最近一直在研究表大小过大,表数量过多对性能的影响.
想着能够通过truncate table 然后机器性能的变化
进行一下简单的验证.
希望能够得出一个用于调优的依据
第一种方式是使用 promethus + node_exporter + grafana
的方式进行部署和使用
自己干了一件比较蠢的事情:
自己部署了node 也部署了grafana
发现可以选择 1860 好的grafana的报表进行相关的处理
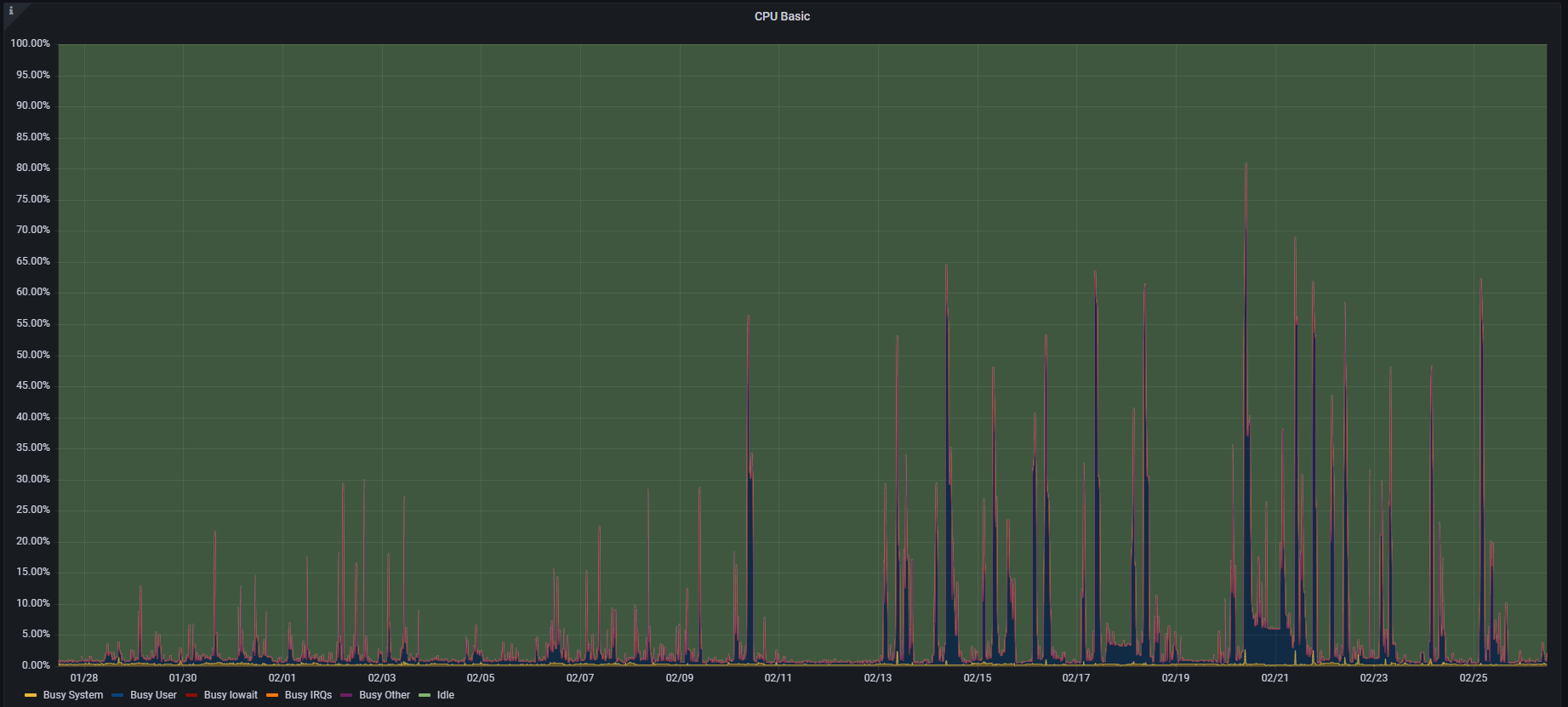
发现最近一段时间CPU的使用在增长, 怀疑可能有部分性能衰退的情况发生.
安装 yum install sysstat
设置服务 systemctl enable sysstat
开启服务 systemctl restart sysstat
sysstat 是一个工具集, 里面很多命令
这里不进行展开 仅说明一下 sar 的汇总命令
查看今天的工作
sar
查看前面30天中任意的工作负载
sar -f /var/log/sa/sa03
# 表示查看 这个月3号或者是上个月3号的工作负载
# 既是: 查看30天内的一个3号的工作负载.
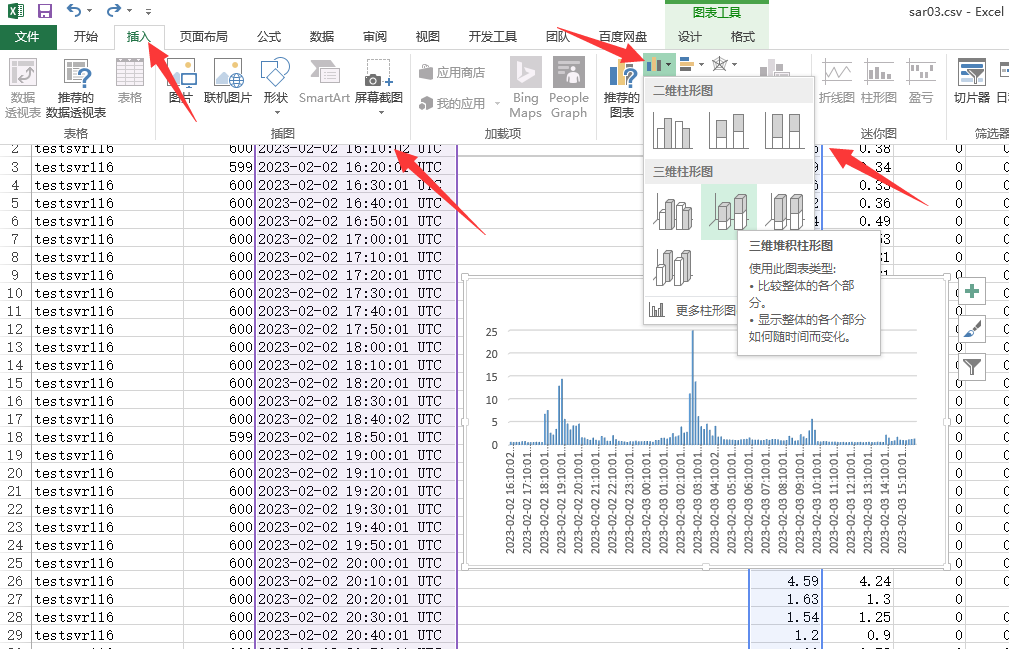
sadf -d /var/log/sa/sa03 | sed 's/;/,/g' > sar03.csv
sadf -d /var/log/sa/sa23 | sed 's/;/,/g' > sar23.csv
#注意 sadf 也是 sar的一个工具, 可以格式化输出部分内容便于分析
sadf 有两个小问题
1. 时区是UTC的需要自己转换一下. 或者是脑补也可以.
2. CPU值是 -1 可以还是用100 减去 idle 的方式来算出来.
然后通过excel的绘图就可以实现一个简单的CPU的时启用情况了