Table of Contents
RPS介绍(Receive Packet Steering)
RSS介绍(Receive-Side Scaling,接收方扩展)
- RPS(Receive Packet Steering,接收数据包指导)
- RFS(Receive flow steering,接收流转向)
- RSS(receive side scaling,接收方扩展)
多队列简介
网卡多队列,顾名思义,也就是传统网卡的DMA队列有多个,网卡有基于多个DMA队列的分配机制。多队列网卡已经是当前高速率网卡的主流。
默认情况下,每个网络接口都有一个流量队列,一次由一个CPU处理。由于SND(安全网络分发器,SecureXL和CoreXL调度程序)在处理流量队列的CPU上运行,因此用于加速的CPU数量不能超过处理流量的接口数量。多队列可让您为每个网络接口配置多个流量队列。这意味着可以使用多个CPU进行加速。
多队列网卡是一种技术,最初是用来解决网络IO QoS (quality of service)问题的,后来随着网络IO的带宽的不断提升,单核CPU不能完全处满足网卡的需求,通过多队列网卡驱动的支持,将各个队列通过中断绑定到不同的核上,以满足网卡的需求。
常见的有Intel的82575、82576,Boardcom的57711等,下面以公司的服务器使用较多的Intel 82575网卡为例,分析一下多队列网卡的硬件的实现以及linux内核软件的支持。
RPS介绍(Receive Packet Steering)
RPS/RFS 功能是在Linux- 2.6.35中有google的工程师提交的两个补丁,这两个补丁的出现主要是基于以下两点现实的考虑:
- 这两个补丁的出现,是由于服务器的CPU越来越强劲,可以到达十几核、几十核,而网卡硬件队列则才4个、8个,这种发展的不匹配造成了CPU负载的不均衡。
- 上面的提到的是多队列网卡的情况,在单队列网卡的情况下,RPS/RFS相当于在系统层用软件模拟了多队列的情况,以便达到CPU的均衡。
出现RFS/RPS的原因主要是由于过多的网卡收包和发包中断集中在一个CPU上,在系统繁忙时,CPU对网卡的中断无法响应,这样导致了服务器端的网络性能降低,从这里可以看出其实网络性能的瓶颈不在于网卡,而是CPU,因为现在的网卡很多都是万兆并且多队列的,如果有过多的中断集中在一个CPU上,将导致该CPU无法处理,所以可以使用该方法将网卡的中断分散到各个CPU上。但对于CentOS 6.1已经支持了。“http://blog.chinaunix.net/uid-20788636-id-4838269.html”
RPS(Receive Packet Steering)主要是把软中断的负载均衡到各个cpu,简单来说,是网卡驱动对每个流生成一个hash标识,这个HASH值得计算可以通过四元组来计算(SIP,SPORT,DIP,DPORT),然后由中断处理的地方根据这个hash标识分配到相应的CPU上去,这样就可以比较充分的发挥多核的能力了。通俗点来说就是在软件层面模拟实现硬件的多队列网卡功能,如果网卡本身支持多队列功能的话RPS就不会有任何的作用。该功能主要针对单队列网卡多CPU环境,如网卡支持多队列则可使用SMP irq affinity直接绑定硬中断。


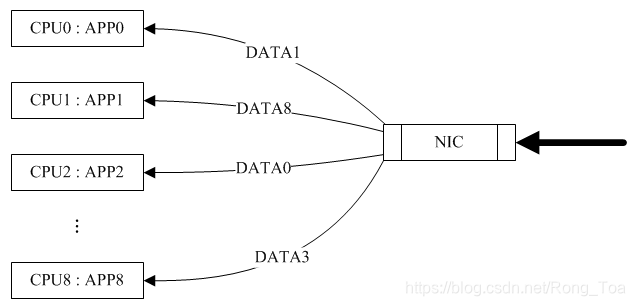
只有RPS的情况下(来源网络)
RFS介绍(Receive flow steering)
由于RPS只是单纯把数据包均衡到不同的cpu,这个时候如果应用程序所在的cpu和软中断处理的cpu不是同一个,此时对于cpu cache的影响会很大,那么RFS(Receive flow steering)确保应用程序处理的cpu跟软中断处理的cpu是同一个,这样就充分利用cpu的cache,这两个补丁往往都是一起设置,来达到最好的优化效果, 主要是针对单队列网卡多CPU环境。

同时开启RPS/RFS后(来源网络)
rps_flow_cnt,rps_sock_flow_entries,参数的值会被进位到最近的2的幂次方值,对于单队列设备,单队列的rps_flow_cnt值被配置成与 rps_sock_flow_entries相同。“http://blog.chinaunix.net/uid-20788636-id-4838269.html”
RSS介绍(receive side scaling)
RSS(receive side scaling)是有微软提出的,通过这项技术能够将网络流量分载到多个cpu上,降低单个cpu的占用率。默认情况下,每个cpu核对应一个rss队列。ixgbe驱动将收到的数据包的源、目的ip地址和端口号,交由网卡硬件计算出一个rss hash值,再根据这个hash值来决定将数据包分配到哪个队列中。通过cat /proc/interrupts |grep 网卡名的方式,就可以看到网卡使用了几个rss通道。http://blog.chinaunix.net/uid-20788636-id-4838269.html
Linux内核中,RPS(Receive Packet Steering)在接收端提供了这样的机制。RPS主要是把软中断的负载均衡到CPU的各个core上,网卡驱动对每个流生成一个hash标识,这个hash值可以通过四元组(源IP地址SIP,源四层端口SPORT,目的IP地址DIP,目的四层端口DPORT)来计算,然后由中断处理的地方根据这个hash标识分配到相应的core上去,这样就可以比较充分地发挥多核的能力了。

DPDK多队列支持
DPDK Packet I/O机制具有与生俱来的多队列支持功能,可以根据不同的平台或者需求,选择需要使用的队列数目,并可以很方便地使用队列,指定队列发送或接收报文。由于这样的特性,可以很容易实现CPU核、缓存与网卡队列之间的亲和性,从而达到很好的性能。从DPDK的典型应用l3fwd可以看出,在某个核上运行的程序从指定的队列上接收,往指定的队列上发送,可以达到很高的cache命中率,效率也就会高。
除了方便地做到对指定队列进行收发包操作外,DPDK的队列管理机制还可以避免多核处理器中的多个收发进程采用自旋锁产生的不必要等待。
以run to completion模型为例,可以从核、内存与网卡队列之间的关系来理解DPDK是如何利用网卡多队列技术带来性能的提升。
- 将网卡的某个接收队列分配给某个核,从该队列中收到的所有报文都应当在该指定的核上处理结束。
- 从核对应的本地存储中分配内存池,接收报文和对应的报文描述符都位于该内存池。
- 为每个核分配一个单独的发送队列,发送报文和对应的报文描述符都位于该核和发送队列对应的本地内存池中。
可以看出不同的核,操作的是不同的队列,从而避免了多个线程同时访问一个队列带来的锁的开销。但是,如果逻辑核的数目大于每个接口上所含的发送队列的数目,那么就需要有机制将队列分配给这些核。不论采用何种策略,都需要引入锁来保护这些队列的数据。
网卡是如何将网络中的报文分发到不同的队列呢?常用的方法有微软提出的RSS与英特尔提出的Flow Director技术,前者是根据哈希值希望均匀地将包分发到多个队列中。后者是基于查找的精确匹配,将包分发到指定的队列中。此外,网卡还可以根据优先级分配队列提供对QoS的支持。
高级的网卡设备(比如Intel XL710)可以分析出包的类型,包的类型会携带在接收描述符中,应用程序可以根据描述符快速地确定包是哪种类型的包。DPDK的Mbuf结构中含有相应的字段来表示网卡分析出的包的类型。
RSS介绍(Receive-Side Scaling,接收方扩展)
RSS就是根据关键字通过哈希函数计算出哈希值,再由哈希值确定队列。

关键字是如何确定的呢?

哈希函数一般选取微软托普利兹算法(Microsoft Toeplitz Based Hash)或者对称哈希。
Flow Director介绍
采用dpdk开发实现类似LVS这种负载均衡时,为了提高性能,session数据结构是per core的,这样可以避免cpu之间锁竞争。详细介绍可以参考https://zhuanlan.zhihu.com/p/24826649。里面详细介绍了为什么需要使用flow director。https://blog.csdn.net/dremi/article/details/78792148

Flow Director技术是Intel公司提出的根据包的字段精确匹配,将其分配到某个特定队列的技术:网卡上存储了一个Flow Director的表,表的大小受硬件资源限制,它记录了需要匹配字段的关键字及匹配后的动作;驱动负责操作这张表,包括初始化、增加表项、删除表项;网卡从线上收到数据包后根据关键字查Flow Director的这张表,匹配后按照表项中的动作处理,可以是分配队列、丢弃等。

相比RSS的负载分担功能,它更加强调特定性。比如,用户可以为某几个特定的TCP对话(S-IP+D-IP+S-Port+D-Port)预留某个队列,那么处理这些TCP对话的应用就可以只关心这个特定的队列,从而省去了CPU过滤数据包的开销,并且可以提高cache的命中率。
图片来源Intel 82599 10GbE Controllerで遊ぼう

服务质量
多队列应用于服务质量(QoS)流量类别:把发送队列分配给不同的流量类别,可以让网卡在发送侧做调度;把收包队列分配给不同的流量类别,可以做到基于流的限速。

流过滤
来自外部的数据包哪些是本地的、可以被接收的,哪些是不可以被接收的?可以被接收的数据包会被网卡送到主机或者网卡内置的管理控制器,其过滤主要集中在以太网的二层功能,包括VLAN及MAC过滤。

应用
针对Intel®XL710网卡,PF使用i40e Linux Kernel驱动,VF使用DPDK i40e PMD驱动。使用Linux的Ethtool工具,可以完成配置操作cloud filter,将大量的数据包直接分配到VF的队列中,交由运行在VF上的虚机应用来直接处理。
echo 1 > /sys/bus/pci/devices/0000:02:00.0/sriov_numvfsmodprobe pci-stubecho "8086 154c" > /sys/bus/pci/drivers/pci-stub/new_idecho 0000:02:02.0 > /sys/bus/pci/devices/0000:2:02.0/driver/unbindecho 0000:02:02.0 > /sys/bus/pci/drivers/pci-stub/bind qemu-system-x86_64 -name vm0 -enable-kvm -cpu host -m 2048 -smp 4 -drive file=dpdk-vm0.img -vnc :4 -device pci-assign,host=02:02.0 ethtool -N ethx flow-type ip4 dst-ip 2.2.2.2 user-def 0xffffffff00000000 action 2 loc 1复制
多队列要求和限制
- 单核计算机不支持多队列。
- 网络接口必须支持多队列
- 队列数量受CPU数量和接口驱动程序类型的限制:
| 驱动类型 | 建议的最大接收队列数 |
|---|---|
| Igb | 4 |
| Ixgbe | 16 |
确定是否需要多队列
本节将帮助您确定是否可以从配置多队列中受益。我们建议您在配置多队列之前执行以下步骤:
- 确保已启用SecureXL
- 检查CPU角色分配
- 检查CPU利用率
- 确定是否可以将更多CPU分配给SND
- 确保网络接口支持多队列
确保启用SecureXL
- 在安全网关上,运行:
fwaccel stat - 检查加速器状态值:
[Expert@gw-30123d:0]# fwaccel statAccelerator Status : onAccept Templates : enabledDrop Templates : disabledNAT Templates : disabled by user Accelerator Features : Accounting, NAT, Cryptography, Routing, HasClock, Templates, Synchronous, IdleDetection, Sequencing, TcpStateDetect, AutoExpire, DelayedNotif, TcpStateDetectV2, CPLS, WireMode, DropTemplates, NatTemplates, Streaming, MultiFW, AntiSpoofing, DoS Defender, ViolationStats, Nac, AsychronicNotif, ERDOSCryptography Features : Tunnel, UDPEncapsulation, MD5, SHA1, NULL, 3DES, DES, CAST, CAST-40, AES-128, AES-256, ESP, LinkSelection, DynamicVPN, NatTraversal, EncRouting, AES-XCBC, SHA256复制
如果此字段的值为:on,则启用SecureXL 。
注意-
- 仅当启用SecureXL时,多队列才有意义。
- 即使在R75.40中停止了对放置模板的支持,放置模板仍会显示在命令输出中
检查CPU角色分配
要查看CPU角色分配,请运行: fw ctl affinity –l
此命令显示分配SND CPU的接口的CPU关联性。它还显示了CoreXL防火墙实例的CPU亲和力。例如,如果您在安全网关上运行命令:
[Expert@gw-30123d:0]# fw ctl affinity -lMgmt: CPU 0eth1-05: CPU 0eth1-06: CPU 1fw_0: CPU 5fw_1: CPU 4fw_2: CPU 3fw_3: CPU 2复制在此示例中:
- SND在CPU 0和CPU1上运行
- CoreXL防火墙实例在CPU 2-5上运行
如果在VSX网关上运行命令:
- [Expert@gw-30123d:0]# fw ctl affinity -l
- Mgmt: CPU 0
- eth1-05: CPU 0
- eth1-06: CPU 1
- VS_0 fwk: CPU 2 3 4 5
- VS_1 fwk: CPU 2 3 4 5
在此示例中:
- SND在CPU 0-1上运行
- 所有虚拟系统的CoreXL防火墙实例(fwk进程的一部分)正在CPU 2-5上运行。
检查CPU利用率
- 在安全网关上,运行:
top。 - 按1切换SMP视图。
这显示每个CPU的使用率和空闲百分比。例如:
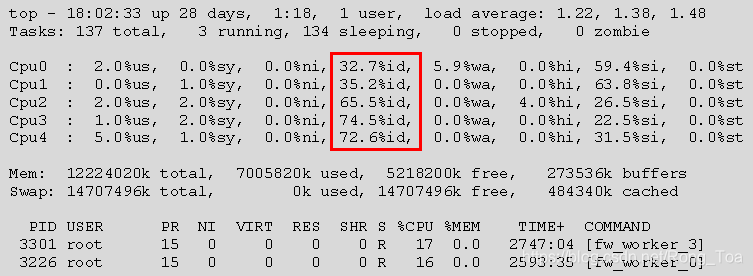
在此示例中:
- SND CPU(CPU0和CPU1)大约空闲30%
- CoreXL防火墙实例CPU大约空闲70%
确定是否可以将更多CPU分配给SND
如果处理流量的网络接口多于分配给SND的CPU(如fw ctl affinity –l命令的输出所示),则可以为SND分配更多的CPU。
例如,如果您具有以下网络接口:
- eth1-04 –连接到内部网络
- eth1-05 –连接到内部网络
- eth1-06 –连接到DMZ
- eth1-07 –连接到外部网络
运行fw ctl affinity -l显示此IRQ相似性:
[Expert@gw-30123d:0]# fw ctl affinity -lMgmt: CPU 0eth1-04: CPU 1eth1-05: CPU 0eth1-06: CPU 1eth1-07: CPU 0fw_0: CPU 5fw_1: CPU 4fw_2: CPU 3fw_3: CPU 2复制您可以更改接口IRQ关联性以将更多CPU用于SND。
确保网络接口支持多队列
仅在使用igb(1Gb)或ixgbe(10Gb)驱动程序的网卡上支持多队列。在升级这些驱动程序之前,请确保最新版本支持多队列。
| 网关类型 | 网卡 |
|---|---|
| 安全设备 | 这些扩展卡在4000、12000和21000设备上支持多队列:
|
| IP设备 | XMC 1Gb卡在以下位置受支持:
|
| 打开服务器 | 使用igb(1Gb)或ixgbe(10Gb)驱动程序的网卡 |
- 要查看接口使用的驱动程序,请运行:
ethtool -i <interface name>。 - 安装使用igb或ixgbe驱动程序的新接口时,请运行:
cpmq reconfigure并重新引导。
建议
我们建议在以下情况下配置多队列:
- SND的CPU负载很高(空闲小于20%),并且
- CoreXL防火墙实例的CPU负载较低(空闲大于50%)
- 您不能通过更改接口IRQ关联性将更多CPU分配给SND
基本多队列配置
所述cpmq实用程序用于查看或改变当前多队列配置。
配置多队列
该cpmq set命令使您可以在支持的接口上配置多队列。
要配置多队列:
- 在网关上,运行:
cpmq set该命令:
- 显示所有受支持的活动接口
- 使您可以更改每个接口的多队列配置。
关闭的网络接口不显示。
注意-
- 多队列可让您最多配置两个接口
- 更改多队列配置后,必须重新启动网关。
查询当前的多队列配置
该cpmq得到命令显示支持的接口的多队列状态。
要查看多队列配置:
跑: cpmq get [-a]
该-a选项显示所有支持的接口(活动和非活动)的多队列配置。例如:
[Expert@gw-30123d:0]# cpmq get -a Active igb interfaces:eth1-05 [On]eth1-06 [Off]eth1-01 [Off]eth1-03 [Off]eth1-04 [On] Non active igb interfaces:eth1-02 [Off]复制
状态讯息
| 状态 | 含义 |
|---|---|
| 上 | 接口上启用了多队列 |
| 关 | 接口上禁用了多队列 |
| 等待中 | 当前禁用多队列。仅在重启网关后,才会在此接口上启用多队列 |
| 等待中 | 启用多队列。仅在重新启动网关后,才会在此接口上禁用多队列 |
在此示例中:
- 两个接口都启用了多队列
(eth1-05,eth1-04)
- 禁用多队列的三个接口
(eth1-06,eth1-01,eth1-03)
- 一个支持多队列的接口关闭
(eth1-02)
运行不带该-a选项的命令仅显示活动接口。
多队列管理
适用于SecureXL和CoreXL的CPU有两个主要角色:
- SecureXL和CoreXL调度程序CPU(SND-安全网络分发程序)
您可以使用
sim affinity -s命令手动配置它。 - CoreXL防火墙实例CPU
您可以使用
fw ctl affinity命令手动配置它。
为了获得最佳性能,同一个CPU不应同时在两个角色中工作。在安装过程中,将设置默认的CPU角色配置。例如,在十二台核心计算机上,将具有最低CPU ID的两个CPU设置为SND,将具有最高CPU ID的十个CPU设置为CoreXL防火墙实例。
如果没有多队列,分配给SND的CPU数量将受到处理流量的网络接口数量的限制。由于每个接口都有一个流量队列,因此每个队列一次只能由一个CPU处理。这意味着每个网络接口SND一次只能使用一个CPU。
当大多数流量加速时,SND的CPU负载可能会很高,而CoreXL防火墙实例的CPU负载可能会很低。这是对CPU容量的低效率利用。
通过多队列,您可以为每个受支持的网络接口配置多个通信队列,以便一个以上的SND CPU可以一次处理单个网络接口的通信。这样可以有效地平衡SND CPU和CoreXL防火墙实例CPU之间的负载。
专业术语
| 术语 | 描述 |
|---|---|
| SND | 安全网络分配器。运行SecureXL和CoreXL的CPU |
| 接收队列 | 接收数据包队列 |
| 发射队列 | 传输数据包队列 |
| IRQ亲和力 | 将IRQ绑定到一个或多个特定CPU。 |
高级多队列设置
高级多队列设置包括:
- 控制队列数
- IRQ亲和力
- 查看CPU利用率
控制队列数
控制队列数取决于驱动程序类型:
| 驱动类型 | s列 |
|---|---|
| igxbe | 为ixgbe接口配置多队列时,将为每个CPU创建一个RxTx队列。您可以控制活动rx队列的数量(所有tx队列均处于活动状态)。 |
| igb | 为igb接口配置多队列时,通过活动rx队列的数量来计算tx和rx队列的数量。 |
- 默认情况下,在安全网关上,活动rx队列的数量由以下公式计算:
活动的rx队列= CPU数量– CoreXL防火墙实例的数量
- 默认情况下,在VSX网关上,活动rx队列的数量通过以下方式计算:
活动的rx队列=分配给fwk进程的最低CPU ID
要控制活动rx队列的数量,请执行以下操作:
跑: cpmq set rx_num <igb/ixgbe> <number of active rx queues>
此命令将覆盖默认值。
要查看活动的rx队列数:
跑: cpmq get rx_num <igb/ixgbe>
要返回建议的rx队列数量:
在Security Gateway上,当您更改CoreXL防火墙实例的数量(使用cpconfig)时,活动队列的数量会自动更改。如果您手动配置rx队列数量,则活动队列的数量不会更改。
cpmq set rx_num <igb/ixgbe> default复制
IRQ亲和力
操作系统启动时,将自动设置队列的IRQ相似性,如图所示(rx_num设置为3):
- rxtx-0-> CPU 0
- rxtx-1-> CPU 1
- rxtx-2-> CPU 2
等等。在为rx和tx队列分配了单独的IRQ的情况下也是如此:
- rx-0-> CPU 0
- tx-0-> CPU 0
- rx-1-> CPU 1
- tx-1-> CPU 1
等等。
- 您不能使用
sim affinity或fw ctl affinity命令更改和查询多队列接口的IRQ相似性。 - 您可以通过运行以下命令来重置多队列IRQ的相似性:
cpmq set affinity - 您可以通过运行以下命令查看多队列IRQ的相似性:
cpmq get -v
重要提示-不要手动更改队列的IRQ关联性。手动更改队列的IRQ亲和力可能会影响性能。
查看CPU利用率
- 通过运行以下命令查找分配给多队列IRQ的CPU
cpmq get -v。例如:
[Expert@gw-30123d:0]# cpmq get -v Active igb interfaces:eth1-05 [On]eth1-06 [Off]eth1-01 [Off]eth1-03 [Off]eth1-04 [On] multi-queue affinity for igb interfaces: eth1-05: irq | cpu | queue----------------------------------------------------- 178 0 TxRx-0 186 1 TxRx-1 eth1-04: irq | cpu | queue----------------------------------------------------- 123 0 TxRx-0 131 1 TxRx-1复制在此示例中:
- 在两个igb接口(eth1-05和eth1-04)上启用了多队列
- 活动rx队列的数量配置为2(对于igb,队列数量由活动rx队列的数量计算)。
- 两个接口的IRQ均分配给CPU 0-1。
- 跑:
top - 按1切换到SMP视图。
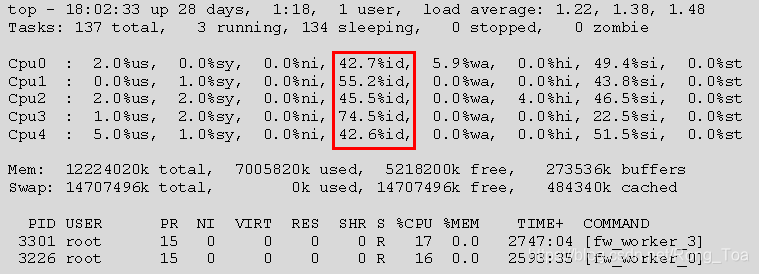
在上面的示例中,由于CPU0和CPU1正在处理队列,多队列CPU的CPU利用率约为50%(如步骤1所示)。
Sim Affinity命令
用于自动分配或取消接口的过程-CPU关联性。
| 参数 | 描述 |
| -l | 列出亲和力设置 |
| -s | 为没有多队列的接口设置静态或手动关联性(并取消 |
| -a | 每秒自动为所有接口设置关联性。 |
| -H | 显示帮助 |
sim affinity -a复制默认情况下,该sim affinity -a过程运行,并为启用多队列和不启用多队列的接口分配亲和力。在R76之前,该sim affinity命令将忽略多队列接口。
如果sim affinity -a通过运行已取消了该进程sim affinity -s,请使用cpqm set affinity重置多队列接口的亲和力。
覆盖RX队列和接口限制
- rx队列的数量受CPU数量和接口驱动程序类型的限制:
| 驱动类型 | 建议的最大接收队列数 |
|---|---|
| Igb | 4 |
| Ixgbe | 16 |
要添加更多的RX队列,请运行:
cpmq rx_num <igb/ixgbe> <number of active rx queues> -f复制由于IRQ的限制,您最多可以使用多队列配置两个接口。
要添加更多接口,请运行:
cpmq set -f复制
特殊方案和配置
- 在Security Gateway模式下:在某些或所有接口上启用多队列时更改CoreXL防火墙实例的数量
为了获得最佳性能,活动的rx队列的默认数量由以下公式计算:
活动的rx队列数量= CPU数量– CoreXL防火墙实例的数量
配置多队列时会自动设置此配置。更改实例数时,如果未手动设置,则活动rx队列数将自动更改。
- 在VSX模式下:更改
fwk分配给进程的CPU数量 - 活动rx队列的默认数目由以下公式计算:
活动的rx队列数=将fwk进程分配给的最低CPU ID
例如:
- [Expert@gw-30123d:0]# fw ctl affinity -l
- Mgmt: CPU 0
- eth1-05: CPU 0
- eth1-06: CPU 1
- VS_0 fwk: CPU 2 3 4 5
- VS_1 fwk: CPU 2 3 4 5
在这个例子中
- 活动的rx队列数设置为2。
- 配置多队列时会自动设置此配置。
- 更改虚拟系统的相似性时,它不会自动更新。更改虚拟系统的关联性时,请确保遵循“高级多队列设置”中的说明。
更改启用多队列的接口的状态的影响
- 将状态更改为DOWN
当您将接口状态更改为关闭时,将保存多队列配置。
由于启用了多队列的接口的数量限制为两个,因此在将其状态更改为down后,可能需要在接口上禁用多队列,才能在其他接口上启用多队列。
该
cpmq set命令使您可以在非活动接口上禁用多队列。 - 将状态更改为UP
如果出现以下情况,则必须重置多队列接口的IRQ关联性
- 接口上启用了多队列
- 您已将接口状态更改为关闭
- 您重新启动了网关
- 您将接口状态更改为up。
如果您正在运行自动sim相似性(
sim affinity -a),则不会发生此问题。默认情况下,自动sim关联会运行,并且必须使用sim affinity -s命令手动将其取消。要再次设置多队列接口的静态亲和力,请运行:
cpmq set affinity。
添加网络接口
- 将网络接口卡添加到使用igb或ixgbe驱动程序的网关时,由于接口索引,多队列配置可能会更改。如果将网络接口卡添加到使用igb或ixgbe驱动程序的网关,请确保再次运行多队列配置或运行:
cpmq reconfigure。 - 如果需要重新配置更改,将提示您重新引导计算机。
更改CoreXL防火墙实例的相似性
- 为了获得最佳性能,我们建议您不要将SND和CoreXL防火墙实例都分配给同一CPU。
- 当更改CoreXL防火墙实例与分配了多队列队列之一的CPU的关联性时,建议您遵循以下规则重新配置活动rx队列的数量:
活动的rx队列= CoreXL防火墙实例分配给的最低CPU编号
- 您可以通过运行以下命令配置活动rx队列的数量:
cpmq set rx_num <igb/ixgbe> <value/default>复制
故障排除
重新启动后,为多队列配置了错误的接口
更改网关上的物理接口后,可能会发生这种情况。要解决此问题:
或再次配置多队列。
- 运行:
cpmq reconfigure - 重启。
更改接口状态时,所有接口IRQ均分配给CPU 0或所有CPU
在自动关联过程运行之后(将关联过程在引导过程中自动运行),如果接口状态更改为UP,则可能会发生这种情况。
要解决此问题,请运行:
cpmq set affinity复制
如果您正在运行自动sim相似性(sim affinity -s),则不会发生此问题。默认情况下,自动sim关联会运行,并且必须使用sim affinity -s命令手动将其取消。
在VSX模式下,fwk进程与某些接口队列在同一CPU上运行
手动更改虚拟系统的亲缘关系但未相应地重新配置多队列时,可能会发生这种情况。
要解决此问题,请手动配置活动rx队列的数量或运行:,cpmq reconfigure然后重新启动。
在安全网关模式下–更改实例数量后,将在所有接口上禁用多队列
更改CoreXL防火墙实例的数量时,活动rx队列的数量会根据此规则自动更改(如果未手动配置):
活动的rx队列= CPU数量– CoreXL防火墙实例的数量
如果实例数等于CPU数,或者CPU数与CoreXL防火墙实例数之差为1,则将禁用多队列。要解决此问题,请运行以下命令手动配置活动的rx队列数:
cpmq set rx_num <igb/ixgbe> <value>复制
参考文章
- 《Multi-queue》https://sc1.checkpoint.com/documents/R76/CP_R76_PerformanceTuning_WebAdmin/93689.htm#o94128
- 《多队列网卡简介》https://blog.csdn.net/turkeyzhou/article/details/7528182
- 《SMP系统上具有多队列NIC的多线程》https://serverfault.com/questions/411868/multithreading-with-multi-queue-nic-on-smp-system
- 《DPDK笔记 RSS(receive side scaling)网卡分流机制》https://rtoax.blog.csdn.net/article/details/108532566
- 《网卡多队列》https://tonydeng.github.io/sdn-handbook/dpdk/queue.html
- RPS/RFS
- Understanding DPDK
- Intel 82599 10GbE Controllerで遊ぼう