https://zhuanlan.zhihu.com/p/568752990
在过去一段时间,我面试过一些 DevOps 相关从业者,并且曾经收到过一些知乎小伙伴的提问,针对于 DevOps 以及相关从业者而言,我个人认为这块的要求是比较高的,因为它对 相关技能 以及 工作经验都有一定要求,并且在落地过程中也需要结合不同 公司的文化 去执行。
而针对于 DevOps 相关从业者技能的要求也很高,需要不断学习,以保持自己与市场需求同步,下面是我根据我的经验和理解列出来的一些关于这个行业的技术技能栈。
(备注:随着技术发展的不断更迭,该技术栈也会不断更新,可添加小编获取最新技术栈)
在网络技术方面有比较扎实的基础
了解基础的 TCP/IP 协议簇相关知识,熟悉常用的 7 层协议以及应用层其他协议,比如 HTTP,HTTP/2,QUIC或HTTP3,mTLS,Proxy,DNS,BGP。
熟悉负载均衡的工作原理,Iptables,IP 地址以及网络规划和架构设计相关的知识。
jvns computer-network(https://jvns.ca/#computer-networking )中有一些比较好的计算机网络相关的知识值得我们去深入学习。
在过去的面试中,经常会遇到候选人有过计算机相关的背景或者曾经写过一些 Rest API,但是当提起基础的 TCP/IP 或者 HTTP 协议时,依然有大部分同学无法很顺畅的说出来,我们要知道,在现代技术架构中,任何程序都是需要依附与网络进行的,因此网络相关的基础技术,一定是作为 DevOps 或者 SRE 相关从业者的最基础的必备知识技能。
掌握 Linux 操作系统的基本原理,以及基本命令
在现代技术架构中,大多数操作系统 (虚拟机、容器等) 都运行在 Linux 上,因此从内而外了解 Linux 非常重要。
Linux 系统中,我们至少应该学习调度,systemd 接口,init 系统,cgroups 和 napespaces,性能调优,并掌握命令行实用工具如 awk,dig,sed,tr, jq, yq, curl,ssh,openssl,wc 等等。
在 brendan's blog (https://www.brendangregg.com/linuxperf.html) 中我们可以学到更多关于 troubleshooting 相关的知识。
诸如:
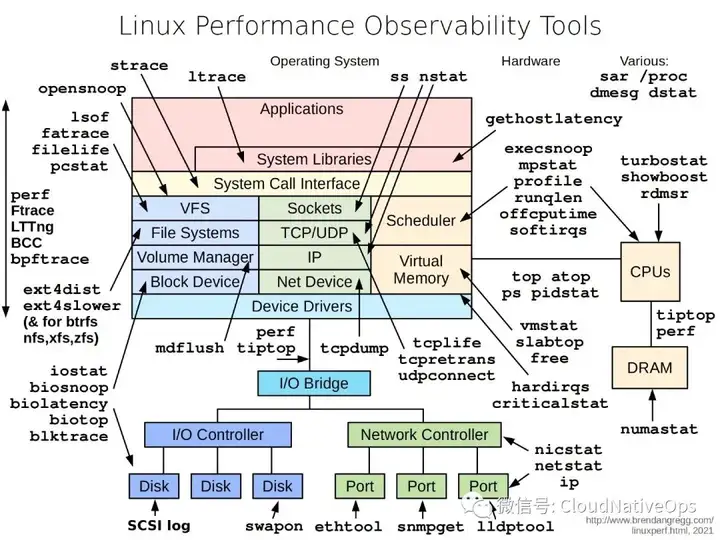
Linux Performance Observability Tools
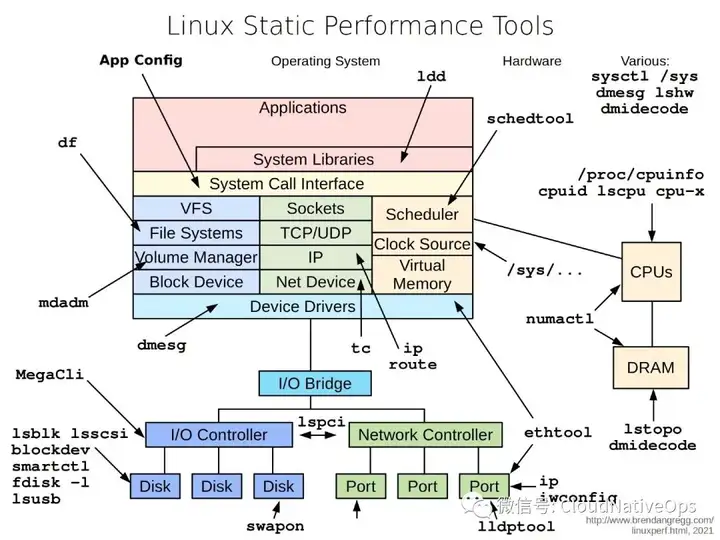
Linux Static Performance Tools
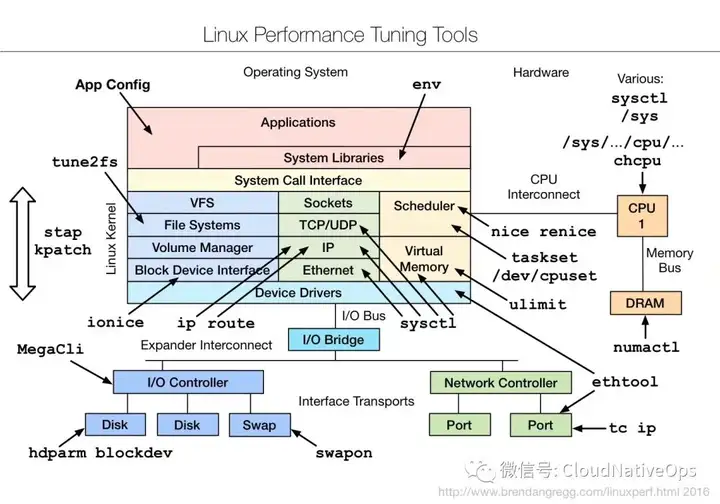
Linux Performance Tuning Tools
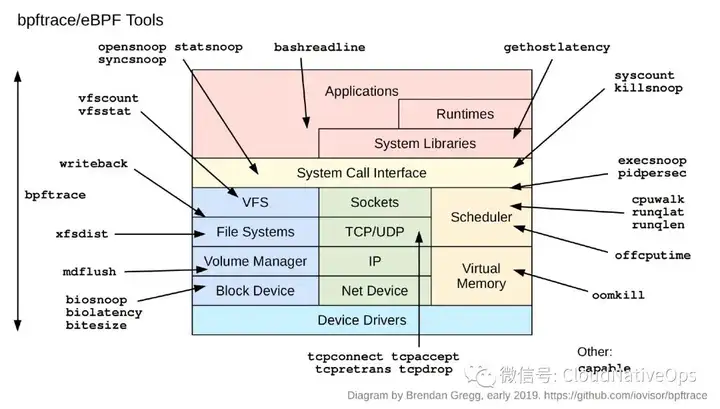
bpftrace/eBPF Tools
等等。
CI/CD
在过去的研发过程管理中,我们通常习惯使用 Jenkins 来做 持续集成、持续交付、持续部署的平台。
但是,当前随着云原生的发展,以及开始转变成为诸如 ArgoCD, ArgoWorkflow 之类的云原生 CI/CD 引擎。
虽然在整体概念和流程上没有什么太大变化,但是作为云原生相关从业者,你应该熟悉 Github Actions,Tekton,Argo 等项目,以便于指导我们如何更好的去做持续交付,理解多种部署策略,比如蓝绿部署或者金丝雀部署 (canary)。
容器化和虚拟化
除了流行的 Docker 运行时,还可以尝试 containerd, podman 等。
了解如何容器化应用程序,如何实现容器安全,以及如何在 Kubernetes 中运行和编排虚拟机。
备注:虽然整个云原生更多在讲容器化和 Kubernetes,但是我们不应该忽视虚拟机的存在以及 Kubernetes 的声明式 API 的优势,因此对于 Kubernetes 和 虚拟机的结合,可以适当了解一下 `KubeVirt`` 项目。
容器编排
Kubernetes 现在是容器编排领域的实际的标准,网上有很多学习 Kubernetes 的内容,并且社区在官方文档中也几乎全版本跟进了中文版本,而我们应该更加关注配置最佳实践、应用程序设计、安全性和调度。
对于早期的 Kubernetes 集群初始化是一件很繁琐且复杂的事情,但随着云服务和社区生态的发展,也出现了各种托管的 k8s 集群服务以及一键部署的工具 (比如 kind,k3d,rancher,kubeadm 等)。
然而在集群上的使用,例如配置服务,监控,日志,CI/CD,如何扩展群集,成本优化和安全性是人们可能在容器化后更加迫切期望解决的一些问题,这也是相关从业者可以着重关注的方向,毕竟最难,最复杂的集群初始化动作,各大云厂商已经提供了高可靠、好可用、高性能的云服务。
备注:国内三大云厂商对应的容器引擎服务。
下面这张图,你可以看到 Kubernetes 这座冰山下的细节。

Source: asankov.dev
大规模可观测性
大多数工程师都知道或熟悉 Zabbix, Prometheus,Grafana,ELK 或者相似的东西。
趋势表明,许多组织正在整合他们的 Kubernetes 集群和可观察性,从性能和成本的角度来看,这是有很大优势的。
因此,了解 Prometheus 的高级配置和体系结构,以及如何扩展它们变得更加重要,你需要了解或者熟悉诸如 Thanos,Cortex,VictoriaMetrics,Datadog 和 Loki 等技术,持续分析工具如 Parca,hypertrace 以及基于 OpenTelemetry 的分布式追踪技术。
像 Istio 这样的服务网格是云原生生态中很受欢迎的成分,但是对于大部分的业务场景而言,过早的引入服务网格也可能会导致架构更加复杂。
平台团队要作为产品团队
平台团队的功能正变得更像一个集中的产品团队,专注于其内部平台客户,如开发人员和测试人员。
我们的目标是优化工作方式,改善整个工作流程,为团队带来一些秩序,因此试着在 开发人员和 QA 团队面临的问题上尽可能多做事情,也就是 职责左移 的问题,不论是作为 DevOps 还是 SRE 从业者,我们都应该往前一步去考虑我们服务对象的需求和痛点。
安全
在许多中小型企业组织中,安全是二等公民,通常在一开始,整个产研团队只会考虑产品特性是否得到满足。
但是,由于越来越复杂的攻击和各种严格的合规要求,公司正在适应左移安全策略,比如端到端加密、RBAC、IAM 策略、治理和审计,以及 NIST、CIS、ISO27001 等基准的实现都很常见。
容器安全、Policy as Code、云治理和供应链安全 都是当前比较热门的话题。
编程
DevOps 或 SRE 角色现在承担了开发人员的辅助运营角色,他们开发工具系统,在执行标准的同时帮助提高开发同学的生产力。
众所周知的是,编写高质量的平台组件需要良好的软件工程实践和技能,对此,我暂时没有办法给出更好的建议,因为,好的组织正在寻找有编程经验的平台工程师,就如同我个人一样,只能在已有的环境尝试使用更多 Coding 的方式去完成工作。
然而编程能力对于 SRE 而言更重要,因为你需要娴熟的编程,能够阅读,理解和调试别人写的代码,如果有必要还需要修复它。
Python 和 Golang 是最受欢迎的,我的建议是 Golang,因为它并发性、严格的类型检查、各类公司的采用、工具链以及许多大型项目都是用 Golang 构建的。
建议开始阶段,可以从如下几个方向着手:
Infrastructure as Code
基础设施即代码是整个云原生过程中,比较普遍的认知。
而 Terraform 目前已经形成 IaC 中的一个标准,一旦理解了这个概念,就很容易适应任何其他工具,因为大多数工具都是基于 DSL 的。
你应当熟悉诸如 Ansible playbooks、Salt State、Terraform 以及 Pulumi 等开源软件。
Cloud
云原生时代,所有的基础设施以及技术都将依赖于云技术。
大多数云都以同样的方式工作,因此,如果你非常了解某个云,就可以轻松地与其他云提供商合作,关注如何以高可用性、高弹性、安全且低成本的方式使用云原生组件设计应用程序。
技术写作
你可能想知道为什么我在讨论 DevOps 时谈论技术写作。
许多人对此没有足够的关注,包括我自己曾经也一样,但实际上技术写作对于自己整体知识体系的回归以及梳理都是非常重要的,并且对于你如何与其他团队进行交流和合作非常重要。
实际上,在工作中我们可能需要大量的依赖技术写作来满足工作需求,比如你可能会创建诸如 快速开始、事后分析、RFCs、架构决策记录和软件设计文档等文档。
一份清晰易懂的技术文章可能创造奇迹,它可以帮助你节省你和读者的时间,提高整体效率。
作为一个普通的技术从业者,如何成为一个好的写手,推荐可以阅读以下该文章:https://blog.pragmaticengineer.com/becoming-a-better-writer-in-tech/
站点可靠性工程
DevOps 和 SRE 之间的界限越来越模糊,在一些组织中,同一个人可能同时扮演两个角色。
理解 SLI、SLO 和 错误预算和 SRE 实践背后的概念。
每个组织的做法都不一样,所以我不建议把别人的文化复制粘贴到你的团队中,这部分参考 谷歌SRE 文化。
Google SRE: https://sre.google/
总结
就我个人而言,我可能对云原生的很多方向会比较感兴趣,并且会持续研究和跟进,以下是一些方向以值得探索的开源工程。