https://zhuanlan.zhihu.com/p/149836046复制
Linux native aio一方面有其实用价值, 基本满足了特别业务比如大型数据库系统对异步io的需求, 另一方面却被总是被诟病, 既不完美也不通用, 究其原因在于设计异步系统的理念.
aio最核心的需求就是解偶submit和wait for completion, 简单地说就是在submit的时候不要阻塞, 这样用户在submit之后可以做其它事情或者继续submit新的io, 从而获得更高的cpu利用率和磁盘带宽. 早期aio的需求主要来源于数据库, 这对当时aio的设计起到了决定性的作用. 和大部分情况一样, 第一步先解决现有问题, 然后才去看能不能扩展到更通用的领域, 而实际情况往往是第一步就决定了后面不好扩展. 数据库比如innodb, page buffer由db自己管理, 基本不使用os提供的page cache, 只要实现异步的direct io就能满足db的需求.
因为主要目标是实现异步的direct io, 把io提交到device的request queue就可以, 后面的执行本来就是异步过程.
do_syscall_64
__x64_sys_io_submit
io_submit_one
__io_submit_one.constprop.0
aio_write
btrfs_file_write_iter
generic_file_direct_write
btrfs_direct_IO
__blockdev_direct_IO
do_blockdev_direct_IO
btrfs_submit_direct
btrfs_map_bio
generic_make_request复制大部分情况下submit direct io可以直接提交到request queue, 但是submit的路径上并不是完全没有阻塞点, 比如pin user page以及文件系统get_block, 或者超过了qdepth. 在某些编程模型下, 比如为了减少context switch的开销, 每个cpu只有一个thread, 当该thread sleep的时候, 就会直接影响到系统的吞吐. 但是db的编程模型并没有这种严格要求, 偶尔的阻塞并不一定能直接导致性能下降, 而且用户态也可以通过一些手段来降低submit阻塞的情况.
另外, 关于dio的语义也是比较模糊的, 引用 Clarifying Direct IO's Semantics 的一段话
The exact semantics of Direct I/O (O_DIRECT) are not well specified. It is not a part of POSIX, or SUS, or any other formal standards specification. The exact meaning of O_DIRECT has historically been negotiated in non-public discussions between powerful enterprise database companies and proprietary Unix systems, and its behaviour has generally been passed down as oral lore rather than as a formal set of requirements and specifications.
异步buffer io比dio复杂很多, dio本质上使用了device的request queue来处理磁盘io的阻塞, 而buffer io因为增加了一层page cache, 多出了很多阻塞点.

以read为例, 这里的异步并不要求page cache到user buffer的copy是异步的, 毕竟这并没有阻塞, 这里关注lock_page等导致的阻塞. 比如要读2个page, 第一个在page cache中并且uptodate, 而第二个不在page cache中, 同步的read会因为第2个page没有ready从而阻塞.
为了做到异步化, 内核实现了retry-based的机制:
In a retry-based model, an operation executes by running through a series of iterations. Each iteration makes as much progress as possible in a non-blocking manner and returns. The model assumes that a restart of the operation from where it left off will occur at the next opportunity. To ensure that another opportunity indeed arises, each iteration initiates steps towards progress without waiting. The iteration then sets up to be notified when enough progress has been made and it is worth trying the next iteration. This cycle is repeated until the entire operation is finished.
以内核2.6.12为例, 支持aio的文件系统实现aio_read, 如果没有读完, 需要通知后面进行retry:
aio_pread
ret = file->f_op->aio_read(iocb, iocb->ki_buf, iocb->ki_left, iocb->ki_pos);
return -EIOCBRETRY if (ret > 0); // 如果没有读完复制而retry的函数正是aio_pread:
io_submit_one
init_waitqueue_func_entry(&req->ki_wait, aio_wake_function);
aio_setup_iocb(req);
kiocb->ki_retry = aio_pread;
aio_run_iocb(req);
current->io_wait = &iocb->ki_wait;
ret = retry(iocb);
current->io_wait = NULL;
__queue_kicked_iocb(iocb) if (-EIOCBRETRY == ret);复制当read的数据ready时, 会retry之前未完成的部分:
aio_wake_function
kick_iocb(iocb);
queue_kicked_iocb
run = __queue_kicked_iocb(iocb);
aio_queue_work(ctx) if (run);
queue_delayed_work(aio_wq, &ctx->wq, timeout);
INIT_WORK(&ctx->wq, aio_kick_handler, ctx);
aio_kick_handler
requeue =__aio_run_iocbs(ctx);
queue_work(aio_wq, &ctx->wq) if (requeue);复制retry机制依赖一个前提, 每一次调用ki_retry()的时候不能block, 否则就没有retry一说, 所以需要将之前的阻塞点比如lock_page改造成非阻塞点, 在资源不ready的情况返回EIOCBRETRY, 而不是同步等待资源ready. 具体可以参考Filesystem AIO rdwr - aio read
-void __lock_page(struct page *page)
+int __lock_page_wq(struct page *page, wait_queue_t *wait)
{
wait_queue_head_t *wqh = page_waitqueue(page);
- DEFINE_WAIT(wait);
+ DEFINE_WAIT(local_wait);
+ if (!wait)
+ wait = &local_wait;
+
while (TestSetPageLocked(page)) {
- prepare_to_wait(wqh, &wait, TASK_UNINTERRUPTIBLE);
+ prepare_to_wait(wqh, wait, TASK_UNINTERRUPTIBLE);
if (PageLocked(page)) {
sync_page(page);
+ if (!is_sync_wait(wait))
+ return -EIOCBRETRY;
io_schedule();
}
}
- finish_wait(wqh, &wait);
+ finish_wait(wqh, wait);
+ return 0;
+}
+EXPORT_SYMBOL(__lock_page_wq);
+
+void __lock_page(struct page *page)
+{
+ __lock_page_wq(page, NULL);
}
EXPORT_SYMBOL(__lock_page);
@@ -621,7 +655,13 @@
goto page_ok;
/* Get exclusive access to the page ... */
- lock_page(page);
+
+ if (lock_page_wq(page, current->io_wait)) {
+ pr_debug("queued lock page \n");
+ error = -EIOCBRETRY;
+ /* TBD: should we hold on to the cached page ? */
+ goto sync_error;
+ }复制以2.6.12为例, 只有在aio_pread/aio_pwrite两个函数中返回了EIOCBRETRY, 而上面提到的lock_page等改造并没有进入内核, 所以buffer io的异步支持没有完成, 只是先加了用于支持retry的框架. 最终在这个commit中全部删掉了, btw, 下面说的kernel thread需要使用submit task的mm, 因为里面会涉及user/kernel间的内存拷贝.
commit 41003a7bcfed1255032e1e7c7b487e505b22e298
Author: Zach Brown <zab@redhat.com>
Date: Tue May 7 16:18:25 2013 -0700
aio: remove retry-based AIO
This removes the retry-based AIO infrastructure now that nothing in tree
is using it.
We want to remove retry-based AIO because it is fundemantally unsafe.
It retries IO submission from a kernel thread that has only assumed the
mm of the submitting task. All other task_struct references in the IO
submission path will see the kernel thread, not the submitting task.
This design flaw means that nothing of any meaningful complexity can use
retry-based AIO.
This removes all the code and data associated with the retry machinery.
The most significant benefit of this is the removal of the locking
around the unused run list in the submission path.复制retry based实现的aio + buffer io使用的设计模式是:
AIO = Sync IO - wait + retry复制这种模式注定了改造起来非常复杂, 首先要找到所有的同步点, 再一个一个改造成异步点, 这种try-and-fix的方法很难提供一个清晰的演进路径, 而aio + buffer io的user case不足以驱动全面改造, 最终native aio并没有真的提供buffer io的异步化. 最后我们引用 Asynchronous I/O Support in Linux 2.5 的一段话来看当时的设计目标:
Ideally, an AIO operation is completely non-blocking. If too few resources exist for an AIO operation to be completely non-blocking, the operation is expected to return -EAGAIN to the application rather than cause the process to sleep while waiting for resources to become available.
However, converting all potential blocking points that could be encountered in existing file I/O paths to an asynchronous form involves trade-offs in terms of complexity and/or invasiveness. In some cases, this tradeoff produces only marginal gains in the degree of asynchrony.
This issue motivated a focus on first identifying and tackling the major blocking points and less deeply nested cases to achieve maximum asynchrony benefits with reasonably limited changes. The solution can then be incrementally improved to attain greater asynchrony.
我们使用fio来做个简单的测试, 看看io_uring大致的工作流程.
# echo 3 > /proc/sys/vm/drop_caches复制$ sudo trace-bpfcc -K 'r::io_read (retval) "r=%x", retval' \
'r::page_cache_sync_readahead' \
'r::page_cache_async_readahead'复制$ ./fio --name=aaa --filename=aaa --ioengine=io_uring --rw=read --size=16k --bs=8k复制根据如下收集的结果, 我们可以大致看出io_uring异步读数据流程:
17547 17547 fio io_read r=fffffff5
kretprobe_trampoline+0x0 [kernel]
io_queue_sqe+0xd3 [kernel]
io_submit_sqe+0x2ea [kernel]
io_ring_submit+0xbf [kernel]
__x64_sys_io_uring_enter+0x1aa [kernel]
do_syscall_64+0x5a [kernel]
entry_SYSCALL_64_after_hwframe+0x44 [kernel]
15931 15931 kworker/u64:10 page_cache_sync_readahead
kretprobe_trampoline+0x0 [kernel]
generic_file_read_iter+0xdc [kernel]
io_read+0xeb [kernel]
kretprobe_trampoline+0x0 [kernel]
io_sq_wq_submit_work+0x15f [kernel]
process_one_work+0x1db [kernel]
worker_thread+0x4d [kernel]
kthread+0x104 [kernel]
ret_from_fork+0x22 [kernel]
17547 17547 fio page_cache_async_readahead
kretprobe_trampoline+0x0 [kernel]
generic_file_read_iter+0xdc [kernel]
io_read+0xeb [kernel]
kretprobe_trampoline+0x0 [kernel]
io_queue_sqe+0xd3 [kernel]
io_submit_sqe+0x2ea [kernel]
io_ring_submit+0xbf [kernel]
__x64_sys_io_uring_enter+0x1aa [kernel]
do_syscall_64+0x5a [kernel]
entry_SYSCALL_64_after_hwframe+0x44 [kernel]复制具体的实现这里不一一展开, 主要看一下user space和kernel space交互的几个ring buffer. 图片来源: https://mattermost.com/blog/iouring-and-go/
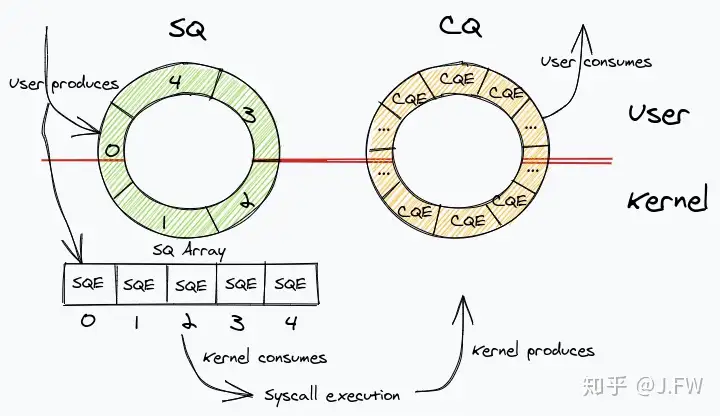
通过SQ, 把submit path的逻辑和kernel的其他模块解耦, 确保submit path上不会阻塞. 如上面的测试, 在io_uring_enter的时候不会去调用可能会导致阻塞的page_cache_sync_readahead, 而是使用workqueue的方式后台执行, 当然worker线程是可能也是可以被阻塞的. 另外SQ的可用长度在userspace是可见的, 所以也不会因为等待SQ entry而阻塞.
最简单高效的异步系统是生产者将任务投递到一条队列上, 消费者处理队列上的任务. 如果在任务到达队列之前生产者就已经阻塞, 那么就不能达到异步的目的, 所以这条队列需要尽可能靠近生产者, 而不是靠近消费者. 这样的投递系统不只简单高效, 并且十分通用, 可以适用绝大部分任务, 所以io_uring不只在传统的块设备上发挥重要作用, 已经广泛应用到各种场合.