https://zhuanlan.zhihu.com/p/585469720
最近这段时间一直在关注Bergamo和Zen 4c,但遗憾的是Genoa的发布会并没有提到太多的Bergamo细节。不过这并不妨碍我们借助已发布的硬件偷瞄它到底有几斤几两,提前解馋。
从目前各类官方/非官方的信息来看,Bergamo是AMD SP5平台的8CCD服务器SoC。

观察Zen 4的die shot可以发现,CCX区域有56%的面积是L2/L3的SRAM和相关控制结构,15%左右是巨大的FPU,其余核心面积只占不到30%。

这意味着在保留完整“Zen 4”微架构的前提下,将每个CCX的L3缓存砍半,并且CPU核心区域采用更高密度的物理设计(官方说法是核心区域也约为一半面积)即可在接近或略大于一个Zen 4 CCX的面积里塞下两倍的CPU核心数,用8个“大核”换取16个“小核”。
可以推测,Bergamo SoC的成本与售价远低于12 CCD的96核Genoa,只是略高于8 CCD的Genoa,但能在相似的面积内提供两倍的CPU核心数。对于一次购买成千上万片服务器SoC的互联网大厂、云厂而言,相近的成本下能获得如此多的核心数提升,显然是非常具有吸引力的。
那么问题就只剩下一个:核心数是翻倍了,但是性能究竟能提升几成呢?
服务器CPU核心数量较多时,DRAM带宽、缓存以及功耗都会成为非常宝贵的资源,每个核心能分配到的并不多。所以如果想要准确地模拟Genoa/Bergamo的环境进行多核性能评估,需要在控制功耗的同时严格控制缓存容量和内存带宽等变量才能较为准确做到,尤其是对于SPECint2017这类对缓存、内存较为敏感的测试。
幸运的是,AMD在桌面处理器里也实现了L3 QoS(或者说,忘记砍掉了?),因此我们现在就能通过调整QoS以及内存配置,通过7950X的16个核心大致模拟一个Zen 4c CCD出来。
经过这些配置,运行多核测试时CPU核心实际大约能分配到35-40W左右的功耗(取决于内存/IO负载高低),可以近似认为这样一个“模拟Zen 4c CCD”分配到的功耗与320-400W左右的8CCD服务器SoC上的一个CCD相同。内存带宽、缓存容量也大约相当于Bergamo 128核处理器满载时一个16核心CCD能分配到的资源。
对照组是同样PPT=65W的完整1CCD 8核心配置(32M L3缓存),开启SMT (8C16T)、单通道DDR5-5200B,用于模拟8CCD的64核Genoa处理器满载时单个CCD的性能。
同时加入13900K的8P16T/16E16T PL1=65W的测试作为对比。由于Intel桌面平台没有L3 QoS所以没有办法精确控制缓存容量,只能通过调整内存配置的方式尽量模拟相同的环境。再加上两个平台的uncore功耗特性也大不相同(13900K实际65W PL下核心大约能分到>50W功耗),Intel也没有打算拿胶水粘几个13900K去给服务器用,所以这一组对比仅供娱乐。
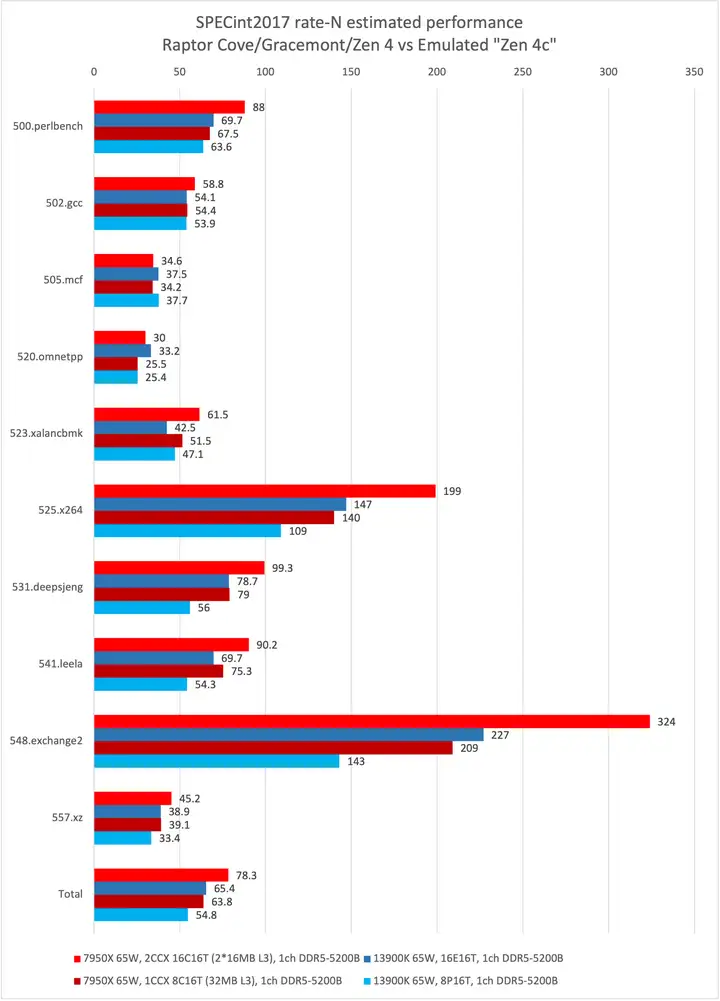
可以看出,在功耗与内存带宽受限的情况下,16核心“模拟Zen 4c”相比8核16线程的“常规Zen 4”可以获得大约23%的性能提升。这个提升幅度甚至略大于同样65W功耗下16线程Gracemont相比Golden Cove的性能提升(19%),那么Bergamo的意义就不言而喻了。
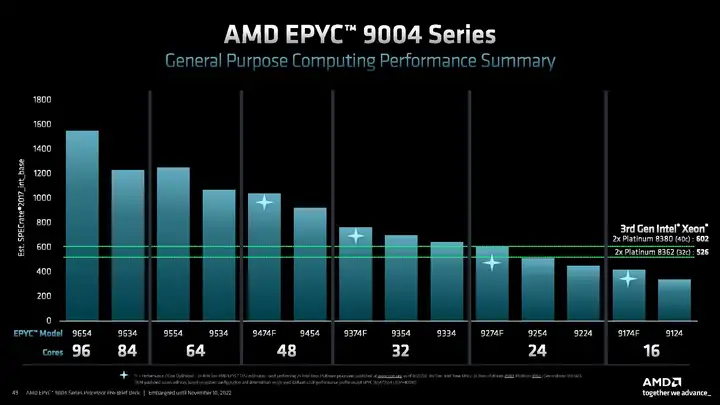
在Genoa的官方PPT里,96核EPYC 9654的SPECint2017 rate-N性能刚好比64核EPYC 9554高23%左右,所以可以认为Bergamo只用了略高于8CCD的成本和更少的128线程,即可达成接近12CCD 192线程Genoa的性能。
毫无疑问,考虑到桌面与服务器SoC的体质、总线拓扑以及缓存、内存延迟差异等多方面因素,以及Zen 4c不同工艺、不同物理设计带来的不同V/f曲线,这样一个“模拟实验”注定是不能做到100%精确的。不过AMD多次公开强调Zen 4/4c在ISA、微架构层面的相似性,因此针对SPECint2017这类测试,我们使用控制缓存和内存的手段依然能获得不少有用的信息,推测出大致的性能相对关系。
与Intel的Core/Atom双微架构并行不同的是,AMD选择了一条单一微架构,多个细分设计的道路。这不禁让我想起早些年高通855/865的"prime core"设计——针对不同的应用场景做出不同密度的物理设计,使用单一微架构达到一石二鸟的目的。事实证明,855与865都是高通相当成功的产品。AMD未来会不会也在某些产品里应用相似的设计思路呢?
目光回到数据中心,我们可以看到Bergamo很显然将会成为2023年非常有竞争力的细分领域数据中心处理器。但如今不仅AMD在尝试做出更高密度的数据中心SoC,Intel的Sierra Forest系列也即将到来,众多ARM SoC这些年来也一直在虎视眈眈。未来几年内,数据中心高密度SoC的竞争必然会愈演愈烈。胜负尚未揭晓,让我们拭目以待。