正文
行转列排除重复数据并且对比的方法
摘要
出差成都. 突然发现被人当成Shell脚本小子了
今天让对着投影仪确定文件是否正确和完备
几乎闪瞎我的双眼
感觉国家这么多年的英语教育的确卓有成效
看简写, 耗费大半天也猜不出是啥意思来..
为了能够记录下来,干的事情, 把用到的命令和处理过程记录一下.
备忘也希望对看到的人有所帮助.
复制
获取原始数据
数据格式为:
"ABC","BCD",""..... 等的样式. 我这边的处理方式为
另存为文件 例如 master
进行处理:
1. 第一步 处理标点符号等
sed -i 's/"//g' master
也可以将多语的空格干掉
sed -i 's/ //g' master
2. 第二步设置行转列
可以将 , 修改为 空格 进行下一步的处理.
sed -i 's/,/ /g' master
注意第一步和第二步一定不要反了..
for i in `cat master` ; do echo $i ; done >master1
进行排序.
sort master1 >master2
然后就可以放入 excel 进行比较了.
复制
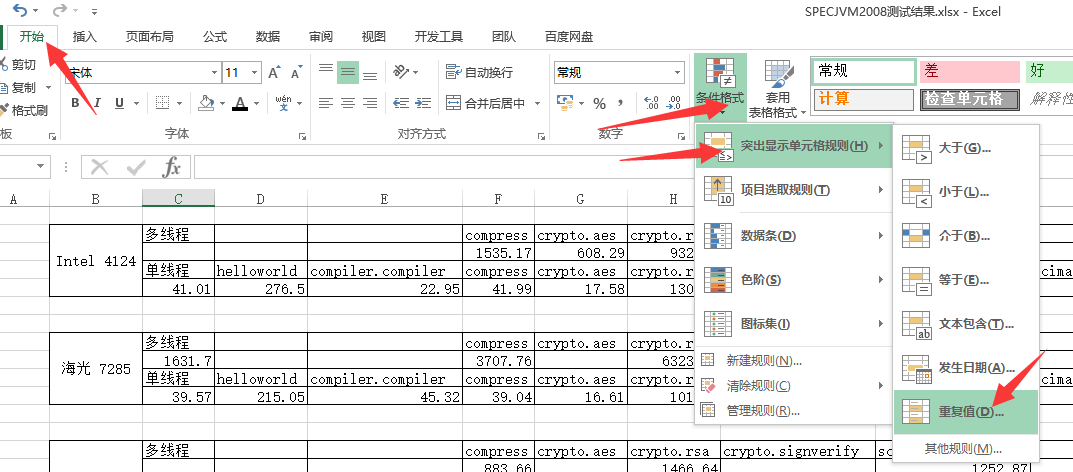
excel去除重复数据
打开excel
将两列需要对比的数据放到 相邻的两个列中.
然后选中这两个列.
点击 开始 -> 条件格式 -> 突出显示重复单元格 -> 重复值
将重复值 设置为有浅红色填充底色的单元格
然后很容易就可以将两个不重复的数据拉取出来.
复制
操作处理部分