最近在使用过程中使用SqlServer的时候发现在高并发情况下,频繁更新和频繁查询引发死锁。通常我们知道如果两个事务同时对一个表进行插入或修改数据,会发生在请求对表的X锁时,已经被对方持有了。由于得不到锁,后面的Commit无法执行,这样双方开始死锁。但是select语句和update语句同时执行,怎么会发生死锁呢?看完下面的分析,你会明白的…
首先看到代码中使用的查询的方法Select
[csharp] view plain copy
/// <summary>
/// 根据学生ID查询教师信息。用于前台学生评分主页面显示
/// </summary>
/// <param name="enTeacherCourseStudent">教师课程学生关系实体:StudentID</param>
public DataTable QueryTeacherByStudent(TeacherCourseStudentLinkEntity enTeacherCourseStudent)
{
//TODO:QueryTeacherByStudent string strSql = "SELECT ID, CollegeTeacherID,CollegeTeacherName,TeacherID,TeacherCode," +
//"TeacherName,CourseID,CourseName,CourseTypeID,CourseTypeName," +
//"StudentID,StudentName,IsEvluation FROM TA_TeacherCourseStudentLink WITH(NOLOCK) " +
//"WHERE StudentID = @StudentID";
//根据学生ID查询该学生对哪些教师评分的sql语句
string strSql = "SELECT ID, CollegeTeacherID,CollegeTeacherName,TeacherID,TeacherCode," +
"TeacherName,CourseID,CourseName,CourseTypeID,CourseTypeName," +
"StudentID,StudentName,IsEvluation FROM TA_TeacherCourseStudentLink WITH(NOLOCK) " +
"WHERE StudentID = @StudentID";
//参数
SqlParameter[] para = new SqlParameter[] {
new SqlParameter("@StudentID",enTeacherCourseStudent.StudentID) //学生ID
};
//执行带参数的sql查询语句或存储过程
DataTable dtStuTeacher = sqlHelper.ExecuteQuery(strSql, para, CommandType.Text);
//返回查询结果
return dtStuTeacher;
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
更新方法
/// <summary>
/// 学生对教师评分完毕,是否评估由N变为Y
/// </summary>
/// <param name="enTeacherCourseStudent">教师课程学生关系实体:StudentID、TeacherID、CourseID</param>
/// <return>是否修改成功,true成功,false失败</return>
public Boolean EditIsEvaluation(TeacherCourseStudentLinkEntity enTeacherCourseStudent, SqlConnection sqlCon, SqlTransaction sqlTran)
{
//更改是否评估字段为"Y"的sql语句
string strSql = "UPDATE TA_TeacherCourseStudentLink WITH(UPDLOCK) SET IsEvluation='Y' WHERE TeacherID=@TeacherID AND StudentID=@StudentID AND CourseID=@CourseID";
//参数
SqlParameter[] paras = new SqlParameter[]{
new SqlParameter("@TeacherID",enTeacherCourseStudent.TeacherID), //教师ID
new SqlParameter("@StudentID",enTeacherCourseStudent.StudentID), //学生ID
new SqlParameter("@CourseID",enTeacherCourseStudent.CourseID) //课程ID
};
//李社河添加2014年12月29日
Boolean flagModify = false;
try
{
//执行带参数的增删改sql语句或存储过程
flagModify = sqlHelper.ExecNoSelect(strSql, paras, CommandType.Text, sqlCon, sqlTran);
}
catch (Exception e)
{
throw e;
}
//返回修改结果
return flagModify;
复制
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
现在分析,在数据库系统中,死锁是指多个用户(进程)分别锁定了一个资源,并又试图请求锁定对方已经锁定的资源,这就产生了一个锁定请求环,导致多个用户(进程)都处于等待对方释放所锁定资源的状态。还有一种比较典型的死锁情况是当在一个数据库中时,有若干个长时间运行的事务执行并行的操作,当查询分析器处理一种非常复杂的查询例如连接查询时,那么由于不能控制处理的顺序,有可能发生死锁现象。
那么,什么导致了死锁?
现象图
 通过查询sqlserver的事务日志视图,发生的错误日志视图知道是在高并发的情况下引发的update和select发生的死锁,接下来我们看例子;
通过查询sqlserver的事务日志视图,发生的错误日志视图知道是在高并发的情况下引发的update和select发生的死锁,接下来我们看例子;
CREATE PROC p1 @p1 int AS
SELECT c2, c3 FROM t1 WHERE c2 BETWEEN @p1 AND @p1+1
GO
CREATE PROC p2 @p1 int AS
UPDATE t1 SET c2 = c2+1 WHERE c1 = @p1
UPDATE t1 SET c2 = c2-1 WHERE c1 = @p1
GO
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
p1没有insert,没有delete,没有update,只是一个select,p2才是update。那么,什么导致了死锁?
需要从事件日志中,看sql的死锁信息:
Spid X is running this query (line 2 of proc [p1], inputbuffer “… EXEC p1 4 …”):
SELECT c2, c3 FROM t1 WHERE c2 BETWEEN @p1 AND @p1+1
Spid Y is running this query (line 2 of proc [p2], inputbuffer “EXEC p2 4”):
UPDATE t1 SET c2 = c2+1 WHERE c1 = @p1
The SELECT is waiting for a Shared KEY lock on index t1.cidx. The UPDATE holds a conflicting X lock.
The UPDATE is waiting for an eXclusive KEY lock on index t1.idx1. The SELECT holds a conflicting S lock.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
首先,我们看看p1的执行计划。怎么看呢?可以执行set statistics profile on,这句就可以了。下面是p1的执行计划
SELECT c2, c3 FROM t1 WHERE c2 BETWEEN @p1 AND @p1+1
|--Nested Loops(Inner Join, OUTER REFERENCES:([Uniq1002], [t1].[c1]))
|--Index Seek(OBJECT:([t1].[idx1]), SEEK:([t1].[c2] >= [@p1] AND [t1].[c2] <= [@p1]+(1)) ORDERED FORWARD)
|--Clustered Index Seek(OBJECT:([t1].[cidx]), SEEK:([t1].[c1]=[t1].[c1] AND [Uniq1002]=[Uniq1002]) LOOKUP ORDERED FORWARD
- 1
- 2
- 3
- 4
我们看到了一个nested loops,第一行,利用索引t1.c2来进行seek,seek出来的那个rowid,在第二行中,用来通过聚集索引来查找整行的数据。这是什么?就是bookmark lookup啊!为什么?因为我们需要的c2、c3不能完全的被索引t1.c1带出来,所以需要书签查找。
好,我们接着看p2的执行计划。
[sql] view plain copy
UPDATE t1 SET c2 = c2+1 WHERE c1 = @p1
|--Clustered Index Update(OBJECT:([t1].[cidx]), OBJECT:([t1].[idx1]), SET:([t1].[c2] = [Expr1004]))
|--Compute Scalar(DEFINE:([Expr1013]=[Expr1013]))
|--Compute Scalar(DEFINE:([Expr1004]=[t1].[c2]+(1), [Expr1013]=CASE WHEN CASE WHEN ...
|--Top(ROWCOUNT est 0)
|--Clustered Index Seek(OBJECT:([t1].[cidx]), SEEK:([t1].[c1]=[@p1]) ORDERED FORWARD)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
通过聚集索引的seek找到了一行,然后开始更新。这里注意的是,update的时候,它会申请一个针对clustered index的X锁的。
实际上到这里,我们就明白了为什么update会对select产生死锁。update的时候,会申请一个针对clustered index的X锁,这样就阻塞住了(注意,不是死锁!)select里面最后的那个clustered index seek。死锁的另一半在哪里呢?注意我们的select语句,c2存在于索引idx1中,c1是一个聚集索引cidx。问题就在这里!我们在p2中更新了c2这个值,所以sqlserver会自动更新包含c2列的非聚集索引:idx1。而idx1在哪里?就在我们刚才的select语句中。而对这个索引列的更改,意味着索引集合的某个行或者某些行,需要重新排列,而重新排列,需要一个X锁。
- 1
问题就这样被发现了,就是说,某个query使用非聚集索引来select数据,那么它会在非聚集索引上持有一个S锁。当有一些select的列不在该索引上,它需要根据rowid找到对应的聚集索引的那行,然后找到其他数据。而此时,第二个的查询中,update正在聚集索引上忙乎:定位、加锁、修改等。但因为正在修改的某个列,是另外一个非聚集索引的某个列,所以此时,它需要同时更改那个非聚集索引的信息,这就需要在那个非聚集索引上,加第二个X锁。select开始等待update的X锁,update开始等待select的S锁,死锁,就这样发生鸟。
添加了针对select和update同一个表的非聚集索引解决问题。那么,为什么我们增加了一个非聚集索引,死锁就消失鸟?我们看一下,按照上文中自动增加的索引之后的执行计划:
ELECT c2, c3 FROM t1 WHERE c2 BETWEEN @p1 AND @p1+1
|--Index Seek(OBJECT:([deadlocktest].[dbo].[t1].[_dta_index_t1_7_2073058421__K2_K1_3]), SEEK:([deadlocktest].[dbo].[t1].[c2] >= [@p1] AND [deadlocktest].[dbo].[t1].[c2] <= [@p1]+(1)) ORDERED FORWARD)
- 1
- 2
- 3
哦,对于clustered index的需求没有了,因为增加的覆盖索引已经足够把所有的信息都select出来。就这么简单。
实际上,在sqlserver 2005中,如果用profiler来抓eventid:1222,那么会出现一个死锁的图,很直观的说。
下面的方法,有助于将死锁减至最少(详细情况,请看SQLServer联机帮助,搜索:将死锁减至最少即可)。
· 按同一顺序访问对象。
· 避免事务中的用户交互。
· 保持事务简短并处于一个批处理中。
· 使用较低的隔离级别。
· 使用基于行版本控制的隔离级别。
- 将 READ_COMMITTED_SNAPSHOT 数据库选项设置为 ON,使得已提交读事务使用行版本控制。
- 使用快照隔离。
- 1
- 2
- 3
· 使用绑定连接。
下面我们在测试的同时开启trace profiler跟踪死锁视图(locks:deadlock graph).(当然也可以开启跟踪标记,或者应用扩展事件(xevents)等捕捉死锁)
创建测试对象code
create table testklup
( clskey int not null,
nlskey int not null,
cont1 int not null,
cont2 char(3000)
)
create unique clustered index inx_cls on testklup(clskey)
create unique nonclustered index inx_nlcs on testklup(nlskey) include(cont1)
insert into testklup select 1,1,100,'aaa'
insert into testklup select 2,2,200,'bbb'
insert into testklup select 3,3,300,'ccc'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
开启会话1 模拟高频update操作
----模拟高频update操作
eclare @i int
set @i=100
while 1=1
begin
update testklup set cont1=@i
where clskey=1
set @i=@i+1
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
开启会话2 模拟高频select操作
----模拟高频select操作
declare @cont2 char(3000)
while 1=1
begin
select @cont2=cont2 from testklup where nlskey=1
- 1
- 2
- 3
- 4
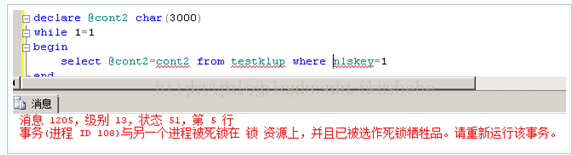 而在我们开启的跟踪中捕捉到了死锁.
而在我们开启的跟踪中捕捉到了死锁.
死锁分析:可以看出由于读进程(108)请求写进程(79)持有的X锁被阻塞的同时,写进程(79)又申请读进程(108)锁持有的S锁.读执行计划图,写执行计划图

 (由于在默认隔离级别下(读提交)读申请S锁只是瞬间过程,读完立即释放,不会等待事务完成),所以在并发,执行频率不高的情形下不易出现.但我们模拟的高频情况使得S锁获得频率非常高,此时就出现了仅仅两个会话,一个读,一个写就造成了死锁现象.
(由于在默认隔离级别下(读提交)读申请S锁只是瞬间过程,读完立即释放,不会等待事务完成),所以在并发,执行频率不高的情形下不易出现.但我们模拟的高频情况使得S锁获得频率非常高,此时就出现了仅仅两个会话,一个读,一个写就造成了死锁现象.
死锁原因:读操作中的键查找造成的额外锁(聚集索引)需求
解决方案:在了解了死锁产生的原因后,解决起来就比较简单了.
我们可以从以下几个方面入手.
a 消除额外的键查找锁需的锁
b 读操作时取消获取锁
a.1我们可以创建覆盖索引使select语句中的查询列包含在指定索引中
CREATE NONCLUSTERED INDEX [inx_nlskey_incont2] ON [dbo].[testklup] ([nlskey] ASC) INCLUDE ( [cont2])
- 1
a.2 根据查询需求,分步执行,通过聚集索引获取查询列,避免键查找.’
declare @cont2 char(3000) declare @clskey intwhile 1=1 begin select @clskey=clskey from testklup where nlskey=1 select @cont2=cont2 from testklup where clskey=@clskey end
- 1
b 通过改变隔离级别,使用乐观并发模式,读操作时源行无需锁
declare @cont2 char(3000)
while 1=1
begin
select @cont2=cont2 from testklup with(nolock) where nlskey=1
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
本文为转载文章,转载原csdn博客为: http://blog.csdn.net/ajianchina/article/details/46807131