https://zhuanlan.zhihu.com/p/86513504
平时大家都知道内存访问很快,今天来让我们来思考两个问题:
问题1: 内存访问一次延时到底是多少?你是否会进行大概的估算?
例如笔者的内存条的Speed显示是1066MHz,那是否可以推算出内存IO延时是1s/1066MHz=0.93ns? 这种算法大错特错。
问题2: 内存存在随机IO比顺序IO慢的问题吗? 我们都知道磁盘的随机IO要比顺序IO慢的多(操作系统底层还专门实现了电梯调度算法来缓解这个问题),那么内存的随机IO会比顺序IO慢吗?
要想彻底弄明白以上两个问题,我想我们得从内存IO的物理过程中来寻找答案。
在开始介绍枯燥的内存工作原理之前。我想先给你讲一个故事,并带你去认识一个人,图书馆的管理员。
在我们的这个故事中,你是故事的主角。你有一所房子,房子里有一个仆人,他每天帮你处理各种各样的图书数据。但是北京房价太贵,所以你的这个房子很小,只能放的下64本书。你家的马路对面,就是北京图书馆(你家房子虽然小但是地段还不错),你所需要的所有的图书在那里都可以找到。图书馆有个管理员,他负责帮你把你想要的书找出来。

好接下来,故事开始进行!
场景1:
你发现你需要编号为0的书的计算结果,你的仆人穿过马路告诉了图书管理员,告诉他请帮我把第0-63本书取出来。图书管理员帮你在电脑前查得该书在二楼。 于是他,花了点时间坐电梯到了二楼。等到了二楼,他又花了点时间帮你找了出来。然后你的仆人抱着64本书放到了客厅,拿起第0本书帮你处理了起来。
场景2:
你发现你需要编号为1的书的计算结果,告诉你的仆人。你的仆人直接从客厅拿出来就可以处理了,这次你等的时间最短。
场景3:
你发现需要编号为65的书,你又告诉你的仆人。你的仆人穿过马路又去找了图书管理员。图书管理员还在二楼呢,听说这次需要65-127,这次他不用再花时间找楼层了。只是花时间找书就可以了。你的仆人把65-127的书放到了客厅(以前的0-63就都扔了),并帮你开始处理起65号书来。
场景4:
你发现你需要编号为10000的书,你告诉了你的仆人。你的仆人穿过马路去图书馆,找到了管理员。这次管理员查得你需要的书是在10楼,他得花点时间坐电梯过去。去了之后,他又得花点时间帮你找出来。
这四个场景里,我觉得你一定发现了不同情形下耗时的差异。
之所以编造这么一个例子,是因为内存的工作方式和它太像了。 接下来我们进入内存的实际分析。
在《带你理解内存对齐最底层原理!》中我们了解了内存颗粒的物理构造以及IO过程,今天我们再来复习一下。
内存是由chip构成。每个chip内部,是由8个bank组成的。其构造如下图:

而每一个bank是一个二维平面上的矩阵,前面文章中我们说到过。矩阵中每一个元素中都是保存了1个字节,也就是8个bit。

每当CPU向内存请求数据的时候,内存芯片总是8个bank并行一起工作。每个bank在定位到行地址后,把对应的行copy到row buffer。 再根据列地址把对应的元素中的数据取出来,8个bank把数据拼接一下,一个64位宽的数据就可以返回给CPU了。
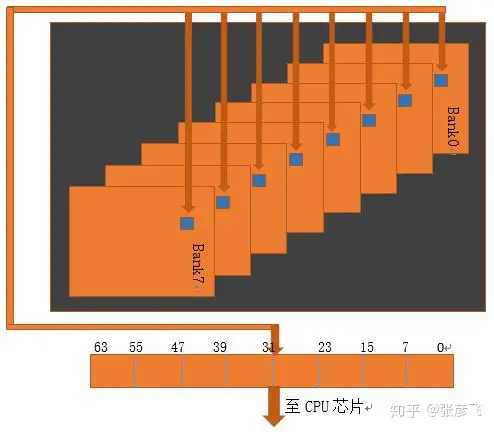
根据上面几张图我们可以大致了解内存的IO过程,在这个过程中每一步操作之间都有一些延迟,让我们来继续了解这些延迟。
在《从DDR发展到DDR4,内存核心频率指标其实基本上就没太大的进步》里我们提到内存的延迟很大程度是受核心频率制约的,你也应该记得我们提到了内存延迟一般是通过CL-tRCD-tRP-tRAS四个参数来标识的。 我们今天来详细理解一下这四个参数的含义:
要注意除了CL是固定周期数以外,其它的三个都是最小周期。另外上面的参数都是以时钟周期为单位的。因为现代的内存都是一个时钟周期上下沿分别各传输一次数据,所以用Speed/2就可以得出,例如笔者的机器的Speed是1066MHz,则时钟周期为533MHz。你自己的机器可以通过dmidecode命令查看:
# dmidecode | grep -P -A16 "Memory Device"
Memory Device
......
Speed: 1067 MHz
......和“图书管理员”类似,内存芯片也有类似的工作场景:
场景1:
你的进程需要内存地址0x0000为的一个字节的数据,CPU这时候向内存控制器发出请求,内存控制器进行行地址的预充电,需要等待tRP个时钟周期。再发出打开一行内存的命令,又需要等待tRCD个时钟周期。接着发送列地址,再等待CL个周期。最终将0x0000-0x0007的数据全部返回给了CPU。 CPU把这些数据放入到了自己的cache里,并帮你开始对0x0000的数据进行运算。
场景2:
你的进程需要内存地址0x0003的一个字节数据,CPU发现发现它在自己的cache里存在,直接使用就好了。这个场景里其实根本就没有内存IO发生。
场景3:
你的进程需要内存地址0x0008的一个字节数据,CPU的cache并没有命中,于是向内存控制器请求。内存控制器发现行地址和上一次工作的行地址一致,这次只需要发送列地址后等待CL个周期,就可以拿到0x0008-0x0015的数据并返回给CPU了。
场景4:
你的进程需要内存地址0xf000的一个字节数据,同样CPU的cache并不命中,向内存控制器请求。内存控制器一看(内心有些许的郁闷),这次行地址又变了,得,和场景1一样。继续等待tRP+tRCD+CL个周期后,才能够取到数据并返回。
实际的计算机的内存IO过程中还需要进行逻辑地址和物理地址的转换,这里忽略不表。
其中场景1和场景4是随机IO的情况,场景2无内存IO发生,场景3是顺序IO。通过上面的过程描述我们可以得到结论。内存也存在和磁盘一样,随机IO比顺序IO要慢的问题。如果行地址同上一次访问的不一致,则需要重新拷贝row buffer,延迟周期需要tRP+tRCD+CL。而如果是顺序IO的话(行地址不变),只需要CL个周期既可完成。
我们接着估算下内存的延时,笔者的机器上的内存参数Speed为1066MHz(通过dmidecode查得),该值除以2就是时钟周期的频率=1066/2=533Mhz。其延迟周期为7-7-7-24。
因为对于内存来说,随机IO一次开销比顺序IO高好几倍。所以操作系统在工作的时候,会尽量让内存通过顺序IO的方式来进行。做法关键就是Cache Line。当CPU发现缓存不命中的时候,实际上从来不会向内存去请求1个字节,8个字节这种。而是一次性就要64字节,然后放到自己的Cache中存起来。
用上面的例子来看,
开销也没贵多少,因为只有第一个字节可能是随机IO,后面的7个字节都是顺序IO。数据是8倍,但是IO耗时只有3倍,而且取出来的数据后面大概率要用,所以计算机内部就这么搞了,通过这种方式帮你避免一些随机IO!
另外,内存也支持burst(突发传输)模式,在这种模式下可以只传入一次行列地址,就命令内存返回该内存开头的连续字节数据,比如64字节。这种模式下,只有第一次的8字节需要真正的行列访问延迟,后面的7个字节可以直接按内存的数据频率给吐出来。接下来我们进行实践测试,请转移到《实际测试内存在顺序IO和随机IO时的访问延时差异》。