Java 内存模型简称 JMM,全名 Java Memory Model 。Java 内存模型规定了 JVM 应该如何使用计算机内存(RAM)。 广义来讲, Java 内存模型分为两个部分:
- JVM 内存结构
- JMM 与线程规范
其中,JVM 内存结构是底层实现,也是我们理解和认识 JMM 的基础。 大家熟知的堆内存、栈内存等运行时数据区的划分就可以归为 JVM 内存结构。
JVM 结构
我们先来看看 JVM 整体的结构概念图:
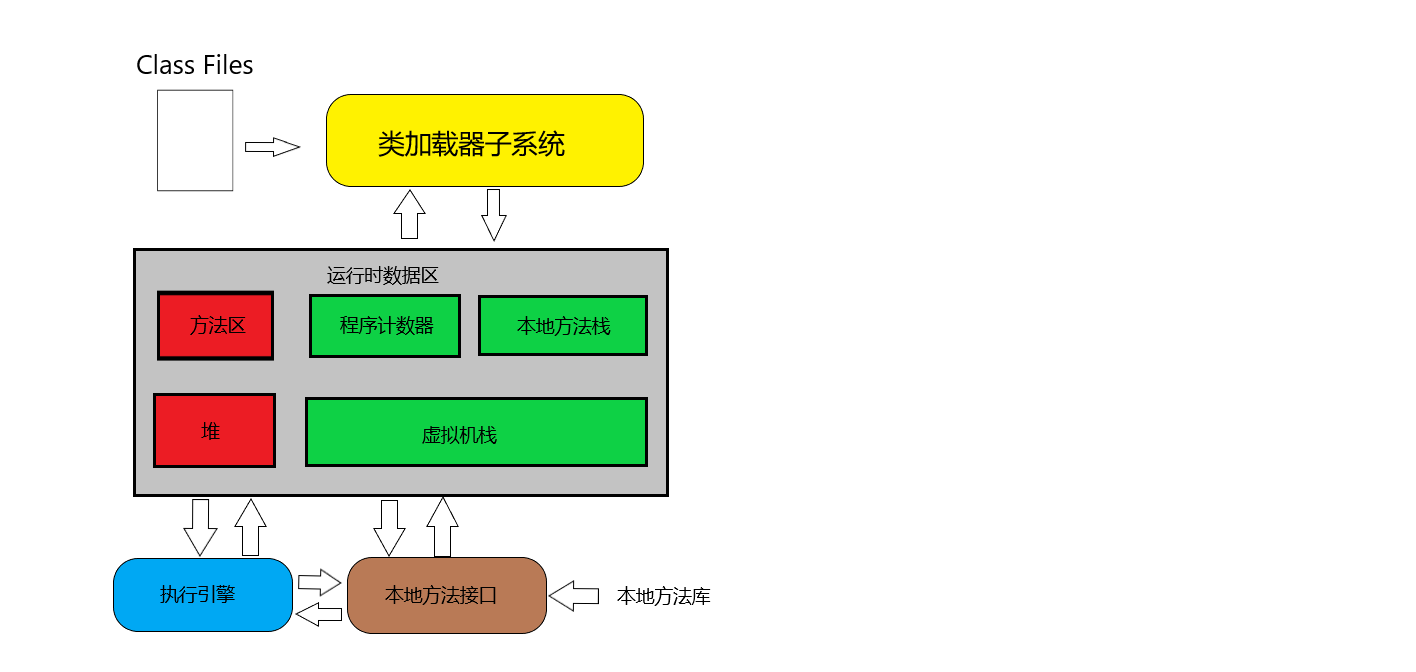
中间这块运行时数据区就是JVM内存模型。绿色的为单独线程私有,红色的为多个线程共享。整个运行时数据区就是一个Runtime,每个JVM只有一个Runtime实例。
在HotSpot JVM 中,每个线程都与操作系统的本地线程直接映射。当一个Java线程准备好执行以后,此时一个操作系统的本地线程也同时创建。Java线程执行终止后,本地线程也会回收。操作系统负责所有线程的安排调度到任何一个key的CPU上。一旦本地线程初始化成功,他就会调用Java线程的run() 方法。
如果使用jconsole或者其他调试工具,都能看到后台有许多线程在运行。这些后台线程不包括调用 public static void main(String[])的main线程以及所有这个main线程自己创建的线程。
这些主要的后台系统线程在HotSpot JVM里主要是以下几个:
- 虚拟机线程:这种线程的操作是需要JVM达到安全点才会出现。这些操作必须在不同的线程中发生的原因是它们都需要JVM达到安全点,这样堆才不会变化。这种线程的执行类型包括“stop-the-world”的垃圾收集,线程栈收集,线程挂起以及偏向锁撤销。
- 周期任务线程:这种线程时时间周期时间的体现(比如中断),它们一般用于周期性操作的调度执行。
- GC线程:这种线程对在JVM里不同种类的垃圾收集行为提供了支持。
- 编译线程:这种线程在运行时会将字节码编译成本地代码。
- 信号调度线程:这种线程接收信号并发送给JVM,在它内部通过调用适当的方法进行处理。
程序计数器
程序计数器(Program Counter Register)的Register 命名源于CPU的寄存器,寄存器存储指令相关的现场信息,CPU只有把数据加载到寄存器才能够运行。它是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在Java 虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,他是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器来完成。
由于Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个时刻,一个CPU(对于多核处理器来说是一个内核)都只会处理一条指令。为了线程切换后能恢复到正确的执行位置,每个线程都需要有一个独立的程序计数器来记住这个线程下一条指令的位置。如果线程执行的是Java 方法,记录的是正在执行的虚拟机字节码指令的地址;如果执行的是本地(native)方法,这个计数器值为空(undefined)。此内存区域是唯一一个在《Java 虚拟机规范》中没有规定任何 OutOfMemoryError 情况的区域。
新建demo:

public class PCRegisterTest {
public static void main(String[] args) {
int i = 10;
int j = 20;
int k = i + j;
String s = "hello world";
System.out.println(i);
System.out.println(k);
}
}复制
找到 PCRegisterTest.class 文件,执行以下命令
javap -v PCRegisterTest.class复制
介绍下 javap 指令
查看官方文档
https://docs.oracle.com/javase/8/docs/technotes/tools/windows/javap.html#BEHHDJGA
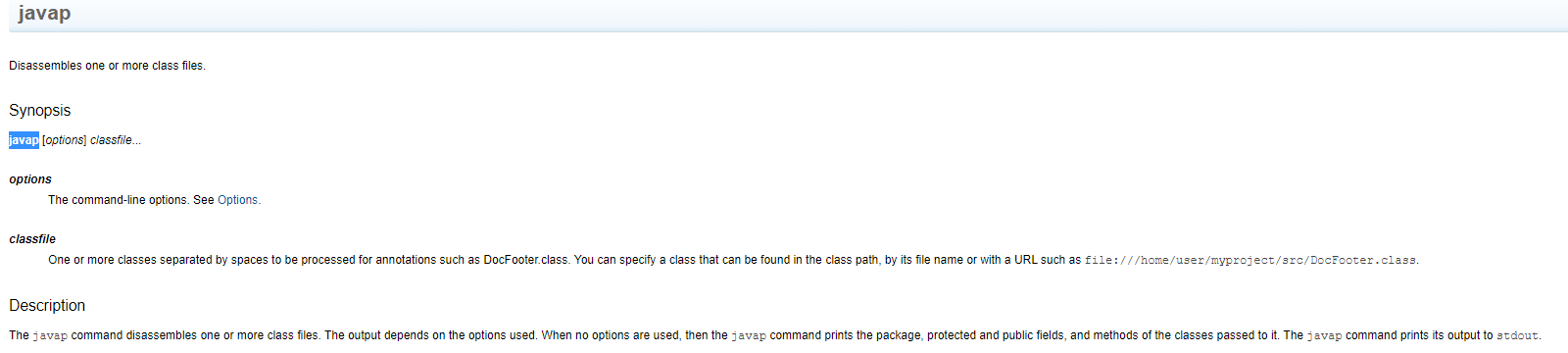
Description
The javap command disassembles one or more class files. The output depends on the options used. When no options are used, then the javap command prints the package, protected and public fields, and methods of the classes passed to it. The javap command prints its output to stdout.
大意:javap 命令反汇编一个或多个类文件。 输出取决于使用的选项。 如果不使用任何选项,则 javap 命令会打印包、受保护和公共字段以及传递给它的类的方法。 javap 命令将其输出打印到标准输出。
执行以后会出现以下内容:
Classfile /D:/study-demo/netty_study/out/production/netty_study/com/xiaojie/jvm/PCRegisterTest.class
Last modified 2021-11-23; size 681 bytes
MD5 checksum be45c601e2571344574e85952671669d
Compiled from "PCRegisterTest.java"
public class com.xiaojie.jvm.PCRegisterTest
minor version: 0 //副版本
major version: 52 //主版本
flags: ACC_PUBLIC, ACC_SUPER //访问标识
Constant pool:
#1 = Methodref #6.#26 // java/lang/Object."<init>":()V
#2 = String #27 // hello world
#3 = Fieldref #28.#29 // java/lang/System.out:Ljava/io/PrintStream;
#4 = Methodref #30.#31 // java/io/PrintStream.println:(I)V
#5 = Class #32 // com/xiaojie/jvm/PCRegisterTest
#6 = Class #33 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lcom/xiaojie/jvm/PCRegisterTest;
#14 = Utf8 main
#15 = Utf8 ([Ljava/lang/String;)V
#16 = Utf8 args
#17 = Utf8 [Ljava/lang/String;
#18 = Utf8 i
#19 = Utf8 I
#20 = Utf8 j
#21 = Utf8 k
#22 = Utf8 s
#23 = Utf8 Ljava/lang/String;
#24 = Utf8 SourceFile
#25 = Utf8 PCRegisterTest.java
#26 = NameAndType #7:#8 // "<init>":()V
#27 = Utf8 hello world
#28 = Class #34 // java/lang/System
#29 = NameAndType #35:#36 // out:Ljava/io/PrintStream;
#30 = Class #37 // java/io/PrintStream
#31 = NameAndType #38:#39 // println:(I)V
#32 = Utf8 com/xiaojie/jvm/PCRegisterTest
#33 = Utf8 java/lang/Object
#34 = Utf8 java/lang/System
#35 = Utf8 out
#36 = Utf8 Ljava/io/PrintStream;
#37 = Utf8 java/io/PrintStream
#38 = Utf8 println
#39 = Utf8 (I)V
{
public com.xiaojie.jvm.PCRegisterTest();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/xiaojie/jvm/PCRegisterTest;
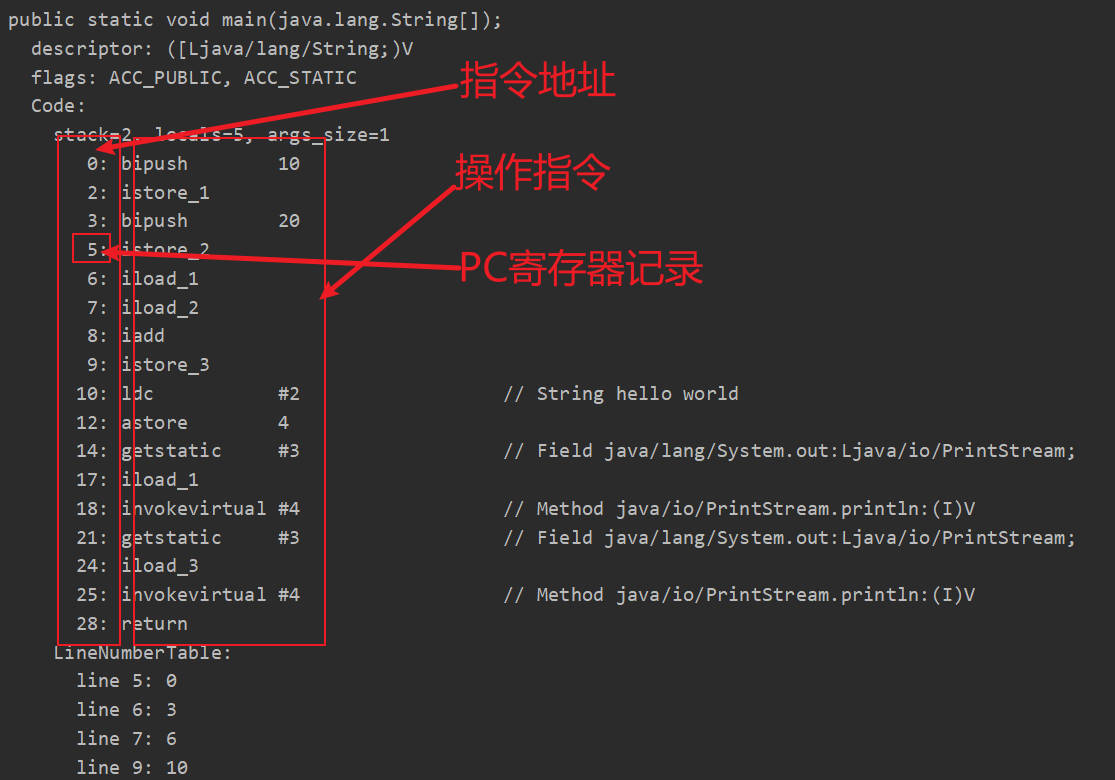
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=5, args_size=1
0: bipush 10
2: istore_1
3: bipush 20
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: ldc #2 // String hello world
12: astore 4
14: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
17: iload_1
18: invokevirtual #4 // Method java/io/PrintStream.println:(I)V
21: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
24: iload_3
25: invokevirtual #4 // Method java/io/PrintStream.println:(I)V
28: return
LineNumberTable:
line 5: 0
line 6: 3
line 7: 6
line 9: 10
line 10: 14
line 11: 21
line 12: 28
LocalVariableTable:
Start Length Slot Name Signature
0 29 0 args [Ljava/lang/String;
3 26 1 i I
6 23 2 j I
10 19 3 k I
14 15 4 s Ljava/lang/String;
}
SourceFile: "PCRegisterTest.java"复制
如果需要打印私有的属性、方法并输出到文本文档上,可以使用以下命令:
javap -v -p PCRegisterTest.class > PCRegisterTest.txt复制
Java虚拟机栈
由于跨平台的设计,Java的指令都是根据栈来设计的。不同平台CPU架构不同,所以不能设计为基于寄存器的。优点是跨平台,指令集小,编译器容易实现,缺点是性能下降,实现同样的功能需要更多地指令。
与程序计数器一样,Java虚拟机栈也是线程私有的,它的生命周期与线程相同。 虚拟机栈描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口和一些附加信息等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
即使两个线程正在执行完全相同的代码,但每个线程都会在自己的虚拟机栈内创建对应代码中声明的局部变量。 所以每个线程都有一份自己的局部变量副本。
局部变量表也被称为局部变量数组或本地变量表,定义为一个数字数组,主要用于存储方法参数和定义在方法体内的局部变量,这些数据类型包括编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它并不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址)。
这些数据类型在局部变量表中的存储空间以局部变量槽(Slot)来表示,即最基本的存储单元是Slot,相当于数组的一个元素。其中64位长度的long和double类型的数据会占用两个变量槽,其余的数据类型只占用一个。byte、short、char、float 在存储前被转换为int,boolean 也被转换为int,0 表示false,非0表示 true。局部变量表所需的内存空间在编译期间完成分配,并保存在方法的Code属性的 maximum local variables 数据项中。当进入一个方法时,这个方法需要在栈帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。这里说的“大小”是指变量槽的数量,虚拟机真正使用多大的内存空间(譬如按照一个变量槽占用32个比特、64个比特,或者更多)来实现一个变量槽,这是完全由具体的虚拟机实现自行决定的事情。boolean、byte、char、short 这四种类型,在栈上占用的空间和 int 是一样的,和引用类型也是一样的。因此,在 32 位的 HotSpot 中,这些类型在栈上将占用 4 个字节;而在 64 位的 HotSpot 中,他们将占 8 个字节。
在《Java虚拟机规范》中,允许Java虚拟机栈的大小可以是动态的,也可以是固定不变的。如果采用固定大小的Java虚拟机栈,那每一个线程的Java虚拟机栈容量可以在线程创建的时候独立选定。如果线程请求分配的栈容量超过Java虚拟机栈允许的最大容量,Java虚拟机将会抛出一个StackOverflowError异常。如果Java虚拟机栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新线程时没有足够的内存去创建对应的虚拟机栈,那Java虚拟机将会抛出一个OutOfMemory异常。HotSpot虚拟机的栈容量是不可以动态扩展的,以前的Classic虚拟机是可以的,所以HotSpot虚拟机上是不会由于虚拟机栈无法扩展而导致OutOfMemoryError异常。只要线程申请栈空间成功了就不会有OOM,但是如果申请时就失败,还是会出现OOM的。
- 线程可以将一个原生变量值的副本传给另一个线程,但不能共享原生局部变量本身。
- 堆内存中包含了 Java 代码中创建的所有对象,不管是哪个线程创建的。 其中也涵盖了包装类型(例如Byte,Integer,Long等)。
- 不管是创建一个对象并将其赋值给局部变量, 还是赋值给另一个对象的成员变量, 创建的对象都会被保存到堆内存中。
- 如果是原生数据类型的局部变量,那么它的内容就全部保留在线程栈上。
- 如果是对象引用,则栈中的局部变量槽位中保存着对象的引用地址,而实际的对象内容保存在堆中。
- 对象的成员变量与对象本身一起存储在堆上, 不管成员变量的类型是原生数值,还是对象引用。
- 类的静态变量则和类定义一样都保存在堆中。
总结一下:原始数据类型和对象引用地址在栈上;对象、对象成员与类定义、静态变量在堆上。
设置栈内存大小:
使用-Xss选项来设置线程的最大栈空间
可以到官方文档处查找
https://docs.oracle.com/javase/8/docs/technotes/tools/windows/index.html
打开官网,找到 Create and Build Applications,点击 java

找到-Xsssize

栈帧
在运行过程中,每当调用进入一个 Java 方法,Java 虚拟机会在当前线程的 Java 方法栈中生成一个栈帧,用以存放局部变量以及字节码的操作数。这个栈帧的大小是提前计算好的,而且 Java 虚拟机不要求栈帧在内存空间里连续分布。在一条活动线程中,一个时间点上,只会有一个活动的栈帧。即只有当前正在执行的方法的栈帧(栈顶栈帧)是有效的,这个栈帧被称为当前栈帧(Current Frame),与当前栈帧对应的方法就是当前方法(Current Method),定义这个方法的类就是当前类(Current Class)。执行引擎运行的所有字节码指令只针对当前栈帧进行操作。如果在该方法中调用了其他方法,对应新的栈帧会被创建出来,放在栈的顶端,称为新的当前栈帧。
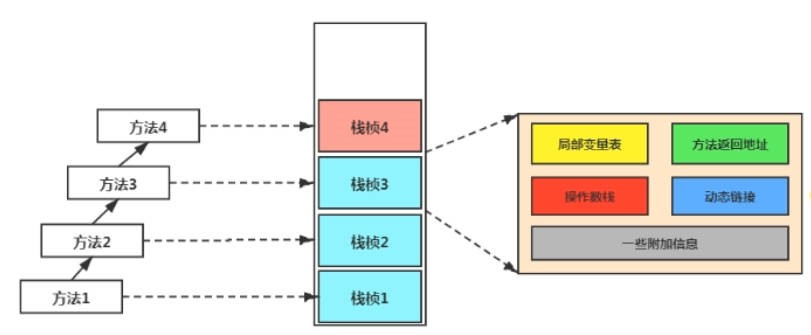
每个栈帧中存储着:
- 局部变量表(Local Variables)
- 操作数栈(Operand Stack)(表达式栈)
- 动态链接(Dynamic Linking)(指向运行时常量池的方法引用)
- 方法返回地址(Return Address)(方法正常退出或者异常退出的定义)
- 一些附加信息
局部变量表
新建demo:
public class LocalVariablesTest {
private int count = 0;
public static void main(String[] args) {
LocalVariablesTest localVariablesTest = new LocalVariablesTest();
int num = 10;
double a = 10.0;
long b = 10L;
localVariablesTest.test1();
}
private void test1() {
Date date = new Date();
String name = "hello world";
String info = test2(date, name);
System.out.println(date + name);
}
private String test2(Date date, String name) {
date = null;
name = "张三";
return date + name;
}
private void test3(Date date, String name) {
count++;
}
}复制
执行
javap -v LocalVariablesTest.class复制
出现以下内容
Classfile /D:/study-demo/netty_study/out/production/netty_study/com/xiaojie/jvm/LocalVariablesTest.class
Last modified 2021-11-23; size 1552 bytes
MD5 checksum 18021d93c46967f4d55b5f24286b4ed3
Compiled from "LocalVariablesTest.java"
public class com.xiaojie.jvm.LocalVariablesTest
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #22.#54 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#55 // com/xiaojie/jvm/LocalVariablesTest.count:I
#3 = Class #56 // com/xiaojie/jvm/LocalVariablesTest
#4 = Methodref #3.#54 // com/xiaojie/jvm/LocalVariablesTest."<init>":()V
#5 = Double 10.0d
#7 = Long 10l
#9 = Methodref #3.#57 // com/xiaojie/jvm/LocalVariablesTest.test1:()V
#10 = Class #58 // java/util/Date
#11 = Methodref #10.#54 // java/util/Date."<init>":()V
#12 = String #59 // hello world
#13 = Methodref #3.#60 // com/xiaojie/jvm/LocalVariablesTest.test2:(Ljava/util/Date;Ljava/lang/String;)Ljava/lang/String;
#14 = Fieldref #61.#62 // java/lang/System.out:Ljava/io/PrintStream;
#15 = Class #63 // java/lang/StringBuilder
#16 = Methodref #15.#54 // java/lang/StringBuilder."<init>":()V
#17 = Methodref #15.#64 // java/lang/StringBuilder.append:(Ljava/lang/Object;)Ljava/lang/StringBuilder;
#18 = Methodref #15.#65 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#19 = Methodref #15.#66 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#20 = Methodref #67.#68 // java/io/PrintStream.println:(Ljava/lang/String;)V
#21 = String #69 // 张三
#22 = Class #70 // java/lang/Object
#23 = Utf8 count
#24 = Utf8 I
#25 = Utf8 <init>
#26 = Utf8 ()V
#27 = Utf8 Code
#28 = Utf8 LineNumberTable
#29 = Utf8 LocalVariableTable
#30 = Utf8 this
#31 = Utf8 Lcom/xiaojie/jvm/LocalVariablesTest;
#32 = Utf8 main
#33 = Utf8 ([Ljava/lang/String;)V
#34 = Utf8 args
#35 = Utf8 [Ljava/lang/String;
#36 = Utf8 localVariablesTest
#37 = Utf8 num
#38 = Utf8 a
#39 = Utf8 D
#40 = Utf8 b
#41 = Utf8 J
#42 = Utf8 test1
#43 = Utf8 date
#44 = Utf8 Ljava/util/Date;
#45 = Utf8 name
#46 = Utf8 Ljava/lang/String;
#47 = Utf8 info
#48 = Utf8 test2
#49 = Utf8 (Ljava/util/Date;Ljava/lang/String;)Ljava/lang/String;
#50 = Utf8 test3
#51 = Utf8 (Ljava/util/Date;Ljava/lang/String;)V
#52 = Utf8 SourceFile
#53 = Utf8 LocalVariablesTest.java
#54 = NameAndType #25:#26 // "<init>":()V
#55 = NameAndType #23:#24 // count:I
#56 = Utf8 com/xiaojie/jvm/LocalVariablesTest
#57 = NameAndType #42:#26 // test1:()V
#58 = Utf8 java/util/Date
#59 = Utf8 hello world
#60 = NameAndType #48:#49 // test2:(Ljava/util/Date;Ljava/lang/String;)Ljava/lang/String;
#61 = Class #71 // java/lang/System
#62 = NameAndType #72:#73 // out:Ljava/io/PrintStream;
#63 = Utf8 java/lang/StringBuilder
#64 = NameAndType #74:#75 // append:(Ljava/lang/Object;)Ljava/lang/StringBuilder;
#65 = NameAndType #74:#76 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#66 = NameAndType #77:#78 // toString:()Ljava/lang/String;
#67 = Class #79 // java/io/PrintStream
#68 = NameAndType #80:#81 // println:(Ljava/lang/String;)V
#69 = Utf8 张三
#70 = Utf8 java/lang/Object
#71 = Utf8 java/lang/System
#72 = Utf8 out
#73 = Utf8 Ljava/io/PrintStream;
#74 = Utf8 append
#75 = Utf8 (Ljava/lang/Object;)Ljava/lang/StringBuilder;
#76 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;
#77 = Utf8 toString
#78 = Utf8 ()Ljava/lang/String;
#79 = Utf8 java/io/PrintStream
#80 = Utf8 println
#81 = Utf8 (Ljava/lang/String;)V
{
public com.xiaojie.jvm.LocalVariablesTest();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_0
6: putfield #2 // Field count:I
9: return
LineNumberTable:
line 5: 0
line 6: 4
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this Lcom/xiaojie/jvm/LocalVariablesTest;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=7, args_size=1
0: new #3 // class com/xiaojie/jvm/LocalVariablesTest
3: dup
4: invokespecial #4 // Method "<init>":()V
7: astore_1
8: bipush 10
10: istore_2
11: ldc2_w #5 // double 10.0d
14: dstore_3
15: ldc2_w #7 // long 10l
18: lstore 5
20: aload_1
21: invokespecial #9 // Method test1:()V
24: return
LineNumberTable:
line 9: 0
line 10: 8
line 11: 11
line 12: 15
line 13: 20
line 14: 24
LocalVariableTable:
Start Length Slot Name Signature
0 25 0 args [Ljava/lang/String;
8 17 1 localVariablesTest Lcom/xiaojie/jvm/LocalVariablesTest;
11 14 2 num I
15 10 3 a D
20 5 5 b J
}
SourceFile: "LocalVariablesTest.java"复制
拿main方法举例:
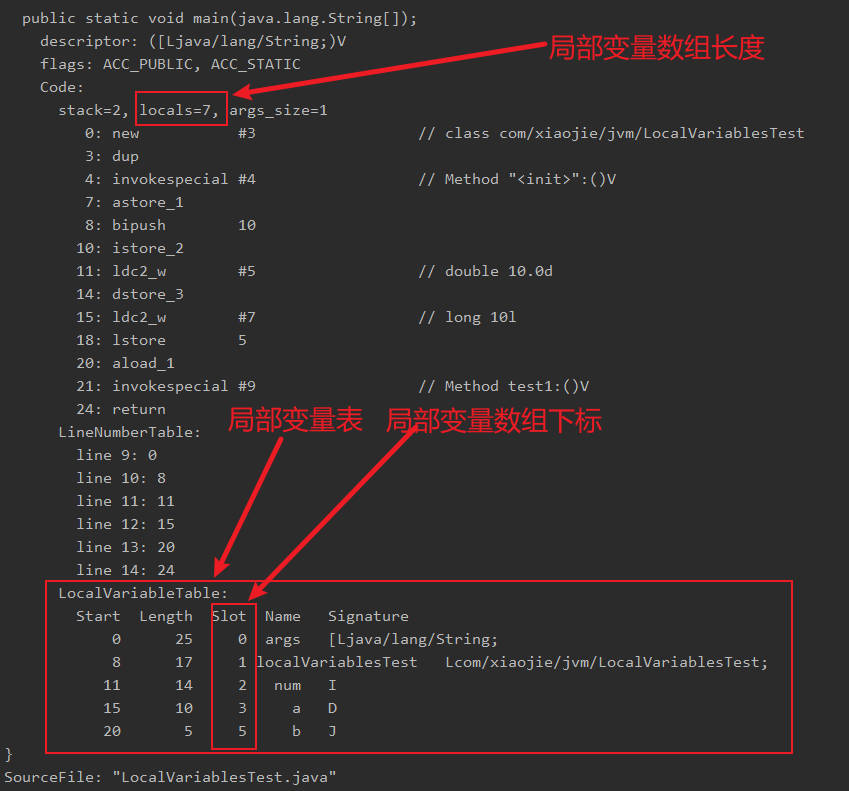
非静态方法的局部变量表中,下标为0的变量是this,静态方法则是参数。
也可以使用工具 jclasslib bytecode viewer
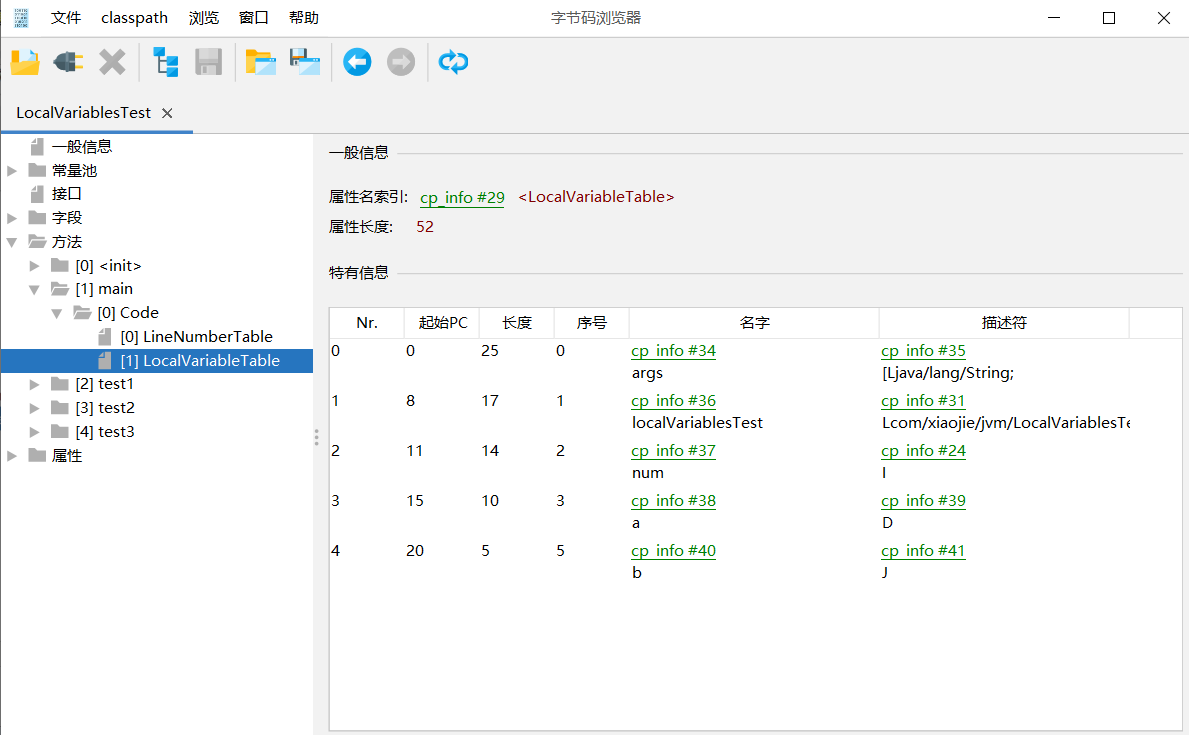
上图中 起始PC就是字节码的位置,起始PC+长度就是 局部变量的作用域范围,序号就是在局部变量数组的位置即下标,名字就是变量名,描述符中 "[" 指代数组,"L" 指代引用类型,
也可以使用idea的插件 jclasslib bytecode viewer 可以看到 局部变量最大槽数为 7,即局部变量数组长度为7。

JVM 会为局部变量表中的每一个Slot都分配一个访问索引,通过这个索引即可成功访问到局部变量表中指定的局部变量值,当一个实例方法被调用的时候,它的方法参数和方法体内部定义的局部变量将会按照顺序被复制到局部变量表中的每一个Slot上。如果需要访问局部变量表中一个64bit的局部变量值时,只需要使用前一个索引即可。比如访问的是long或double类型。如果当前帧是由构造方法或者实例方法创建的,那么该对象引用this将会存放在index为0 的slot处,其余的参数按照参数表顺序继续排列。栈帧中的局部变量表中的槽位是可以复用的,如果一个局部变量过了作用域,那么在其作用域之后申明的新的局部变量就很有可能会复用过期局部变量的槽位,从而达到节省资源的目的。
增加方法四
private void test4() {
int a = 0;
{
int b = 0;
b = a + 1;
}
int c = a + 1;
}复制
查看字节码
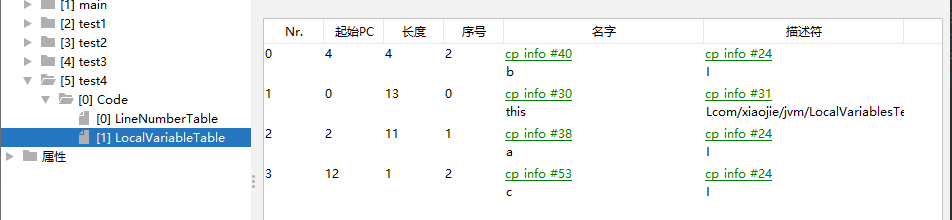

变量c使用之前已经销毁的变量b占据的slot的位置,而变量b的起始PC+长度 并不是13,因为它是方法体内的变量,作用域没有那么大。
变量的分类
按照数据类型分:
- 基本数据类型
- 引用数据类型
按照类中声明的位置分:
- 成员变量:在使用前,都经历过默认初始化赋值
- 类变量:链接的准备阶段:给类变量默认赋值,初始化阶段:给类变量显示赋值
- 实例变量:随着对象的创建,会在堆空间中分配实例变量空间,并进行默认赋值
- 局部变量:在使用前,必须进行显示赋值,否则,编译不通过
补充说明
在栈帧中,与性能调优关系最为密切的部分就是前面提到的局部变量表。在方法执行时,虚拟机使用局部变量表完成方法的传递。
局部变量表中的变量也是重要的垃圾回收根节点,只要被局部变量表中直接或间接引用的对象都不会被回收。
在 Java 虚拟机规范中,局部变量区等价于一个数组,并且可以用正整数来索引。除了 long、double 值需要用两个数组单元来存储之外,其他基本类型以及引用类型的值均占用一个数组单元。也就是说,boolean、byte、char、short 这四种类型,在栈上占用的空间和 int 是一样的,和引用类型也是一样的。因此,在 32 位的 HotSpot 中,这些类型在栈上将占用 4 个字节;而在 64 位的 HotSpot 中,他们将占 8 个字节。当然,这种情况仅存在于局部变量,而并不会出现在存储于堆中的字段或者数组元素上。对于 byte、char 以及 short 这三种类型的字段或者数组单元,它们在堆上占用的空间分别为一字节、两字节,以及两字节,也就是说,跟这些类型的值域相吻合。
因此,当我们将一个 int 类型的值,存储到这些类型的字段或数组时,相当于做了一次隐式的掩码操作。举例来说,当我们把 0xFFFFFFFF(-1)存储到一个声明为 char 类型的字段里时,由于该字段仅占两字节,所以高两位的字节便会被截取掉,最终存入“\uFFFF”。boolean 字段和 boolean 数组则比较特殊。在 HotSpot 中,boolean 字段占用一字节,而 boolean 数组则直接用 byte 数组来实现。为了保证堆中的 boolean 值是合法的,HotSpot 在存储时显式地进行掩码操作,也就是说,只取最后一位的值存入 boolean 字段或数组中。
Java 虚拟机的算数运算几乎全部依赖于操作数栈。也就是说,我们需要将堆中的 boolean、byte、char 以及 short 加载到操作数栈上,而后将栈上的值当成 int 类型来运算。对于 boolean、char 这两个无符号类型来说,加载伴随着零扩展。举个例子,char 的大小为两个字节。在加载时 char 的值会被复制到 int 类型的低二字节,而高二字节则会用 0 来填充。对于 byte、short 这两个类型来说,加载伴随着符号扩展。举个例子,short 的大小为两个字节。在加载时 short 的值同样会被复制到 int 类型的低二字节。如果该 short 值为非负数,即最高位为 0,那么该 int 类型的值的高二字节会用 0 来填充,否则用 1 来填充。
操作数栈
每一个独立的栈帧中除了包含局部变量表以外,还包含一个后进先出(Last-In-First-Out)的操作数栈,也可以称之为表达式栈(Expression Stack)。
操作数栈,在方法执行过程中,根据字节码指令,往栈中写入数据或提取数据,即入栈和出栈。某些字节码指令将值压入操作数栈,其余的字节码指令将操作数从栈中取出,使用它们后再把结果压入栈。比如:执行复制、交换、求和等操作。也可以这样说,操作数栈,主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间。
操作数栈是JVM执行引擎的一个工作区,当一个方法刚开始执行的时候,一个新的栈帧也会随之被创建出来,此时这个方法的操作数栈是空的。
每一个操作数栈都会拥有一个明确的栈深度用于存储数值,其所需的最大深度在编译器就定义好了,保存在方法的Code属性中,为max_stack的值。

jclasslib bytecode viewer 插件
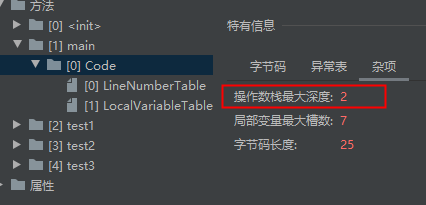
操作数栈中的任何一个元素都可以是任意的Java数据类型。
- 32bit的类型占用一个栈单位深度。
- 64bit的类型占用两个栈单位深度。
操作数栈并不能采用访问索引的方式来进行数据访问,而是通过标准的入栈和出栈操作来完成一次数据访问。
如果被调用的方法带有返回值的话,其返回值将会被压入当前栈帧的操作数栈中,并更新PC寄存器中下一条需要执行的字节码指令。
操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,这由编译器在编译期进行验证,同时在类加载过程中的类检验阶段的数据流分析阶段再次验证。另外,我们说的Java虚拟机的解释引擎是基于栈的执行引擎,其中的栈指的就是操作数栈。
代码说明:
新建demo
public class OperationStackTest {
public void testAddOperation() {
byte i = 15;
int j = 8;
int k = i + j;
int l = 127;
int m = 128;
int g = 32767;
int n = 32768;
boolean a = true;
boolean b = false;
}
}复制
使用 javap -v 反编译,得到以下结果
Classfile /D:/tmp/spring-study/target/classes/com/fhj/jvm/OperationStackTest.class
Last modified 2021-12-3; size 592 bytes
MD5 checksum a157d217bd30ed90bb55cdbc3660e0f7
Compiled from "OperationStackTest.java"
public class com.fhj.jvm.OperationStackTest
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #4.#27 // java/lang/Object."<init>":()V
#2 = Integer 32768
#3 = Class #28 // com/fhj/jvm/OperationStackTest
#4 = Class #29 // java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Utf8 LineNumberTable
#9 = Utf8 LocalVariableTable
#10 = Utf8 this
#11 = Utf8 Lcom/fhj/jvm/OperationStackTest;
#12 = Utf8 testAddOperation
#13 = Utf8 i
#14 = Utf8 B
#15 = Utf8 j
#16 = Utf8 I
#17 = Utf8 k
#18 = Utf8 l
#19 = Utf8 m
#20 = Utf8 g
#21 = Utf8 n
#22 = Utf8 a
#23 = Utf8 Z
#24 = Utf8 b
#25 = Utf8 SourceFile
#26 = Utf8 OperationStackTest.java
#27 = NameAndType #5:#6 // "<init>":()V
#28 = Utf8 com/fhj/jvm/OperationStackTest
#29 = Utf8 java/lang/Object
{
public com.fhj.jvm.OperationStackTest();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/fhj/jvm/OperationStackTest;
public void testAddOperation();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=10, args_size=1
0: bipush 15
2: istore_1
3: bipush 8
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: bipush 127
12: istore 4
14: sipush 128
17: istore 5
19: sipush 32767
22: istore 6
24: ldc #2 // int 32768
26: istore 7
28: iconst_1
29: istore 8
31: iconst_0
32: istore 9
34: return
LineNumberTable:
line 5: 0
line 6: 3
line 7: 6
line 9: 10
line 10: 14
line 11: 19
line 12: 24
line 13: 28
line 14: 31
line 15: 34
LocalVariableTable:
Start Length Slot Name Signature
0 35 0 this Lcom/fhj/jvm/OperationStackTest;
3 32 1 i B
6 29 2 j I
10 25 3 k I
14 21 4 l I
19 16 5 m I
24 11 6 g I
28 7 7 n I
31 4 8 a Z
34 1 9 b Z
}
SourceFile: "OperationStackTest.java"复制
分析方法 testAddOperation 的字节码:
0: bipush 15
2: istore_1
3: bipush 8
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: bipush 127
12: istore 4
14: sipush 128
17: istore 5
19: sipush 32767
22: istore 6
24: ldc #2 // int 32768
26: istore 7
28: iconst_1
29: istore 8
31: iconst_0
32: istore 9
34: return复制
- bipush 15:b指代byte类型,由于需要验证,即使参数定义的时候使用 int,字节码中的指令还是会根据值,转换为相应的类型。像参数 l 和 m ,定义的时候使用 int,字节码中一个为bipush,一个为sipush。 而 boolean 类型,true 为 iconst_1,false 为iconst_0;栈帧初始化时,局部变量表和操作数栈都是空的,PC寄存器记录的是0。push指令 操作将15压入操作数栈。
- istore_1: i指代int,因为 byte、short、boolean 存入局部变量表都会转换为 int 类型。store 指令将数据从操作数栈取出,存入局部变量表。_1 指代局部变量表中索引为1的位置,因为0已经被this占用了。
- 同理,bipush 8 将8压入操作数栈
- istore_2 指令将8从操作数栈取出,存入局部变量表,位置为索引为2的地方。
- iload_1:将局部变量表中索引为1的数据取出放入操作数栈。
- iload_2:将局部变量表中索引为2的数据取出放入操作数栈。
- iadd:将操作数栈的数据出栈,然后执行引擎将iadd字节码指令翻译为机器指令,执行相加操作,将出栈的两个数据相加,并将运算结果入栈。
- istore_3:将23从操作数栈中取出,存入局部变量表,位置为索引3的地方。
- 后续的指令只是用来展示,不细说。
- return:结束方法
演示有返回值的情况:
新增以下两个方法
public int getSum() {
byte i = 15;
int j = 8;
int k = i + j;
return k;
}
public void testGetSum() {
int j = getSum();
}复制
反编译:
public int getSum();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=1
0: bipush 15
2: istore_1
3: bipush 8
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: iload_3
11: ireturn
LineNumberTable:
line 18: 0
line 19: 3
line 20: 6
line 21: 10
LocalVariableTable:
Start Length Slot Name Signature
0 12 0 this Lcom/fhj/jvm/OperationStackTest;
3 9 1 i B
6 6 2 j I
10 2 3 k I
public void testGetSum();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=2, args_size=1
0: aload_0
1: invokevirtual #3 // Method getSum:()I
4: istore_1
5: return
LineNumberTable:
line 25: 0
line 26: 5
LocalVariableTable:
Start Length Slot Name Signature
0 6 0 this Lcom/fhj/jvm/OperationStackTest;
5 1 1 j I
}
SourceFile: "OperationStackTest.java"复制
有返回值的方法最后的指令为 ireturn 。
看 testGetSum() 方法,第一个指令为 aload_0,看下aload 指令的官方描述。

大意为:从局部变量中加载引用,后面的数字必须是当前帧的局部变量数组的索引。指定位置的局部变量必须包含一个引用 reference。指定位置的局部变量中的对象引用 objectref 被压入操作数堆栈。
aload_0 指令作用为 从当前栈帧的局部变量表中获取this对象,将其压入操作数栈,然后调用invokevirtual 方法走到 getSum()方法,getSum()方法返回值会保存在 testGetSum() 的操作数栈的栈顶,istore_1指令将值写到局部变量表。
栈顶缓存技术(Top-of-Stack-Cashing)
之前提过,基于栈式架构的虚拟机所使用的的零地址指令更加紧凑,但完成一项操作的时候必然需要使用更多的入栈和出栈指令,这同时也就意味着将需要更多的指令分配次数和内存读/写次数。由于操作数是存储在内存中的,因此频繁地执行内存读写操作必然会影响执行速度,为了解决这个问题,HotSpot JVM 的设计者们提出了栈顶缓存技术,将栈顶元素全部缓存在物理CPU的寄存器中,以此降低对内存的读写次数,提升执行引擎的执行效率。
动态连接(指向运行时常量池的方法引用)
每个栈帧内部都包含一个指向运行时常量池中该栈帧所属方法的引用。包含这个引用的目的就是为了支持方法调用过程中的动态链接。比如 invokedynamic 指令。Class文件的常量池中存在大量的符号引用。字节码中的方法调用指令就以常量池里指向方法的符号引用作为参数。这些符号引用一部分会在类加载阶段或者第一次使用的时候就被转化为直接引用,这种转化被称为动态解析。另外一部分将在每一次运行期间都转化为直接引用,这部分称为动态连接。
拿上面的字节码说明:

#3 指定的就是上面常量池中的 #3

动态链接其实就是方法的引用。
方法返回地址
退出方法的方式有两种:
- 第一种是执行引擎遇到任意一个方法返回的字节码指令,这时候可能会有返回值传递给上层的方法调用者即调用当前方法的方法,方法是否有返回值以及返回值类型将根据遇到何种返回指令来决定,这种退出方式称为”正常调用完成“。
- 另一种是遇到异常,并且这个异常没有在方法内得到处理,这种方式称为“异常调用完成”。这种方式退出,是不会给方法调用者提供任何返回值。
无论通过哪种方式退出,在方法退出后,都必须返回到该方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层方法调用者的执行状态。一般来说,正常退出,上层方法调用者的PC寄存器的值作为返回地址,栈帧中很可能会保存这个值。而异常退出,返回地址是通过异常处理表来确定的,栈帧一般不会保存这部分信息。
看下异常处理表,新建demo。
public class ReturnAddressTest {
public void method1(String[] args) {
try {
method2();
} catch (IOException e) {
e.printStackTrace();
}
}
public void method2() throws IOException {
FileReader fileReader = new FileReader("xiaojiesir.txt");
char[] buffer = new char[1024];
int len;
while ((len = fileReader.read(buffer)) != -1) {
String str = new String(buffer, 0, len);
System.out.println(str);
}
fileReader.close();
}
}复制
字节码分析:
public void method1(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC
Code:
stack=1, locals=3, args_size=2
0: aload_0
1: invokevirtual #2 // Method method2:()V
4: goto 12
7: astore_2
8: aload_2
9: invokevirtual #4 // Method java/io/IOException.printStackTrace:()V
12: return
Exception table:
from to target type
0 4 7 Class java/io/IOException
LineNumberTable:
line 9: 0
line 12: 4
line 10: 7
line 11: 8
line 13: 12
LocalVariableTable:
Start Length Slot Name Signature
8 4 2 e Ljava/io/IOException;
0 13 0 this Lcom/fhj/jvm/ReturnAddressTest;
0 13 1 args [Ljava/lang/String;
StackMapTable: number_of_entries = 2
frame_type = 71 /* same_locals_1_stack_item */
stack = [ class java/io/IOException ]
frame_type = 4 /* same */复制

from:0 指代字节码的第0行,即源码的第9行,to:4 指代字节码的第4行,源码的12行,合起来就是 try catch 包起来的部分。target 就是处理的字节码行数,源码第 10 行。type 就是异常的类型。
本质上,方法的退出就是当前栈帧出栈的过程。方法正常退出时,可能执行的操作有:恢复上层方法的局部变量表、操作数栈、将返回值压入调用者栈帧的操作数栈、调整PC寄存器值等。调用者的PC寄存器的值作为返回地址,即调用者指令的下一条指令的地址,让调用者方法继续执行下去。
方法返回地址存放的是调用该方法的PC寄存器的值。例如:A方法调用了B方法,会将B方法的栈帧压入栈,执行完B方法后,需要返回A方法,所以需要在B方法栈帧中记录A方法下一步要执行的指令,即PC寄存器的值。因为PC寄存器只存一个值,在执行B方法时,存的都是B的指令序号,如果想回到A方法,就需要事先将A方法的下一步指令存入方法返回地址。
一些附加信息
《Java虚拟机规范》允许虚拟机实现增加一些规范里没有描述的信息到栈帧中,例如与调试、性能收集相关的信息,这部分信息完全取决于具体的虚拟机实现。在讨论概念时,一般会把动态连接,方法返回地址与其他附加信息全部归为一类,称为栈帧信息。
方法调用
在JVM中,将符号引用转换为调用方法的直接引用与方法的绑定机制有关。
- 静态连接:当一个字节码文件被加载进JVM内部时,如果被调用的目标方法在编译期可知,且运行期保持不变时。这种情况下将调用方法的符号引用转换为直接引用的过程称之为静态连接。
- 动态连接:如果被调用的方法在编译期无法被确定下来,也就是说,只能够在程序运行期将调用方法的符号引用转换为直接引用,由于这种引用转换过程具备动态性,因此称之为动态连接。
绑定机制:
对应的方法的机制为:早期绑定和晚期绑定。绑定是一个字段、方法或类在符号引用被替换为直接引用的过程,仅仅发生一次。
- 早期绑定:指被调用的目标方法如果在编译期可知,且运行期保持不变时,即可将这个方法与所属的类型进行绑定,这样一来,由于明确了被调用的目标方法究竟是哪一个,因此也就可以使用静态连接的方式将符号引用转换为直接引用。
- 晚期绑定:如果被调用的方法在编译期无法被确定下来,只能够在程序运行期根据实际的类型绑定相关的方法,这种绑定方式也被称为晚期绑定。
所有方法调用的目标方法在Class文件里面都是一个常量池中的符号引用,在类加载的解析阶段,会将其中的一部分符号引用转化为直接引用,但需要前提:方法在程序真正运行之前就有一个可确定的调用版本,并且这个方法的调用版本在运行期时不可改变的。即调用目标在程序代码写好、编译器进行编译那一刻就已经确定下来。这类方法的调用叫做解析。
在类加载阶段进行解析的方法主要有静态方法和私有方法。前者与类关联,后者在外部不可被访问,所以它们不可能通过继承或别的方式重写,符合“编译器可知,运行期不可变”的要求。
调用不同类型的方法,字节码指令集设计了不同的指令。JVM支持以下5条方法调用字节码指令:
- invokestatic。用于调用静态方法,解析阶段确定唯一方法版本
- invokespecial。用于调用实例构造器<init>()方法、私有方法和父类中的方法,解析阶段确定唯一方法版本。
- invokevirtual。用于调用所有的虚方法。
- invokeinterface。用于调用接口方法,会在运行时在确定一个实现该接口的对象。
- invokedynamic。先在运行时动态解析出需要调用的方法,然后再执行该方法。
前面四条调用指令为普通调用指令,分派逻辑都固化在Java虚拟机内部,方法的调用执行不可人为干预,而invokedynamic指令为动态调用指令,分派逻辑是由用户设定的引导方法来决定的。
只要能被 invokestatic 和 invokespecial指令调用的方法,都可以在解析阶段中确定唯一的调用版本,符合条件的方法有 静态方法、私有方法、实例构造器、父类方法,再加上被final修饰的方法(尽管它使用invokevirtual指令调用),这5种方法调用会在类加载的时候就可以将符号引用解析为直接引用。这些方法统称为“非虚方法”,其他方法就被称为“虚方法”。
JVM字节码指令集一直比较稳定,一直到Java 7 中才增加一个 invokedynamic 指令,这是Java 为了实现动态类型语言支持而做的一种改进。但是Java 7中并没有提供直接生成invokedynamic 指令的方法,需要借助ASM这种底层字节码工具来产生invokedynamic指令。知道Java 8的Lamada 表达式的出现,invokedynamic 指令的生成,在Java中才有了直接的生成方式。Java 7 中增加的动态语言类型支持的本质是对Java虚拟机规范的修改,而不是对Java语言规则的修改,增加了虚拟机中的方法调用,最直接的受益者就是运行在Java平台的动态语言的编译器。
动态类型语言和静态类型语言两者的区别在于对类型的检查是在编译器还是在运行期,满足前者的就是静态类型语言,反之就是动态类型语言。即静态类型语言是判断变量自身的类型信息;动态类型语言是判断变量值的类型信息,变量没有类型信息,变量值才有类型信息,这是动态语言的一个重要特征。
解析调用一定是个静态过程,在编译期就完全确定,在类加载的解析阶段就会把涉及的符号引用全部转变为明确的直接引用,不必延迟到运行期再去完成。而另一种主要的方法调用形式:分派调用就比较复杂了,它可能是静态的也可能是动态的,按照分派依据的宗量数可分为单分派和多分派。组合方式就有 静态单分派,静态多分派、动态单分派、动态多分派4种分派组合情况。
静态分派:
先看下以下代码:
public class StaticDispatch {
static abstract class Human {
}
static class Man extends Human {
}
static class Woman extends Human {
}
public void sayHello(Human guy) {
System.out.println("hello guy");
}
public void sayHello(Man guy) {
System.out.println("hello gentleman");
}
public void sayHello(Woman guy) {
System.out.println("hello lady");
}
public static void main(String[] args) {
Human man = new Man();
Human woman = new Woman();
StaticDispatch staticDispatch = new StaticDispatch();
staticDispatch.sayHello(man);
staticDispatch.sayHello(woman);
}
}复制
运行结果:
hello guy hello guy复制
Human man = new Man(); “Human”称为变量的“静态类型”,或者叫“外观类型”,“Man”被称为变量的“实际类型”,或者叫“运行时类型”。静态类型和实际类型在程序中都可能会发生变化,区别是静态类型的变化仅仅发生在使用时,变量本身的静态类型不会被改变,并且最终的静态类型是在编译期可知的;而实际类型变化的结果是在运行期才确定的,编译器在编译程序的时候并不知道一个对象的实际类型是什么。
上面的例子代码中,main方法里面的两次sayHello方法调用,在方法接收者已经确定是对象“staticDispatch”的前提下,使用那个重载版本,取决于传入参数的数量和数据类型。代码中定义了两个静态类型相同,但实际类型不同的变量,但虚拟机(准确的说是编译器)在重载时是通过参数的静态类型而不是实际类型作为判定依据的,由于静态类型在编译期可知,所以在编译阶段,Javac编译器就根据参数的静态类型决定了会使用那个重载版本,因此选择了sayHello(Human)作为调用目标,并把这个方法的符号引用写到main方法里的两条invokevirtual指令的参数中。
所有依赖静态类型来决定方法执行版本的分派动作,都称为静态分派。最典型应用表现是方法重载。静态分派发生在编译阶段,所以确定静态分派的动作不是由虚拟机来执行的。
虽然Javac编译器能确定方法的重载版本,但是在很多情况下这个版本并不是唯一的,往往只能确定一个相对更适合的版本。例如存在一个方法,有多个重载版本,其参数可以是 char、int、long,character。如果注释掉参数为char的那个方法,但是调用的时候还是传入 char 类型,会发现调用的是 参数为 int 类型的版本。因为它发生了一次自动类型转换,‘a’除了可以代表一个字符,也可以代表数字97,所以 int类型的版本也是正确的。实际上自动转型还会发生好几次,按照 char>int>long>float>double的顺序转型进行匹配,但不会匹配byte 和short 类型的重载,因为char到byte或short的转型是不安全的。同样的,也会调用Character类型的方法,因为自动装箱。还会根据继承关系和实现接口继续往上找。
动态分派
先看下以下代码:
public class DynamicDispatch {
static abstract class Human {
protected abstract void sayHello();
}
static class Man extends Human {
@Override
protected void sayHello() {
System.out.println("hello gentleman");
}
}
static class Woman extends Human {
@Override
protected void sayHello() {
System.out.println("hello lady");
}
}
public static void main(String[] args) {
Human man = new Man();
Human woman = new Woman();
man.sayHello();
woman.sayHello();
man = new Woman();
man.sayHello();
}
}复制
执行结果:
hello gentleman hello lady hello lady复制
这里选择调用的方法版本就不是根据静态类型来决定的。我们使用javap命令看下字节码。
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: new #2 // class com/xiaojie/jvm/DynamicDispatch$Man
3: dup
4: invokespecial #3 // Method com/xiaojie/jvm/DynamicDispatch$Man."<init>":()V
7: astore_1
8: new #4 // class com/xiaojie/jvm/DynamicDispatch$Woman
11: dup
12: invokespecial #5 // Method com/xiaojie/jvm/DynamicDispatch$Woman."<init>":()V
15: astore_2
16: aload_1
17: invokevirtual #6 // Method com/xiaojie/jvm/DynamicDispatch$Human.sayHello:()V
20: aload_2
21: invokevirtual #6 // Method com/xiaojie/jvm/DynamicDispatch$Human.sayHello:()V
24: new #4 // class com/xiaojie/jvm/DynamicDispatch$Woman
27: dup
28: invokespecial #5 // Method com/xiaojie/jvm/DynamicDispatch$Woman."<init>":()V
31: astore_1
32: aload_1
33: invokevirtual #6 // Method com/xiaojie/jvm/DynamicDispatch$Human.sayHello:()V
36: return
LineNumberTable:
line 24: 0
line 25: 8
line 26: 16
line 27: 20
line 28: 24
line 29: 32
line 30: 36
LocalVariableTable:
Start Length Slot Name Signature
0 37 0 args [Ljava/lang/String;
8 29 1 man Lcom/xiaojie/jvm/DynamicDispatch$Human;
16 21 2 woman Lcom/xiaojie/jvm/DynamicDispatch$Human;
}
SourceFile: "DynamicDispatch.java"
InnerClasses:
static #9= #4 of #7; //Woman=class com/xiaojie/jvm/DynamicDispatch$Woman of class com/xiaojie/jvm/DynamicDispatch
static #11= #2 of #7; //Man=class com/xiaojie/jvm/DynamicDispatch$Man of class com/xiaojie/jvm/DynamicDispatch
static abstract #13= #12 of #7; //Human=class com/xiaojie/jvm/DynamicDispatch$Human of class com/xiaojie/jvm/DynamicDispatch复制
0-15行是准备动作,建立man和woman的内存空间、调用Man和Woman类型的实例构造器,将这两个实例的引用存放在第1、2个局部变量表的变量槽中,对应源码的
Human man = new Man();
Human woman = new Woman();
16和20行的aload 指令将两个对象的引用压到栈顶,这两个对象是将要执行的sayHello方法的所有者,称为接收者;17和21 行是方法调用指令,从字节码角度看,无论是指令(都是invokevirtual)还是参数(都是常量池中第6项的常量,注释显示 这个常量是Human.sayHello() 的符号引用)都完全一样,但是两句指令最终执行的目标方法并不相同。所以需要了解 invokevirtual 指令,才能明白原理。
根据《Java虚拟机规范》,invokevirtual 指令的运行时解析过程分为以下几步:
- 找到操作数栈顶的第一个元素所指向的对象的实际类型,记作C。
- 如果在类型C中找到与常量中的描述符和简单名称都相符的方法,则进行访问权限校验,如果通过则返回这个方法的直接引用,查找结束;不通过则返回java.lang.IllegalAccessError异常。
- 否则,按照继承关系从下往上依次对C的各个父类进行第二步的搜索和验证过程。
- 如果始终没有找到合适的方法,则抛出java.lang.AbstractMethodError异常。
正是因为invokevirtual指令执行的第一步是在运行期确定接收者的实际类型,所以两次调用中的invokevirtual指令并不是吧常量池中的方法的符号引用解析到直接引用上就结束了,还会根据方法接收者的实际类型来选择方法版本,这过程就是Java语言中方法重写的本质。这种在运行期根据实际类型确定方法执行版本的分派过程称为动态分派。
字段是没有多态的。
public class FieldHasNoPolymorphic {
static class Father {
public int money = 1;
public Father() {
money = 2;
showMeTheMoney();
}
public void showMeTheMoney() {
System.out.println(" I am Father,i have ¥" + money);
}
}
static class Son extends Father {
public int money = 3;
public Son() {
money = 4;
showMeTheMoney();
}
public void showMeTheMoney() {
System.out.println(" I am Son,i have ¥" + money);
}
}
public static void main(String[] args) {
Father guy = new Son();
System.out.println(" This guy have ¥" + guy.money);
}
}复制
输出结果:
I am Son,i have ¥0 I am Son,i have ¥4 This guy have ¥2复制
输出两句都是“ I am Son”,因为Son类在创建的时候,首先隐式调用了Father的构造函数,而Father的构造函数中对 showMeTheMoney 调用是一次虚方法调用,实际执行的是Son.showMeTheMoney 方法,所以输出的是 “ I am Son”。而这时Father 的money字段虽然被初始化2了,但Son.showMeTheMoney 方法中访问的是Son的money 字段,这时候的结果是0,因为它要到子类的构造函数执行时才会被初始化。main方法的最后一句通过静态类型访问到了父类的money,输出2。
单分派和多分派
方法的接收者与方法的参数统称为方法的宗量。根据分派基于多少种宗量,可以将分派划分为单分派和多分派。单分派是根据一个宗量对目标进行选择,多分派是根据多于一个宗量对目标方法进行选择。
public class Dispatch {
static class QQ {
}
static class _360 {
}
public static class Father {
public void hardChoice(QQ arg) {
System.out.println(" I am Father,i choose qq");
}
public void hardChoice(_360 arg) {
System.out.println(" I am Father,i choose 360");
}
}
public static class Son extends Father {
public void hardChoice(QQ arg) {
System.out.println(" I am Son,i choose qq");
}
public void hardChoice(_360 arg) {
System.out.println(" I am Son,i choose 360");
}
}
public static void main(String[] args) {
Father father = new Father();
Father son = new Son();
father.hardChoice(new _360());
son.hardChoice(new QQ());
}
}复制
运行结果:
I am Father,i choose 360 I am Son,i choose qq复制
main方法中调用了两次 hardChoice 方法。首先,编译阶段中编译器的选择过程,也就是静态分派的过程。这时候选择目标方法的依据有两点:一是静态类型,father还是son,二是参数是QQ还是 360。这次选择会产生两条 invokevirtual 指令,分别指向 Father.hardChoice(360) 及Father.hardChoice(qq) 方法的符号引用。因为根据两个宗量选择,所以静态分派属于多分派类型。
在看下运行阶段虚拟机的选择,即动态分派的过程。执行Son.hardChoice(new QQ()) 时,由于编译期已经决定目标方法的签名必须为 hardChoice(qq) ,虚拟机此时不会关心传递过来的参数“QQ” 实现类是什么,因为这时参数的静态类型,实际类型都对方法的选择不会构成任何影响,唯一可以影响虚拟机选择的因素只有该方法的接受者的实际类型是Father还是Son。因为只有一个宗量作为选择依据,所以动态分派属于单分派类型。
虚拟机动态分派的实现
动态分派是执行非常频繁的动作,而且动态分派的方法版本选择过程需要运行时在接收者类型的方法元数据中搜索合适的目标方法,因此,Java虚拟机实现基于执行性能的考虑,真正运行时一般不会频繁的反复搜索类型元数据。为了应对这种情况,设计了一种优化手段,为类型在方法区建立一个虚方法表,与此对应,在invokeinterface执行时也会用到接口方法表,使用虚方法表所有来代替元数据查找以提高性能。

虚方法表中存放着各个方法的实际入口地址。如果某个方法在子类中没有被重写,那子类的虚方法表中的地址入口和父类相同方法的地址入口是一致的,都指向父类的实现入口。如果子类重写了,子类虚方法表中的地址就会被替换为指向子类实现版本的入口地址。上图中,Son重写了Father的全部方法,所以son的方法表中没有指向Father类型数据的箭头。但是Son和Father都没有重写来自Object的方法,所以它们的方法表中所有从Object继承来的方法都指向了Object的数据类型。
为了程序实现方便,相同签名的方法,父子类的虚方法表中都应当具有一样的索引序号,这样当类型变换时,只需要变更查找的虚方法表,就可以从不同的虚方法表中按索引转换出所需的入口地址。虚方法表一般在类加载的连接阶段进行初始化,准备了类的变量初始值后,虚拟机会把该类的虚方法表也一同初始化完毕。
查虚方法表是分派调用的一种优化手段,由于Java对象里面的方法默认(即不使用final修饰)就是虚方法,虚拟机除了使用虚方法表之外,为了进一步提高性能,还会使用类型继承关系分析、守护内联、内联缓存等多种非稳定的激进优化来争取更大的性能空间。
本地方法栈
本地方法
本地方法:由非Java语言实现,并供Java调用的方法。本地方法的作用是融合不同的编程语言为Java所用。
使用本地方法的原因:
- 与外面的环境交互:例如:Java需要与一些底层系统,如操作系统或某些硬件交换信息。本地方法刚好可以为我们提供一个非常简洁的接口,我们无需去了解Java应用外的细节。
- 与操作系统交互:JVM支持着Java语言本身和运行时库,它是Java程序赖以生存的平台,它由一个解释器(解释字节码)和一些连接到本地代码的库组成。然而不管怎样,它毕竟不是一个完整的系统,它经常依赖于一些底层系统的支持。这些底层系统常常是强大的操作系统。通过本地方法,我们得以用Java实现的jre与底层系统的交互,甚至JVM的一些部分就是用C写的,还有,如果我们要使用一些Java语言本身没有提供封装的操作系统的特性时,我们也需要使用本地方法。
- SUN'S Java:Sun的解释器是用C实现的,这使得它能像一些普通的C一样与外部交互。jre大部分是用Java实现的,它也通过一些本地方法与外界交互。例如:类java.lang.Thread的setPriority()方法是用Java实现的,但是它实际调用的是内部的本地方法setPriority0(),这个方法是用C实现的,并被植入JVM内部,在windows 95的平台上,这个本地方法最终调用win32 SetPriority()API。这是一个本地方法的具体实现由JVM直接提供,更多情况是本地方法由外部的动态链接库(external dynamic link library)提供,然后被JVM调用。
目前本地方法使用的越来越少,除非是和硬件有关的应用,例如:通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。现在的异构领域间的通信很发达,例如socket通信,Web Service等等。
本地方法栈
本地方法栈与虚拟机栈所发挥的作用是非常相似的,其区别只是虚拟机栈为虚拟机执行Java方法服务,而本地方法栈则是为虚拟机使用到的本地方法服务。并不是所有的JVM都支持本地方法,《Java虚拟机规范》对本地方法栈中方法使用的语言、使用方式与数据结构并没有任何强制规定,因此具体的虚拟机可以根据需要自由实现它。如果JVM产品不打算支持native方法,也可以不实现本地方法栈,有些虚拟机直接将本地方法栈和虚拟机栈合二为一,例如HotSpot 虚拟机。与虚拟机栈一样,也是线程私有的,内存大小允许设置为固定或者可动态扩展。本地方法栈也会出现 StackOverflowError 和 OutOfMemoryError异常。
当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。它和虚拟机拥有同样的权限。本地方法可以通过本地方法接口来访问虚拟机内部的运行时数据区,它也可以直接使用本地处理器中的寄存器,能直接从本地内存的堆中分配任意数量的内存。
堆
对于Java应用程序来说,堆是JVM管理的最大一块内存空间, 所有的线程共享Java堆。堆的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。因为由于即时编译技术的进步,尤其是逃逸分析技术的日渐强大,栈上分配、标量替换优化手段已经导致一些微妙的变化悄然发生,所以说Java对象实例都分配在堆上也逐渐变得不是那么绝对了。
一个对象创建的时候,到底是在堆上分配,还是在栈上分配呢?这和两个方面有关:对象的类型和在 Java 类中存在的位置。 Java 的对象可以分为基本数据类型和普通对象。 对于普通对象来说,JVM 会首先在堆上创建对象,然后在其他地方使用的其实是它的引用。比如,把这个引用保存在虚拟机栈的局部变量表中。 对于基本数据类型来说(byte、short、int、long、float、double、char),有两种情况。 我们上面提到,每个线程拥有一个虚拟机栈。当你在方法体内声明了基本数据类型的对象,它就会在栈上直接分配。其他情况,都是在堆上分配。 注意,像 int[] 数组这样的内容,是在堆上分配的。数组并不是基本数据类型。
Java堆是垃圾收集器管理的内存区域。方法结束后。堆中的对象不会马上被移除,仅仅在垃圾收集的时候才会被移除。
堆还会划分线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB),以提升对象分配时的效率和回收效率。
《Java虚拟机规范》规定,堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为是连续的。但对于大对象(如数组对象),多数虚拟机实现出于实现简单、存储高效的考虑,很可能会要求连续的内存空间。
一个JVM实例只存在一个堆内存,堆也是Java内存管理的核心区域。Java堆既可以被实现成固定大小的,也可以是可扩展的,当前主流的Java虚拟机都是按照可扩展来实现的(通过-Xmx和-Xms设定)。Java堆在JVM启动的时候就会被创建,其空间大小也就确定了。一旦堆区中的内存大小超过“-Xmx”所指定的最大内存时,将会抛出OutOfMemoryError异常。通常会将 -Xmx 和 -Xms 两个参数配置相同的值,其目的是为了能够在Java 垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小,从而提高性能。默认情况下,初始内存大小:物理内存大小/64;最大内存大小:物理内存大小/4
public class HeapSpaceInitial {
public static void main(String[] args) {
//返回Java虚拟机中的堆内存总量
long initialMemory = Runtime.getRuntime().totalMemory() / 1024 / 1024;
//返回Java虚拟机试图使用的最大堆内存量
long maxMemory = Runtime.getRuntime().maxMemory() / 1024 / 1024;
System.out.println("-Xms : " + initialMemory + "M");
System.out.println("-Xmx : " + maxMemory + "M");
System.out.println("系统内存大小为:" + initialMemory * 64.0 / 1024 + "G");
System.out.println("系统内存大小为:" + maxMemory * 4.0 / 1024 + "G");
}
}复制
执行结果:
-Xms : 245M -Xmx : 3614M 系统内存大小为:15.3125G 系统内存大小为:14.1171875G复制
堆内存的结构
现代垃圾收集器大部分都基于分代收集理论设计,堆空间细分为:
- java 7 及之前堆内存逻辑上分为三部分:年轻代+老年代+永久代
- Young Generation Space 年轻代 Young/New
- 又被分为Eden区、Survivor0区和Survivor1区
- Tenure Generation Space 老年代 Old/Tenure
- Permanent Space 永久代 Perm
- Young Generation Space 年轻代 Young/New
- Java 8 及之后堆内存逻辑上分为两部分:年轻代+老年代(不包含元空间)
- Young Generation Space 年轻代 Young/New
- 又被分为Eden区、Survivor0区和Survivor1区
- Tenure Generation Space 老年代 Old/Tenure
- Meta Space 元空间 Meta
- Young Generation Space 年轻代 Young/New
约定:新生区=新生代=年轻代 养老区=老年区=老年代 永久区=永久代
默认情况下,年轻代和老年代所占内存的比例是1:2,即年轻代占整个堆的1/3,老年代占2/3。一般我们说的堆是不包括元空间。
在HotSpot中,Eden区和两个 Survivor区所占内存的比例是8:1:1。
配置年轻代与老年代在堆结构的占比
默认:-XX:NewRatio=2,表示年轻代占1,老年代占2。可以修改-XX:NewRatio=4,表示年轻代占1,老年代占4,年轻代占整个堆的1/5。一般不会修改此参数,除非生命周期很长的对象很多。
继续用上面那个demo,增加线程睡眠代码,使用 -Xms600m -Xmx600m 配置JVM,

打开 jvisualvm工具,执行上面的方法,执行结果:
-Xms : 575M -Xmx : 575M复制
会发现少了25M,因为 Survivor区会分成两个区,S0和S1,两个区只能使用一个,所以最大内存会去掉一部分。
jvisualvm工具显示

可以看到 Eden + Survivor0 +Survivor1 为200M,old 为400M,即年轻代和老年代的比例为1:2。
但是 Eden : Survivor0 : Survivor1 = 6:1:1,并不是上文说的8:1:1。因为存在自适应内存分配策略,-XX:+UseAdaptiveSizePolicy UseAdaptiveSizePolicy 前面的+表示启用自适应机制,-表示禁用自适应机制。 但是你会发现,这个参数配不配都没效果。
如果希望三者的比例为8:1:1,则需要配置 -XX:SurvivorRatio=8(配置Eden区与Survivor 区的内存比例)。

配置完以后的效果:

-Xmx:用来设置堆空间(年轻代+老年代)的最大内存大小,等价于-XX:MaxHeapSize。
-Xms:用来设置堆空间(年轻代+老年代)的初始内存大小,等价于-XX:InitialHeapSize。-X 是jvm的运行参数,ms 是memory start
-XX:MetaspaceSize 配置元空间内存大小
-XX:MaxPermSize 配置永久代内存大小
-Xmn:设置年轻代的空间大小
如果同时配置了-Xmn 和 -XX:NewRatio,会以 -Xmn为准,即 优先级 -Xmn 比较高。
几乎所有的Java对象都是在Eden区创建,除非Eden区放不下,才会在老年代创建。绝大部分的Java对象的销毁都在年轻代进行,因为研究表明,年轻代中80%的对象都是朝生夕死的。
TLAB
定义以下方法
public void test(){
User user=new user();
user.setUserName("张三");
}复制
user 对象的作用域是在test() 方法里面,也就是说user 对象的生命周期会随着方法的调用开始而开始,方法的调用结束而结束。
如果JVM所有的对象都放在堆内存中,一旦方法结束,没有了指向该对象的引用,该对象就需要被GC回收,如果存在大量的这种情况,对gc来说无疑是一种负担。对于这种情况,我们应该考虑将对象不在分配在堆空间中。
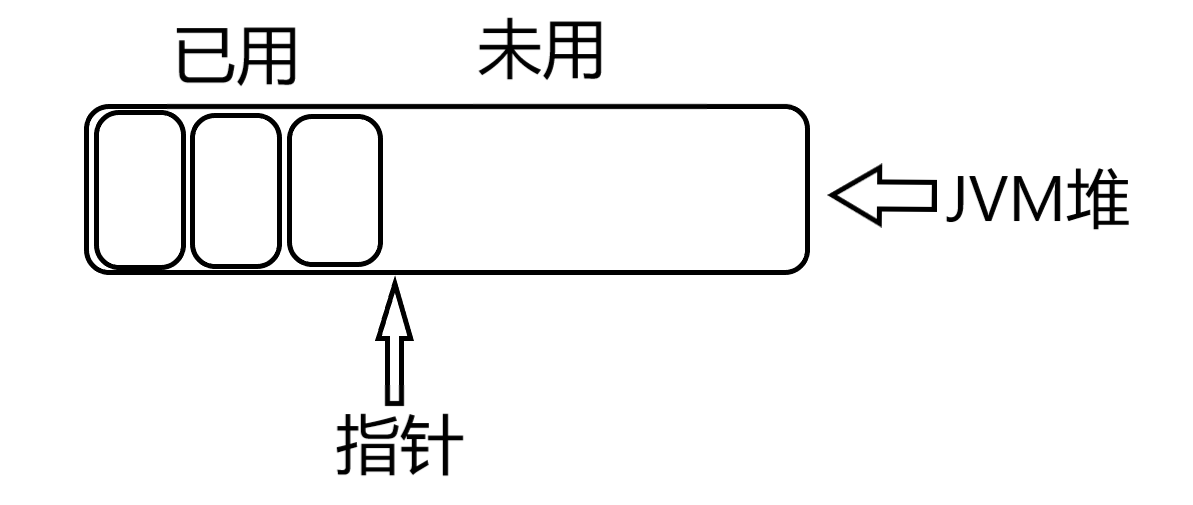
指针碰撞
假设JVM虚拟机上,堆内存都是规整的。堆内存被一个指针一分为二。指针的左边都被塞满了对象,指针的右边是未使用的区域。每一次有新的对象创建,指针就会向右移动一个对象size的距离。这就被称为指针碰撞。
TLAB的全称是Thread Local Allocation Buffer,即线程本地分配缓存区,这是一个线程专用的内存分配区域。
可以这样理解:TLAB就是一种线程私有的堆空间,即使这块堆空间特别小,但是只要有,就可以在每个线程分配对象到堆空间时,先分配到自己所属的那一块堆空间中,避免同步带来的效率问题,从而提高分配效率。
如果设置了虚拟机参数 -XX:UseTLAB,在线程初始化时,同时也会申请一块指定大小的内存,只给当前线程使用,这样每个线程都单独拥有一个空间,如果需要分配内存,就在自己的空间上分配,这样就不存在竞争的情况,可以大大提升分配效率。
TLAB空间的内存非常小,缺省情况下仅占有整个Eden空间的1%,也可以通过选项-XX:TLABWasteTargetPercent设置TLAB空间所占用Eden空间的百分比大小。

如何开启TLAB
JVM默认开启了TLAB功能,也可以使用-XX: +UseTLAB 显示开启
如何观察TLAB使用情况
JVM提供了-XX:+PrintTLAB 参数打开跟踪TLAB的使用情况
如何调整TLAB默认大小
-XX:TLABSize 通过该参数指定分配给每一个线程的TLAB空间的大小
TLAB的本质其实是三个指针管理的区域:start,top 和 end,每个线程都会从Eden分配一块空间,例如说100KB,作为自己的TLAB,其中 start 和 end 是占位用的,标识出 eden 里被这个 TLAB 所管理的区域,卡住eden里的一块空间不让其它线程来这里分配。
TLAB只是让每个线程有私有的分配指针,但底下存对象的内存空间还是给所有线程访问的,只是其它线程无法在这个区域分配而已。从这一点看,它被翻译为 线程私有分配区 更为合理一点。
当一个TLAB用满(分配指针top撞上分配极限end了),就新申请一个TLAB,而在老TLAB里的对象还留在原地什么都不用管——它们无法感知自己是否是曾经从TLAB分配出来的,而只关心自己是在eden里分配的。
TLAB的问题
- 对象的分配优先在 TLAB上 分配,但 TLAB通常很小,放不下大对象,所以大对象还是会在Eden区共享的区域分配。
- 请求的内存大小超出TLAB剩余内存。
- 直接在堆内存中对该对象进行内存分配。如果 TLAB 只剩下 1KB 的空间了,那么后续的大多数对象都需要在堆内存中分配。
- 废弃当前的 TLAB,重新申请 TLAB 空间再次进行内存分配。有可能会有频繁的申请 TLAB 的情况。TLAB 内存自己从堆中进行分配时也是需要并发控制的,而频繁的分配 TLAB 就失去了 TLAB 的意义了。
- 若请求分配的内存大于 refill_waste,会选择在Eden区共享的区域中分配。
- 若请求分配的内存小于 refill_waste,会选择废弃当前的 TLAB,重新创建 TLAB 进行对象内存分配。
引入 TLAB 之后,也有很多值得考虑的问题
-
引入 TLAB 后,会有内存孔隙问题,还可能影响 GC 扫描性能
- 某个线程在一轮 GC 内分配的内存并不稳定
堆空间的参数设置
官方文档:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html#BGBCIEFC
堆空间常用的JVM参数
-XX:+PrintFlagsInitial :查看所有的参数的默认初始值
-XX:+PrintFlagsFinal :查看所有的参数的最终值(可能会存在修改,不再是初始值)
-Xms:初始化堆空间内存(默认物理内存的1/64)
-Xmx:最大堆空间内存(默认物理内存的1/4)
-Xmn:设置年轻代的大小。(初始值及最大值)
-XX:NewRatio:配置年轻代与老年代在堆结构的占比
-XX:InitialSurvivorRatio:设置年轻代中Eden和S0/S1空间的比例
-XX:MaxTenuringThreshold:设置年轻代垃圾的最大年龄
-XX:+PrintGCDetails:输出详细的GC处理日志
-XX:+PrintGC:输出简易的GC处理日志
-verbose:gc:输出简易的GC处理日志
-XX:HandlePromotionFailure:是否设置空间分配担保
具体查看某个参数的指令:
jps:查看当前运行中的进程
jinfo -flag SurvivorRatio 进程id
方法区
方法区(Method Area)与Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。虽然《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但它却有个别名叫做“非堆”(Non-Heap),目的是与Java堆分开。
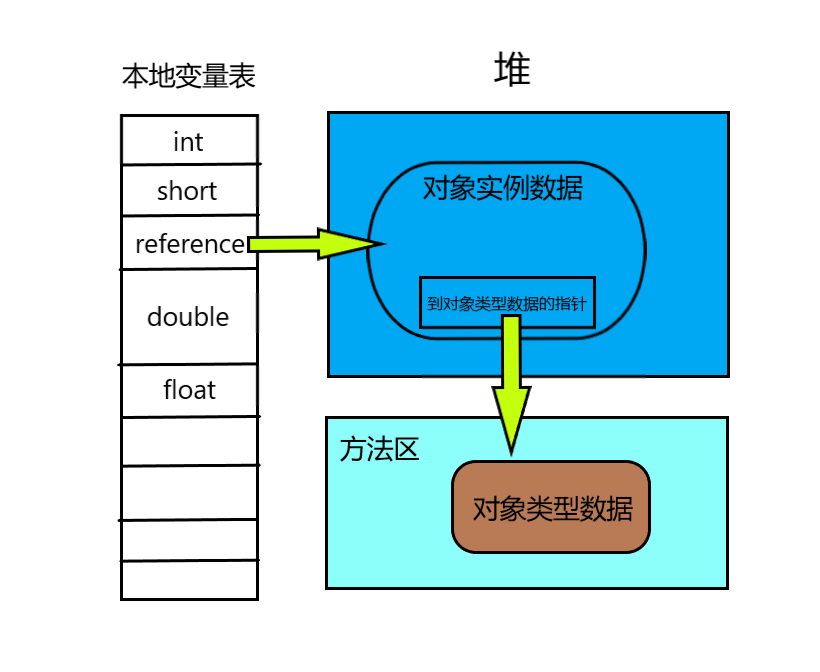
JDK 8 以前,很多人习惯将方法区称为“永久代”,但其实两者并不是等价的,只是因为当时的HotSpot VM 设计团队选择把收集器的分代设计扩展到方法区,或者说使用永久代来实现方法区而已,这样使得HotSpot的垃圾收集器能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的工作。对于其他虚拟机实现,是不存在永久代这一概念的。实现方法区属于虚拟机实现细节,不受《Java虚拟机规范》管束,并不要求统一。目前看来,使用永久代来实现方法区并不是一个好主意,这种设计导致Java应用更容易遇到内存溢出的问题,永久代有-XX:MaxPermSize 的上限,即使不设置也有默认值,而J9和JRockit只要没有触碰到进程可用内存的上限就不会有问题,而且有极少数方法(例如String::intern)会因永久代的原因而导致不同虚拟机有不同的表现。。考虑到HotSpot未来的发展,在JDK6 的时候HotSpot打算放弃永久代,逐步改为采用本地内存来实现方法区,到了JDK 7 ,吧原本放在永久代的字符串常量池、静态变量等移出,到了 JDK 8 ,完全废弃永久代,改用与J9、JRockit一样在本地内存中实现的元空间(Meta Space)来代替,把JDK 7中永久代剩余的内容(主要是类型信息)全部移到元空间中。元空间的本质和永久代类型,都是对《Java虚拟机规范》的方法区的实现。不过元空间与永久代最大的区别在于:元空间不在虚拟机设置的内存中,而是使用本地内存。
《Java虚拟机规范》对方法区的约束非常宽松,除了和堆一样不需要连续的内存和可以选择固定大小或者可扩展外,甚至可以选择不实现垃圾收集。
这区域的内存回收目标主要是针对常量池中废弃常量的回收和对不再使用的类型的卸载。判定一个常量是否“废弃”还是比较简单的,而判定一个类型是否属于“不再使用”的条件就比较苛刻,需要满足一下三个条件:
- 该类所有的实例都已经被回收,也就是Java堆中不存在该类及其任何派生子类的实例。
- 加载该类的类加载器已经被回收,这个条件除非是经过精心设计的可替换类加载器的场景,如OSGI、JSP的重加载等,否则通常是很难达成的。
- 该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
JVM被允许对满足上述三个条件的无用类进行回收,这里说的仅仅是“被允许”,而不是和对象一样,没有引用就必然会回收。是否要对类型进行回收,HotSpot VM提供了 -Xnoclassgc参数进行控制,还可以使用 -verbose:class 以及 -XX:TraceClass-Loading、-XX:TraceClassUnLoading 查看类加载和卸载信息。在大量使用反射、动态代理、CGLIB等字节码框架,动态生成JSP以及OSGI这类频繁自定义类加载器的场景中,通常都需要Java虚拟机具备类型卸载能力,以保证不会对方法区造成过大的内存压力。
根据《Java虚拟机规范》的规定,如果方法区无法满足新的内存分配需求时,会抛出OutOfMemoryError异常。
设置方法区大小
JDK 7 及以前
通过 -XX:PermSize=size 来设置永久代初始分配空间。默认值是20.75M
通过 -XX:MaxPermSize=size 来设置永久代最大分配空间。32位机器默认是64M,64位默认是82M。
JDK 8 及以后
通过 -XX:MetaspaceSize=size 来设置元空间初始分配空间。
通过 -XX:MaxMetaspaceSize=size 来设置元空间最大分配空间。
默认值依赖于平台。windows 平台下,-XX:MetaspaceSize = 21M, -XX:MaxMetaspaceSize = 4G。如果元空间发生溢出,虚拟机一样会抛出OutOfMemoryError:Metaspace异常。
对于一个64位的服务器端JVM来说,其默认的 -XX:MetaspaceSize = 21M。这是初始的高水位线,一旦触及这个水位线,Full GC将会被触发并卸载没用的类(即这些类对应的类加载器不在存活),然后这个高水位线将会重置。新的高水位线的值取决于GC后释放了多少元空间。如果释放的空间不足,那么在不超过MaxMetaspaceSize时,适当提高该值。如果释放空间过多,则会适当降低该值。如果初始化的高水位线设置过低,上述调整情况会发生很多次。通过垃圾回收的日志可以观察到Full GC多次调用。为了避免频繁地GC,建议将 -XX:MetaspaceSize设置为一个相对较高的值。
运行时常量池
常量池类型:字符串常量池、静态常量池、运行时常量池。
静态常量池
Java程序要运行时,需要编译器先将源代码文件编译成字节码(.class)文件,然后在由JVM解释执行。
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表,用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放在方法区的运行时常量池中。
字⾯量就是我们所说的常量概念,如⽂本字符串、被声明为final的常量值等。
符号引⽤是⼀组符号来描述所引⽤的⽬标,符号可以是任何形式的字⾯量,只要使⽤时能⽆歧义地定位到⽬标即可(它与直接 引⽤区分⼀下,直接引⽤⼀般是指向⽅法区的本地指针,相对偏移量或是⼀个能间接定位到⽬标的句柄)。⼀般包括以下常量:
- 类和接⼝的全限定名:例如对于String这个类,它的全限定名就是java/lang/String。
- 字段的名称和描述符:所谓字段就是类或者接口中声明的变量,包括类级别变量(static)和实例级的变量。
- ⽅法的名称和描述符:相当于方法的参数类型+返回值类型。
描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示,详见下表:(数据类型:基本数据类型、引用数据类型)
| 标志符 | 含义 |
| B | 基本数据类型byte |
| C | 基本数据类型char |
| D | 基本数据类型double |
| F | 基本数据类型float |
| I | 基本数据类型int |
| J | 基本数据类型long |
| S | 基本数据类型short |
| Z | 基本数据类型boolean |
| V |
void类型 |
| L | 对象类型,比如:Ljava/lang/Object |
| [ | 数组类型,代表一维数组。比如:double[][][] is [[[D |
用描述符描述方法时,按照先参数列表,后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“()”之内。如方法java.lang.String toString()的描述符为() Ljava/lang/String;,方法int abc(int[] x,int y)的描述符为([II) I。
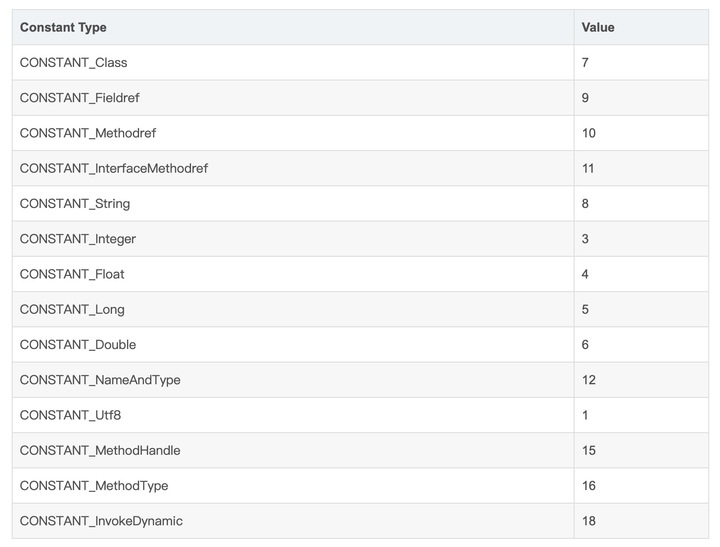
Class文件中的常量池就是静态常量池。Class常量池是在编译时每个class文件中都存在。常量池的每⼀项常量都是⼀个表,⼀共有如下表所示的11种各不相同的表结构数据,这每个表开始的第⼀位都是⼀个字节的标 志位(取值1-12),代表当前这个常量属于哪种常量类型。不同的符号信息放置在不同标志的常量表中。
demo:
public class HelloByteCode {
public static void main(String[] args) {
HelloByteCode obj = new HelloByteCode();
}
}复制
字节码:
Classfile /D:/study/jvm/target/classes/com/fhj/jvm/HelloByteCode.class
Last modified 2021-11-20; size 439 bytes
MD5 checksum fda1980c3ed6b553c05d1a8c700bdff7
Compiled from "HelloByteCode.java"
public class com.fhj.jvm.HelloByteCode
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #4.#19 // java/lang/Object."<init>":()V
#2 = Class #20 // com/fhj/jvm/HelloByteCode
#3 = Methodref #2.#19 // com/fhj/jvm/HelloByteCode."<init>":()V
#4 = Class #21 // java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Utf8 LineNumberTable
#9 = Utf8 LocalVariableTable
#10 = Utf8 this
#11 = Utf8 Lcom/fhj/jvm/HelloByteCode;
#12 = Utf8 main
#13 = Utf8 ([Ljava/lang/String;)V
#14 = Utf8 args
#15 = Utf8 [Ljava/lang/String;
#16 = Utf8 obj
#17 = Utf8 SourceFile
#18 = Utf8 HelloByteCode.java
#19 = NameAndType #5:#6 // "<init>":()V
#20 = Utf8 com/fhj/jvm/HelloByteCode
#21 = Utf8 java/lang/Object
{
public com.fhj.jvm.HelloByteCode();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/fhj/jvm/HelloByteCode;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=1
0: new #2 // class com/fhj/jvm/HelloByteCode
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: return
LineNumberTable:
line 5: 0
line 6: 8
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 args [Ljava/lang/String;
8 1 1 obj Lcom/fhj/jvm/HelloByteCode;
}
SourceFile: "HelloByteCode.java"复制
静态常量池: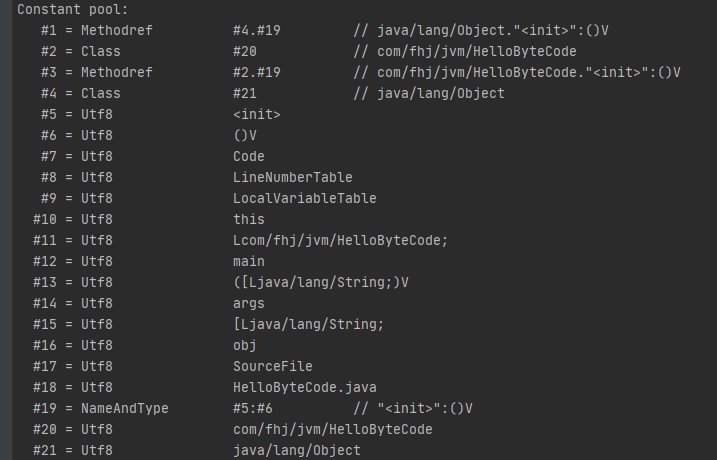
静态常量池存在于编译器,运行时中的常量是JVM加载class文件之后进行分配的。
运行时常量池
运行时常量池就是程序运行时将编译后的类信息解析放入方法区中,也就是说它是方法区的一部分。
运行时常量池用来动态获取类信息,包括:class文件元信息描述、编译后的代码数据、引用类型数据、类文件常量池等。
JVM在执⾏某个类的时候,必须经过加载、连接、初始化,⽽连接⼜包括验证、准备、解析三个阶段。而在类加载完成之后,JVM会将每个class常量池中的内容转存到运行时常量池中。每个class都有一个运行时常量池。class常量池中存的是字⾯量和符号引⽤,也就是说他们存的并不是对象的实例,⽽是对象的符号引⽤值。类在解析之后将符号引用替换成直接引用,解析的过程会去查询全局字符串池,也就是我们上⾯所的StringTable,以保证运⾏时常量池所引⽤的字符串与全局字符串池中所引⽤的是⼀致的。
运行时常量池相对于class文件常量池的另外一个特性是具备动态性,java语言并不要求常量一定只有编译器才产生,也就是并非预置入class文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中。
字符串常量池
String在JDK8及以前内部定义了final char [] value用于存储字符串数据。JDK9 时改为byte[],而且新增了一个coder的成员变量。在程序中,绝大多数字符串只包含英文字母数字等字符,使用Latin-1编码,一个字符占用一个byte。如果使用char,一个char要占用两个byte,会占用双倍的内存空间。但是,如果字符串中使用了中文等超出Latin-1表示范围的字符,使用Latin-1就没办法表示了。这时JDK会使用UTF-16编码,那么占用的空间和旧版(使用char[])是一样的。coder变量代表编码的格式,目前String支持两种编码格式Latin-1和UTF-16。Latin-1需要用一个字节来存储,而UTF-16需要使用2个字节或者4个字节来存储。COMPACT_STRINGS属性则是用来控制是否开启String的compact功能。默认情况下是开启的。可以使用-XX:-CompactStrings参数来对此功能进行关闭。
字符串池里的内容是在类加载完成,经过验证、准备阶段之后在堆中⽣成字符串对象实例,然后将该字符串对象实例的引⽤值存到字符串常量池中(记住:字符串常量池中存的是引⽤值⽽不是具体的实例对象,具体的实例对象是在堆中开辟的⼀块空间存放的)。
在HotSpot VM⾥实现字符串常量池功能的是⼀个StringTable类,它是⼀个哈希表。⾥⾯存的是驻留字符串(也就是我们常说的 ⽤双引号括起来的)的引⽤(⽽不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引⽤之后就 等同被赋予了”驻留字符串”的身份。
字符串常量池只会存储一份,也就是说这个StringTable在每个HotSpot VM的实例只有⼀份,被所有的类共享,存放的是字符串常量的引⽤值。Java语言规范里要求完全相同的字符串字面量,应该包含同样的Unicode字符序列(包含同一份码点序列的常量),并且必须是指向同一个String类实例。创建字符串的基本流程是:创建字符串之前检查常量池中是否存在,如果存在则获取其引用,如果不存在则创建并存入,返回新对象引用。
如果放进 String Pool的String 非常多,就会造成Hash冲突严重,从而导致链表很长,而链表长了会直接造成的影响就是当调用String.intern时性能会大幅下降。使用-XX:StringTableSize可设置StringTable长度。
在JDK6中StringTable是固定的,长度默认1009,如果常量池中的字符串过多就会导致效率下降很快。StringTableSize设置没有要求。可以使用命令 jinfo -flag StringTableSize 进程id 查看。
在JDK7中StringTable的长度默认是60013。StringTableSize设置没有要求。
JDK8开始,设置StringTable的长度的话,1009是可设置的最小值。
常量池内存位置演化
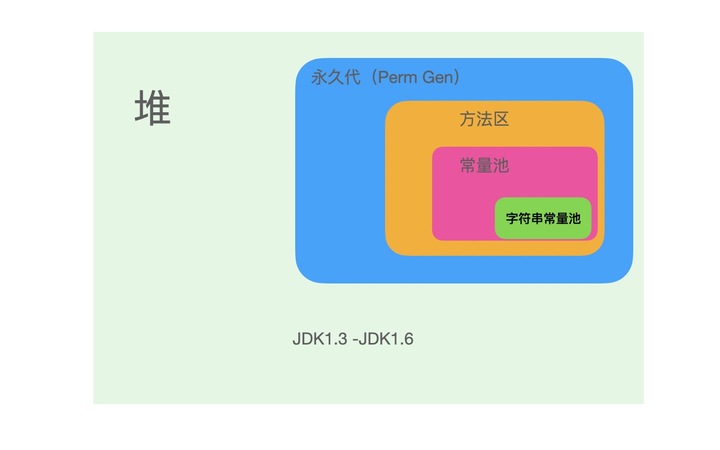
在JDK1.6及之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时hotspot虚拟机对方法区的实现为永久代。
在JDK1.7字符串常量池和静态变量被从方法区拿到了堆中,运行时常量池剩下的还在方法区, 也就是hotspot中的永久代。注意:此处的静态变量只是静态变量的引用,对象实体始终都在堆空间。
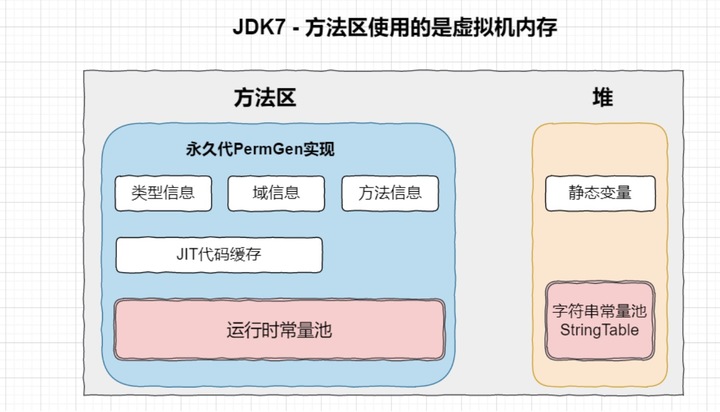
在JDK8 hotspot移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆,运行时常量池还在方法区,只不过方法区的实现从永久代变成了元空间(Metaspace)。

- 为永久代设置空间大小是很难确定的。在某些场景下,如果动态加载类很多,容易产生永久代的OOM。比如某个实际Web工程中,因为功能点比较多,在运行过程中,会不断的动态加载很多类。而换成元空间以后,因为元空间并不在虚拟机中,而是使用本地内存,默认情况下,元空间的大小仅受本地内存限制,不易产生OOM。
- 对永久代进行调优是很困难的。
注意:以上的静态变量都是静态变量引用,对象实体始终都存在堆空间。
举个例子
public class StaticObjTest {
static class Test{
static ObjectHolder staticObj = new StaticObjTest.ObjectHolder();
ObjectHolder instanceObj = new ObjectHolder();
void foo(){
ObjectHolder localObj = new ObjectHolder();
System.out.println("done");
}
}
private static class ObjectHolder{
}
public static void main(String[] args) {
Test test = new StaticObjTest.Test();
test.foo();
}
}复制
staticObj 随着Test的类型信息存放在方法区,instanceObj随着Test的对象实例存放在堆,localObj则是存放在foo()方法栈帧的局部变量表中。三个对象的数据在内存中的地址都落在Eden区范围内。
直接内存
直接内存不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但这部分内存也被频繁使用,而且也可能导致OOM异常出现。
在JDK 1.4 中新加入了NIO,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,他可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。读写频繁的场合可以考虑使用直接内存。
本机直接内存的分配不受Java堆大小的限制,但是,受到本机总内存(包括物理内存、SWAP分区或者分页文件)大小以及处理器寻址空间的限制,一般服务器管理员配置虚拟机参数时,会根据实际内存区设置-Xmx等参数信息,但经常忽略直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现OOM异常。直接内存大小可以通过MaxDirectMemorySize设置
直接内存的缺点是分配回收成本较高,不收JVM内存回收管理。
在 Linux 机器上,使用 top 或者 ps 命令,在大多数情况下,能够看到 RSS 段(实际的内存占用),是大于给 JVM 分配的堆内存的。 如果你申请了一台系统内存为 2GB 的主机,可能 JVM 能用的就只有 1GB,这便是一个限制。
总结

Java内存模型
先看一个例子:
int a=0, b=0;
public void method1() {
int r2 = a;
b = 1;
}
public void method2() {
int r1 = b;
a = 2;
}复制
定义了两个共享变量 a 和 b,以及两个方法。第一个方法将局部变量 r2 赋值为 a,然后将共享变量 b 赋值为 1。第二个方法将局部变量 r1 赋值为 b,然后将共享变量 a 赋值为 2。请问(r1,r2)的可能值都有哪些?
在单线程环境下,我们可以先调用第一个方法,最终(r1,r2)为(1,0);也可以先调用第二个方法,最终为(0,2)。
在多线程环境下,假设这两个方法分别跑在两个不同的线程之上,如果 Java 虚拟机在执行了任一方法的第一条赋值语句之后便切换线程,那么最终结果将可能出现(0,0)的情况。
除上述三种情况之外,还有一种看似不可能的情况(1,2)。
造成这一情况的原因有三个,分别为即时编译器的重排序,处理器的乱序执行(也叫指令级并行的重排序),以及内存系统的重排序。下面讲一下编译器优化的重排序是怎么一回事。
编译器重排序
首先需要说明一点,即时编译器(和处理器)需要保证程序能够遵守 as-if-serial 属性。通俗地说,就是在单线程情况下,要给程序一个顺序执行的假象。即经过重排序的执行结果要与顺序执行的结果保持一致。
另外,如果两个操作之间存在数据依赖,那么即时编译器(和处理器)不能调整它们的顺序,否则将会造成程序语义的改变。
int a=0, b=0;
public void method1() {
int r2 = a;
b = 1;
.. // Code uses b
if (r2 == 2) {
..
}
}复制
在上面这段代码中,扩展了先前例子中的第一个方法。新增的代码会先使用共享变量 b 的值,然后再使用局部变量 r2 的值。
此时,即时编译器有两种选择。
第一,在一开始便将 a 加载至某一寄存器中,并且在接下来 b 的赋值操作以及使用 b 的代码中避免使用该寄存器。第二,在真正使用 r2 时才将 a 加载至寄存器中。这么一来,在执行使用 b 的代码时,不再霸占一个通用寄存器,从而减少需要借助栈空间的情况。
int a=0, b=0;
public void method1() {
for (..) {
int r2 = a;
b = 1;
.. // Code uses r2 and rewrites a
}
}复制
另一个例子则是将第一个方法的代码放入一个循环中。除了原本的两条赋值语句之外,我只在循环中添加了使用 r2,并且更新 a 的代码。由于对 b 的赋值是循环无关的,即时编译器很有可能将其移出循环之前,而对 r2 的赋值语句还停留在循环之中。
可以看到,即时编译器的优化可能将原本字段访问的执行顺序打乱。在单线程环境下,由于 as-if-serial 的保证,我们无须担心顺序执行不可能发生的情况,如(r1,r2)=(1,2)。
然而,在多线程情况下,这种数据竞争(data race)的情况是有可能发生的。而且,Java 语言规范将其归咎于应用程序没有作出恰当的同步操作。
指令重排序
计算机按支持的指令大致可以分为两类:
- 精简指令集计算机(RISC), 代表是如今大家熟知的 ARM 芯片,功耗低,运算能力相对较弱。
- 复杂指令集计算机(CISC), 代表作是 Intel 的 X86 芯片系列,比如奔腾,酷睿,至强,以及 AMD 的 CPU。特点是性能强劲,功耗高。(实际上从奔腾 4 架构开始,对外是复杂指令集,内部实现则是精简指令集,所以主频才能大幅度提高)
不管哪一种指令集,CPU 的实现都是采用流水线的方式。如果 CPU 一条指令一条指令地执行,那么很多流水线实际上是闲置的。于是硬件设计人员就想出了一个好办法: “指令乱序”。 CPU 完全可以根据需要,通过内部调度把这些指令打乱了执行,充分利用流水线资源,只要最终结果是等价的,那么程序的正确性就没有问题。但这在如今多 CPU 内核的时代,随着复杂度的提升,并发执行的程序面临了很多问题。
JMM 是一个抽象的概念,它描述了一系列的规则或者规范,用来解决多线程的共享变量问题,比如 volatile、synchronized 等关键字就是围绕 JMM 的语法。这里所说的变量,包括实例字段、静态字段,但不包括局部变量和方法参数,因为后者是线程私有的,不存在竞争问题。JVM 试图定义一种统一的内存模型,能将各种底层硬件,以及操作系统的内存访问差异进行封装,使 Java 程序在不同硬件及操作系统上都能达到相同的并发效果。
JMM 的结构
JMM 分为主存储器(Main Memory)和工作存储器(Working Memory)两种。
- 主存储器是实例位置所在的区域,所有的实例都存在于主存储器内。比如,实例所拥有的字段即位于主存储器内,主存储器是所有的线程所共享的。
- 工作存储器是线程所拥有的作业区,每个线程都有其专用的工作存储器。工作存储器存有主存储器中必要部分的拷贝,称之为工作拷贝(Working Copy)。
在这个模型中,线程无法对主存储器直接进行操作。如下图,线程 A 想要和线程 B 通信,只能通过主存进行交换。
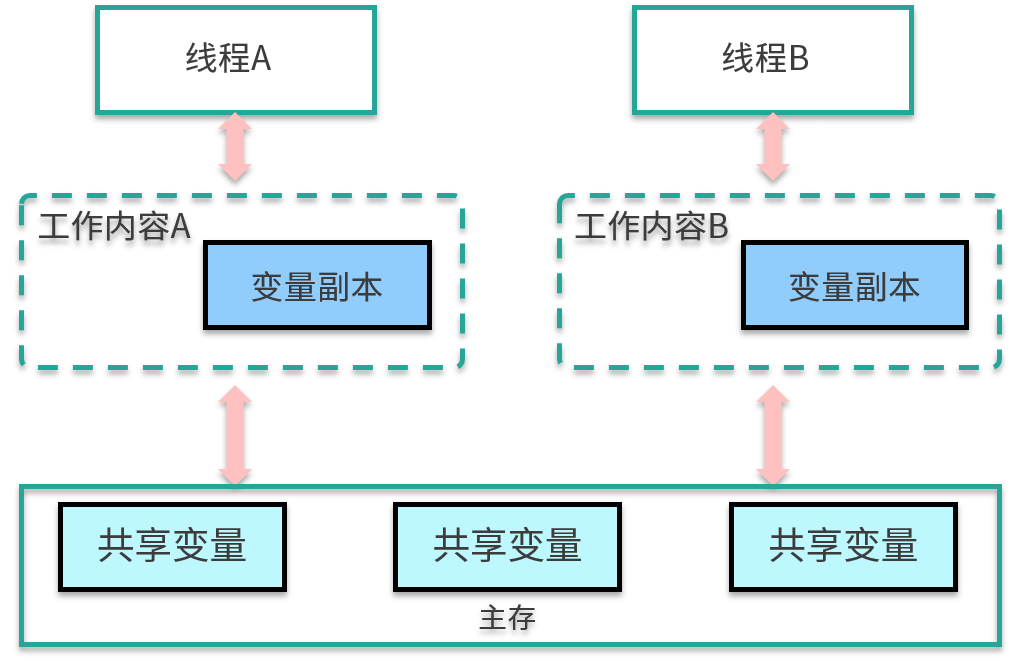
那这些内存区域都是在哪存储的呢?如果非要有个对应的话,你可以认为主存中的内容是 Java 堆中的对象,而工作内存对应的是虚拟机栈中的内容。但实际上,主内存也可能存在于高速缓存,或者 CPU 的寄存器上;工作内存也可能存在于硬件内存中,我们不用太纠结具体的存储位置。
8 个 Action
操作类型
为了支持 JMM,Java 定义了 8 种原子操作(Action),用来控制主存与工作内存之间的交互。
(1)read(读取)作用于主内存,它把变量从主内存传动到线程的工作内存中,供后面的 load 动作使用。
(2)load(载入)作用于工作内存,它把 read 操作的值放入到工作内存中的变量副本中。
(3)store(存储)作用于工作内存,它把工作内存中的一个变量传送给主内存中,以备随后的 write 操作使用。
(4)write (写入)作用于主内存,它把 store 传送值放到主内存中的变量中。
(5)use(使用)作用于工作内存,它把工作内存中的值传递给执行引擎,每当虚拟机遇到一个需要使用这个变量的指令时,将会执行这个动作。
(6)assign(赋值)作用于工作内存,它把从执行引擎获取的值赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时,执行该操作。
(7)lock(锁定)作用于主内存,把变量标记为线程独占状态。
(8)unlock(解锁)作用于主内存,它将释放独占状态。
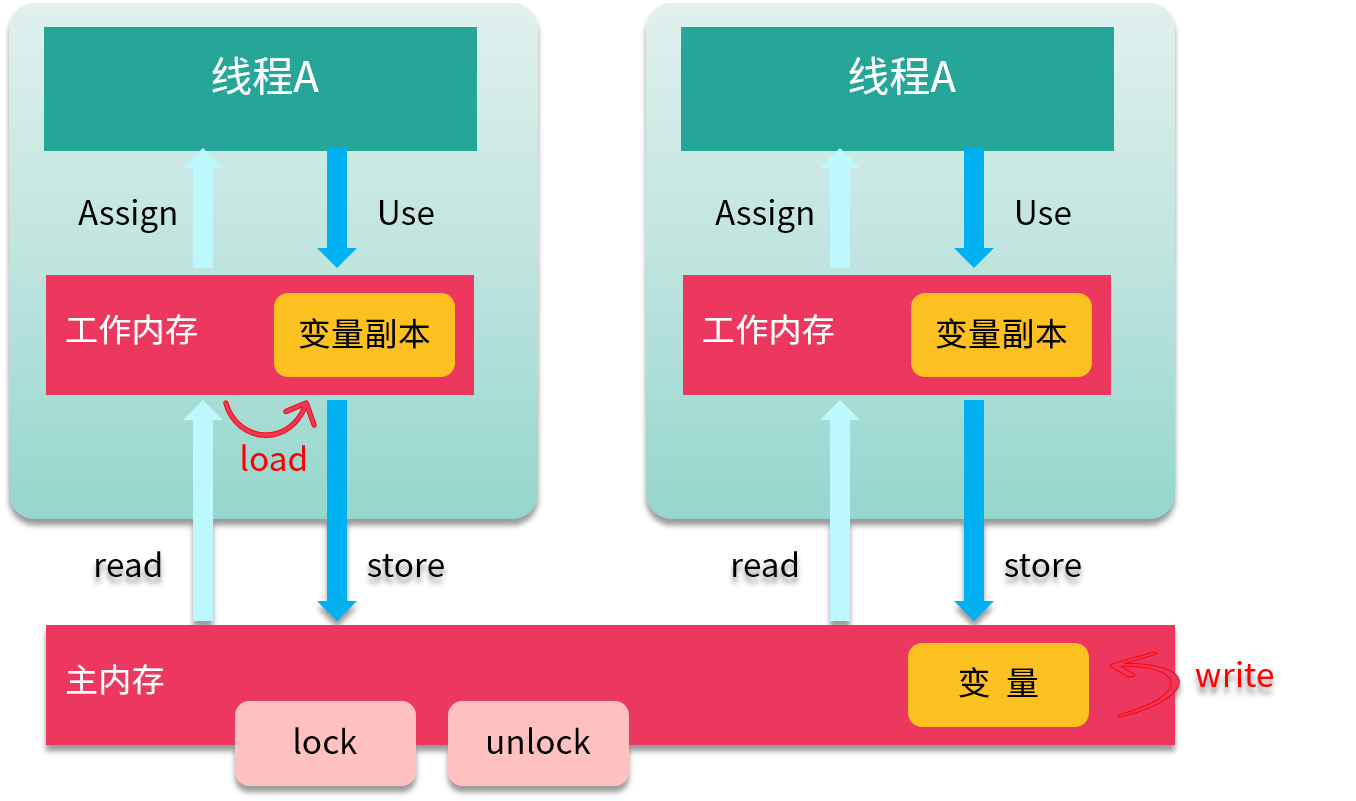
如上图所示,把一个变量从主内存复制到工作内存,就要顺序执行 read 和 load;而把变量从工作内存同步回主内存,就要顺序执行 store 和 write 操作。
三大特征
(1)原子性
JMM 保证了 read、load、assign、use、store 和 write 六个操作具有原子性,可以认为除了 long 和 double 类型以外,对其他基本数据类型所对应的内存单元的访问读写都是原子的。
如果想要一个颗粒度更大的原子性保证,就可以使用 lock 和 unlock 这两个操作。
(2)可见性
可见性是指当一个线程修改了共享变量的值,其他线程也能立即感知到这种变化。
我们从前面的图中可以看到,要保证这种效果,需要经历多次操作。一个线程对变量的修改,需要先同步给主内存,赶在另外一个线程的读取之前刷新变量值。
volatile、synchronized、final 和锁,都是保证可见性的方式。
这里要着重提一下 volatile,因为它的特点最显著。使用了 volatile 关键字的变量,每当变量的值有变动时,都会把更改立即同步到主内存中;而如果某个线程想要使用这个变量,则先要从主存中刷新到工作内存上,这样就确保了变量的可见性。
而锁和同步关键字就比较好理解一些,它是把更多个操作强制转化为原子化的过程。由于只有一把锁,变量的可见性就更容易保证。
(3)有序性
Java 程序很有意思,从上面的 add 操作可以看出,如果在线程中观察,则所有的操作都是有序的;而如果在另一个线程中观察,则所有的操作都是无序的。
除了多线程这种无序性的观测,无序的产生还来源于指令重排。
指令重排序是 JVM 为了优化指令,来提高程序运行效率的,在不影响单线程程序执行结果的前提下,按照一定的规则进行指令优化。在某些情况下,这种优化会带来一些执行的逻辑问题,在并发执行的情况下,按照不同的逻辑会得到不同的结果。
我们可以看一下 Java 语言中默认的一些“有序”行为,也就是先行发生(**happens-before)**原则,这些可能在写代码的时候没有感知,因为它是一种默认行为。
Java 内存模型与 happens-before 关系
为了让应用程序能够免于数据竞争的干扰,Java 5 引入了明确定义的 Java 内存模型。其中最为重要的一个概念便是 happens-before 关系。happens-before 关系是用来描述两个操作的内存可见性的。如果操作 X happens-before 操作 Y,那么 X 的结果对于 Y 可见。
在同一个线程中,字节码的先后顺序(program order)也暗含了 happens-before 关系:在程序控制流路径中靠前的字节码 happens-before 靠后的字节码。然而,这并不意味着前者一定在后者之前执行。实际上,如果后者没有观测前者的运行结果,即后者没有数据依赖于前者,那么它们可能会被重排序。
除了线程内的 happens-before 关系之外,Java 内存模型还定义了下述线程间的 happens-before 关系。
- 解锁操作 happens-before 之后(这里指时钟顺序先后)对同一把锁的加锁操作。
- volatile 字段的写操作 happens-before 之后(这里指时钟顺序先后)对同一字段的读操作。
- 线程的启动操作(即 Thread.starts()) happens-before 该线程的第一个操作。
- 线程的最后一个操作 happens-before 它的终止事件(即其他线程通过 Thread.isAlive() 或 Thread.join() 判断该线程是否中止)。
- 线程对其他线程的中断操作 happens-before 被中断线程所收到的中断事件(即被中断线程的 InterruptedException 异常,或者第三个线程针对被中断线程的 Thread.interrupted 或者 Thread.isInterrupted 调用)。
- 构造器中的最后一个操作 happens-before 构造器的第一个操作。即一个对象的初始化完成 happens-before 它的 finalize() 方法的开始。
happens-before 关系还具备传递性。如果操作 X happens-before 操作 Y,而操作 Y happens-before 操作 Z,那么操作 X happens-before 操作 Z。
在前面的例子中,程序没有定义任何 happens-before 关系,仅拥有默认的线程内 happens-before 关系。也就是 r2 的赋值操作 happens-before b 的赋值操作,r1 的赋值操作 happens-before a 的赋值操作。
Thread1 Thread2 | | b=1 | | r1=b | a=2 r2=a |复制
拥有 happens-before 关系的两对赋值操作之间没有数据依赖,因此即时编译器、处理器都可能对其进行重排序。举例来说,只要将 b 的赋值操作排在 r2 的赋值操作之前,那么便可以按照赋值 b,赋值 r1,赋值 a,赋值 r2 的顺序得到(1,2)的结果。
那么如何解决这个问题呢?答案是,将 a 或者 b 设置为 volatile 字段。
比如说将 b 设置为 volatile 字段。假设 r1 能够观测到 b 的赋值结果 1。显然,这需要 b 的赋值操作在时钟顺序上先于 r1 的赋值操作。根据 volatile 字段的 happens-before 关系,我们知道 b 的赋值操作 happens-before r1 的赋值操作。
int a=0;
volatile int b=0;
public void method1() {
int r2 = a;
b = 1;
}
public void method2() {
int r1 = b;
a = 2;
}复制
根据同一个线程中,字节码顺序所暗含的 happens-before 关系,以及 happens-before 关系的传递性,我们可以轻易得出 r2 的赋值操作 happens-before a 的赋值操作。
这也就意味着,当对 a 进行赋值时,对 r2 的赋值操作已经完成了。因此,在 b 为 volatile 字段的情况下,程序不可能出现(r1,r2)为(1,2)的情况。
由此可以看出,解决这种数据竞争问题的关键在于构造一个跨线程的 happens-before 关系 :操作 X happens-before 操作 Y,使得操作 X 之前的字节码的结果对操作 Y 之后的字节码可见。
锁操作同样具备 happens-before 关系。具体来说,解锁操作 happens-before 之后对同一把锁的加锁操作。实际上,在解锁时,Java 虚拟机同样需要强制刷新缓存,使得当前线程所修改的内存对其他线程可见。需要注意的是,锁操作的 happens-before 规则的关键字是同一把锁。也就意味着,如果编译器能够(通过逃逸分析)证明某把锁仅被同一线程持有,那么它可以移除相应的加锁解锁操作。因此也就不再强制刷新缓存。举个例子,即时编译后的 synchronized (new Object()) {},可能等同于空操作,而不会强制刷新缓存。
volatile 字段可以看成一种轻量级的、不保证原子性的同步,其性能往往优于(至少不亚于)锁操作。然而,频繁地访问 volatile 字段也会因为不断地强制刷新缓存而严重影响程序的性能。在 X86_64 平台上,只有 volatile 字段的写操作会强制刷新缓存。因此,理想情况下对 volatile 字段的使用应当多读少写,并且应当只有一个线程进行写操作。volatile 字段的另一个特性是即时编译器无法将其分配到寄存器里。换句话说,volatile 字段的每次访问均需要直接从内存中读写。
final 实例字段则涉及新建对象的发布问题。当一个对象包含 final 实例字段时,我们希望其他线程只能看到已初始化的 final 实例字段。因此,即时编译器会在 final 字段的写操作后插入一个写写屏障,以防某些优化将新建对象的发布(即将实例对象写入一个共享引用中)重排序至 final 字段的写操作之前。在 X86_64 平台上,写写屏障是空操作。
Java 内存模型的底层实现
在理解了 Java 内存模型的概念之后,我们现在来看看它的底层实现。Java 内存模型是通过内存屏障(memory barrier)来禁止重排序的。Java 编译器在生成字节码时,会在执行指令序列的适当位置插入内存屏障来限制处理器的重排序。
内存屏障简介
内存屏障(Memory Barrier)与内存栅栏(Memory Fence)是同一个概念,不同的叫法。
通过volatile标记,可以解决编译器层面的可见性与重排序问题。而内存屏障则解决了硬件层面的可见性与重排序问题。
先简单了解两个指令:
- Store:将处理器缓存的数据刷新到内存中。
- Load:将内存存储的数据拷贝到处理器的缓存中。
内存屏障可分为读屏障和写屏障,用于控制可见性。 常见的 内存屏障 包括:
LoadLoad StoreStore LoadStore StoreLoad
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 该屏障确保Load1数据的装载先于Load2及其后所有装载指令的的操作 |
| StoreStore Barriers | Store1;StoreStore;Store2 | 该屏障确保Store1立刻刷新数据到内存(使其对其他处理器可见)的操作先于Store2及其后所有存储指令的操作 |
| LoadStore Barriers | Load1;LoadStore;Store2 | 确保Load1的数据装载先于Store2及其后所有的存储指令刷新数据到内存的操作 |
| StoreLoad Barriers | Store1;StoreLoad;Load2 | 该屏障确保Store1立刻刷新数据到内存的操作先于Load2及其后所有装载装载指令的操作。它会使该屏障之前的所有内存访问指令(存储指令和访问指令)完成之后,才执行该屏障之后的内存访问指令 |
这些屏障的主要目的,是用来短暂屏蔽 CPU 的指令重排序功能。 和 CPU 约定好,看见这些指令时,就要保证这个指令前后的相应操作不会被打乱。
- 比如看见 LoadLoad, 那么屏障前面的 Load 指令就一定要先执行完,才能执行屏障后面的 Load 指令。
- 比如我要先把 a 值写到 A 字段中,然后再将 b 值写到 B 字段对应的内存地址。如果要严格保障这个顺序,那么就可以在这两个 Store 指令之间加入一个 StoreStore 屏障。
- 遇到LoadStore屏障时, CPU 自废武功,短暂屏蔽掉指令重排序功能。
- StoreLoad屏障, 能确保屏障之前执行的所有 store 操作,都对其他处理器可见; 在屏障后面执行的 load 指令, 都能取得到最新的值。换句话说, 有效阻止屏障之前的 store 指令,与屏障之后的 load 指令乱序 、即使是多核心处理器,在执行这些操作时的顺序也是一致的。
代价最高的是 StoreLoad 屏障, 它同时具有其他几类屏障的效果,可以用来代替另外三种内存屏障。
如何理解呢?
就是只要有一个 CPU 内核收到这类指令,就会做一些操作,同时发出一条广播, 给某个内存地址打个标记,其他 CPU 内核与自己的缓存交互时,就知道这个缓存不是最新的,需要从主内存重新进行加载处理。
对于即时编译器来说,它会针对前面提到的每一个 happens-before 关系,向正在编译的目标方法中插入相应的读读、读写、写读以及写写内存屏障。
这些内存屏障会限制即时编译器的重排序操作。以 volatile 字段访问为例,所插入的内存屏障将不允许 volatile 字段写操作之前的内存访问被重排序至其之后;也将不允许 volatile 字段读操作之后的内存访问被重排序至其之前。
然后,即时编译器将根据具体的底层体系架构,将这些内存屏障替换成具体的 CPU 指令。以我们日常接触的 X86_64 架构来说,读读、读写以及写写内存屏障是空操作(no-op),只有写读内存屏障会被替换成具体指令 。
在前面的例子中,method1 和 method2 之中的代码均属于先读后写(假设 r1 和 r2 被存储在寄存器之中)。X86_64 架构的处理器并不能将读操作重排序至写操作之后。因此,例子中的重排序必然是即时编译器造成的。
举例来说,对于 volatile 字段,即时编译器将在 volatile 字段的读写操作前后各插入一些内存屏障。
然而,在 X86_64 架构上,只有 volatile 字段写操作之后的写读内存屏障需要用具体指令来替代。
该具体指令的效果,可以简单理解为强制刷新处理器的写缓存。写缓存是处理器用来加速内存存储效率的一项技术。
在碰到内存写操作时,处理器并不会等待该指令结束,而是直接开始下一指令,并且依赖于写缓存将更改的数据同步至主内存(main memory)之中。
强制刷新写缓存,将使得当前线程写入 volatile 字段的值(以及写缓存中已有的其他内存修改),同步至主内存之中。
由于内存写操作同时会无效化其他处理器所持有的、指向同一内存地址的缓存行,因此可以认为其他处理器能够立即见到该 volatile 字段的最新值。
总结:Java 内存模型是通过内存屏障来禁止重排序的。对于即时编译器来说,内存屏障将限制它所能做的重排序优化。对于处理器来说,内存屏障会导致缓存的刷新操作。