一、背景
最近遇到个现象,hubble-api-open组件过段时间会内容占满,从而被K8S强制重启。
让我困惑的是,已经设置了-XX:MaxRAMPercentage=75.0,我觉得留有了一定的空间,不应该会占满,所以想深究下原因。
-XX:MaxRAMPercentage是设置JVM的最大堆内存占虚机或pod(limits)的比例,默认为25.0。我设置的是75.0。
注意呦:是堆内存哦!不包含元空间,非堆这些,所以Java进程实际使用的内存可能是超过配置的limits的75%。
二、是否是配置没有起作用?如何验证?
要验证的话,其实也简单,看下JVM配置的最大堆内存是多少即可。
好在我们已经接入了prometheus,接入了Actuator,因此我们是可以看到配置的最大内存的指标的,检查如下:
- jvm_memory_max_bytes{area="nonheap",id="Code Cache",} 2.5165824E8
- jvm_memory_max_bytes{area="nonheap",id="Metaspace",} -1.0
- jvm_memory_max_bytes{area="nonheap",id="Compressed Class Space",} 1.073741824E9
- jvm_memory_max_bytes{area="heap",id="G1 Eden Space",} -1.0
- jvm_memory_max_bytes{area="heap",id="G1 Survivor Space",} -1.0
- jvm_memory_max_bytes{area="heap",id="G1 Old Gen",} 4.718592E9
上面的area="heap"的三个加起来就是配置的最大的堆内存,算一下:
4.718592E9 = 4.718592 乘以 10的9次方 = 4.718592 * 10^9 = 4718592000 byte = 4718592000 byte = 4608000 KB = 4500 MB = 4.395GB
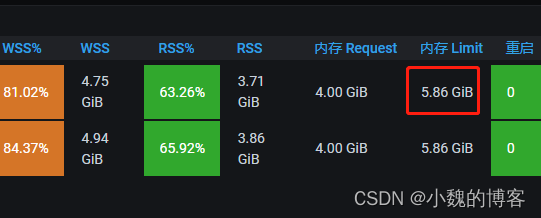
也就是配置的JVM允许使用的最大的堆内存是4.395GB,是不是75%呢?我们需要去看下limits的配置:可见是5.86GB
5.86*0.75 = 4.395GB,和我们从指标上看到的是一致的,说明配置生效了
三、为什么会OOM?
1、是否是非堆内存导致的?
答案:不是
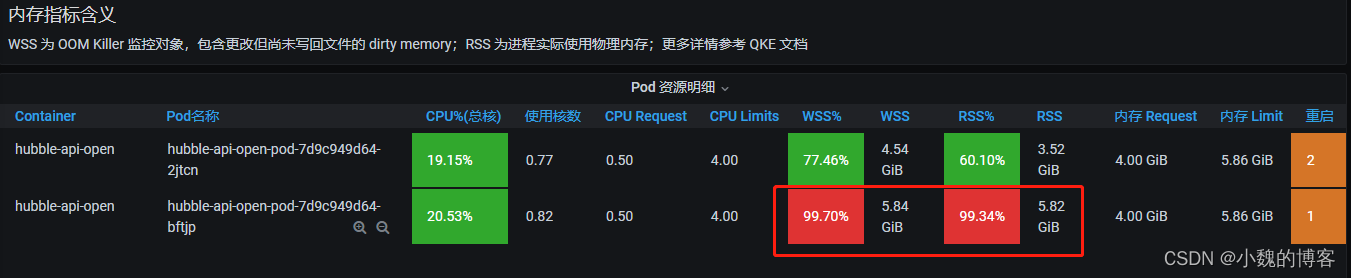
grafana看下当前RSS和WSS,可以看到已经快100%了:
但是我们看JVM进程实际使用的,其实并不高:
jvm_memory_used_bytes:表示JVM实际已经使用的内存
jvm_memory_committed_bytes:可供Java虚拟机使用的已提交的内存量
- committed是当前可使用的内存大小(包括已使用的),committed >= used。committed不足时jvm向系统申请
jvm_memory_max_bytes:表示最大可以申请的内存量
- committed <= max

再看下其它相关内存(这个内存也是动态变化的):
jvm_memory_committed_bytes:可供Java虚拟机使用的已提交的内存量
这理论上是从操作系统层面看到的Java进程占用的内存。
如下堆和非堆总计也就4.2GB左右(所以不是非堆导致),并没有达到Limits的97.49%

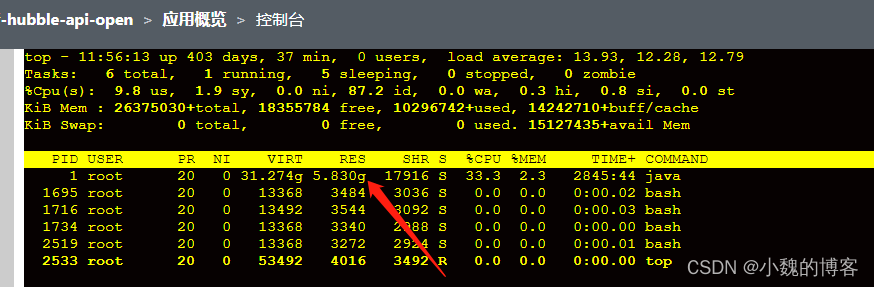
进入容器,用top命令查看,占了5.83g内存,明显还是要大于jvm_memory_committed_bytes,所以,java应该还有使用的没有通过指标列出来,这块需要找下
下面是不同内存区域最大可申请的内存量
jvm_memory_max_bytes:表示最大可以申请的内存量

本来我觉得JVM在TOP中使用的内存大小是按照JVM实际使用量计算,即按照jvm_memory_used_bytes,但是经过排查,其实是jvm_memory_committed_bytes + JVM其它内存(这块待研究)
从TOP命令看(即从操作系统层面看),确实是Java进程占用了所有的内存,所以java除了已提交的内存,一定还有其它的。
如果按照jvm_memory_committed_bytes来计算,那么差不多占了4.2GB左右,这个数值应该等于TOP中的RES,但是为什么差距那么大呢?
2、是不是因为线程占用的内存没有在prometheus指标中体现?
我觉得这个倒是有可能的,看了下线程相关的指标:
- jvm_threads_live 906.0
- tomcat_threads_current{name="http-nio-9507",} 200.0
可见JVM线程 + tomcat线程有差不多1000个了,假设每个1M的话,差不多占了1GB,所以这块严重怀疑。
这样算下来其实就差不多了,4.2GB + 1GB = 5.2GB
怎么验证呢?每个线程栈大小是多大呢?
通过dump命令拉取到某个时刻的线程数:879MB
而在jvm_memory_committed_bytes指标中并未看到类似大小的指标,所以我判断应该是没有在memory相关指标中有显示。
但是算上线程栈的话,假设5.2GB,和实际占用5.83还是差几百兆,因此应该还有一部分没有算上。
3、其它内存
待续……
四、JVM占用内存与操作系统层面看JVM占用内存
在JDK 8及之前,哪怕GC之后占用内存下降,得到的内存空间也仅仅是从Used转变为Committed,在JVM一侧看这些已经是空闲内存了,但在OS一侧看来,仍然是被JVM占用的状态。
从JDK 9起,加入了ShrinkHeapInSteps参数,或者说修复了以前的UseAggressiveHeapShrink参数的问题(https://bugs.openjdk.java.net/browse/JDK-8146436),让OS一侧能看到JVM主动释放的内存。
但这个行为必须是与具体收集器相关的,其他几款收集器的改进并不活跃,G1在这个时期有改动,让它在FullGC时顺带Decommit空闲内存回OS(https://bugs.openjdk.java.net/browse/JDK-8038423)。
不过,以上改进仍然是效果很差,因为G1是并发增量收集,FullGC是很罕见的,所以通常加了这个参数也不容易见到效果。
到了JDK 12,发布了JEP 346(https://openjdk.java.net/jeps/346),这个JEP的改进就是让G1能在正常的不产生FullGC的收集循环中,也能自动Decommit空闲内存回OS(通过G1PeriodicGCInterval参数),后来的Shenandoah收集器也共用了这部分代码。
到了JDK 13,ZGC默认就有Decommit行为,不需要额外参数了。
五、Java程序的占用内存构成
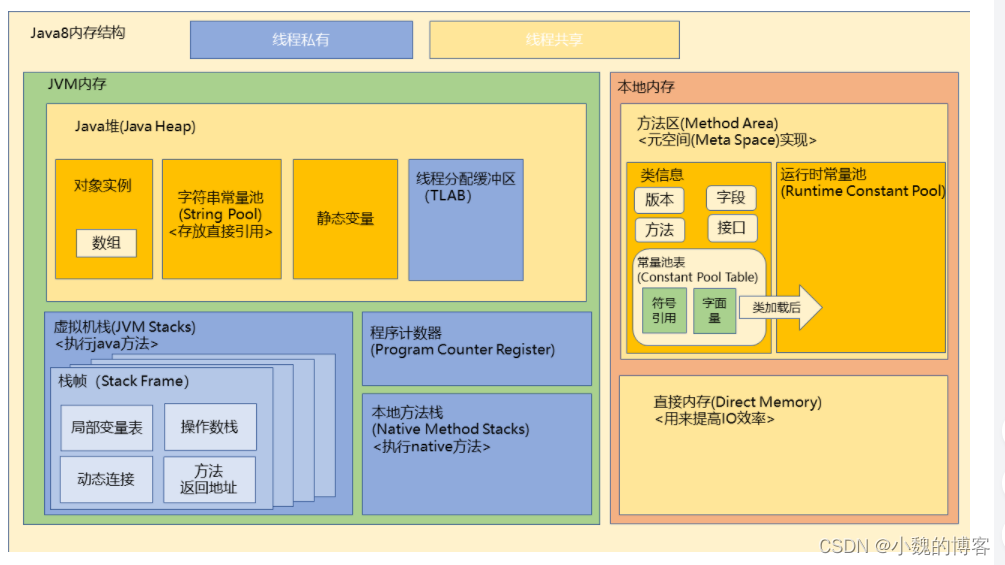
虚拟机内存与本地内存的区别
Java虚拟机在执行的时候会把管理的内存分配成不同的区域,这些区域被称为虚拟机内存,同时,对于虚拟机没有直接管理的物理内存,也有一定的利用,这些被利用却不在虚拟机内存数据区的内存,我们称它为本地内存,这两种内存有一定的区别:
JVM内存
- 受虚拟机内存大小的参数控制,当大小超过参数设置的大小时就会报OOM
本地内存
- 本地内存不受虚拟机内存参数的限制,只受物理内存容量的限制,虽然不受参数的限制,但是如果内存的占用超出物理内存的大小,同样也会报OOM
六、各个主要内存区域存放的数据
1、堆
java堆是JVM内存中最大的一块,由所有线程共享,是由垃圾收集器管理的内存区域。
2、虚拟机栈
虚拟机栈是线程私有的,随线程生灭。
由于一个线程默认分配1M空间,一个Java进程一般都有几百个线程,升至上千个线程,因此虚拟机栈一般是除了堆之外,最占用内存的区域。
另外,程序计数器是线程私有的,每个线程都已自己的程序计数器,所以,程序计数器的内容不用另外算,直接计算线程的内存即可。
3、元空间(Meta Space)
元空间类似于老版本的方法区。非堆区。
元空间一般占内存100MB左右,是堆,栈之外,最占用内存的区域。
元空间主要包含两部分数据:
- 类信息:或者说类的元信息。
- 类的元信息里面放置了类的基本信息,包括类的版本、字段、方法、接口以及常量池表
- 常量池表:存储了类在编译期间生成的字面量、符号引用
- 运行时常量池:主要存放在类加载后被解析的字面量与符号引用
方法区是所有线程共享的内存。
在java8以前是放在JVM内存中的,由永久代实现,受JVM内存大小参数的限制。
在java8中移除了永久代的内容,方法区由元空间(Meta Space)实现,并直接放到了本地内存中,不受JVM参数的限制(当然,如果物理内存被占满了,方法区也会报OOM),并且将原来放在方法区的字符串常量池和静态变量都转移到了Java堆中。
CCS(Compressed Class Space)
在Java8以前,有一个选项是UseCompressedOops。所谓OOPS是指“ordinary object pointers“,就是原始指针。Java Runtime可以用这个指针直接访问指针对应的内存,做相应的操作(比如发起GC时做copy and sweep)。
那么Compressed是啥意思?64bit的JVM出现后,OOPS的尺寸也变成了64bit,比之前的大了一倍。这会引入性能损耗——占的内存double了,并且同尺寸的CPU Cache要少存一倍的OOPS。
于是就有了UseCompressedOops这个选项。打开后,OOPS变成了32bit。但32bit的base是8,所以能引用的空间是32GB——这远大于目前经常给jvm进程内存分配的空间。
Compressed Class Space 是 Metaspace 的一部分,默认值是 1G。所以其实 Compressed Class Space 这个名字取得很误导,压缩的并不是 Klass,而是 Klass*。
compressed class space 空间的大小,是通过 -XX:CompressedClassSpaceSize 指定的。
如下占用了13MB左右空间,比较小。非堆区。
jvm_memory_committed_bytes{application="hubble-biz-host",area="nonheap",id="Compressed Class Space",} 1.3549568E7复制
4、代码缓存区
代码缓存区是一块存储编译后代码的区域。非堆区。
如下大致占了80MB左右的空间
jvm_memory_committed_bytes{application="hubble-biz-host",area="nonheap",id="Code Cache",} 7.9757312E7复制
5、本地方法栈(Native Method Stacks)
本地方法栈与虚拟机栈的作用是相似的,都会抛出OutOfMemoryError和StackOverFlowError,都是线程私有的,主要的区别在于:
- 虚拟机栈执行的是java方法
- 本地方法栈执行的是native方法
直接内存
执行native方法会产生直接内存。
直接内存位于本地内存,不属于JVM内存,但是也会在物理内存耗尽的时候报OOM。非堆区。
直接内存(DirectMemory)的容量大小可通过-XX:MaxDirectMemorySize参数来指定,如果不去指定,则默认与Java堆最大值(由-Xmx指定)一致。
这块占用的内存经过观察一般不高,如下可知只有大约4MB,如下:
jvm_buffer_memory_used_bytes{application="hubble-biz-host",id="direct",} 4169692.0复制
在jdk1.4中加入了NIO(New Input/Putput)类,引入了一种基于通道(channel)与缓冲区(buffer)的新IO方式,它可以使用native函数直接分配堆外内存,然后通过存储在java堆中的DirectByteBuffer对象作为这块内存的引用进行操作,这样可以在一些场景下大大提高IO性能,避免了在java堆和native堆来回复制数据。
七、其它可能产生内存的地方
八、内存归还
1、介绍
JVM 的垃圾回收,只是一个逻辑上的回收,回收的只是 JVM 申请的那一块逻辑堆区域,将数据标记为空闲之类的操作,不是调用 free 将内存归还给操作系统。
JVM 的自动内存管理,其实只是先向操作系统申请了一大块内存,然后自己在这块已申请的内存区域中进行“自动内存管理”。JAVA 中的对象在创建前,会先从这块申请的一大块内存中划分出一部分来给这个对象使用,在 GC 时也只是这个对象所处的内存区域数据清空,标记为空闲而已
2、为什么不把内存归还给操作系统?
JVM 还是会归还内存给操作系统的,只是因为这个代价比较大,所以不会轻易进行。而且不同垃圾回收器 的内存分配算法不同,归还内存的代价也不同。
比如在清除算法(sweep)中,是通过空闲链表(free-list)算法来分配内存的。简单的说就是将已申请的大块内存区域分为 N 个小区域,将这些区域同链表的结构组织起来,就像这样:
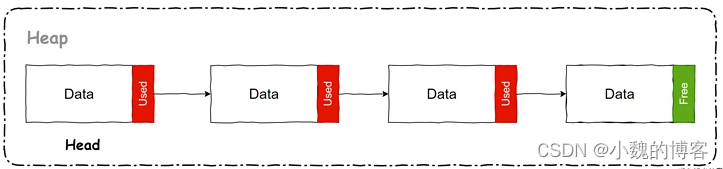
每个 data 区域可以容纳 N 个对象,那么当一次 GC 后,某些对象会被回收,可是此时这个 data 区域中还有其他存活的对象,如果想将整个 data 区域释放那是肯定不行的。
所以这个归还内存给操作系统的操作并没有那么简单,执行起来代价过高,JVM 自然不会在每次 GC 后都进行内存的归还。
3、怎么归还?
虽然代价高,但 JVM 还是提供了这个归还内存的功能。JVM 提供了-XX:MinHeapFreeRatio和-XX:MaxHeapFreeRatio 两个参数,用于配置这个归还策略。
- MinHeapFreeRatio:代表当空闲区域大小下降到该值时,会进行扩容,扩容的上限为
Xmx - MaxHeapFreeRatio:代表当空闲区域超过该值时,会进行“缩容”,缩容的下限为
Xms
不过虽然有这个归还的功能,不过因为这个代价比较昂贵,所以 JVM 在归还的时候,是线性递增归还的,并不是一次全部归还。
经过实测,这个归还内存的机制,在不同的垃圾回收器,甚至不同的 JDK 版本中还不一样!
参考: