本期分享专家:枫凡,曾就职于安恒信息。目前在阿里云从事ECS产品的技术支持,专注于云计算相关的安全问题以及网络问题。坚信:“不忘初心,方得始终”

在你发现网站访问慢、业务不稳定的时候,你是不是也发现了服务器的ping值很高,还经常会有丢包的情况,这些病症技术专家经常见到,也经常帮客户分析治疗此类病症,总结起来可能的原因有这几点:运营商的网络影响、带宽跑满啦、本地网络问题、系统层面的问题等。 不过专家还说了 ,丢包只是问题的现象,要解决丢包的病症还得找到病根。今天专家枫凡坐诊为您分析丢包问题,一个案例教你如何排查系统原因导致的丢包问题。
问题背景
问题实例:
公网IP地址 xx.xx.138.206
用户业务说明:
用户业务基于UDP 协议,ECS 安装 CentOS 6.5,作为中转服务器,收到客户端发送的UDP报文请求后,根据配置将客户端UDP报文请求转发到其它业务服务器。出入流量大致持平,即流入多少流量,流出多少流量。
客户业务正常服务时, ECS 服务器整体的公网出入 PPS(Packets Per Second) 均在7W 左右。
问题现象:
客户发现业务异常,有如下表现:
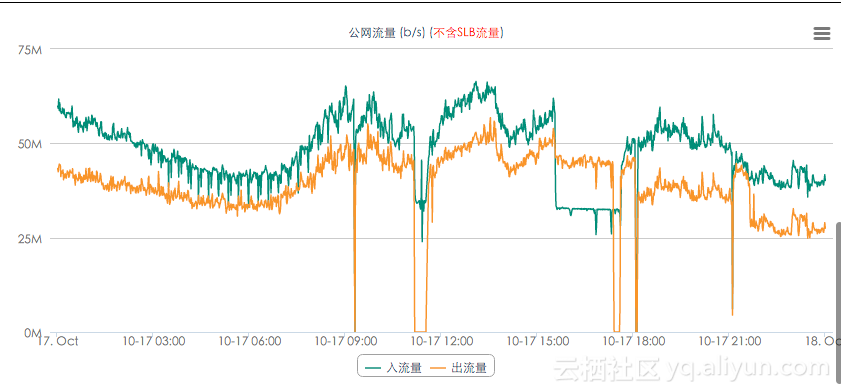
1、整体的流量情况不符合预期,流入流量明显大于流出流量。
2、外部IP地址ping xx.xx.138.206 该IP地址都存在丢包的情况。从本机ping 外部IP地址不存在丢包情况。
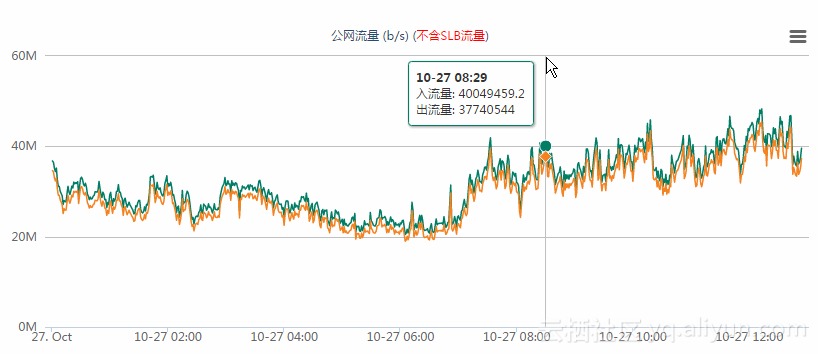
3、查看用户历史数据,在业务高峰期流量高于60M左右时,会出现不稳定的情况。
如下图:
排查思路
根据用户的反馈,核心问题是UDP流量转发异常,同时发现Ping丢包的症状。如下是问题定位过程的步骤摘要:
1、通过双向MTR命令测试,发现ECS对外访问客户端的MTR报文第1跳就丢包。通过ECS内部Tcpdump抓取网络包也发现内部收到ICMP Request后并不响应。我们认为该问题与OS内部相关,与中间网络无关。
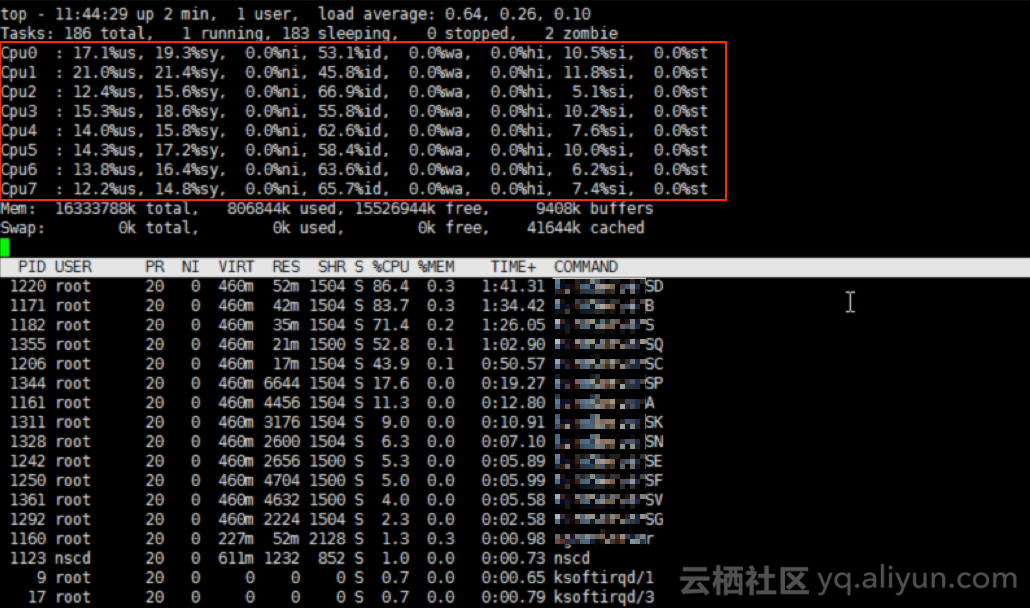
2、通过TOP命令查看OS内部的负载情况,发现CPU 0 跑满,通过调整CentOS启动参数保证软中断在多个CPU核之间均匀处理。
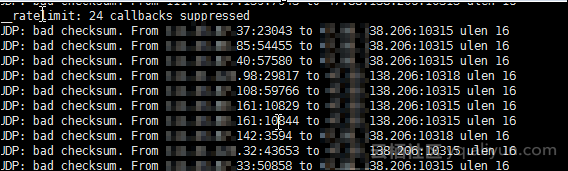
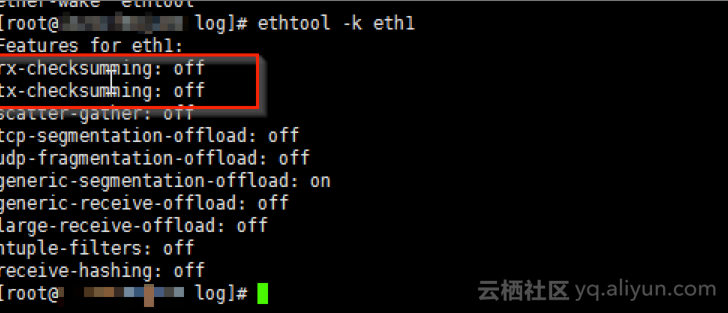
3、通过检查dmesg命令输出以及/var/log/messages等日志,发现有”Bad Checksum”错误和” _ratelimit: 25 callbacks suppressed”信息,通过临时关闭Checksum以排除是否是因为Checksum处理错误造成影响。
4、在进行上述分析时,用户已经将转发业务关闭,但仍然发现出现Ping丢包的情况。
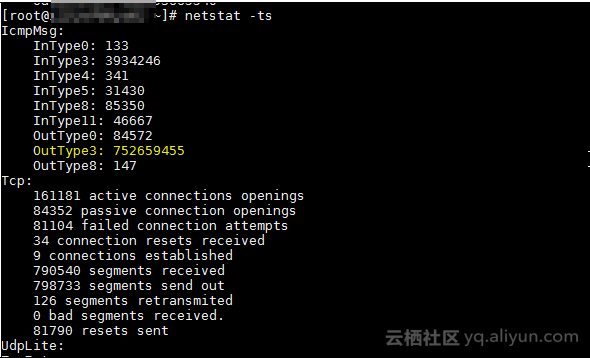
5、通过Sar命令排查系统内部连接数情况,Netstat命令查看网络统计信息发现大量ICMP Type 3报文,通过抓包也确实发现因为业务关闭,造成ECS 返回大量ICMP Type 3(Port Unreachable)消息。我们怀疑内核在大量ICMP Type 3报文的处理下,可能对ICMP Request报文处理存在问题。通过IPTables关闭发送ICMP Port Unreachable消息测试。
6、关闭响应ICMP Type 3后,发现外部Ping该ECS恢复正常。同时将转发业务开启,发现可以正常处理业务。
详情请参考如下逐项的定位测试。
1、网络测试分析
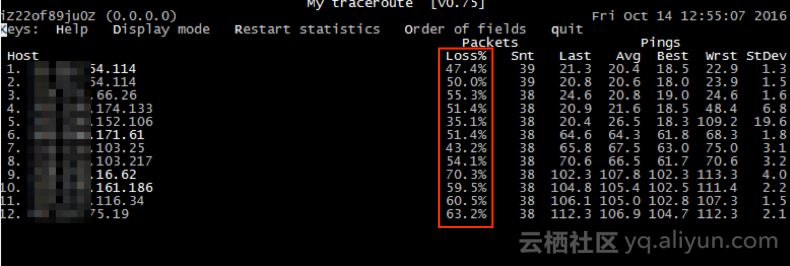
通过MTR定位丢包点,如下图双向MTR结果:
- 从ECS到客户端第一跳就开始丢包;
- 从客户端到ECS,最后一跳才丢包。
结论:结合抓包也发现系统收到ICMP Request后不响应,判断异常是系统内部的原因导致。
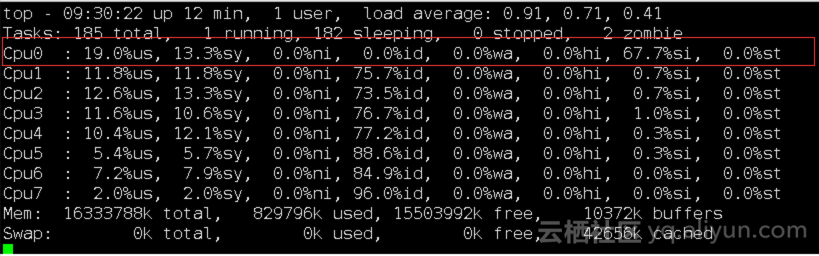
2、CPU负载情况分析
通过Top命令,发现ECS CPU 0跑满,该情况会导致网卡软中断的处理存在问题,可能出现丢包情况。
为了解决该问题,修改Linux内核参数调优中断的使用。
具体见:附3。
处理完成后效果如下:
可以看到来自网卡的网络包处理的软中断在多个CPU核上均匀处理。
3、系统日志层面分析
dmesg命令查看日志发现异常
如下内容的报文:
|
UDP: bad checksum. From xx.xx.86.85:54455 to xx.xx.138.206:10315 ulen 16
|
怀疑是否是由于checksum校验问题导致的,于是为了排除干扰,先关闭Checksum Offload功能。
通过如下命令关闭网卡checksum offload:
关闭后结果如下图:
messages以及dmesg中都出现了如下的信息说明
|
_ratelimit: 25 callbacks suppressed
|
怀疑该提示为日志限速,是由大量的类似如下的报文在打印到日志中,不影响业务。
|
UDP: bad checksum. From xxx.xx.86.85:54455 to xx.xx.138.206:10315 ulen 16
|
4、网络层面分析
用户临时将转发业务关闭,但是客户端的流量仍然发送到该ECS。从原理上来说,转发关闭后,该ECS的出流量应该降低很多,但是通过监控查看发现流量,特别是PPS没有太大的变化。
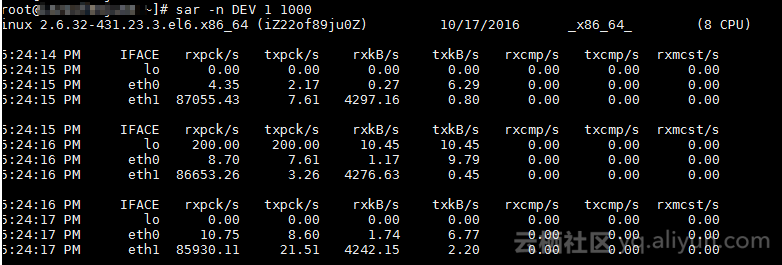
如下通过Sar和Netstat命令在系统内部进行分析:
步骤1:通过Sar查看连接数信息
使用命令
查看关闭业务后还是有大量的连接数,
步骤2:通过Netstat检查各网络协议处理情况
使用命令netstat -ts进行连接数的统计查看。如下图:IcmpMsg:中的OutType3类型有非常大的计数。
注:关于netstat –ts的详细介绍见:附1
我们判断大量ICMP Out Type 3报文与用户业务场景有关,由于用户的业务类型为转发类型的,即使关闭了业务,但是还是有流量流入的。UDP端口关闭监听,在收到报文的情况下,系统会响应ICMP Port Unreachable报文。
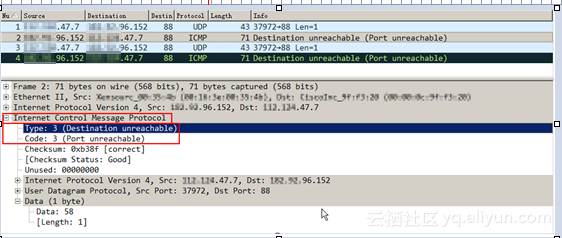
步骤3:抓包核实
通过抓包确实发现了系统有Type 3的回包ICMP destination-unreachable
由于端口不通,主机向客户端返回端口不可达的报文。
注:详细的介绍见”附2”
问题定位以及解决
怀疑点:
由于ICMP报文的原因,导致PPS无法有效的下降,占用CPU资源;同时考虑大量ICMP报文的发送,导致内核在处理ICMP协议时出现问题。
跟进方案:
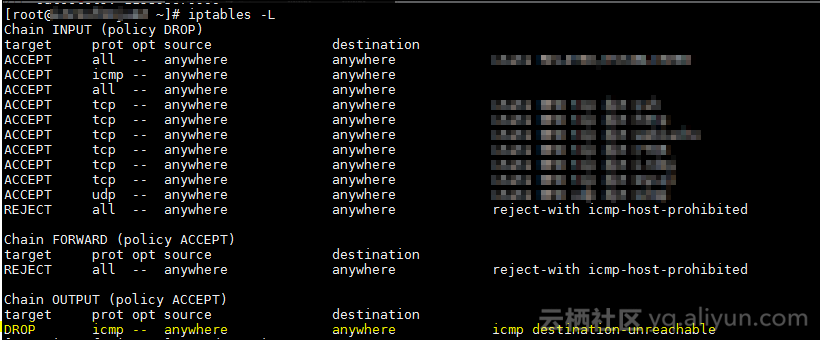
使用系统防火墙IPTables禁止destination-unreachable类型的报文,命令如下:
iptables -I OUTPUT -p icmp --icmp-type destination-unreachable -j DROP
注:该配置会影响到ICMP Destination Unreachable的响应,目前仅作为临时方案。
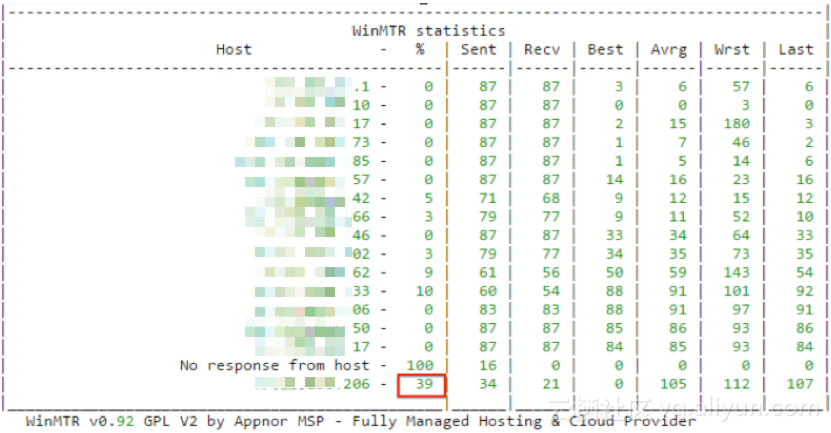
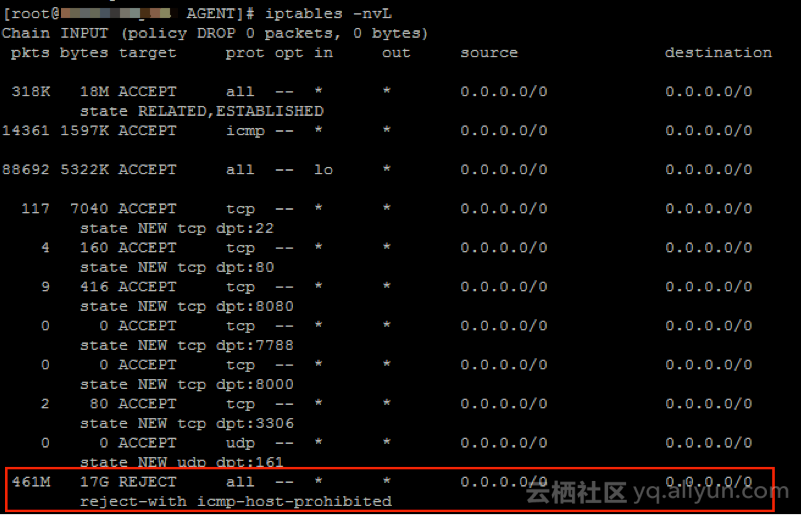
关闭后查看iptables结果如附件,拦截了大量的请求,有效的降低CPU资源消耗。
在系统内部使用命令查看
发送的报文明显减少,如下图
添加后测试用户反馈测试正常。
原因分析:
业务停止后,依然有流量进入服务器,此类情况OS都会回复ICMP destination unreachable消息,海量的ICMP处理可能导致内核处理真正的ICMP Request消息存在问题。目前禁用ICMP Destination Unreachable消息后ECS Ping正常。
用户后续恢复业务使用,反馈业务正常。
关于该问题的本质应该还是在于之前的CPU 0跑满的问题。但在排查的过程中,由于用户停止了应用程序,导致ICMP destination Unreachable 消息影响了系统对网络ICMP Request的处理,误导了排查问题的方向。
通过使用netstat命令、抓包等手段,合理的定位到问题点,先解决了ICMP destination Unreachable的影响,同时通过增加多个CPU处理网卡中断,有效提升了网络流量的处理效率,解决了问题。
附1:关于netstat -ts的介绍
netstat命令大家非常熟悉,一般用户查看系统开放的端口信息和连接建立情况。在排查问题的时,经常使用netstat –antp.
这里介绍下关于netstat 中的参数s
-s或--statistice 显示网络工作信息统计表。
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
netstat -st输出的两个重要信息来源分别是/proc/net/snmp和/proc/net/netstat
如果希望更多了解参数,建议通过“TCP SNMP counters”搜索了解详情。
本例中主要关注ICMP,ICMP协议的统计时在TCP以及UDP下的统计结果类似,类似如下(截图命令执行部分结果):
|
[root@xxxxx ~]# netstat –ts
IcmpMsg:
InType0: 133
InType3: 3934246
InType8: 2211
InType11: 236
OutType0: 2211
OutType3: 752659455 #OUT的Type的计数有752659455该值判断异常。
OutType8: 147
|
附2:关于ICMP协议Type 3的介绍
ICMP经常被认为是IP层的一个组成部分。它传递差错以及其他需要注意的信息。ICMP报文通常被IP层或四层协议(TCP或UDP)使用。一些ICMP报文把差错报文返回给用户进程。
ICMP报文是在IP数据报内部被传输的,它封装在IP数据报内。关于ICMP的正式规范参见RFC792.
端口不可达报文,它是ICMP目的不可到达报文中的一种,以此来看看ICMP差错报文中所附加的信息。举例UDP的ICMP端口不可达;UDP的规则之一是,如果收到一份UDP数据报而目的端口与某个正在使用的进程不相符,那么UDP返回一个不可达报文。
Type:3 Code:3为 端口不可达
报文样例:
附3:CPU 0跑满导致网络丢包的处理方法
问题原因:
OS 默认所有的网络中断都是集中在 CPU 0 上的,所以 CPU 0 一跑满就出现丢包。
问题处理:
注:
1、重启生效
2、适用于内核2.6.32版本(CentOS 6系列),其他内核不适用。
/boot/grub/menu.lst中加入nox2apic参数,
如: kernel /boot/vmlinuz-2.6.32-431.23.3.el6.x86_64 ro root=UUID=94e4e384-0ace-437f-bc96-057dd64f42ee rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet nox2apic
系统层面的丢包问题你知道怎么解了吗?欢迎大家留言讨论,如果有想了解的技术也可以随时留言,我们下期再见。