参数翻译
可测试目标:
file_path 文件abc.file
#<physical drive number> #1为第一块物理磁盘[谨慎,别拿系统盘测试,一般用于准备投入的数据磁盘测试]
<partition_drive_letter>: 盘符c:
可用的选项:
-ag 以轮询方式将进程和CPU Group绑定,默认从Group 0开始,然后group 1,依次进行.[我的理解是超过64个逻辑核才会出现group1,而且Win2008, Vista, 2003 XP都不支持Processor Groups][80个逻辑CPU可能会出现不均衡Process Group问题,如80core时,group0可能有60core,group1有20core,系统调度变得好复杂]
关于Processor Groups请参考https://docs.microsoft.com/en-us/windows/desktop/procthread/processor-groups
-ag#,#[,#,...]> 高级版CPU与线程绑定参数.使用-n禁用默认关联.[这个参数真的是用在比较高级的数据库服务器上,比如超过64个核心,支持热插拔CPU等]
-a0,1,2 和-ag0,0,1,2是一样的.
-ag0,0,1,2,g1,0,1,2指定了组0和组1中的前三个核心。
-ag0,0,1,2和-ag1,0,1,2是一样婶的.
-b<size>[K|M|G] 块大小,单位bytes,默认为64K,单位可以是KMG
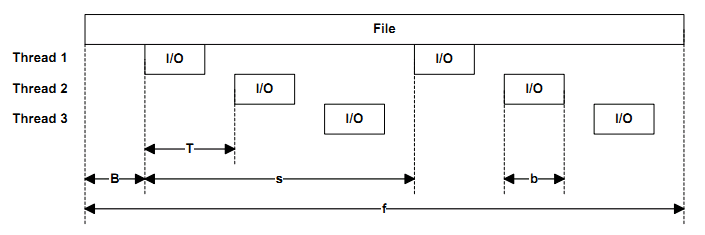
-B<offs>[K|M|G|b] 以字节为单位的基本目标偏移量.默认为0,不偏移.例如diskspd -b4K -B512b #1 ,这样可以躲开分区表,我没试过哦!
-c<size>[K|M|G|b] 创建文件的大小
-C<seconds> 冷却时间-测量完成后测试的持续时间.默认为0
-D<milliseconds> 捕获IOPs统计信息的时间间隔,默认1000ms.
-d<seconds> 测试持续时间,默认10s.
-f<size>[K|M|G|b] 目标大小,目标可以为文件,磁盘,分区.
-f<rst> 使用附加访问提示打开文件.一般启用软件缓存时才适用
-fr:文件标志随机访问提示.
-fs:文件标志顺序扫描提示.
-ft:文件属性临时提示.
-F<count> 每文件的线程总数,与-t冲突.
-g<bytes per ms> 调整每ms给定每个线程或每个目标的字节数.此选项与完成例程(-x)不兼容.[默认:不活动].[编程用]
-h 弃用,查看-Sh
-i<count> 每次发送的IO数量,一般和-j联用.[默认:不活动]
-j<milliseconds> 定义一次IO发送间隔<毫秒>;一般和-i联用[默认:不活动]
-I<priority> 设置IO优先级.1-非常低,2-低,3-普通(默认)
-l 使用大页面作为IO缓冲区
-L 记录IO延时的统计数据
-n 禁用默认的亲和力
-o<count> 队列深度.(1=同步I/O,除非使用-F指定了多个线程)[默认值=2]
-O<count> 允许未完成几个I/O的情况下继续发送请求,和-f一起使用(1=同步I/O)
-p 启动具有相同偏移量的并行顺序I/O操作(如果指定-r则忽略,只在-o2或更大时才有意义)
-P<count> 完成<count>个I/O操作后打印进度点(类似进度条,不是进度条),按每个线程分别计算.默认值为65536.
-r<align>[K|M|G|b] 随机I/O参数.一般单独使用-r,此时偏移量是块对齐的.带参数时,在每次I/O操作之前,将随机选择执行I/O操作的文件偏移量。所有偏移量都与-r参数指定的大小对齐。-r不能与-s参数一起使用,因为-s定义了下一个I/O操作的偏移量,在随机I/O的情况下,下一个操作的偏移量不是一个常量。如果指定-r和-s,则-r覆盖-s。
-R<text|xml> 输出格式,默认为文本格式.
-s[i]<size>[K|M|G|b] 不完全顺序操作,增加I/O偏移量,指定-r时会自动忽略本参数.一般使用-si.与-T,-p冲突.
-S[bhmruw] 控制缓存行为[diskspd默认:启用缓存],与后面的bhmruw参数随意组合.
-S 等同于-Su
-Sb 启用缓存,默认情况下即启用此参数.
-Sh 相当于suw,禁用软件/硬件缓存.常用选项.
-Sm 启用内存映射I/O
-Su 禁用软件缓存
-Sr 禁用本地缓存,启用远程sw缓存;仅对远程文件系统有效
-Sw 禁用硬件写缓存
-t<count> 每个目标的线程数(与-F冲突)[单文件下可以参考设置为CPU总核心数,未测试]
-F会让-t的区别 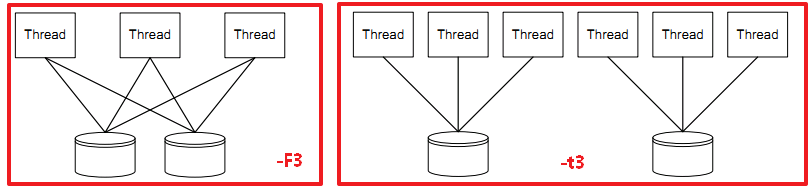
-T<offs>[K|M|G|b] 不同线程在相同目标上执行的I/O操作之间的偏移量,每个目标的线程数大于1时才有意义.默认为0.起始偏移量=基本文件偏移量+(线程数*偏移量)
-b,-B,-f,-T,-s之间的关系可参照下图:
-v 详细模式
-w<percentage> 写请求的百分比.-w0和-w等效,即为读测试.
-W<seconds> 预热时间-测量开始前测试持续时间[默认=5s]
-x 使用完成例程而不是I/O完成端口.[编程用][除非有特定的原因来探究组合模型中的差异,否则通常应该保持默认状态。]
-X<filepath> 使用XML文件配置工作负载。不能与其他参数一起使用。
-z[seed] 参数控制DISKSPD随机数发生器的初始状态,默认为0
-N<vni> [未翻译]
写缓存:
-Z 将缓冲区填充为0用于写测试.默认情况下,写缓冲区填充模式为(0, 1, 2, ..., 255, 0, 1, ...)
-Zr 每个IO设置随机缓冲区用于写测试-这将导致额外的开销用以创建随机内容.不能与没有-Zr运行的结果进行比较.
-Z<size>[K|M|G|b] 为写操作提供随机数据
-Z<size>[K|M|G|b],<file> 使用文件作为数据源来填充写源缓冲区。
同步:[不翻译了]
指定可以用于启动、结束、取消或发送磁盘spd通知的事件
事件追踪:[未翻译]
MT标注:对于顺序读写的偏移量,我实在没搞太明白,在此标注一下:
标注1:
测试用例:
使用已存在的testfile.dat文件,测试随机读性能:块大小4KB,每文件创建2个线程,队列深度32,持续时间10s,禁用软硬件缓存
diskspd.exe -b4K -t2 -o32 -d10 -Sh -r testfile.dat
(如果文件不存在可增加-c1G参数)
创建两个1GB的文件,将块大小设置为4KB,每个文件创建两个线程,亲化线程到cpu 0和1(每个文件都有与这两个cpu密切相关的线程)并运行读测试持续10秒:
diskspd.exe -c1G -b4K -t2 -d10 -a0,1 testfile1.dat testfile2.dat
题目:
- 使用2个线程和1个未完成的IO进行4KB顺序写入
- 使用2个线程和1个未完成的IO进行64KB顺序写入
- 8KB随机读取使用2个线程,1个未完成的IO
- 使用2个线程和1个未完成的IO进行128KB随机读取
diskspd.exe -c100G -t2 -si4K -b4K -d30 -L -o1 -w100 -D -h H:\testfile.dat > 4K_Sequential_Write_2Threads_1OutstandingIO.txt
diskspd.exe -t2 -si64K -b64K -d30 -L -o1 -w100 -D -h H:\testfile.dat > 64KB_Sequential_Write_2Threads_1OutstandingIO.txt
diskspd.exe -r -t2 -b8K -d30 -L -o1 -w0 -D -h H:\testfile.dat > 8KB_Random_Read_2Threads_1OutstandingIO.txt
diskspd.exe -r -t2 -b128K -d30 -L -o1 -w0 -D -h H:\testfile.dat > 128KB_Random_Read_2Threads_1OutstandingIO.txt
测试结果解读
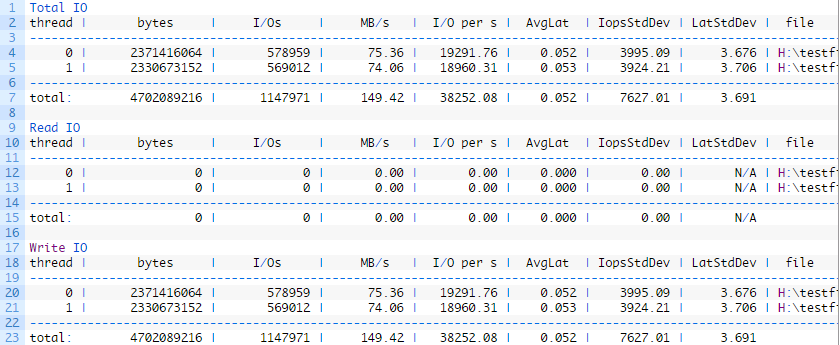
- thread:生成IO的线程的编号
- bytes:为测试传输的总字节数
- I/Os:为测试执行的IO操作总数
- MB/s:吞吐量,以MB /秒为单位
- I/O per s:每秒的IO操作数
- AvgLat:测试的所有IO操作的平均延迟
- IopsStdDev:每秒IO操作的标准偏差
- LatStdDev:测试遇到的延迟的标准偏差
- file:IO测试中使用的文件的路径
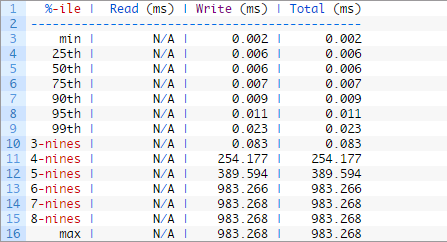
99.9%[3-nines]的write操作延时为0.083,还是比较好的。
Microsoft建议日志延迟应该在1-5ms到数据延迟应该在4-20ms之间。
测试命令举例
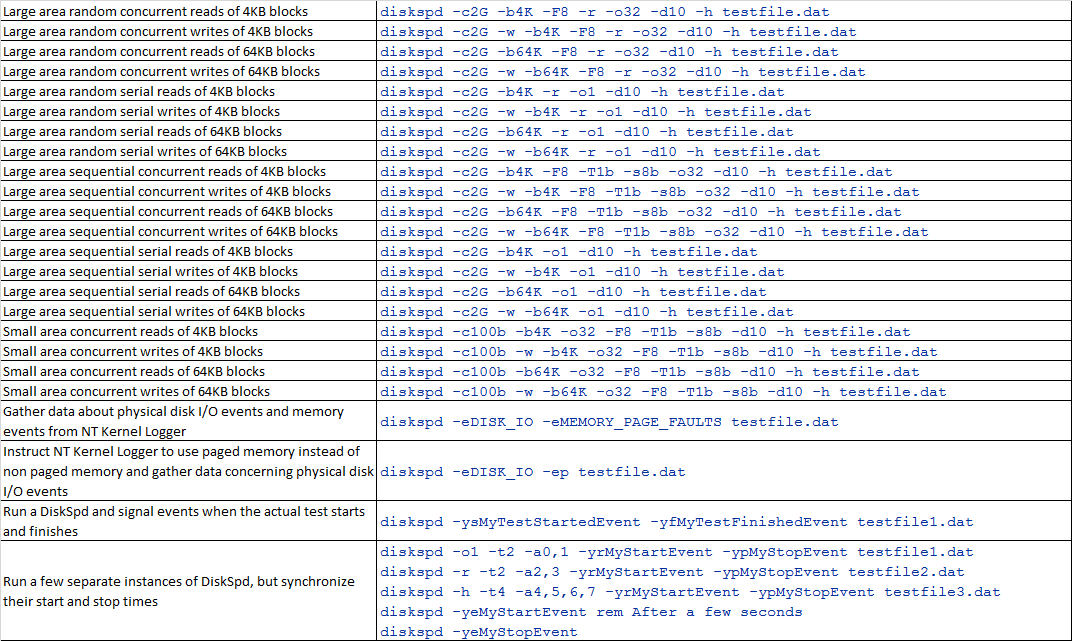
还有不明确的可以参考
https://github.com/Microsoft/diskspd
http://pugchallenge.org/downloads2016/681%20-%20diskspd_documentation.pdf
就为了翻这么一篇我至少详细阅读了60个英文网页。翻译真TM难,翻译成人话,更更更难。