https://zhuanlan.zhihu.com/p/206743670复制
Brendan Gregg在性能分析工业界如雷贯耳, 相信看到这篇文章的人肯定知道他的大名. 我们看一下他自己写的bio, 这里摘取的是short版本:
Brendan Gregg is an industry expert in computing performance and cloud computing. He is a senior performance architect at Netflix, where he does performance design, evaluation, analysis, and tuning. He is the author of Systems Performance and BPF Performance Tools (Addison-Wesley), and received the USENIX LISA Award for Outstanding Achievement in System Administration. Brendan has created numerous performance analysis tools, visualizations, and methodologies for performance analysis, including flame graphs.
Brendan的博客内容非常丰富, 总的来说主要包括3个部分:
本文会大量借鉴和引用上面的内容.
Brendan博客更关注的是怎么去定位性能问题, 性能分析也可以用于容量规划等, 本文也主要关注前者.
每个人在解决问题时都或多或少都有些思路, 当这些思路沉淀下来并能应用到不同的问题上, 便形成了方法论. 作为一个系统工程师, 不管是不是"全栈工程师", 总会碰到不熟悉的系统或者应用, 我们怎么通过对系统的理解, 使用和创造工具, 通过我们的方法论来解决和定位问题.
我们从问题本身出发, QA在报一个bug之前, 首先需要确定这是一个bug, 如果是个好QA, 还可以提供更多的信息供开发人员参考:
将问题本身描述清楚就是方法的一种, 而且是第一步, 方法并不需要都是高大上的, 它更关注的是普适性.
对于很多问题, 特别是复杂的问题, 通过快速地复现问题往往可以事半功倍. 记得多年前, 我们碰到一个很棘手的问题, 当我们好几个人连续几天在不停看日志看代码讨论分析的时候, 公司派了一位资深专家一起来处理这个问题, 他却写了好些小的测试用例试图复现这个问题. 一旦把问题复现了, 那么就有了N份log可以分析, 信息量很可能更多了, 更重要的是可以使用其他的调试手段, trace工具等简化问题. 退一步说, 即使没能复现问题, 也一定程度上排除了一部分可能性, 而且这些东西是可以被看见被量化的, 对个人也是好事, 总有的问题会复杂到不是一时半会能搞定的.
复现问题需要对整个系统有足够理解, 比如两个docker导致cpu cache互相影响的话, 不停地调整目标docker里面的逻辑并不能起到作用. 复现问题关注两个点:
可以简单认为, 一个复杂系统总是由多个子系统组成, 分治是非常自然的想法. 当然怎么切分, 横着切还是竖着切, 从哪个角度切分, 可以多种多样, 很多方法都有分治的影子. 之前碰到过一个linux pxe启动慢的问题, pxe在下载Initrd的时候总是花费比较长的时间, 如果没有明确的证据, 我们不太可能一开始就去看PXE的代码是怎么通过ftfp下载文件的, 这只是整个路径的一部分, 如果我们押宝问题出在pxe代码, 那么这是个收益比较低的猜测. 一种更靠谱的方法是检查网络是否有问题, 当然这也是一种猜测, 但至少可以比较简单进行验证从而给出结论. 更普适的方法是把整个pxe启动相关的流程和组件都画出来, 从而拆解成一个个小问题. 最后我定位到的是tftp server上的目录其实是通过nfs挂载的, 因为代码的每个commit都会在该目录下生成kernel和initrd两个文件, 导致目录下文件异常地多, 而nfs遍历该目录需要很长的时间.
当然这也不是万能的, 分治的核心是要把问题分解(divide)到足够小, 小到我们能够处理(conquer). 这样一个人的能力分为几个部分:
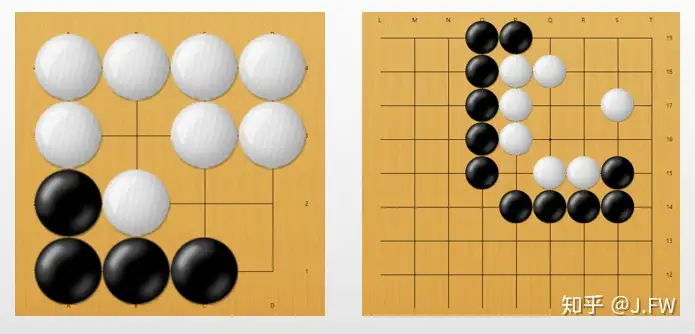
下图是101围棋网的两个死活题, 都是黑先白死, 左边那个比较简单, 如果能把问题分解到这种程度, 那么我是能hold住, 而右边的那个我既不能继续分解, 作为单个死活单元我也计算不出来, 这就一定程度上决定了我的围棋水平.
上面的图说了局部死活的影响, 另外一部分是怎么把全局分拆, 有的时候这并不是简单的事情. 右上的黑棋和数字棋子之间看似离得很远, 但是却紧密关联.
Scientific method是一个不停提出假设和验证的过程, 举例如下:
USE关注的是Utilization, Saturation和Errors. USE先列出系统的所有资源, 既可以是硬件资源比如cpu和io, 也可以是锁等软件资源, 然后通过工具获得每个资源的U/S/E信息:
USE会对系统的每个资源生成一个checklist, 这样有两个好处, 一是不容易漏了某个资源, 二是可以在短时间内得出一个结论, 非常时候问题的初步分析阶段.
RED关注的是Rates, Errors和Duration, 和USE从资源的角度不同, RED以微服务处理request出发, 通过简单的规则将不同的微服务统一到相同的指标上, 从而简化问题, 解决scalability of an operations team.
On-CPU的问题, 也就是CPU运行时花了过多时间的问题, 是相对比较简单, 通过采样往往就能发现问题所在. On-CPU的执行时间取决于两个因素:
本质上, On-CPU的问题变量比较少, 而且有相对固定的知识和方法, 比如false sharing, 第一次接触可能会没有头绪, 但它终究只是一个知识点. 变量的多少以及相关性直接决定了问题的复杂度, 比如一只南美洲亚马逊河流域热带雨林中的蝴蝶,偶尔扇动几下翅膀,可以在两周以后引起美国得克萨斯州的一场龙卷风, 从德克萨斯的龙卷风反过来推断出其根本原因来源于蝴蝶是相当复杂的.
和On-CPU不同, 目标程序都没有在cpu上运行, 普通的采样通过在中断处理函数中抓栈的方式就不好用了, 但是我们可以trace内核调度的代码来解决这个问题, 具体做法可以参考 offcputime的源码, 只要trace函数finish_task_switch即可. 对于时钟触发的采样, 开销基本是确定的, 但是对于软件event, 比如scheduler event, 它发生的次数和上面跑的应用执行情况有很强的相关性, 当scheduler event过多的时候, 额外的开销需要注意. 这里也说明熟悉os内核代码对于系统调试来说一定程度上必须的, 一是熟悉内核能够帮助我们理解问题, 二是调试时想了解的很多信息都可以通过内核抓取, 以Brendan的那些工具为例, 很大一部分都是通过在内核插桩完成的.
Thread State Analysis关注的线程的状态. 当我们说一个请求或者mysql的一条sql执行慢的时候, 它其实是指这个sql的整个延迟, 这包括了执行时间以及等待时间等, 通过拆分出每个状态的时长, 我们就知道该sql是因为cpu执行太长还是io时间太长等.
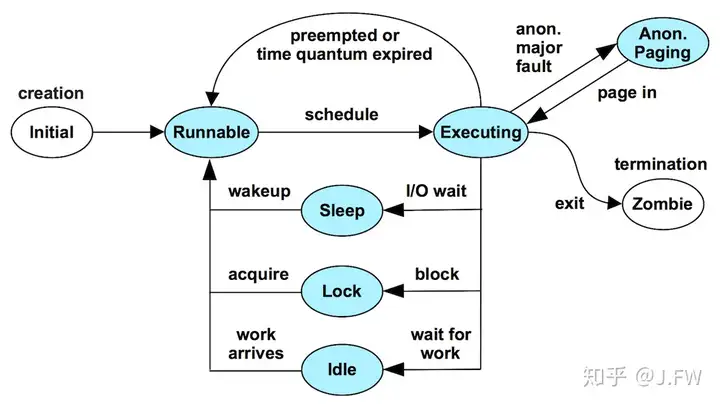
TSA其实部分覆盖了scheduler latency, 也就是thread处于running但是不能on cpu的状态. 在前公司时升级内核版本的时候有过调试scheduler latency的经验, 现在手上已经没有相关文档, 这里摘取Dick Sites的Datacenter Computers里面的例子. 首先看一下 Dick Sites的介绍, 感受一下名门正宗:
Fred Brooks, John Cocke, and Seymour Cray strongly influenced his approach to computer architecture; Don Knuth his approach to CPU performance; and Edward Tufte his approach to displaying dense tracing information.
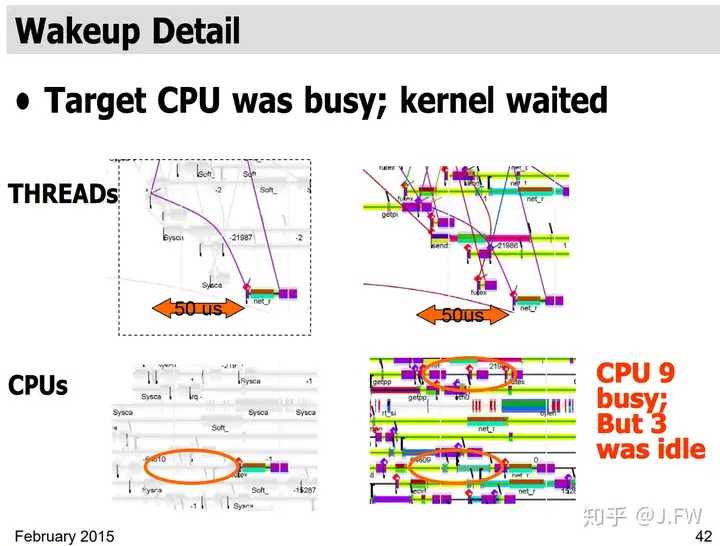
这里的方法是通过各种不同的角度观察系统, 并关联到相同的时间轴上:
有了上面的信息, 我们可以发现当thread被唤醒时, 它并没有马上on cpu, 而是过了50us才得到执行, 这就是调度延迟. 特别地, 这段时间是有cpu处于空闲状态的, 内核调度器从cache的角度决定不做迁移. 在我自己处理的那个case, 及时迁移对性能是有正面影响的. 这不能简单说迁移好还是不迁移好, 所以一般内核会搞个配置选项.
除了以上一些方法外, 还有很多其他方法这里不再一一详述:
工具在性能分析过程中作用很大, 熟练使用和编写新的工具都可能加快问题的解决, 但是使用工具或者编写基本的trace工具其实没有太高的门槛, 更高的门槛反而是理解这些工具后面的子系统, 当我们能在这些子系统提出有针对性问题时, 自然就知道需要使用或者编写哪些工具, 所以我把下面的图缩小了.
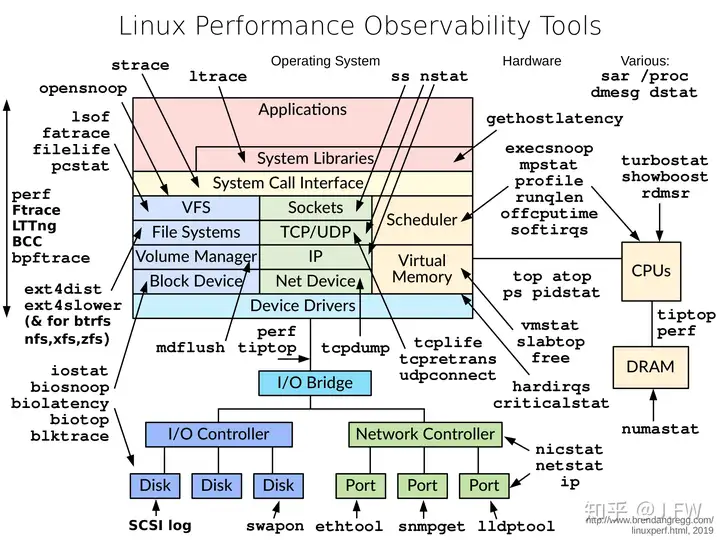
人终归是视觉动物, 相亲贴说得再好下面的回帖总是无图无真相. 同样的数据不同展示, 起到的效果是完全不一样的, 绝大部分人不能像就电影里面的人那样能一堆跳动的0/1里面能够过滤出有用信息. 一张好的图不仅能帮助我们识别出问题, 还能帮助我们提出问题, 有机会真的有必要学习一下Edward Tufte的大作, 这是门大学问.
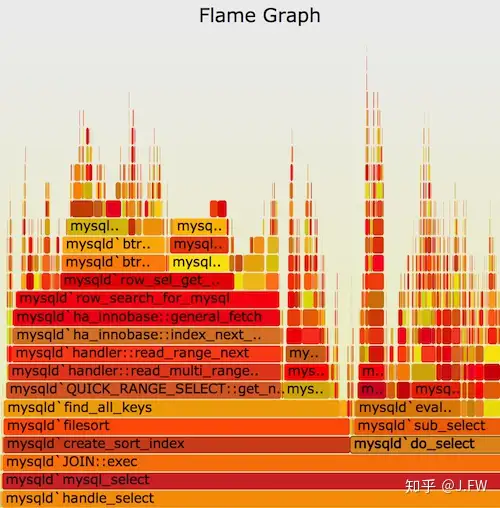
Flame graph现在几乎是性能分析的必备工具, 其流行程度可见一斑, 所以在上面Brendan的75字bio就提到了它. flame graph之所以流行可能有这几个原因:
现在flame graph几乎做成了图形化显示栈信息的标准方式, 基于frame graph又开发出了differential flame graph, icicle flame graph, offcpu包括wakeup stack的flame graph等.
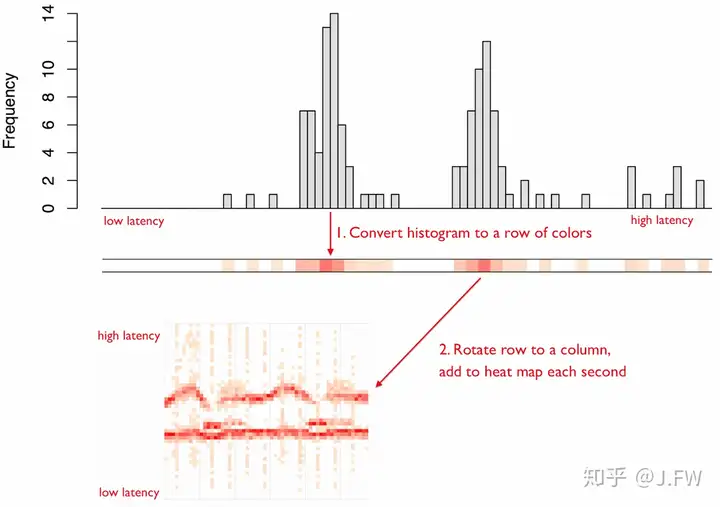
Heat map最核心的思想是用颜色来代表一维, 这样二维的就退化为一维, 三维的退化为二维.
和heat map不同, frequency trail并没有降低维度, 而是通过高度来表示frequency, 所以可以有更高的精度. 下面每行表示一个分布, 我们可以很清楚看出每行的分布, 以及圆点代表的outliers. 每座山也可以根据某种规则, 比如mean对齐的方式移动.

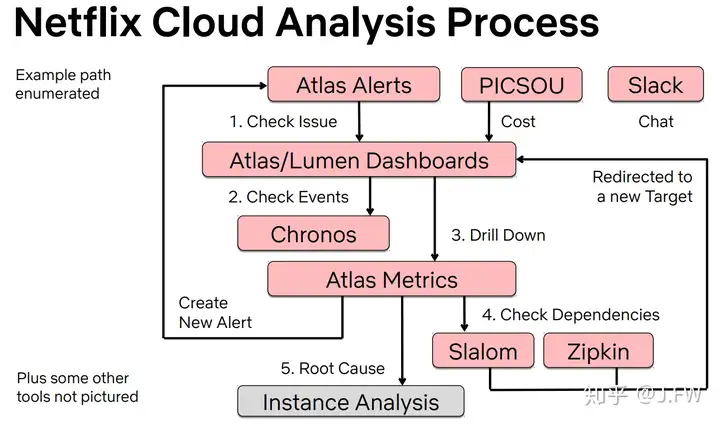
对公司而言, 一套完整的性能分析或者定位平台的重要性不言而喻, 对个人而言也是一样, 没有分析平台的话, 做性能分析就像是打零工, 即使有能力解决各种疑难杂症, 也很难成为那个go-to person, 因为大部分人压根就不知道有这个人, 但是平台却不一样. 将平台作为抓手, 通过平台解决80%-90%的问题, 从而有精力去解决其他的复杂问题. 下面是Netflix的分析流程, 最麻烦的部分也就是Instance Analysis需要用到上述方法. 另外, Atlas的github: https://github.com/Netflix/atlas.
Dashboard不是将所有的metrics一股脑随意展示出来, 它需要体现出我们定位问题的方法论, 需要便利我们进行调试, 比如使用USE方法应该怎么展示, 使用drill down方法应该怎么展示等等.