写在最前面的
我相信你脑子里关于网络的概念都在下面这张图上,但是乱成一团麻,这就是因为知识没有贯通、没有实践、没有组织

上面的概念在RFC1180中讲的无比的通熟易懂了,但是抱歉,当时你也许看懂了,但是一个月后又忘记了,或者碰到问题才发现之前即使觉得看懂了的东西实际没懂
所以这篇文章希望解决书本知识到实践的贯通,希望把网络概念之间的联系通过实践来组织起来
最近客户环境碰到一个网络ping不通的问题,折腾了一周,所以记录一下
当时的网络链路是(大概是这样,略有简化):
容器1->容器1所在物理机1->交换机->物理机2
- 从容器1 ping 物理机2 不通;
- 从物理机1上的容器2 ping物理机2 通;
- 物理机用一个vlan,容器用另外一个vlan
- 交换机都做了trunk,让两个vlan都允许通过(肯定没问题,因为容器2是通的)
- 同时发现即使是通的,有的容器 ping物理机1只需要0.1ms,有的容器需要200ms以上(都在同一个交换机下),不合理
- 所有容器 ping 其它外网IP反而是通的
扯了一周是因为容器的网络是我们自己配置的,交换机我们没有权限接触,由客户配置。出问题的时候都会觉得自己没问题对方有问题,另外就是对网络基本知识认识不够所以都觉得自己没问题。
这个问题的答案在大家看完本文的基础知识后会总结出来。
开始前大家先想想,假如有个面试题是:输入 ping IP后 敲回车,然后发生了什么?
route 路由表
$route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric RefUse Iface
0.0.0.0 10.125.15.254 0.0.0.0 UG0 00 eth0
10.0.0.0 10.125.15.254 255.0.0.0 UG0 00 eth0
10.125.0.0 0.0.0.0 255.255.240.0 U 0 00 eth0
11.0.0.0 10.125.15.254 255.0.0.0 UG0 00 eth0
30.0.0.0 10.125.15.254 255.0.0.0 UG0 00 eth0
100.64.0.0 10.125.15.254 255.192.0.0 UG0 00 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 00 eth0
172.16.0.0 10.125.15.254 255.240.0.0 UG0 00 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 00 docker0
192.168.0.0 10.125.15.254 255.255.0.0 UG0 00 eth0
假如你现在在这台机器上ping 172.17.0.2 根据上面的route表得出 172.17.0.2这个IP符合:
172.17.0.0 0.0.0.0 255.255.0.0 U 0 00 docker0
这条路由规则,那么ping 包会从docker0这张网卡发出去。
但是如果是ping 10.125.4.4 根据路由规则应该走eth0这张网卡。
接下来就要判断目标IP是否在同一个子网了
ifconfig
首先来看看这台机器的网卡情况:
$ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.42.1 netmask 255.255.0.0 broadcast 0.0.0.0
ether 02:42:49:a7:dc:ba txqueuelen 0 (Ethernet)
RX packets 461259 bytes 126800808 (120.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 462820 bytes 103470899 (98.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.125.3.33 netmask 255.255.240.0 broadcast 10.125.15.255
ether 00:16:3e:00:02:67 txqueuelen 1000 (Ethernet)
RX packets 280918095 bytes 89102074868 (82.9 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 333504217 bytes 96311277198 (89.6 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 0 (Local Loopback)
RX packets 1077128597 bytes 104915529133 (97.7 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1077128597 bytes 104915529133 (97.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
这里有三个IP,三个子网掩码(netmask),根据目标路由走哪张网卡,得到这个网卡的子网掩码,来计算目标IP是否在这个子网内。
arp协议
网络包在物理层传输的时候依赖的mac 地址而不是上面的IP地址,也就是根据mac地址来决定把包发到哪里去。
arp协议就是查询某个IP地址的mac地址是多少,由于这种对应关系一般不太变化,所以每个os都有一份arp缓存(一般15分钟过期),也可以手工清理,下面是arp缓存的内容:
$arp -a
e010125011202.bja.tbsite.net (10.125.11.202) at 00:16:3e:01:c2:00 [ether] on eth0
? (10.125.15.254) at 0c:da:41:6e:23:00 [ether] on eth0
v125004187.bja.tbsite.net (10.125.4.187) at 00:16:3e:01:cb:00 [ether] on eth0
e010125001224.bja.tbsite.net (10.125.1.224) at 00:16:3e:01:64:00 [ether] on eth0
v125009121.bja.tbsite.net (10.125.9.121) at 00:16:3e:01:b8:ff [ether] on eth0
e010125009114.bja.tbsite.net (10.125.9.114) at 00:16:3e:01:7c:00 [ether] on eth0
v125012028.bja.tbsite.net (10.125.12.28) at 00:16:3e:00:fb:ff [ether] on eth0
e010125005234.bja.tbsite.net (10.125.5.234) at 00:16:3e:01:ee:00 [ether] on eth0
进入正题,回车后发生什么
首先 os需要把ping命令封成一个icmp包,需要填上包头(包括IP、mac地址),那么os先根据目标IP和本机的route规则计算使用哪个interface(网卡),每条路由规则基本都包含目标IP范围、网关、网卡这样几个基本元素。
如果目标IP在同一子网
如果目标IP和本机IP是同一个子网(根据本机ifconfig上的每个网卡的netmask来判断),并且本机arp缓存没有这条IP对应的mac记录,那么给整个子网的所有机器广播发送一个 arp查询
比如我ping 10.125.3.42,然后tcpdump抓包看到的arp请求:
$sudo tcpdump -i eth0 arp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
16:22:01.792501 ARP, Request who-has e010125003042.bja.tbsite.net tell e010125003033.bja, length 28
16:22:01.792566 ARP, Reply e010125003042.bja.tbsite.net is-at 00:16:3e:01:8d:ff (oui Unknown), length 28
上面就是本机发送广播消息,10.125.3.42的mac地址是多少,很快10.125.3.42回复了自己的mac地址。
收到这个回复后,先缓存起来,下个ping包就不需要再次arp广播了。
然后将这个mac地址填写到ping包的包头的目标Mac(icmp包),然后发出这个icmp request包,按照mac地址,正确到达目标机器,然后对方正确回复icmp reply【对方回复也要查路由规则,arp查发送放的mac,这样回包才能正确路由回来,略过】。
来看一次完整的ping 10.125.3.43,tcpdump抓包结果:
$sudo tcpdump -i eth0 arp or icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
16:25:15.195401 ARP, Request who-has e010125003043.bja.tbsite.net tell e010125003033.bja, length 28
16:25:15.195459 ARP, Reply e010125003043.bja.tbsite.net is-at 00:16:3e:01:0c:ff (oui Unknown), length 28
16:25:15.211505 IP e010125003033.bja > e010125003043.bja.tbsite.net: ICMP echo request, id 27990, seq 1, length 64
16:25:15.212056 IP e010125003043.bja.tbsite.net > e010125003033.bja: ICMP echo reply, id 27990, seq 1, length 64
我换了个IP地址,接着再ping同一个IP地址,arp有缓存了就看不到arp广播查询过程了。
如果目标IP不是同一个子网
arp只是同一子网广播查询,如果目标IP不是同一子网的话就要经过本IP网关就行转发,如果本机没有缓存网关mac(一般肯定缓存了),那么先发送一次arp查询网关的mac,然后流程跟上面一样,只是这个icmp包发到网关上去了(mac地址填写的是网关的mac)
从本机10.125.3.33 ping 11.239.161.60的过程,因为不是同一子网按照路由规则匹配,根据route表应该走10.125.15.254这个网关,如下截图:
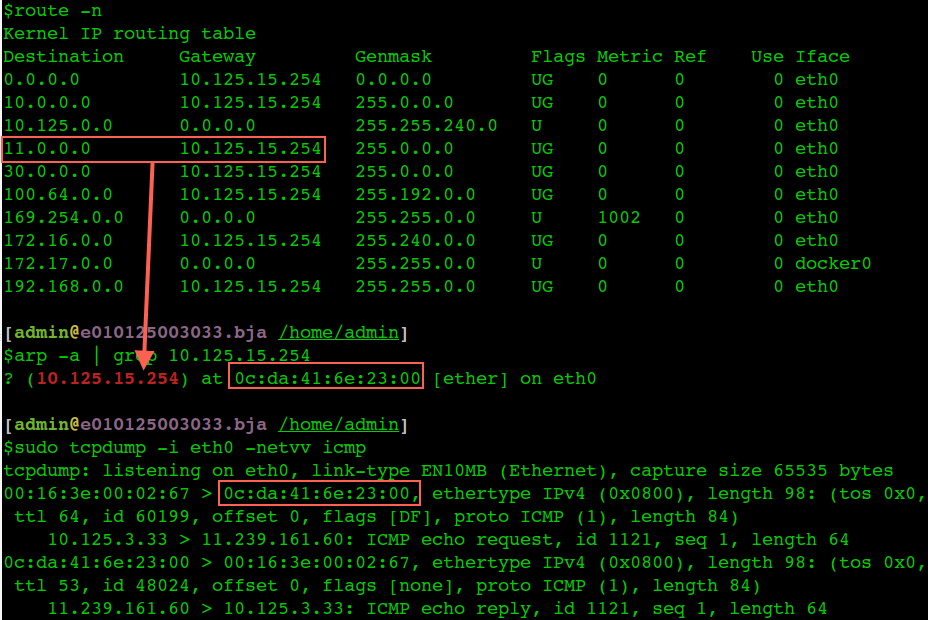
首先是目标IP 11.239.161.60 符合最上面红框中的路由规则,又不是同一子网,所以查找路由规则中的网关10.125.15.254的Mac地址,arp cache中有,于是将 0c:da:41:6e:23:00 填入包头,那么这个icmp request包就发到10.125.15.254上了,虽然包头的mac是 0c:da:41:6e:23:00,但是IP还是 11.239.161.60.
看看目标IP 11.239.161.60 的真正mac信息(跟ping包包头的Mac是不同的):
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 11.239.161.60 netmask 255.255.252.0 broadcast 11.239.163.255
ether 00:16:3e:00:04:c4 txqueuelen 1000 (Ethernet)
这个包根据Mac地址路由到了网关上
网关接下来怎么办
为了简化问题,假设两个网关直连
网关收到这个包后(因为mac地址是她的),打开一看IP地址是 11.239.161.60,不是自己的,于是继续查自己的route和arp缓存,发现11.239.161.60这个IP的网关是11.239.163.247,于是把包的目的mac地址改成11.239.163.247的mac继续发出去。
11.239.163.247这个网关收到包后,一看 11.239.161.60是自己同一子网的IP,于是该arp广播找mac就广播,cache有就拿cache的,然后这个包才最终到达目的11.239.161.60上。
整个过程中目标mac地址每一跳都在变,IP地址不变,每经过一次变化可以简单理解从一跳。
实际上可能要经过多个网关多次跳跃才能真正到达目标机器
目标收到这个icmp包后的回复过程一样,略过。
arp广播风暴和arp欺骗
广播风暴:如果一个子网非常大,机器非常多,每次arp查询都是广播的话,也容易因为N*N的问题导致广播风暴。
arp欺骗:同样如果一个子网中的某台机器冒充网关或者其他机器,当收到arp查询的时候总是把自己的mac冒充目标机器的mac发给你,然后你的包先走到他,为了不被发现达到自己的目的后再转发给真正的网关或者机器,所以在里面都点什么手脚,看看你发送的内容都还是很容易的
讲完基础再来看开篇问题的答案
分别在两个物理机上抓包
在物理机2上抓包:

tcpdump: listening on em1, link-type EN10MB (Ethernet), capture size 65535 bytes
f4:0f:1b:ae:15:fb > 18:66:da:f0:15:90, ethertype 802.1Q (0x8100), length 102: vlan 134, p 0, ethertype IPv4, (tos 0x0, ttl 63, id 5654, offset 0, flags [DF], proto ICMP (1), length 84)
10.159.43.162 > 10.159.43.1: ICMP echo request, id 6285, seq 1, length 64
18:66:da:f0:15:90 > 00:00:0c:9f:f0:86, ethertype 802.1Q (0x8100), length 102: vlan 134, p 0, ethertype IPv4, (tos 0x0, ttl 64, id 21395, offset 0, flags [none], proto ICMP (1), length 84)
10.159.43.1 > 10.159.43.162: ICMP echo reply, id 6285, seq 1, length 64
这个抓包能看到核心证据,ping包有到达物理机2,同时物理机2也正确回复了(mac、ip都对)
同时在物理机1上抓包只能看到ping包出去,回包没有到物理机1(所以回包肯定不会到容器里了)
所以问题的核心在交换机没有正确把物理机2的回包送到物理机1上面。
同时观察到的不正常延时: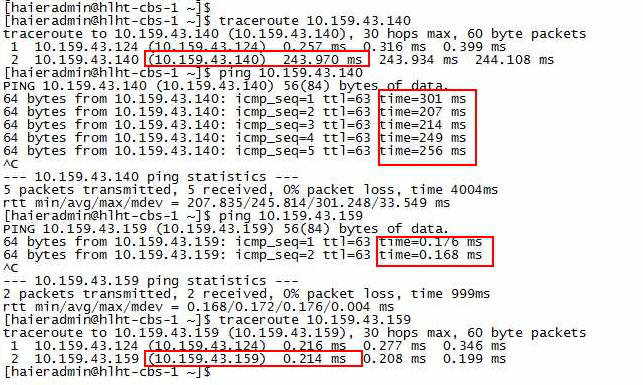
过程中的其它测试:
- 新拿出一台物理机配置上不通的容器的IP,这是通的,所以客户坚持是容器网络的配置;
- 怀疑不通的IP所使用的mac地址冲突,在交换机上清理了交换机的arp缓存,没有帮助,还是不通
对于1能通,我认为这个测试不严格,新物理机所用的mac不一样,并且所接的交换机口也不一样,影响了测试结果。
最终的原因
最后在交换机上分析包没正确发到物理机1上的原因跟客户交换机使用了HSRP(热备份路由器协议,就是多个交换机HA高可用,也就是同一子网可以有多个网关的IP),停掉HSRP后所有IP容器都能通了,并且前面的某些容器延时也恢复正常了。
通俗点说就是HSRP把回包拐跑了,有些回包拐跑了又送回来了(延时200ms那些)
至于HSRP为什么会这么做,要厂家出来解释了。
大概结构如下图:
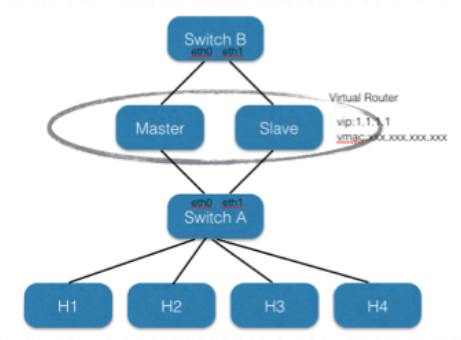
关于HSRP和VRRP
VRRP是虚拟路由冗余协议的简称,这个协议的目的是为了让多台路由器共同组成一个虚拟路由器,从而解决单点故障。
使用VRRP的网络架构大致如上面这个图所示,其中Master和Slave共同组成了一个虚拟路由器,这台虚拟路由器的IP是1.1.1.1,同时还会有一个虚拟的mac地址,所有主机的默认网关IP都将设置成1.1.1.1。
假设主机H1需要对外发送数据,在发送IP数据包时主机H1需要知道1.1.1.1这个IP对应的物理地址,因此H1会向外广播一个ARP请求,询问1.1.1.1这个IP数据包对应的物理地址。此时,Master将会负责响应这个APR请求,将虚拟的mac地址报告给主机H1,主机H1就用这个物理地址发送IP数据包。
当IP数据包到达交换机Switch A的时候,Switch A需要知道应该把这个数据包转发到哪条链路去,这个时候Switch A也会广播一个ARP请求,看看哪条链路会响应这个ARP请求。同样,Master会响应这个ARP请求,从而Switch A就知道了应该把数据包从自己的eth0对应的这条链路转发出去。此时,Master就是真正负责整个网络对外通信的路由器。
当Master出现故障的时候,通过VRRP协议,Slave可以感知到这个故障(通过类似于心跳的方式),这个时候Slave会主动广播一个ARP消息,告诉Switch A应该从eth1对应的链路转发物理地址是虚拟mac地址的数据包。这样就完成了主备路由器的切换,这个过程对网络中的主机来说是透明的。
通过VRRP不仅可以实现1主1备的部署,还可以实现1主多备的部署。在1主多备的部署结构下,当Master路由器出现故障,多个Backup路由器会通过选举的方式产生一个新的Master路由器,由这个Master路由器来响应ARP请求。
除了利用VRRP屏蔽单点故障之外,还可以实现负载均衡。在主备部署的情况下,Backup路由器其实是空转的,并不负责数据包的路由工作,这样显然是有点浪费的。此时,为了让Backup也负责一部分的路由工作,可以将两台路由器配制成互为主备的模式,这样就形成了两台虚拟路由器,网络中的主机可以选择任意一台作为默认网关。这种互为主备的模式也可以应用到1主多备的部署方式下。比如由3台路由器,分别是R1,R2和R3,用这3台路由器可以组成3台虚拟路由器,一台虚拟路由器以R1为Master,R2和R3为Backup路由器,另外一台以R2为Master,R1和R3为Backup路由器,第三台则以R3为Master,R1和R2为Backup路由器。
通过VRRP,可以实现LVS的主备部署,屏蔽LVS单点故障对应用服务器的影响。
网络到底通不通是个复杂的问题
讲这个过程的核心目的是除了真正的网络不通,有些是服务不可用了也怪网络。很多现场的同学根本讲不清自己的服务(比如80端口上的tomcat服务)还在不在,网络通不通,网络不通的话该怎么办?
实际这里涉及到四个节点(以两个网关直连为例),srcIP -> src网关 -> dest网关 -> destIP.如果ping不通(也有特殊的防火墙限制ping包不让过的),那么分段ping(二分查找程序员应该最熟悉了)。 比如前面的例子就是网关没有把包转发回来
抓包看ping包有没有出去,对方抓包看有没有收到,收到后有没有回复。
ping自己网关能不能通,ping对方网关能不能通
接下来说点跟程序员日常相关的
如果网络能ping通,服务无法访问
那么尝试telnet IP port 看看你的服务监听的端口是否还在,在的话是否能正常响应新的连接。有时候是进程挂掉了,端口也没人监听了。有时候是进程还在但是死掉了,所以端口也不响应新的请求了。
如果端口还在也是正常的话,telnet应该是好的:
$telnet 11.239.161.60 2376
Trying 11.239.161.60...
Connected to 11.239.161.60.
Escape character is '^]'.
^C
Connection closed by foreign host.
假如我故意换成一个不存在的端口,目标机器上的OS直接就拒绝了这个连接(抓包的话一般是看到reset标识):
$telnet 11.239.161.60 2379
Trying 11.239.161.60...
telnet: connect to address 11.239.161.60: Connection refused
一个服务不响应,然后首先怀疑网络不通、丢包的Case
当时的反馈应用代码抛SocketTimeoutException,怀疑网络问题:
- tsar检查,发现retran率特别高,docker容器(tlog-console)内达到50,物理机之间的retran在1-2之间。
- Tlog连接Hbase,出现大量连接断开,具体日志见附件,Hbase服务器完全正常,Hbase同学怀疑retran比较高导致。
- 业务应用连接Diamond 偶尔会出现超时异常,具体日志见附件。
- 业务很多这样的异常日志:[Diamond SocketTimeoutException]
- 有几台物理机io偶然情况下会飙升到80多。需要定位解决。
其实当时看到tsar监控retran比较高,我也觉得网络有问题,但是我去看的时候网络又非常好,于是我看了一下出问题时间段的网卡的流量信息也非常正常:
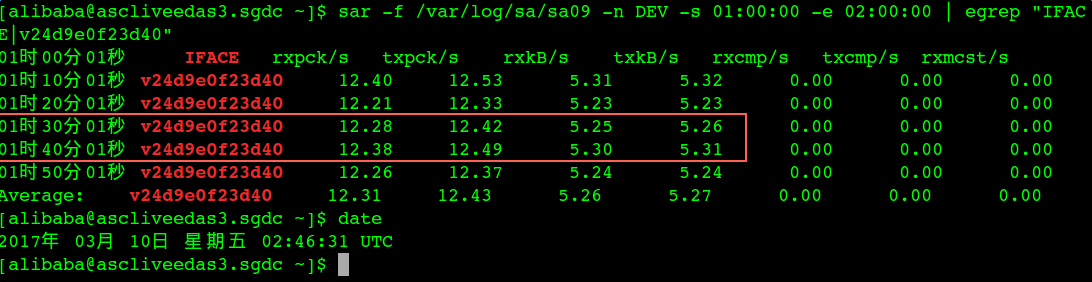
上图是通过sar监控到的9号 10.16.11.138(v24d9e0f23d40) 这个网卡的流量,看起来也是正常,流量没有出现明显的波动(10.16.11.138 出问题容器对应的网卡名:v24d9e0f23d40)
为了监控网络到底有没有问题,接着在出问题的两个容器上各启动一个http server,然后在对方每1秒钟互相发一次发http get请求,基本认识告诉我们如果网络丢包、卡顿,那么我这个http server的监控日志时间戳也会跳跃,如果应用是因为网络出现异常那么我启动的http服务也会出现异常。
实际监控来看,应用出异常的时候我的http服务是正常的(写了脚本判断日志的连续性,没问题):
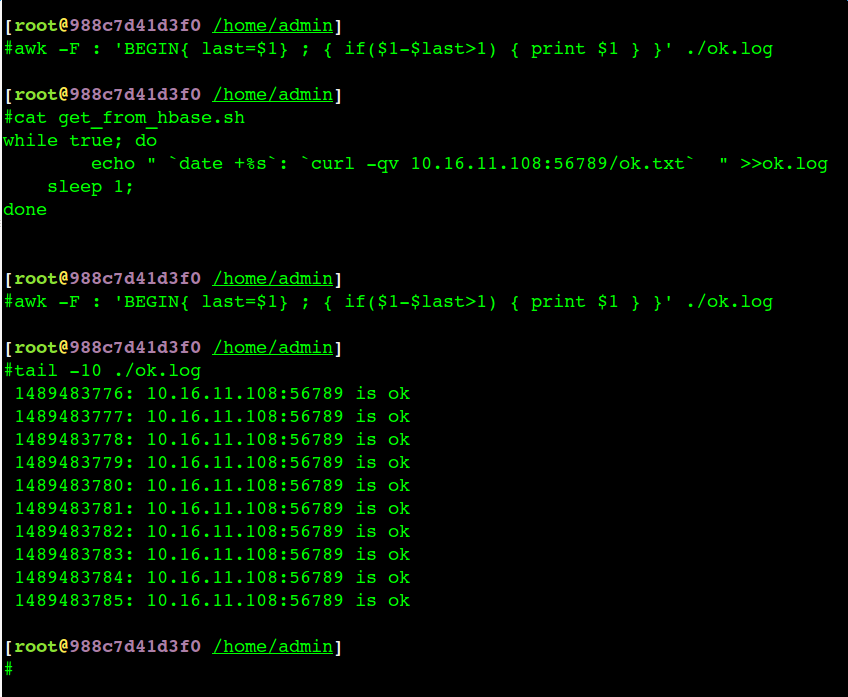
这也强有力地证明了网络没问题,所以大家集中火力查看应用的问题。后来的实际调查发现是应用假死掉了(内部线程太多,卡死了),服务端口不响应请求了。
TCP建连接过程跟前面ping一样,只是把ping的icmp协议换成TCP协议,也是要先根据route,然后arp。
总结
网络丢包,卡顿,抖动很容易做背包侠,找到正确的原因解决问题才会更快,要不在错误的路径上怎么发力都不对。准的方向要靠好的基础知识和正确的逻辑以及证据来支撑,而不是猜测
- 有重传的时候(或者说重传率高的时候),ping有可能是正常的(icmp包网卡直接返回);
- 重传高,一般是tcp retrans,可能应用不响应,可能操作系统软中断太高等
- ping只是保证网络链路是否通畅
这些原理基本都在RFC1180中阐述的清晰简洁,图文并茂,结构逻辑合理,但是对于90%的程序员没有什么卵用,因为看完几周后就忘得差不多。对于普通人来说还是要通过具体的案例来加深理解。
一流的人看RFC就够了,差一些的人看《TCP/IP卷1》,再差些的人要看一个个案例带出来的具体知识的书籍了,比如《wireshark抓包艺术》,人和人的学习能力有差别必须要承认。
参考文章:
https://tools.ietf.org/html/rfc1180
https://www.practicalnetworking.net/series/packet-traveling/packet-traveling/
Computer Networking Introduction - Ethernet and IP (Heavily Illustrated) 这篇凑合吧,其实没我这篇写得好,不过这个博客还有些别的文章也不错