原创:打码日记(微信公众号ID:codelogs),欢迎分享,转载请保留出处。
简介#
现如今,正则表达式几乎是程序员的必备技能了,它入手确实很容易,但如果你不仔细琢磨学习,会长期停留在正则最基本的用法层面上。
因此,本篇文章,我会介绍一些能用正则解决的场景,但这些场景如果全自己琢磨实现的话,需要花一些时间才能完成,或者就完全想不出来,另外也会介绍一些正则表达式的性能问题。
匹配多个单词#
比如我想匹配zhangsan、lisi、wangwu这三个人名,这是一个很常见的场景,其实在正则里面也算基本功,但鉴于本人初入门时还是在网上搜索得到的答案,还是值得提一下的!
实现如下:
zhangsan|lisi|wangwu
其中|表示或的含义,就是匹配zhangsan或lisi或wangwu了。
匹配重复数字#
匹配如1111、2222、3333这样的4位长度的重复数字,突一想,这不用\d{4}就解决了嚒,其实不然,因为\d{4}可以匹配1111,但也可以匹配1234啊。
写法如下:
(\d)\1{3}
\d匹配第一个数字,后面的\1匹配前面\d匹配的内容,重复3次,这样就可以匹配1111或2222这样的4位数字串了。
匹配各种空白#
在使用正则时,常用\s来匹配空白,但遗憾的是,还是有一些Unicode的空白字符,\s无法匹配,这时可以尝试POSIX字符类\p{Space},我在Java中验证通过,可以匹配ascii空白字符与Unicode空白字符,如果是其它语言的话,可能正则语法会稍有区别。
位置匹配#
正则表达式中\G与环视是比较难理解的,因为这两个东西很多书上只是介绍了匹配的规则,没有说出实质,导致死记的规则过一段时间就忘,也不明白这两东西有啥用。
我们转换一下思维,其实在正则表达式中,匹配目标只有两个,一是匹配字符串中的字符,二是匹配字符串中的位置,如下图: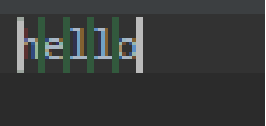
上边的hello,有5个字符可以匹配,另外还有6个位置可以匹配,而^hello中^就是代表匹配开头的位置,所以如果是_hello就无法被^hello匹配,因为_与h之间的位置并不是开头,不能与^匹配!
常见位置匹配规则
| 规则 | 匹配的位置 |
|---|---|
| ^ \A | 匹配开始位置 |
| $ \z \Z | 匹配结束位置 |
| \b \B | 匹配单词与非单词边界位置 |
| \G | 匹配当前匹配的开始位置 |
| (?=a) (?!a) | 正向环视,看看当前位置后面是否是a,或不是a |
| (?<=a) (?<!a) | 逆向环视,看看当前位置前面是否是a,或不是a |
^与\A
^ 匹配文本开始位置,但在多行匹配模式下,^匹配每一行的开始位置。
\A 仅仅只能匹配开始位置,不管什么匹配模式下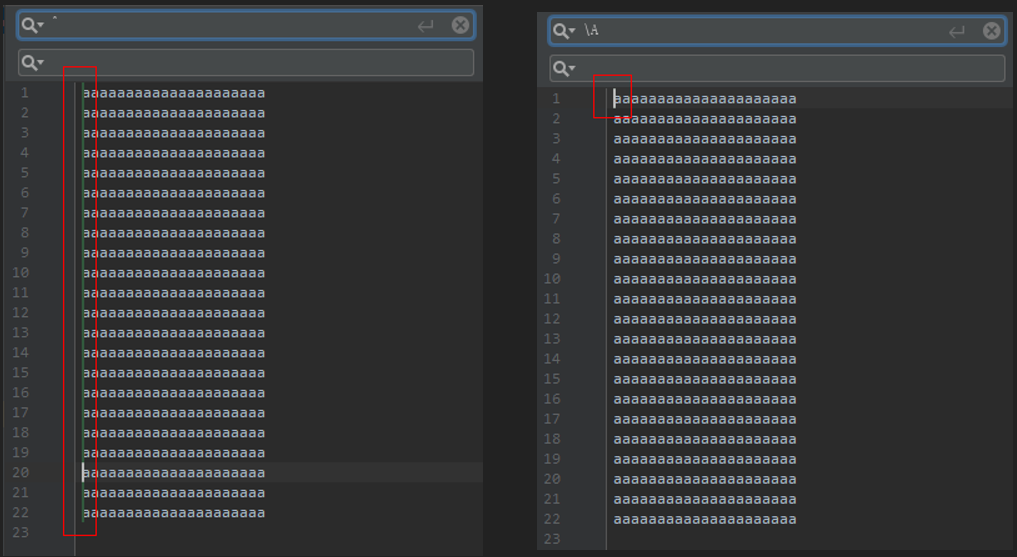
$与\Z
$ 匹配文本末尾位置,但在多行匹配模式下,$匹配每一行的末尾位置。
\Z 仅仅只能匹配末尾位置,不管什么匹配模式下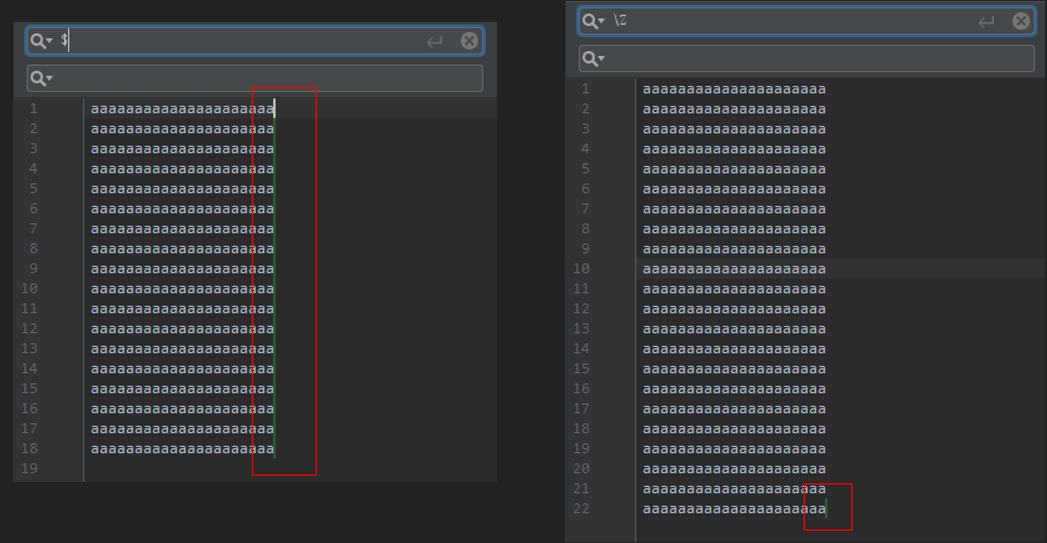
\b与\B
\b匹配单词边界,在Java中,单词边界即是字母与非字母之间的位置,中文不认为是单词,另外文本开头与文本结尾也是单词边界
\B匹配非单词边界
\G
匹配上次匹配的结束位置或当前匹配的开始位置,第一次匹配时,匹配文本开始位置,如下:
从1234a5678中找单个数字,如果用\d去找,可以找到8个,但使用\G\d去找,却只能找到4个
查找过程:
第1次查找,\G匹配文本开始位置,1与\d匹配,找到第1个匹配,即1
第2次查找,\G匹配1后面2前面之间的位置,2与\d匹配,找到第2个匹配,即2
第3次查找,\G匹配2后面3前面之间的位置,3与\d匹配,找到第3个匹配,即3
第4次查找,\G匹配3后面4前面之间的位置,4与\d匹配,找到第4个匹配,即4
第5次查询,\G匹配4后面5前面之间的位置,但a与\d不匹配,匹配结束,总共找到4个匹配。
环视
(?=a) 与 (?!a)
正向肯定(否定)环视,用来检测当前位置后面字符是否是a,或不是a
(?<=a) 与 (?<!a)
逆向肯定(否定)环视,用来检查当前位置前面字符是否是a,或不是a
如下,查找被()包裹的单词,使用环视限定单词左边是(,右边是)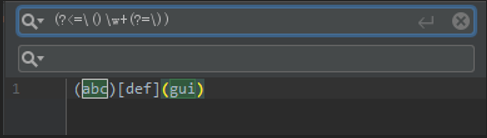
位置可被多次匹配
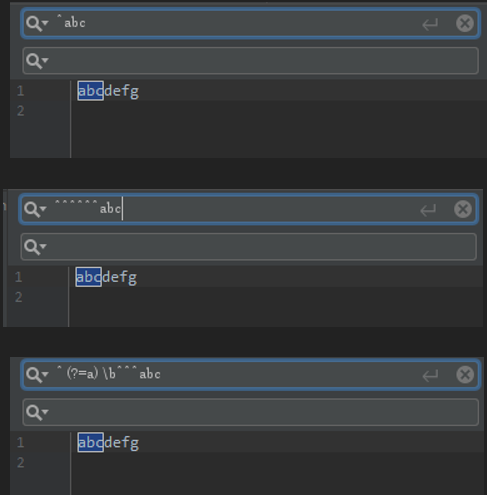
文本中的一个位置,可以同时匹配多个规则,且与规则在正则表达式中的先后顺序无关,例如下面3个正则表达式是等价的:
^abc
^^^^^^abc
^(?=a)\b^^^abc
下面举两个实际例子体会一下位置匹配!
例1:密码强度校验
前端校验密码强度时,经常有这样的要求,长度8到10位,且必须包含数字、字母、标点符号,可通过一个正则表达式校验出来,如下:
^(?=.*[0-9])(?=.*[a-zA-Z])(?=.*\p{P}).{8,10}$
其中,(?=.*[0-9])表示开头位置的后面一定要有数字,(?=.*[a-zA-Z])表示开头位置后面一定要有字母,(?=.*\p{P})表示开头位置的后面一定要有标点符号,.{8,10}表示匹配8到10位字符,这几个正则合在一起,就实现了校验密码强度的要求。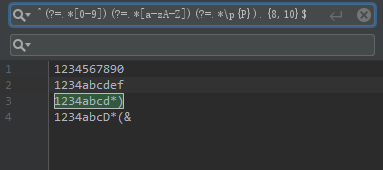
例2:千分位数字
有时我们需要将123456789变成123,456,789这样的千分位数字,这个使用正则就可以实现,如下,将此正则匹配到的位置,替换为,:
(?!^)(?=(\d{3})+$)
其中,(?=(\d{3})+$)表示匹配位置,这个位置后面必须要有一组或多组3个数字,满足这样条件的位置有3个,开头与1之间的位置,3和4之间的位置,6和7之间的位置,然后(?!^)又限制了同样的这些位置,不能是开头,就只能3和4,6和7之间的位置满足要求了,所以替换之后,就变成了123,456,789。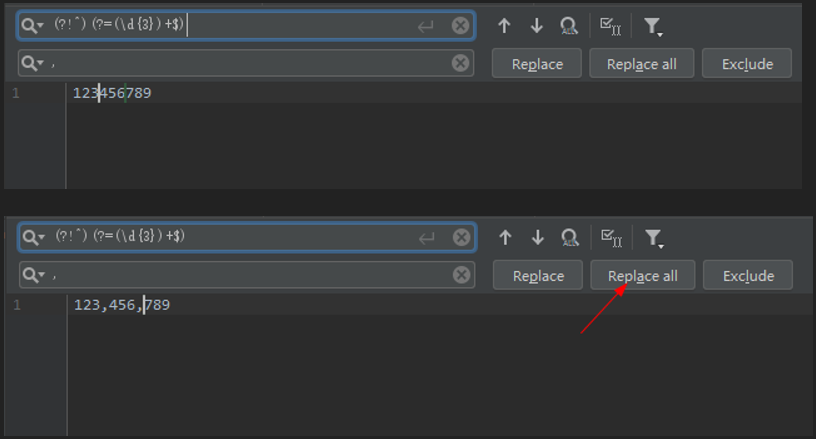
匹配带引号字符串#
匹配诸如"hello,world"这样的带引号的字符串,很容易想到,用"[^"]+"即可,但是如果引号字符串里面允许用\来转义"呢,如"hello \"bob\"!",如果用"[^"]+"来匹配的话,就只会匹配到"hello \"了,显然不对,可以先自行想想如何用正则实现。
...
...
...
想不出来?我们可以换一个视角,包含带\开头转义字符的字符串,其实可以拆解为",hello,\"bob,\"!,",然后再泛化为正则形式,",[^\\"]*,\\.[^\\"]*,\\.[^\\"]*,",组合在一起如下:
"[^\\"]*(?:\\.[^\\"]*)*"
表达式中多了个(?:),这表示非捕获分组,可以用来提高正则匹配性能,而由于字符串中有可能没有\开头的转义字符,故(?:\\.[^\\"]*)后面是*,直接由[^\\"]*匹配完引号内所有内容。
别搞炸了CPU#
正则表达式如果写得很复杂,就需要谨慎评估了,因为有可能平时运行得好好的,但遇到一些特殊情况,会导致CPU直接100%,比如还是上面那个匹配带引号字符串的场景,有同学可能会给出这样的正则:
"([^\\"]+|\\.)*"
乍一看,这个正则很完美,[^\\"]+匹配非转义字符的部分,\\.匹配\",\n之类的。这个正则在遇到满足条件的字符串时完全没有问题(如"hello \"bob\"!"),而遇到不满足条件的字符串时,正则匹配复杂度会随着字符串长度呈指数式上升,导致CPU 100%,如"hello \"bob\"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!,其中"没有闭合。
public static void main(String[] args) {
long begin = System.currentTimeMillis();
boolean isMatch = "\"hello \\\"bob\\\"!!!!!!!!!!!!!!!!!!".matches("\"([^\\\\\"]+|\\\\.)*\"");
System.out.println(String.format("%s ms, isMatch: %s", System.currentTimeMillis() - begin, isMatch));
}
这段java代码,在我机器上跑完要2s的样子,但如果字符串中再加4个!,运行时间立马上升到17s,性能下降非常恐怖!
原因
如果知道一些正则匹配原理,应该知道正则在匹配时,如果匹配不上,会将已经匹配的字符吐出来,再看看是否能够匹配,这叫回溯,比如".*"匹配"hello",先正则中的"匹配上了字符串中的",然后.*依次匹配了h,e,l,l,o,",最后正则中的"匹配字符串结尾位置,匹配不上,这时正则引擎会让前面的.*吐出它匹配的",然后吐出来的这个",刚好可以和正则中的"匹配,这样就匹配成功了。
那如果是"hello这样没有闭合的字符串,.*会一直吐字符,一直到它没有字符可吐,发现还是匹配不上,这样整个匹配才认定为匹配失败。
是的,正则中包含匹配量词?,*,+时,你就可以想像为它们一直在吃字符,当后面的规则匹配不上时,会强迫它又吐出来,而如果是懒惰匹配量词??,*?,+?,你就可以想像它先不吃,当后面的规则匹配不上时,会强迫它去吃。
我们再来分析下"([^\\"]+|\\.)*"匹配"!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!为啥会如此低效!
注:为了分析方便,我简化了待匹配字符串,但效果是一样的
- 首先
[^\\"]+吃掉了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!。 - 然后发现正则中
"与字符串结尾位置不匹配,开始回溯。 - 然后
[^\\"]+吐出一个!,注意这里,由于外层还有一个*贪婪量词,吐出来的!又被[^\\"]+|\\.中的[^\\"]+吃掉了,它吃掉后,到了字符串结尾,发现结尾又与正则中的"不匹配,又要求[^\\"]+|\\.中的[^\\"]+吐出刚吃掉的!,结果吐出后又不匹配。 - 然后又逼着最前面的那个
[^\\"]+吐出倒数第二个!,注意,再次吐出!后,当前匹配位置后面有两个!,可恶的是,这两个!又被后面[^\\"]+|\\.中的[^\\"]+吃掉了,然后悲剧重演,它又要吐出来,如此循环往复,计算量指数级上升。
解决办法
其实可以看出来,造成这个问题是因为正则表达式中有两个量词,内层有一个+,外层有一个*,不信的话,你可以尝试用^(a+)*$去匹配aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa0,同样的会非常慢。
而要解决这个问题,有两个办法。
- 让
[^\\"]+吐出来的字符,无法被外层正则中另一个贪婪的自己吃掉,比如前面介绍的"[^\\"]*(?:\\.[^\\"]*)*",[^\\"]*吐出来的字符,是无法被\\.[^\\"]*吃掉的,因为吐出来的一定不是\,而\\.[^\\"]*要先吃一个\。 - 明知道自己吐出来的字符后,后面的规则也无法匹配,那就让量词吃掉字符后不吐,比如将正则修改为
"([^\\"]++|\\.)*"这样,+变成了++,像这种量词后面再加+号的,比如?+,*+,++,这表示占有量词,吃完字符后就不会吐了。
注:占有量词不要乱用,有时吐出来字符可以让整个正则匹配,而你强制让它不吐出来,反而让它匹配不了了,如^.+b$可以匹配ab,但如果你用^.++b$就无法匹配ab了,因为.吃掉了ab,吐出一个b刚好可以使后面的b匹配。而^[^b]++b$这种用法就是对的,因为^b吐出来的字符肯定不能和后面的b匹配,就没必要再吐了。
总结#
正则表达式很强大,用好它事半功倍,但也需要了解它的执行过程,避免指数级回溯陷阱。