https://zhuanlan.zhihu.com/p/33411449复制
ARM big.LITTLE Processing with ARM Cortex-A15 & Cortex-A7
--Improving Energy Efficiency in High-Performance Mobile Platforms
big.LITTLE是ARM提出的异构处理架构,结合了大核高性能处理以及小核低功耗工作的优点,能够提高高性能移动平台的能源效率。本文是翻译ARM官方介绍big.LITTLE架构的文档,如有错误,请多多指出。
原作者:Peter Greenhalgh, ARM
发表时间:September 2011
翻译作者:He11o_Liu
转载请注明出处
原文下载地址:ARM big.LITTLE Processing with ARM Cortex-A15 & Cortex-A7
本文介绍了ARM big.LITTLE系统的基本原理和设计。本文设计的硬件有高性能Cortex-A15 MPCore处理器,高效能Cortex-A7 MPCore处理器,以及ARM CoreLink CCI-400 interconnect和相关的IP核。
随着以手机为代表的移动终端的快速发展,移动处理器处理器对于性能的要求前所未有的大。用户既需要移动终端能够完成高强度的任务,如网页浏览与游戏,也期望其能够有足够的续航来完成低强度的任务,如发短信,邮件以及听音乐。
在ARM的第一个big.LITTLE系统设计中,一个`big`的ARM Cortex-A15处理器与一个`LITTLE`的ARM Cortex-A7处理器配合使用,构建起一个既能够完成高强度任务,同时具有不错的效能的系统。实际运用中,ARM Cortex-A15和ARM Cortex-A7处理器通过CoreLink CCI-400内部总线进行连接,组成一个足以面对各种运用场景的灵活系统。
在big.LITTLE系统中,无论大小核处理器在架构上都是相同的。例如ARM Cortex-A15和ARM Cortex-A7都实现了完整的ARM v7A架构,包括虚拟化和大型物理地址扩展。 因此,所有的指令在Cortex-A15和Cortex-A7上运行都是“结构一致”(Architecturally consistent)相同的,除了两者性能差别导致的执行时间不同。
Cortex-A15和Cortex-A7特性集实现的定义也是类似的。 因此两个处理器都可以被配置为拥有一到四个核,并且都在处理器集群内部集成了一个l2级缓存。 另外,由于两个处理器都支持AMBA-4定义的片中总线,故可以使用CoreLink CCI-400内部总线进行连接。
Cortex-A15和Cortex-A7两者之间的差异主要体现在微架构(micro-architectures)中。
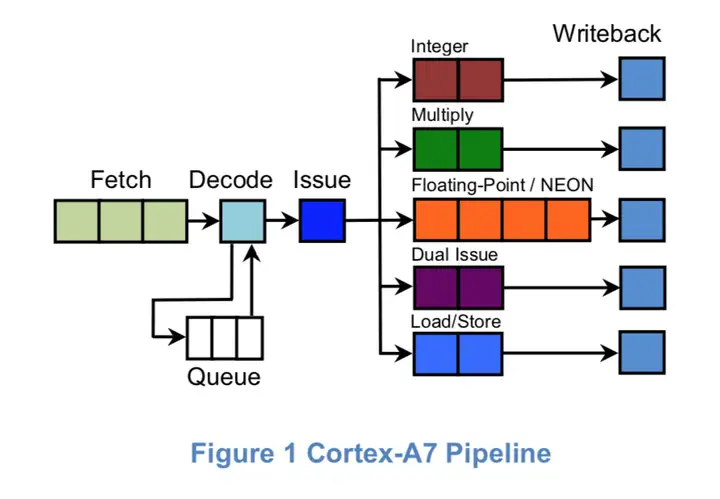
Cortex-A7是一个有序、非对称、双发射(超标量)处理器,其流水线长度在8-stages到10-stages之间。
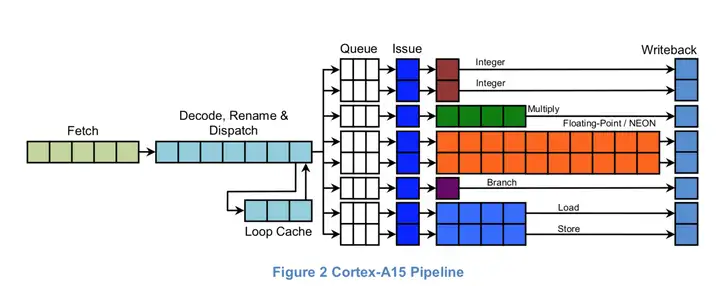
Cortex-A15是一个乱序、三发射(超标量)处理器,其流水线长度在15-stages到24-stages之间。
对于一条指令来说,执行其所消耗的能量有一部分是与其经历的流水线长度有关的。所以Cortex-A15和Cortex-A7之间的功耗差别很大程度与他们流水线长度有关。(当然,流水线越长,指令中可重叠的部分越多,CPU性能也越高。)
总的来说,Cortex-A15与Cortex-A7在微结构中采用了不同的倾向。Cortex-A15偏重性能,而Cortex-A7会牺牲性能来提高能源效率。这两种架构的l2级cache设计是这种折衷倾向的一个很好例子。通过在Cortex-A15和Cortex-A7之间共享一个l2级缓存,可以使两者进行互补。
Cortex-A15和Cortex-A7之间在性能和效能上的差异如下表所示:
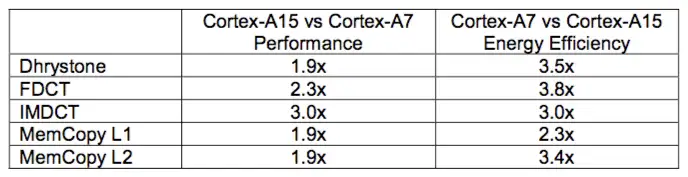
上表的第一列表示了从Cortex-A7到Cortex-A15的性能提升。第二列则表示了从Cortex-A15到Cortex-A7的效能提升。 上表中所有的测量都在相同设置的Cortex-A15和Cortex-A7处理器上完成,并使用相同的单元和RAM库。 所有在Cortex-A7上执行的代码都是为Cortex-A15编译的。
从上表可以看出 ,虽然Cortex-A7被标记为“LITTLE”处理器,但其性能上的表现依然非常不错。因此,相当可观数量的一些任务可以留在Cortex -A7上执行,而不用切换到Cortex-A15上执行。
big.LITTLE架构的另一个必须要考虑的问题是处理器间的系统该如何构建,才能完整发挥出big.LITTLE架构的优势。
其中最为关键的部分是利用CCI-400进行处理器间总线互连,它确保了Cortex-A15和Cortex-A7之间的完全一致性,同时也确保了与其他部件(如GPU)的IO一致性。同时兼顾 Cortex-A15与Cortex-A7之间的特性,主存访问以及系统的特征,我们可以找到一个最佳的方案。
big.LITTLE在A15与A7上面的实现的一个系统实例如下图所示:
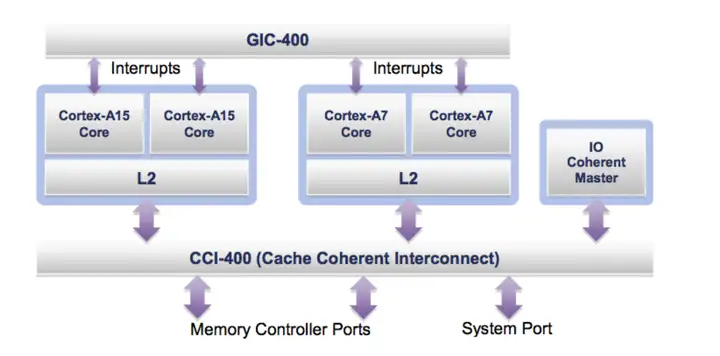
big.LITTLE架构的另一个重要的特性是Cortex-A15和Cortex-A7共享一个通用中断控制器(GIC-400)。多达480个中断可以分配给Cortex-A15和Cortex-A7。且可编程的中断控制器GIC-400允许在Cortex-A15或Cortex-A7集群中的任何核心之间迁移中断。
从跟踪和调试的角度来看,Cortex-A15和Cortex-A7都提供了跟踪解决方案,且两者都符合Debug v7.1体系结构。 通过CoreSight SoC,big.LITTLE提供了调试和跟踪的接口。
要考虑的最后一点是,虽然big.LITTLE架构并没有强制要求特定的组合,特定的环境, 但是考虑到big.LITTLE架构中任务迁移的复杂性,建议在Cortex-A15与Cortex-A7的集群中使用相同数量的内核。
big.LITTLE的任务迁移是在A15与A7之间,一个任务不会同时使用两个核心 。这种模式与动态电压和频率调节(DVFS)的思路类似。OS将会比较当前任务所需要的性能与当前使用处理簇平台的性能,并设置一个转换点(Operating point)。
例如,当前任务在Cortex-A7执行时,操作系统将会计算出当前平台处理的最高工作点(Operation Point)。 一旦Cortex-A7处于最高工作点,且还需要更多的资源,操作系统和应用程序将会移动到Cortex-A15上开始执行。
Cortex-A15-Cortex-A7 DVFS 曲线图见下:
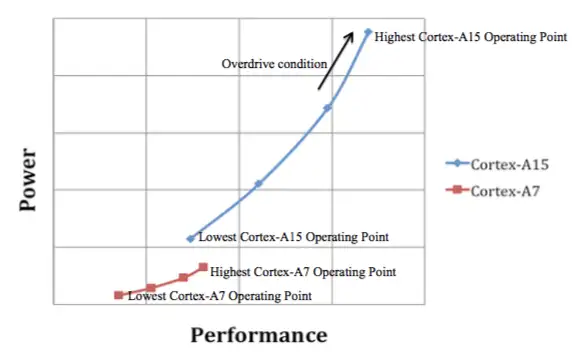
big.LITTLE系统的另一个需要严肃考虑的问题是在Cortex-A15集群和Cortex-A7集群之间迁移任务所需的时间。如果花费时间太长,有可能会得不偿失,反而没有直接在A7上运行快。因此,Cortex-A15-Cortex-A7系统设计成在1GHz下,迁移花费在 20,000个周期(20ms)以内。
任务迁移可以如此之快的原因之一是任务迁移涉及到的处理器状态空间是比较小的。 即将被关闭的处理器(出站处理器)必须保存所有 整数和高级SIMD 寄存器文件内容与 整个CP15配置状态内容。 即将恢复执行的处理器(入站处理器)将按照刚才保存的文件恢复所有状态。另外,由GIC-400控制的处理中中断也必须要迁移。整个保存-恢复的流程只用不到2000条指令就实现,这是因为两个处理器在结构上是相同的,故在入站和出站处理器之间可以建立一个一对一的状态寄存器映射。
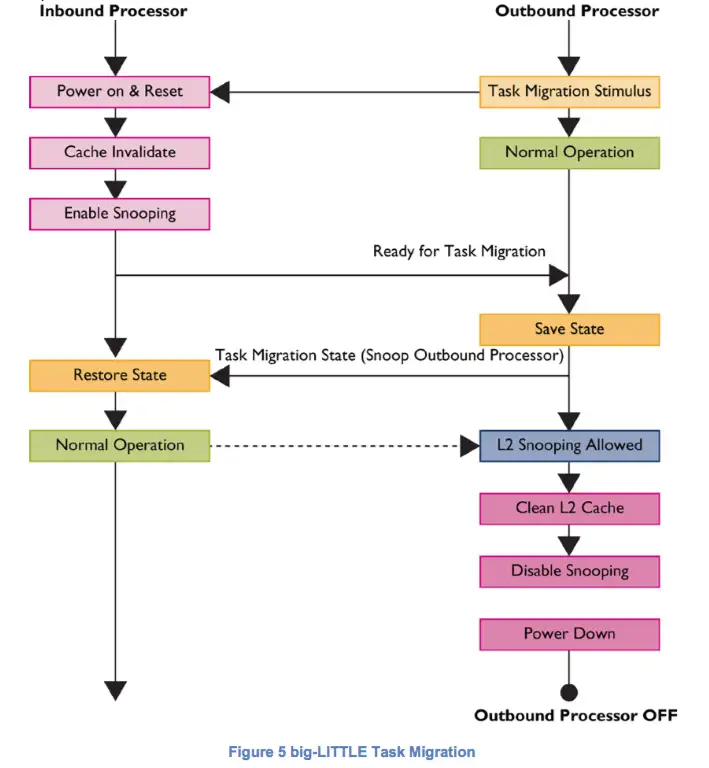
上图描述了入站和出站处理器之间的任务迁移的整个流程。一致性是能够实现快速迁移的保证,因为其能够使入站处理器直接从出站处理器的保存状态中进行恢复,而不用走主存。此外,由于出站处理器的二级缓存是一致的,因此可以在任务迁移之后保持在线,以改善入站处理器的高速缓存冷启动(warming time)时间。但是,由于出站处理器的已经分配的二级缓存不能再使用,其最终还是需要清理、关闭。
还应该注意的是,在任务迁移过程中当前正在执行的线程。对于该线程来说,运行暂停只是存在于关闭中断开始迁移的这一小段时间。
除了上面描述的任务迁移模型,另一个模型是允许Cortex-A15和Cortex-A7同时通电并同时执行代码。这个模型被称为big.LITTLE MP,它本质上是异构/异质的多核处理(Multi-Processing)。在这种模型下,Cortex-A7是一直在线的,只有当需要更多的计算资源时,Cortex-A15才上线并与Cortex-A7同时执行。
big.LITTLE MP最为引人注目的特点是其能使线程在最合适的处理资源上执行。对于那些计算密集的线程,且需要大量的处理性能,因为它们的输出是用户可见的,可以分配给Cortex-A15执行。 而对于那些大量处理I/O或者不需要立刻提供给用户(非时间敏感)的任务,都可以交给Cortex-A7执行。例如电子邮件的后台更新就是一个这样的例子。当用户在浏览其他网页时,用户期望电子邮件也会继续在后台更新,但是此时对于时效性要求就没有那么高。由于Cortex-A7更节能,消耗更少的电量,故该任务可以交给Cortex-A7来执行。
最后,作为一个完全一致的系统,为了维持一致性可能会导致很高的维持一致性开销。但是Cortex-A15,Cortex-A7和CCI-400的设计考虑了应对这种最糟糕的情况。 比如当Mali-T604 GPU连接到其中一个I/O 一致性 CCI-400端口时的情况。在这种情况下,为了维持一致性GPU会对Cortex-A15与Cortex-A7的变量进行监听,同时Cortex-A15与Cortex-A7也会相互进行监听。
作为big.LITTLE系统的一部分,ARM提供了一个运行在Cortex-A15,Cortex-A7,CCI-400和GIC-400架构上的软件转换器(切换器)。该转换器有两个目的:
ARM提供的转换器代码使得当今的操作系统都能够比较轻松地移植到big.LITTLE架构上来。然而,可能有少数大小核之间有差异的编程模型希望由操作系统来处理,而不是由转换器来处理(对于状态保存与恢复部分的代码)。
本白皮书描述了ARM的第一个big.LITTLE架构并描述了该架构的一个具体实现:由Cortex-A15和Cortex -A7组合而成的系统。该系统为移动高性能计算领域开辟了新的思路,新的可能。
现有架构只能利用一个处理器来应对各种高、低性能需求的应用与场景,而big.LITTLE可以动态适应应用以及场景,在需要更多计算资源是才开启A15核心。该架构相较于传统架构有更多的灵活性,既能够面对高性能要求的场景,又拥有不错的能效表现。
总的来说,big.LITTLE架构提供了在下一代移动平台上提升性能同时兼顾续航,延长电池寿命的思路。