一、介绍
本文主要梳理下进程,线程,协程的概念、区别以及使用场景的选择。
二、进程
我们知道,一切的软件都是跑在操作系统上,真正用来干活 (计算) 的是 CPU。早期的操作系统每个程序就是一个进程,知道一个程序运行完,才能进行下一个进程,就是 “单进程时代”。一切的程序只能串行发生。
早期的单进程操作系统,面临 2 个问题:
- 单一的执行流程,计算机只能一个任务一个任务处理。
- 进程阻塞所带来的 CPU 时间浪费。
那么能不能有多个进程来一起来执行多个任务呢?
后来操作系统就具有了最早的并发能力:多进程并发,当一个进程阻塞的时候,切换到另外等待执行的进程,这样就能尽量把 CPU 利用起来,CPU 就不浪费了。
为了更合理的利用 CPU 资源,内存划分为多块,不同进程使用各自的内存空间互不干扰,CPU 可以在多个进程之间切换执行,让 CPU 的利用率变高。
为了实现 CPU 在多个进程之间切换,需要保存进程的上下文(如程序计数器、栈等等),以便下次切换回来可以恢复执行。还需要一种调度算法,Linux 中采用了基于时间片和优先级的完全公平调度算法。
进程的上下文切换涉及到从【用户态】->【内核态】->【用户态】的过程,并且上下文中包含非常多的数据,如下图所示:
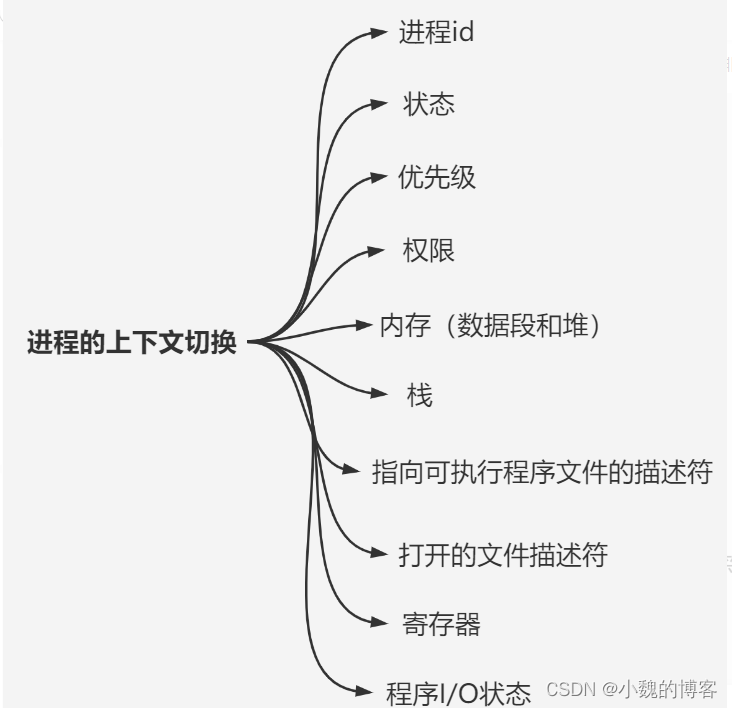
在多进程 / 多线程的操作系统中,就解决了阻塞的问题,因为一个进程阻塞 cpu 可以立刻切换到其他进程中去执行,而且调度 cpu 的算法可以保证在运行的进程都可以被分配到 cpu 的运行时间片。这样从宏观来看,似乎多个进程是在同时被运行。
但新的问题就又出现了,进程拥有太多的资源,进程的创建、切换、销毁,都会占用很长的时间,CPU 虽然利用起来了,但如果进程过多,CPU 有很大的一部分都被用来进行进程调度了。
怎么才能提高 CPU 的利用率呢?
三、线程
1、介绍
多进程的出现是为了解决 CPU 利用率的问题,那为什么还需要线程?答案是为了减少上下文切换时的开销。
进程在如下两个时间点可能会让出 CPU,进行 CPU 切换:
- 进程阻塞,如网络阻塞、代码层面的阻塞(锁、sleep等)、系统调用等
- 进程时间片用完,让出 CPU
而进程切换 CPU 时需要进行这两步:
- 切换页目录以使用新的地址空间
- 切换内核栈和硬件上下文
进程和线程在 Linux 中没有本质区别,他们最大的不同就是进程有自己独立的内存空间,而线程(同进程中)是共享内存空间。
在进程切换时需要转换内存地址空间,而线程切换没有这个动作,所以线程切换比进程切换代价更小。
- 为什么内存地址空间转换这么慢?Linux 实现中,每个进程的地址空间都是虚拟的,虚拟地址空间转换到物理地址空间需要查页表,这个查询是很慢的过程,因此会用一种叫做 TLB 的 cache 来加速,当进程切换后,TLB 也随之失效了,所以会变慢。
综上,线程是为了降低进程切换过程中的开销。
2、线程切换
从单线程应用到多线程应用带来的不仅仅是好处。也会带来开销。
当一个cpu从一个线程切换到另一个线程时,cpu需要保存当前线程的本地数据,程序当前的指针等,然后加载下一个等待执行的线程的本地数据,程序指针等。这种切换被称之为上下文切换。cpu从执行一个线程切换去执行另一个线程。
线程的上下文切换涉及到从【用户态】->【内核态】->【用户态】的过程,上下文中包含的数据虽然不像进程中的那么多,但整个过程也非常耗时,具体包含的数据如下图所示:
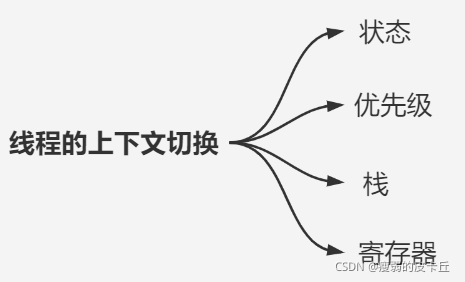
四、协程
1、介绍
很明显,CPU 调度切换的是进程和线程。尽管线程看起来很美好,但实际上多线程开发设计会变得更加复杂,要考虑很多同步竞争等问题,如锁、竞争冲突等。
多进程、多线程已经提高了系统的并发能力,但是在当今互联网高并发场景下,为每个任务都创建一个线程是不现实的,因为会消耗大量的内存 (进程虚拟内存会占用 4GB [32 位操作系统],而线程也要大约 4MB)。
大量的进程 / 线程出现了新的问题
- 系统线程会占用非常多的内存空间
- 过多的线程切换会占用大量的系统时间。
- 多线程开发涉及锁、竞争冲突等,开发复杂
当我们的程序是 IO 密集型时(如 web 服务器、网关等),为了追求高吞吐,有两种思路:
- 为每个请求开一个线程处理,为了降低线程的创建开销,可以使用线程池技术,理论上线程池越大,则吞吐越高,但线程池越大,CPU花在切换上的开销也越大。
-
使用异步非阻塞的开发模型,用一个进程或线程接收请求,然后通过 IO 多路复用让进程或线程不阻塞,省去上下文切换的开销
这两个方案,优缺点都很明显:方案1实现简单,但性能不高;方案2性能非常好,但实现起来复杂。
2、解决方案
有没有介于这两者之间的方案?既要简单,又要性能高,协程就解决了这个问题。
而协程刚好可以解决上述2个问题。
协程是用户视角的一种抽象,操作系统并没有协程的概念。
协程运行在线程之上,协程的主要思想是在用户态实现调度算法,用少量线程完成大量任务的调度。
协程需要解决线程遇到的几个问题:
- 内存占用要小,且创建开销要小
- 用户态的协程,可以设计的很小,可以达到 KB 级别。是线程的千分之一。
- 线程栈空间通常是MB级别, 协程栈空间最小KB级别。
- 减少上下文切换的开销
- 让可执行的线程尽量少,这样切换次数必然会少
- 让线程尽可能的处于运行状态,而不是阻塞让出时间片
- 多个协程多个协程绑定一个或者多个线程上
- 当一个协程执行完成后,可以选择主动让出,让另一个协程运行在当前线程之上(分时复用)。
- 即使有协程阻塞,该线程的其他协程也可以被 runtime 调度,转移到其他可运行的线程上。
- 多个协程多个协程绑定一个或者多个线程上
- 降低开发难度
- goroutine是golang中对协程的实现
- goroutine底层实现了少量线程干多事,减少切换时间等
- 程序员可以轻松创建协程,无需去关注底层性能优化的细节
相较进程和线程而言,协程的上下文切换则快了很多, 它只需在【用户态】即可完成上下文的切换,并且需要切换的上下文信息也较少

五、进程、线程、协程上下文切换开销
为什么 【用户态】->【内核态】->【用户态】这一过程比较耗时,耗资源呢?
我们知道,操作系统保持跟踪进程运行所需的所有状态信息,这种状态,也就是上下文。
进程的上下文包括许多信息,比如PC和寄存器文件的当前值,以及主存的内容。
在任何一个时刻,单处理器系统都只能执行一个进程的代码。当操作系统决定要把控制权从当前进程转移到某个新进程时,就会进行上下文切换,即保存当前进程的上下文、恢复新进程的上下文,然后将控制权传递到新进程。新进程就会从它上次停止的地方开始。
假设现在有两个并发的进程:shel进程和hello进程。最开始,只有 shell进程在运行,即等待命令行上的输人。当我们让它运行hello程序时, shell通过调用一个专门的函数,即系统调用,来执行我们的请求,系统调用会将控制权传递给操作系统。操作系统保存 shell进程的上下文,创建一个新的hello进程及其上下文,然后将控制权传给新的hello进程。hello进程终止后,操作系统恢复shll进程的上下文,并将控制权传回给它, shell进程会继续等待下一个命令行输入。
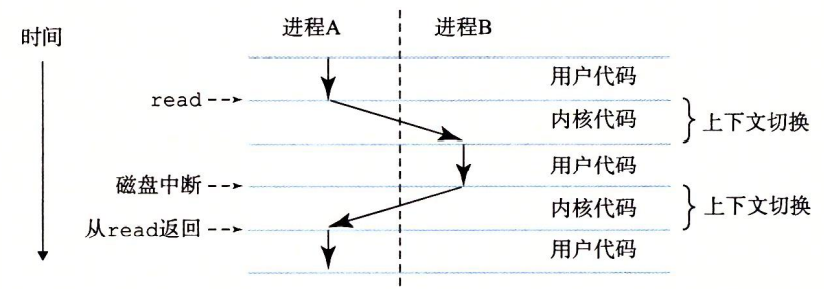
从上面这个实例我们可以得出结论:
(1)上一个进程的上下文信息还在内存和处理器当中,我们要保存这些信息的话,就必须陷入到内核态才可以。
(2)创建一个新的进程,以及它的上下文信息,并且将控制权交给这个新进程,这些都只有在内核态才能实现。
综上,我们可以得出结论,进程和线程的上下文切换相较于协程比较“耗时耗力”。
那么协程的上下文切换相较线程有哪些提升?
协程上下文切换只涉及CPU上下文切换,而所谓的CPU上下文切换是指少量寄存器(PC / SP / DX)的值修改,协程切换非常简单,就是把当前协程的 CPU 寄存器状态保存起来,然后将需要切换进来的协程的 CPU 寄存器状态加载的 CPU 寄存器上就 ok 了。而对比线程的上下文切换则需要涉及模式切换(从用户态切换到内核态)、以及 16 个寄存器、PC、SP…等寄存器的刷新;
线程栈空间通常是 2M, 协程栈空间最小 2K。
六、以下为ChatGPT的回答
协程(Coroutine)和线程(Thread)都是常见的并发编程技术。线程是操作系统进行调度的最小单位,而协程则是在应用程序内部进行调度的最小单位。在多线程并发编程中,线程之间的切换涉及到内核态和用户态之间的切换,会带来一定的开销。而在协程并发编程中,由于很多协程都运行在同一个线程内,因此协程之间的切换只涉及到用户态之间的切换,避免了内核态和用户态之间的频繁切换,从而提高了性能。
从底层角度来看,线程和协程之间的主要区别在于它们的调度方式和内存模型。在线程模型中,每个线程都有自己的线程栈和寄存器状态,由操作系统进行调度。线程之间的切换需要保存和恢复线程栈和寄存器状态,这会带来一定的开销。而在协程模型中,多个协程共享同一个线程栈和寄存器状态,由协程库进行调度。协程之间的切换只需要保存和恢复少量的状态信息,避免了线程切换的大量开销。
具体来说,在协程模型中,协程的状态可以通过一个状态机来表示。每个协程只有在遇到IO等需要等待的操作时才会主动让出CPU,转而让其他协程继续执行。当IO操作完成后,该协程会被唤醒并从上次挂起的状态恢复执行。这种调度方式可以避免线程切换的开销,并且允许多个协程在同一线程上进行并发执行,从而提高了性能。
总之,协程的快速切换和共享内存模型使得它在一些场景下比线程更加高效,但是也需要注意到协程并发编程可能存在一些潜在的问题,例如上下文切换和调度算法等方面的性能问题和错误处理等方面的编程难度问题。因此,在选择编程模型时需要根据具体场景进行权衡和选择。
七、总结
从单进程到多进程提高了 CPU 利用率;从进程到线程,降低了上下文切换的开销;从线程到协程,进一步降低了上下文切换的开销,使得高并发的服务可以使用简单的代码写出来
协程(协同程序):同一时间只能执行某个协程。开辟多个协程开销不大。协程适合对某任务进行分时处理。
线程:同一时间可以同时执行多个线程。开辟多条线程开销很大。线程适合多任务同时处理。
协程可以让同一个线程执行多个协程任务。降低了线程切换的开销。
虽然协程也切换,但是由于多个线程共享线程栈和寄存器,因此协程切换就不涉及到线程栈和寄存器的开销了,仅有协程本身一些状态的变更。
</article>