ARMv8架构
文章目录
参考文档
ARMv8 架构参考手册(称为 ARM ARM)全面描述了 ARMv8 指令集架构、程序员模型、系统寄存器、调试功能和内存模型。它形成了一个详细的规范,ARM处理器的所有实现都必须遵守该规范。
-
1149.1-2001 - IEEE Standard Test Access Port and Boundary Scan Architecture
-
ARM® Architecture Reference Manual - ARMv8, for ARMv8-A architecture profile (ARM DDI0487)
-
ARM® Cortex®-A Series Programmer’s Guide for ARMv7-A (DEN 0013)
-
ARM® Cortex®-A53 MPCore Processor Technical Reference Manual (DDI 0500)
-
ARM® Cortex®-A57 MPCore Processor Technical Reference Manual (DDI 0488)
-
ARM® Generic Interrupt Controller Architecture Specification (ARM IHI 0048)
ARMv8架构的概述
ARMv8架构包含32位和64位执行状态,其引入了使用 64 位宽寄存器执行执行的功能,并且提供了向后兼容性机制,使现有的 ARMv7 软件能够执行。
- AArch64 :ARMv8中64位的执行状态。
- AArch32:ARMv8中32位的执行状态,与ARMv7几乎相同。
在GNU和Linux的文档中(除了Redhat和Fedora外),有时会将AArch64称为ARM64。
Cortex-A 系列处理器现在包括在 ARMv8-A 和 ARMv7-A 中实现:
- Cortex-A5, Cortex-A7, Cortex-A8, Cortex-A9, Cortex-A15以及Cortex-A17处理器全部由 ARMv7-A 架构实现。
- Cortex-A53,Cortex-A57 和Cortex-A73处理器由 ARMv8-A 架构实现。
ARMv8 处理器仍然支持为 ARMv7-A 处理器编写的软件(有一些例外)。这意味着,例如,为 ARMv7 Cortex-A 系列处理器编写的 32 位代码也可运行在 ARMv8 处理器(如 Cortex-A57)上。但是,仅当 ARMv8 处理器处于 AArch32 执行状态时,代码才会运行。
此外,A64 的64 位指令集不能在 ARMv7 处理器上运行,而只能在 ARMv8 处理器上运行。
从32位到64位的变化The changes from 32 bits to 64 bits
64位的处理器其性能上有很大的提升,其中包括以下改变:
1,Larger register pool(更大的寄存器池)
A64 指令集提供了一些显著的性能优势,其中包括一个更大的寄存器池。A64具有31个64bits通用寄存器和ARM Architecture Procedure Call Standard (AAPCS) 提供了性能上的加速,当用户在函数调用中需要传递四个以上参数(需要四个以上寄存器)时,在ARMv7中可能要使用栈,而在AArch64中,最多可以在寄存器中传递八个参数,因此可以增加性能,减少栈的使用。
2,Wider integer registers(具有更宽的整数寄存器)
更宽的整数寄存器使对 64 位数据运行的代码能够更高效地工作。 32 位处理器可能需要多个操作才能对 64 位数据执行算术运算。64 位处理器可能能够在单个操作中执行相同的任务,速度通常和以同一处理器执行 32 位操作相同。因此,执行许多 64 位大小操作的代码速度明显更快。
3,Larger virtual address spac(更大的虚拟地址空间)
64 位操作使应用程序能够使用更大的虚拟地址空间。虽然大型物理地址扩展 (Large Physical Address Extension,LPAE) 将 32 位处理器的物理地址空间扩展到 40 位,但它不会扩展虚拟地址空间。这意味着即使使用 LPAE,单个应用程序也仅限于 32 位 (4GB) 地址空间。这是因为此地址空间中的某些空间是为操作系统保留的。
较大的虚拟地址空间还支持内存映射较大的文件。这是将文件内容映射到线程的内存映射。即使物理 RAM 可能不够大,无法包含整个文件,也可能发生这种情况。
32位地址空间
作为32位的微处理器,ARM体系结构所支持的最大寻址空间为4GB(232字节), 可将该地址空间看作是大小为 232 个字节(8bit),这些字节的单元地址是一个无符号的32位数值,其取值范围为0~232-1。ARM地址空间也可以看作是230个32位的字(1 word = 4 bytes)单元。这些字单元的地址可以被4整除,也就是说该地址的低两位为00。地址为A的字数据,包括地址为A,A+1,A+2,A+3这4个字节单元的内容。
每执行一条指令,当前指令计数器加4个字节。
4,Larger physical address space(更大的物理地址空间)
在 32 位体系结构上运行的软件可能需要在执行时映射内存中的一些数据进行输入输出。具有更大的地址空间(使用 64 位指针)可避免此问题。
但是,使用 64 位指针确实会产生一些成本:同一段代码通常比使用 32 位指针使用更多的内存。
每个指针都存储在内存中,需要8个字节而不是4个字节。这听起来可能微不足道,但可能会造成重大负担。此外,与64 位相关的内存空间使用量的增加,可能会导致缓存中命中(hit)率下降,这反过来又会降低性能。
- 64-bit pointers: 8 bytes
- 32-bit pointers: 4 bytes
ARMv8-A 架构
ARM架构可以追溯到1985年,自早期的ARM内核以来,它已经得到了巨大的发展,在每一步都增加了特性和功能。
ARMv4 and earlier
这些早期的处理器仅使用 ARM 32 位指令集。
ARMv4T
ARMv4T 架构将 Thumb 16 位指令集添加到 ARM 32 位指令集中。这是第一个广泛许可的架构。它由ARM7TDMI®和ARM9TDMI®处理器实现。
ARMv5TE
ARMv5TE 架构为 DSP 类型操作、饱和算术以及 ARM 和 Thumb 互通增加了改进。ARM926EJ-S® 实现了这种架构。
ARMv6
ARMv6 进行了多项增强,包括对未对齐内存访问的支持、对内存体系结构的重大更改以及对多处理器的支持。此外,还包括对 32 位寄存器中的字节或半字操作的 SIMD 操作的一些支持。ARM1136JF-S® 实现了这种架构。ARMv6架构还提供了一些可选的扩展,特别是Thumb-2和安全扩展(TrustZone®)。 Thumb-2 将 Thumb 扩展为混合长度的 16 位和 32 位指令集。
ARMv7-A
ARMv7-A 体系结构强制使用 Thumb-2 扩展,并添加了高级 SIMD 扩展 (NEON)。在 ARMv7 之前,所有内核都遵循基本相同的架构或功能集。为了帮助解决越来越多的不同应用,ARM 引入了一组架构配置:
- ARMv7-A提供了支持Linux等平台操作系统所需的所有功能
- ARMv7-R 提供可预测的实时高性能。
- ARMv7-M 面向深度嵌入式微控制器。 ARMv6 体系结构中还添加了 M 配置,以启用旧体系结构的功能。ARMv6M 配置由低功耗的低成本微处理器使用。
ARMv8-A
ARMv8 体系结构包括 32 位执行和 64 位执行。它引入了使用 64 位宽寄存器,同时保持了与现有 ARMv7 软件的向后兼容性。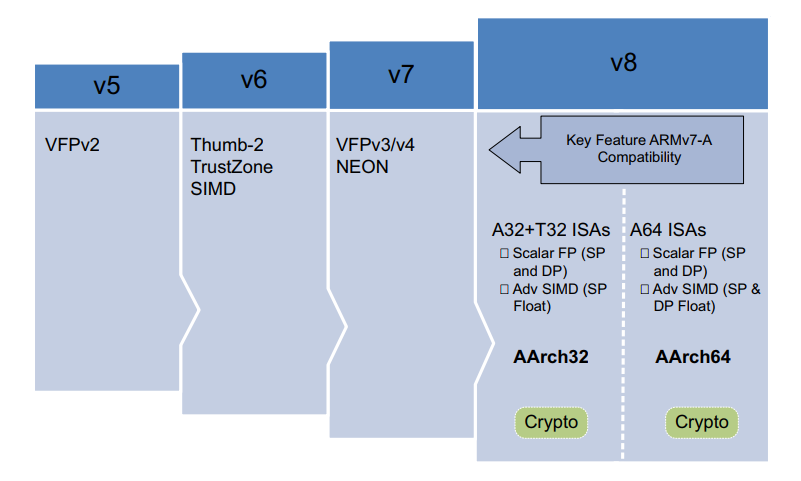
ARMv8-A 架构引入了许多更改,从而可以设计出性能更高的处理器实现:
较大的物理地址
这使处理器能够访问超过 4GB 的物理内存。
64 位虚拟寻址
这允许超过 4GB 限制的虚拟内存。这对于使用内存映射文件 I/O 或稀疏寻址的现代桌面和服务器软件非常重要。
自动事件信号
这可实现高能效、高性能的自旋锁。
更大的寄存器文件
31 个 64 位通用寄存器可提高性能并减少堆栈使用。
高效的 64 位立即数生成
对文本池的需求较少。
较大的 PC 相对寻址范围
一个 +/-4GB 的寻址范围,可在共享库和位置独立的可执行文件中实现高效的数据寻址。
额外的 16KB 和 64KB 转换粒度
这降低了Translation Lookaside Buffer (TLB)的未命中率和页面浏览深度。
新的异常模型
这降低了操作系统和虚拟机管理程序软件的复杂性。
高效的缓存管理
用户空间缓存操作可提高动态代码生成效率。使用数据缓存零指令清除快速数据缓存(DC)。
硬件加速加密
提供 3× 到 10×的软件加密性能提升。这对于小粒度解密和加密非常有用,这些小颗粒解密和加密太小而无法有效地装载到硬件加速器,例如https。
Load-Acquire,Store-Release 指令
专为 C++11、C11、Java 内存模型而设计。它们通过消除显式内存屏障指令来提高线程安全代码的性能。
NEON 双精度浮点高级 SIMD
这使得 SIMD 矢量化能够应用于更广泛的算法集,例如科学计算、高性能计算 (High Performance Computing,HPC) 和超级计算机。
ARMv8-A 处理器:A53,A57和A73
A73:
A73所有内核共享一个公共 L2 缓存,并且每个内核对所有参数具有相同的配置。
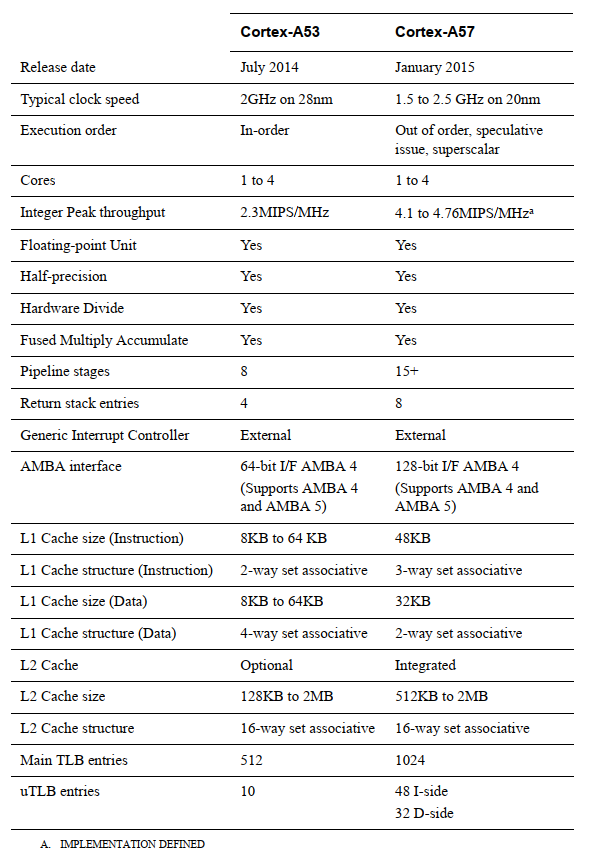
Cortex-A53 处理器
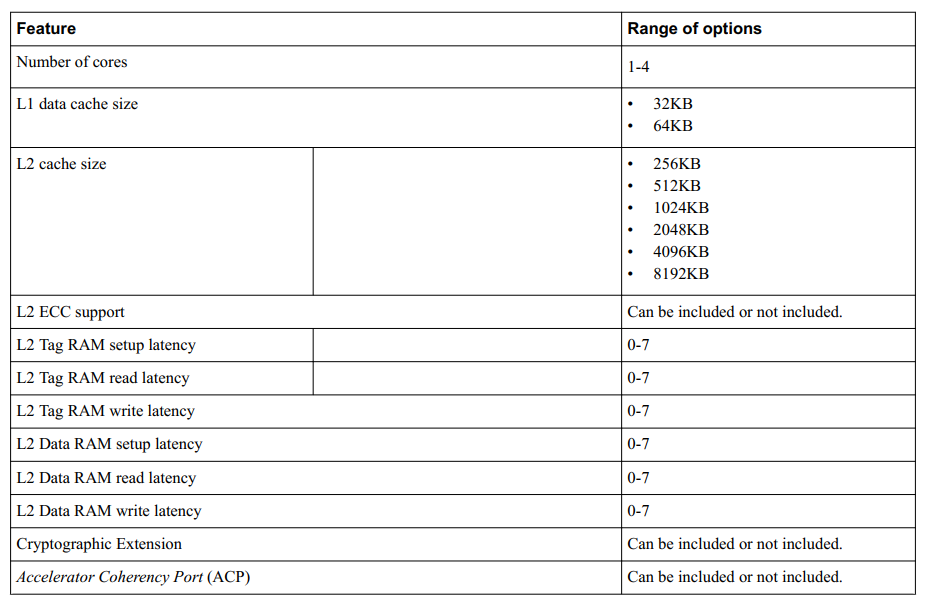
Cortex-A53 处理器是一款中档低功耗(mid-range, low-power)处理器,在单个cluster中具有1到4个内核,每个内核都有一个 L1 缓存子系统、一个可选的集成 GICv3/4 接口和一个可选的 L2 缓存控制器。
Cortex-A53 处理器是一款高能效极高的处理器,能够支持 32 位和 64 位代码。它提供的性能明显高于大获成功的 Cortex-A7 处理器。它能够部署为独立的应用处理器,或与Cortex-A57处理器配对,使用big.LITTLE 配置即可实现最佳性能、可扩展性和能效。
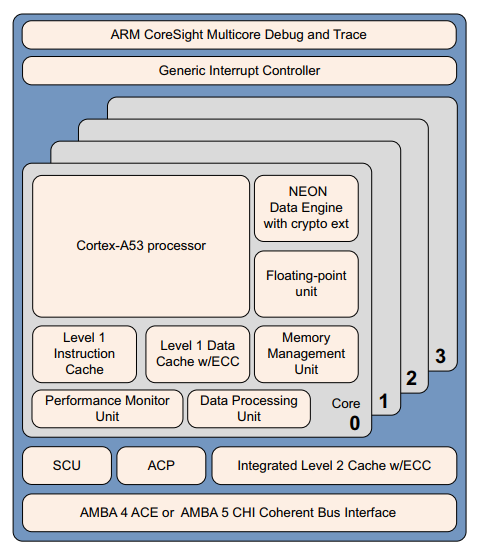
Cortex-A53 处理器具有以下特点:
- 按顺序排列,八级流水线。
- 通过使用分层时钟门控、电源域和高级保持模式,降低功耗。
- 通过重复执行资源和双指令解码器,增强了dual-issue capability 。
- 功耗优化的 L2 高速缓存设计可提供更低的延迟,并在性能与效率之间取得平衡。
Cortex-A57 处理器
Cortex-A57 处理器面向移动和企业计算应用,包括计算密集型 64 位应用,如高端计算机、平板电脑和服务器产品。它可以与Cortex-A53处理器一起使用ARM big.LITTLE 配置,即可实现可扩展的性能和更高效的能源使用。
Cortex-A57 处理器具有与其他处理器(包括用于 GPU 计算的 ARM Mali™ 系列图形处理单元 (GPU))的缓存一致互操作性,并为高性能企业应用提供可选的可靠性和可扩展性功能。它提供比 ARMv7 Cortex-A15 处理器更高的性能,具有更高的能效。与上一代处理器相比,包含加密扩展可将加密算法的性能提高 10 倍。
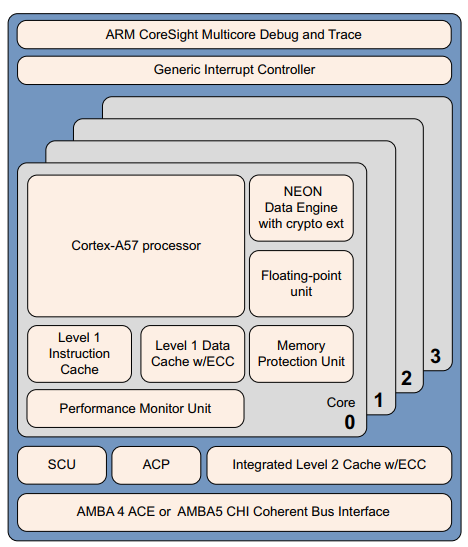
Cortex-A57 处理器完全实现了 ARMv8-A 架构。它支持多核操作,在单个集群中具有一到四个内核的多处理。通过 AMBA5 CHI 或 AMBA 4 ACE 技术,可以实现多个相干的 SMP 集群。调试和跟踪可通过 CoreSight 技术获得。
Cortex-A57 处理器具有以下特点:
- 无序的15 个以上的流水线。
- 节能功能包括way预测、tag减少和缓存查找抑制。
- 通过重复执行资源提高峰值指令吞吐量。 功耗优化的指令解码,具有本地化解码,3-wide解码带宽。
- 性能优化的 L2 高速缓存设计使cluster中的多个内核能够同时访问 L2。
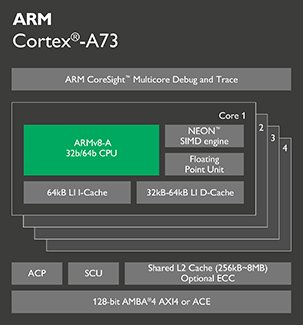
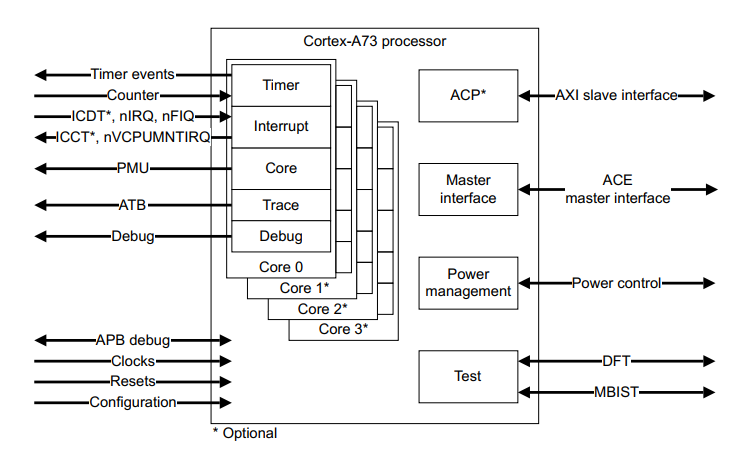
Cortex-A73 处理器
这是ARM 2016年发布的最新A系列处理器,Cortex-A73支持全尺寸ARMv8-A构架,包括128位 AMBR 4 ACE接口和ARM的big.LITTLE系统一体化接口,采用了目前最先进的10nm技术制造,可以提供比Cortex-A72高出30%的持续处理能力,非常适合移动设备和消费级设备使用。
</article>复制