https://zhuanlan.zhihu.com/p/447836322复制
本文适合适合AI芯片设计人员入门与芯片赛道投资人了解技术内涵。
■ 陈巍,资深芯片专家,人工智能算法-芯片协同设计专家,擅长芯片架构与存算一体。
相关推荐
陈巍谈芯:什么是存算一体技术?发展史、优势、应用方向、主要介质(收录于存算一体芯片赛道投资融资分析)
陈巍谈芯: 3.5 目标检测网络SSD —《AI芯片设计:原理与实践》节选
陈巍谈芯:7.2 RRAM模拟存内计算 《先进存算一体芯片设计》节选
陈巍谈芯:7 分析实战:Hopper架构——《GPGPU 芯片设计:原理与实践》节选

自从BERT模型夺得NLP(自然语言处理)武林大赛桂冠后,就不断有年轻的后辈前来挑战切磋。
之后踢馆成功出名的是CMU的Zhilin Yang等提出的XLNet。
这个新的NLP武林盟主号称在20项任务比拼中撸了BERT模型的羊毛。
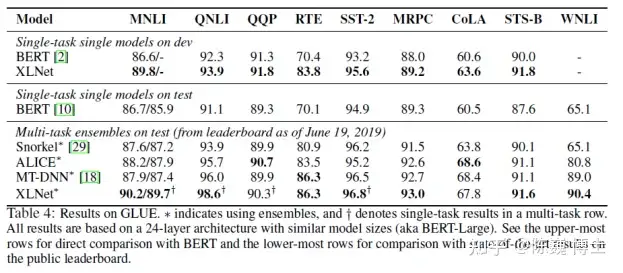
废话不多说,让我们看看这XLNet到底厉害在哪里,招式如何?
先放上原文源码地址为敬:
论文地址:https://arxiv.org/pdf/1906.08237.pdf
预训练模型及代码地址:https://github.com/zihangdai/xlne
我们再看看XLNet这小伙子的优势:
一直以来,AR(autoregressive,自回归)与AE(autoencoding,自编码)就是无监督表征学习中的两大绝学。
AR语言模型基于大量语料统计,被训练为编码单向上下文。AE则通过被掩盖的输入重建原始数据(例如BERT),弥补了双向信息的损失,但却由于信息的掩盖导致训练与实际推理的偏差。
XLNet的出现一开始就对准了这两个绝学的命门。
首先,XLNet借鉴NADE中的置换(Permutation),考虑句段各种分解顺序的可能性。这样就把上下文信息都加进的AR的计算之中。
其次,XLNet训练不再依赖于数据遮盖(Mask),这样就把BERT训练时遮遮掩掩与实际推理的偏差规避了。
借助了Tansformer-XL(戏称:超大号变形金刚)的循环机制和相对位置编码。(后面会详细介绍)从而改善了长文本序列的客户体验与准确度。
Permutation(置换)是个很有意思的数学思想。
其最早的实践大概来自于Fisher提出的置换检验(Permutation Test)。就是利用样本的随机排列进行统计分析和推断。置换这个概念非常适合总体分布未知的样本数据。
XLNet借用最近提出的了OrderlessNADE想法来实现置换。把序列中所有的元素都放到计算袋子里求最大期望:
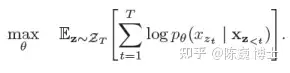
这一模型收集了元素两端所有位置的信息来进行训练,从而具备了捕获双向上下文的能力。
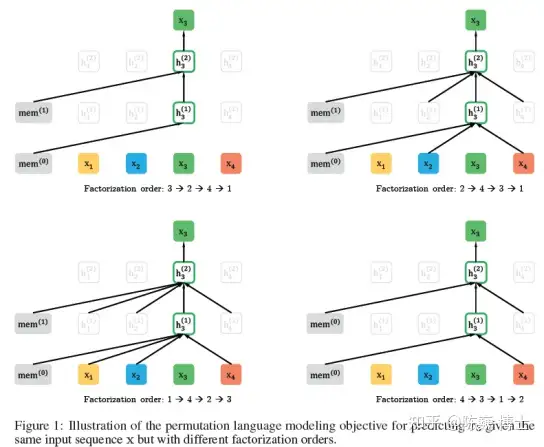
又例如,以句子序列
为例,假设
是预测目标。XLNet和BERT的期望计算可以近似理解为:
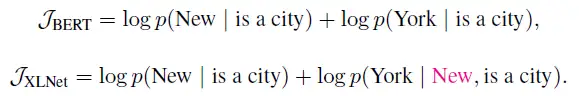
所谓的双流,就是内容(Contenet)与查询(Query)。通过这两组Attention,来进行PLM的训练。
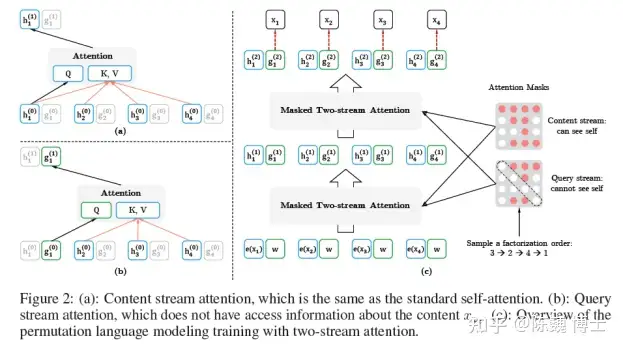
Content流与Query流的定义如下:
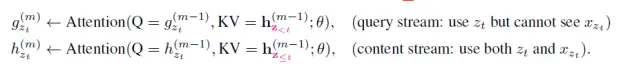
Q,K,V分别表示Attention中的Query,Key和Value。
Content流提供了完整的上下文信息用于AR的完整期望训练,而Query提供了类似掩盖的方式来增强预测。
Transformer-XL 是在VanillaTransformer的基础上诞生的。
长程依赖现象在序列数据很常见。例如常见的订票问答中的一个回答,可能要参照若干条对话之前订票人员信息。Vanilla Transformer使用固定长度上下文在数据单元之间建立直接的长程依赖关系。但这也使得句子边界附近的上下文碎片化。

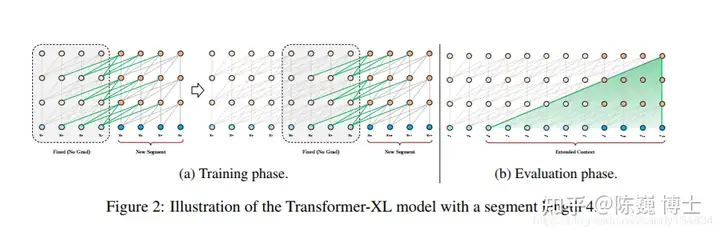
Transformer-XL则引入了两个关键工作:
1) 循环机制(RecurrenceMechanism)
2) 相对位置编码(RelativePositional Encoding)
先说循环机制。在训练期间,为前一个句段计算的表征会被修正并缓存,当处理下一句段时,前一个句段即作为扩展上下文使用。
在Transformer-XL中,相对位置信息由一组位置编码提供,即相对位置编码。
基于上述两点,Transformer-XL 学习的依赖关系大约比传统RNN 长 80%,比 Vanilla Transformer 长 450%。当然,Transformer-XL由于参数量巨大,训练和推理所需的算力也是很大的(烧钱的)。
很有意思的是,Transformer-XL的论文投稿到 ICLR 2019 是被毫不留情的拒绝了的。估计也是评委们心里暗想土豪(TPU的所有者,Google的卡丽熙,算力吞噬者……)就不要用钱砸场子了。
XLNet确实对得起它的名字,XL号的,训练时使用了512块 TPU v3芯片!
要知道,这可是极度碾压阿尔法狗的算力啊,相当于XL学问答要用几百个李世石的围棋脑力。
我们从自然界的角度来看,似乎可以看到一些端倪:
大部分昆虫凭借很小的脑容量就可以拥有视觉能力,却难以通过语音交互;
大部分小型哺乳动物拥有中等的脑容量可以通过语音交互(类似于ASR之类的命令词)却难以进行复杂的表达和对话(类似NLP的多轮对话);
目前看,几乎只有人类,拥有较大的脑容量和几乎最大的脑重比,才可以进行复杂的自然语言处理和理解。
BERT、XLnet和自然界,似乎在暗示我们:算力,应该是类人NLP的基础。
人工智能领域的竞赛,正逐渐变为算力和芯片的角逐。芯片,正成为人工智能体系中必不可少的一环。