读取并处理文本,如下:
# 查找异常日志,并保留异常栈
awk -v RS= -v ORS='\n\n' '/Exception/' app_error.log | less
复制-v RS=等效于-v RS='',设置RS变量为空,使得awk一段一段地读取日志-v ORS='\n\n'设置ORS变量为2个换行,使得awk一段一段的输出/Exception/代表过滤出包含正则Exception的段
使用less查看#
一般情况下,使用less可以更快速的查看日志,比如通过tail -n10000取出最近1w条日志,通过less查看,如下:
tail -n 10000 app.log | less
复制看日志时,有一个很常见的需求,就是很多日志都是当前不需要关心的,需要将它们过滤掉,less提供了&/的功能,可快速过滤掉不想看的日志,从而找到问题日志,如下: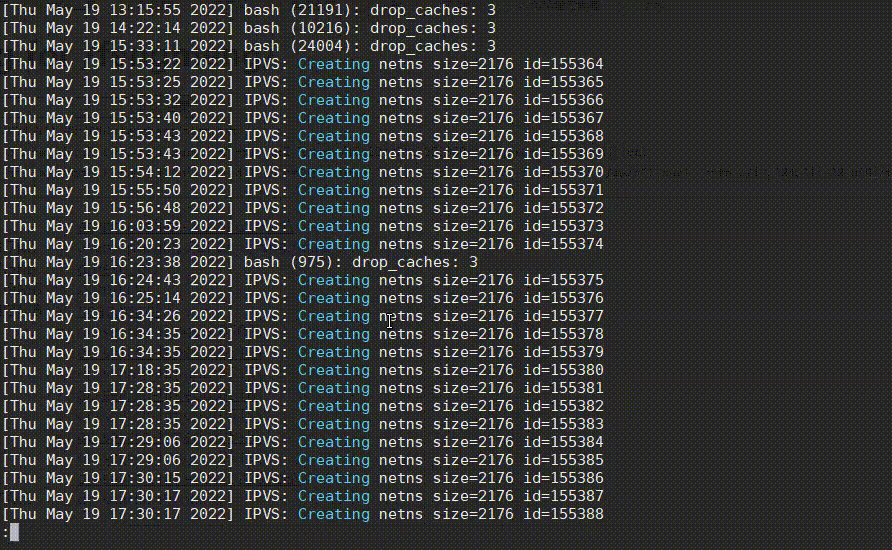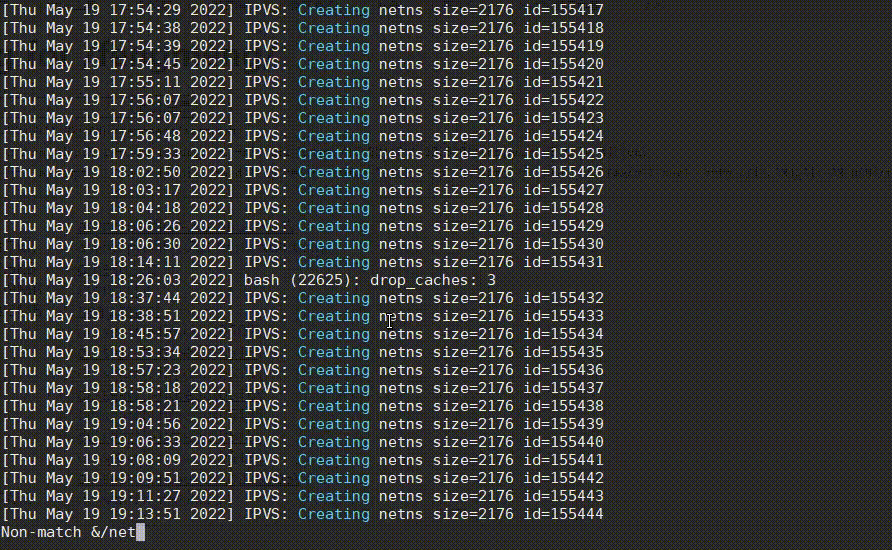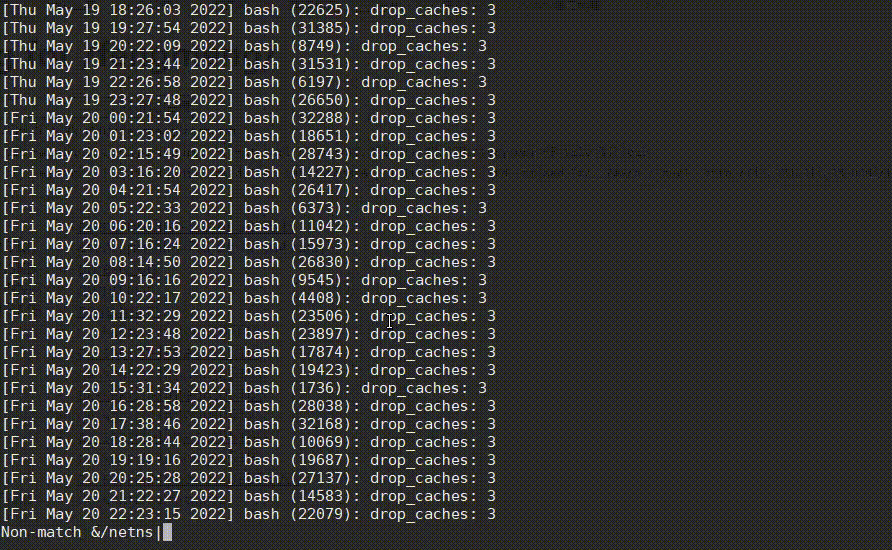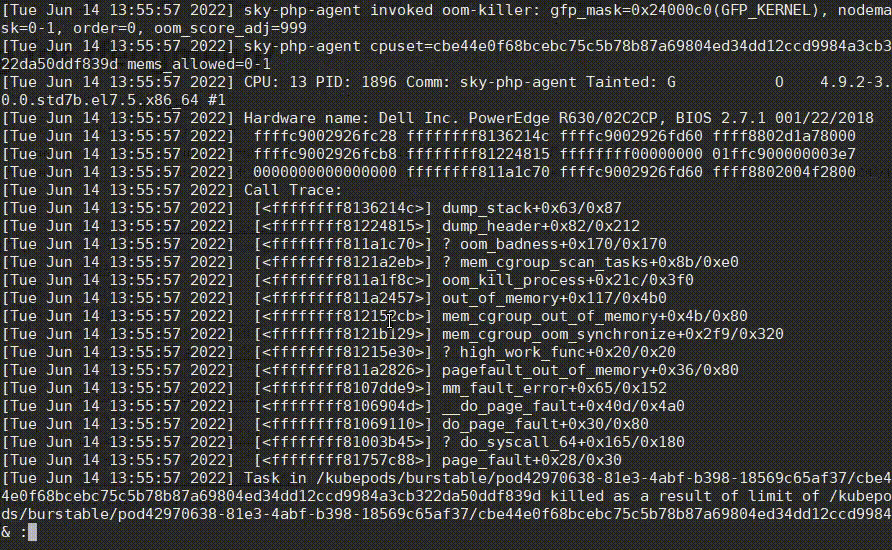
操作步骤:
- 先输入
&,再输入!进入Non-match过滤模式。 - 然后输入正则
netns,再按Enter,排除掉这种正常的日志,过滤后又发现有很多drop_caches日志。 - 然后也是先输入
&,再输入!,再直接按上箭头快速获取上次的输入内容,再接着输入|drop_caches,将drop_caches日志也过滤掉。 - 哦豁,发现了一个oom killer日志!
使用vim查看#
less可以一行一行的排除,但如果要一段一段的排除,如日志中经常会有一些常见且无影响的错误日志,这种情况可以通过vim配合awk排除,如下:
tail -n 10000 app_error.log | vim -
复制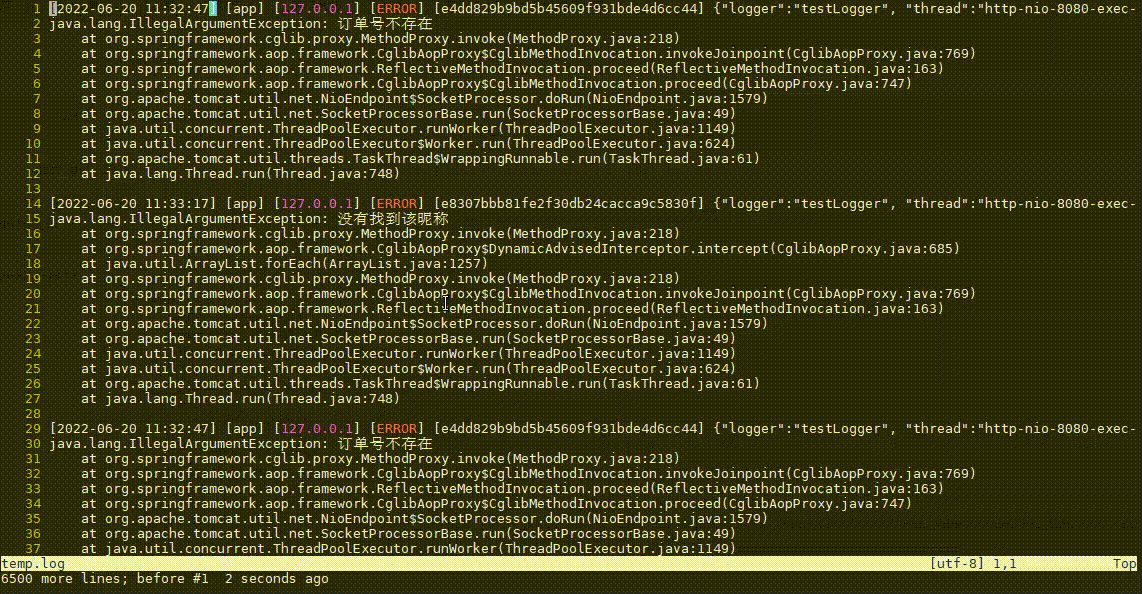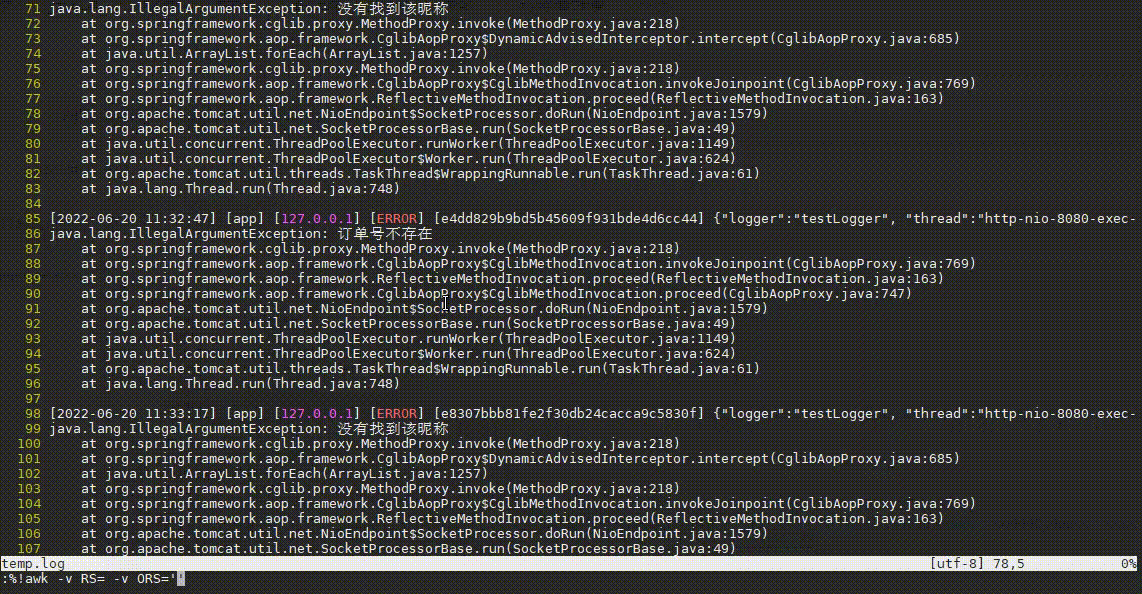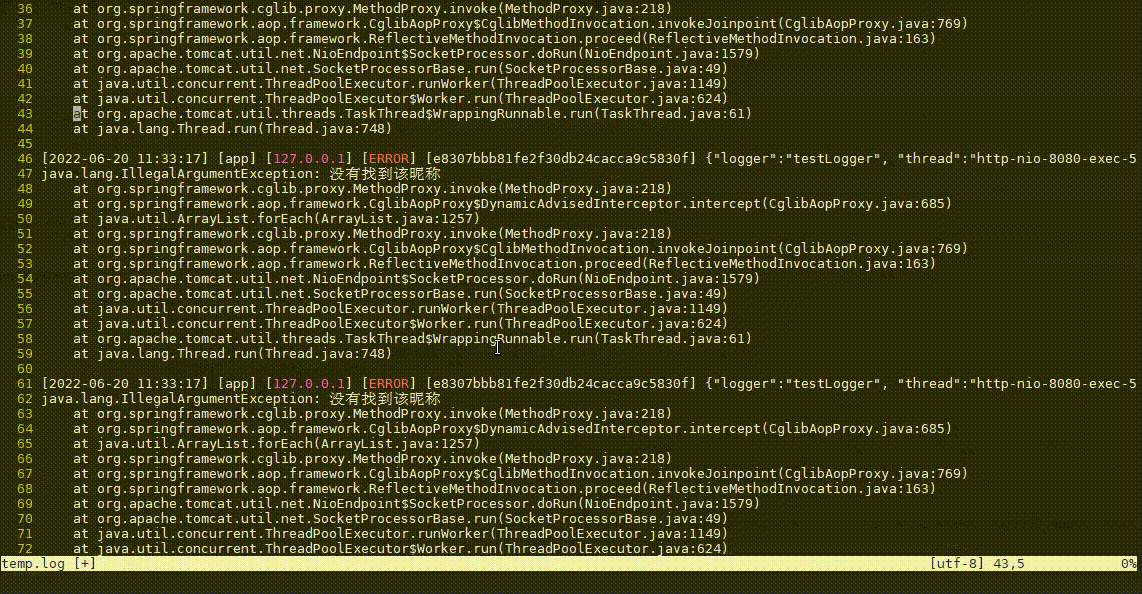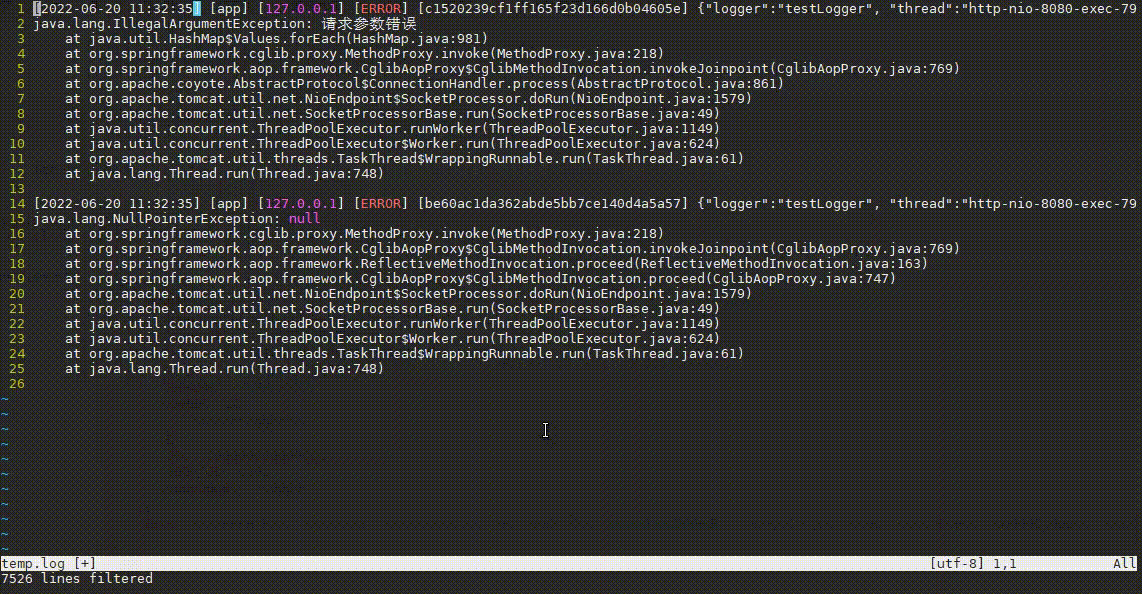
操作步骤:
- 先输入
:,进入vim的命令模式 - 再输入
%!awk -v RS= -v ORS='\n\n' ...,执行awk命令,其中%代表当前文件所有内容,!代表执行命令,所以%!代表将当前文件内容输入到命令中 - 然后awk规则中输入
'\!/订单号不存在/'并回车,这代表排除段中包含订单号不存在的段,排除后又发现很多没有找到该昵称异常。 - 接着输入
:再按上箭头快速获取上次输入内容,并补充&& \!/没有找到该昵称/,将这种常见异常也过滤掉。 - 哦豁,发现了一个NullPointerException异常!
其它工具#
有时为节省磁盘空间,日志会压缩成*.gz格式,这也是可以直接查看的,如下:
# 类似cat,同时解压并输出内容
zcat app.log.gz
# 类似grep,同时解压并查找内容
zgrep -m 10 ERROR app.log.gz
# 类似less,同时解压并查看内容
zless app.log.gz
复制而在处理时间方面,dateutils工具包用起来会更方便一些,如下:
# CentOS7安装dateutils
$ wget https://download-ib01.fedoraproject.org/pub/epel/8/Everything/x86_64/Packages/d/dateutils-0.4.9-1.el8.x86_64.rpm && rpm -Uvh dateutils-0.4.9-1.el8.x86_64.rpm
# Ubuntu安装dateutils
$ apt install dateutils
# 根据时间范围过滤日志,可指定时间串格式
$ cat dmesg.log | dategrep -i '%a %b %d %H:%M:%S %Y' '>=2022-06-24T12:00:00 && <now'
[Fri Jun 24 12:15:36 2022] bash (23610): drop_caches: 3
[Fri Jun 24 13:16:16 2022] bash (30249): drop_caches: 3
# 有时我们需要将日志中时间串转换为unix时间缀,方便处理
$ head -n4 access.log
127.0.0.1 - - [07/May/2022:19:00:25 +0800] "GET /health HTTP/1.1" 200 4 3ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - [07/May/2022:19:00:26 +0800] "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - [07/May/2022:19:00:27 +0800] "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - [07/May/2022:19:00:28 +0800] "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
$ head -n4 access.log |dateconv -i '[%d/%b/%Y:%H:%M:%S %Z]' -f '%s' -z 'Asia/Shanghai' -S
127.0.0.1 - - 1651950025 "GET /health HTTP/1.1" 200 4 3ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - 1651950026 "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - 1651950027 "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - 1651950028 "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
复制注:Ubuntu中对命令进行了改名,dategrep叫dateutils.dgrep,dateconv叫dateutils.dconv
总结#
这些工具组合起来还是很强大的,这也是为什么即使在公司有日志平台的情况下,依然还是有很多人会去使用命令行!
往期内容#
接口偶尔超时,竟又是JVM停顿的锅!
耗时几个月,终于找到了JVM停顿十几秒的原因
mysql的timestamp会存在时区问题?
真正理解可重复读事务隔离级别
密码学入门
字符编码解惑