
之前在学习ARM的SIMD加速时学习到关系矩阵计算优化的部分,所以现在想来整理自己在计算人脸相似度计算的时候是如何进行优化的,以及与openblas的计算性能优化的比较。
首先原理我就不多做介绍了,大致就是一个向量1 x n和矩阵n x m相乘,最后得到然后计算得到的1 x m的结果,优化的原理跟向量矩阵乘法的优化类似,并比较计算最大值,我这里使用的是余弦距离,公式如下:
���(�,�)=�⋅�|�|⋅|�|=∑�=1���⋅��∑�=1���2⋅∑�=1���2
基本的优化:1)分母中 yi2 的值可提前计算,使用空间换时间,在计算之前提前计算好;2)x xi2 一般维度比较少,是一个vector * vector,simd优化空间不大,所以这里也不研究讨论,只优化x * y。
主要的优化方向
为了便于理解这里定义输入的向量大小是N,也就是人脸特征大小,M是代查询的人脸库的数量,对应的矩阵大小就是N x M,代码中使用num_input代表N,num_output代表M, bottom代表输入向量,feature代表人脸库
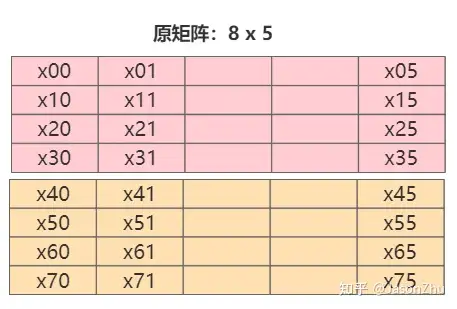
正常情况下的向量与矩阵的运算,就是两层for循环,矩阵存储一列代表一个人脸特征,大小是nums_input
for (int i = 0; i < nums_output; i++) {
for (int j = 0; j < nums_input; j++) {
// 行优先遍历
res[i] += features[i * nums_input + j] + bottom[j];
}
} 复制正常分析数据读取的顺序以及方式,存储方式如下,一行代表的是每个人脸特征,按行遍历,内层循环,每次计算与库中一个人脸的距离。
simd是可以同时计算多个变量,在这里指的是一次计算4个人脸的特征,伪代码如下:最基础的版本
for (int i = 0; i < num_output / 4; i++) {
for (int j = 0; j < num_input; j++) {
// simd计算,每次访问四列的相同位置,
// 第0行第一个位置x00,第1行第一个位置x10,第2行第一个位置x20,第三行第一个位置x30
res[i] += features[(i + 0) * num_input + j] * bottom[j];
res[i + 1] += features[(i + 1) * num_input + j] * bottom[j];
res[i + 2] += features[(i + 2) * num_input + j] * bottom[j];
res[i + 3] += features[(i + 3)* num_input + j] * bottom[j];
}
} 复制
分析:每次访问时都是列优先访问,如遍历如下所示矩阵,按列优先访问x00, x10, x20,x30,每次跨度非常大,访问数据地址不连续,由于cache块的大小有限,不能一次加载所有的数据,如果nums_input太大的话,会出现大量的cache miss。
所以可以先对数据进行重排,也可称为是pack,pack我个人理解是将需要进行simd的数据,相邻的单元放到一起,这样内存加载到cache时,数据是相邻的,充分利用数据总线带宽,减少内存访问。
数据存储方式(M / pack) * N * (pack), pack这个数量跟微处理器架构以及指令集有关,比如说有的ARM的simd的指令集和微架构的支持128位,那么如果不做量化,就是128 / f32 = 4,如果使用半精度16,那就是128 / f16 = 8,pack的大小是8,在比如说x86架构的AVX指令集支持256,那就是256 / f32 = 8,pack大小就是8。我这里使用的ARM64位的支持ARM8指令集,使用的是128位的寄存器,所以是4。
数据重排pack的代码:
void DataPack(float* feature, float* feature_pack,
int num_output, int num_input, int pack_nums) {
// 一行一个人脸特征,num_input
for (int q = 0; q + (pack_nums - 1) < num_output; q += pack_nums) {
float* f0 = feature + q * num_input;
float* g0 = feature_pack + q * num_input;
for (int p = 0; p < num_input; p++) {
for (int j = 0; j < pack_nums; j++) {
// x00 x10 x20 x30
// x01 x11 x21 x31
*g0++ = *(f0 + j * num_input + p);
}
}
}
}复制转换的流程图如下,右边是pack的结果
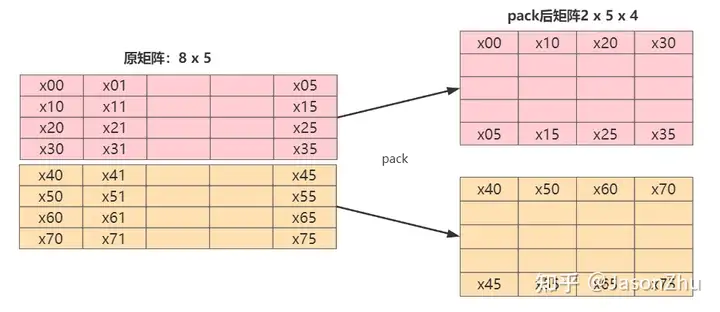
实际就是将先将矩阵分块,每块是 pack x num_input 然后转置num_input x pack,改成行优先访问,现有访问顺序x00, x10, x20, x30,访问地址连续,充分利用数据总线带宽。
PS:如果说边界值不能被4整除,为了后续的计算方便,需要进行padding,我这里使用人脸库中最后一个人脸的特征进行padding,这样在最后计算最近相似距离时不需要进行任何处理。
arm下可使用neon加速指令集,x86架构下可使用avx/sse指令集
以neon指令为例,简化代码版
for (int i = 0; i < feat_nums; i += pack_nums) {
float* g0 = features + i * feat_size;
float32x4_t _sum0 = vdupq_n_f32(0.f); // 保存计算res[0],res[1],res[2],res[3]结果
for (int j = 0; j < feat_size; j++) {
float32x4_t q0 = vdupq_n_f32(bottom[j]); //加载输入数据b[0]
float32x4_t m0 = vld1q_f32(g0); // 加载g[0][0],g[1][0],g[2][0],g[3][0]
_sum0 = vmlaq_f32(_sum0, q0, m0); // 乘加计算
g0 += 4;
}
vst1q_f32(res + i, _sum0);
}复制总的来说,就是i从0遍历到nums_input,每次计算 x0i, x1i, x2i, x3i 和 bi 的乘积并累加到 res0, res1, res2, res3 上
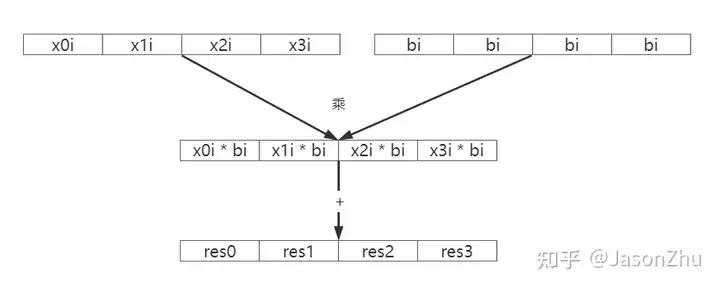
内层循环遍历结束后得到pack_nums(4)个人脸的相似度距离计算的结果。
循环展开是指通过将for循环中的代码,多复制几行,减少循环的次数,让每次循环执行更多的代码,我也找到了很多解释为什么会有优化效果:
并行编程方法与优化实践书:使用循环展开技术,以使用更多的寄存器,来解除数据依赖,填充浮点计算流水线
网上的说法:
第一,减少了分支预测失败的可能性。
第二,增加了循环体内语句并发执行的可能性,当然,这需要循环体内各语句不存在数据相关性。
关于并行编程方法与优化实践书中,我的个人理解是把不用的寄存器调用起来,当计算单元计算时,可以同时执行寄存器加载数据的指令,更好的使用指令流水线,,下面只展示循环展开的部分,当然还需要注意不能被4整除的边界处理和最后累加_sum0,_sum1,_sum2,_sum3的值
for (int j = 0; j + 3 < feat_size; j += 4) {
// unroll
float32x4_t q0 = vdupq_n_f32(bottom[j]);
float32x4_t m0 = vld1q_f32(g0);
float32x4_t q1 = vdupq_n_f32(bottom[j + 1]);
float32x4_t m1 = vld1q_f32(g0 + 4);
float32x4_t q2 = vdupq_n_f32(bottom[j + 2]);
float32x4_t m2 = vld1q_f32(g0 + 8);
float32x4_t q3 = vdupq_n_f32(bottom[j + 3]);
float32x4_t m3 = vld1q_f32(g0 + 12);
_sum0 = vmlaq_f32(_sum0, q0, m0);
_sum1 = vmlaq_f32(_sum1, q1, m1);
_sum2 = vmlaq_f32(_sum2, q2, m2);
_sum3 = vmlaq_f32(_sum3, q3, m3);
g0 += 16;
}
// 寄存器累加
_sum0 = vaddq_f32(_sum0, _sum1);
_sum2 = vaddq_f32(_sum2, _sum3);
_sum0 = vaddq_f32(_sum0, _sum2);
vst1q_f32(res + i, _sum0);复制ps:边界处理的代码我没有贴出来,其实就是for循环剩余的不能4个一起pack的数据。
其实关于这部分的内容,我个人理解就是使用多个CPU核心去优化代码,上面的simd代码我使用的一个cpu去跑,那么如果我使用多个CPU核计算,每个CPU核计算一个pack块的结果不就行了,反正他们之前没有数据依赖。
代码也简单,只要在外层训练如下命令就行,4代表使用四个CPU核心,可自行修改,如果想更深入了解openmp的可参考OpenMP并行开发(C++)
#pragma omp parallel for num_threads(4)
for (int i = 0; i < feat_nums; i += pack_nums) {
//每个pack块的计算
}复制OpenBlas中的cblas_sgemv的相关参数介绍
cblas_sgemm(layout, transA, transB, M, N, K, alpha, A, LDA, B, LDB, beta, C, LDC);复制// feat_nums 行
// feat_size 列
// CblasRowMajor 行主序
// CblasNoTrans 不需要转置
cblas_sgemv(CblasRowMajor, CblasNoTrans, feat_nums, feat_size, 1.0, features, feat_size, bottom, 1, 0.0, res, 1);复制说明:
对比部分分为单核和4核,c++编译使用参数如下,使用O3的编译器优化,这里只使用了neon的intrinsic代码,没有使用assembly代码,等我想明白了,后面看看能不能用assembly优化
-O3 -mcpu=cortex-a53 -fopenmp -lpthread -lopenblas复制性能分析
使用如下方式测试芯片的实际极限的GFLOPS,测试之后结果是 9.32GFLOPS
数据大小2^15 x 128,这个大小基本上可以证明优化有效性,当然2^13, 2^14,2^16也是可以的,基本上都差不多,将原始进行归一化,计算加速比,单核效果
| 类型 | 时间 | GFLOPS | 加速比 |
|---|---|---|---|
| 原始 | 40.6741 ms | 0.205541 | 1x |
| Openblas-1核 | 18.1682 ms | 0.459087 | 2.23x |
| 数据重排+SIMD | 7.77417 ms | 1.07619 | 5.23x |
| 数据重排+SIMD+循环展开 | 6.40089 ms | 1.30542 | 6.35x |
其实这部分测试也不是很准确,因为我这里在计算的时候数据重排不累加在计算时间上,但是数据重排完全可以在矩阵向量乘法计算之前做,感觉Openblas的计算时间应该是包含了数据pack,也有可能是别的原因。
4核结果
| 类型 | 时间 | GFLOPS | 加速比 |
|---|---|---|---|
| 原始 | 40.6741 ms | 0.205541 | 1x |
| Openblas | 5.88533 ms | 0.459087 | 6.91x |
| Openmp+数据重排+SIMD+循环展开 | 3.55032 ms | 2.35354 | 11.45x |
使用SIMD和一些优化手段确实可以实现提升速度的效果,但是跟实际的计算峰值还有很大的差距,还需要进一步优化,路漫漫其修远兮,吾将上下而求索~