1:设置合理的索引分片数和副本数
索引分片数建议设置为集群节点的整数倍,初始数据导入时副本数设置为 0,生产环境副本数建议设置为 1(设置 1 个副本,集群任意 1 个节点宕机数据不会丢失;设置更多副本会占用更多存储空间,操作系统缓存命中率会下降,检索性能不一定提升)。单节点索引分片数建议不要超过 3 个,每个索引分片推荐 10-40GB 大小,索引分片数设置后不可以修改,副本数设置后可以修改。
Elasticsearch6.X 及之前的版本默认索引分片数为 5、副本数为 1,从 Elasticsearch7.0 开始调整为默认索引分片数为 1、副本数为 1。
不同分片数对写入性能的影响(测试环境:7节点Elasticsearch6.3集群,写入30G新闻数据,单节点56核CPU、380G内存、3TB SSD卡,0副本,20线程写入,每批次提交10M左右数据)。
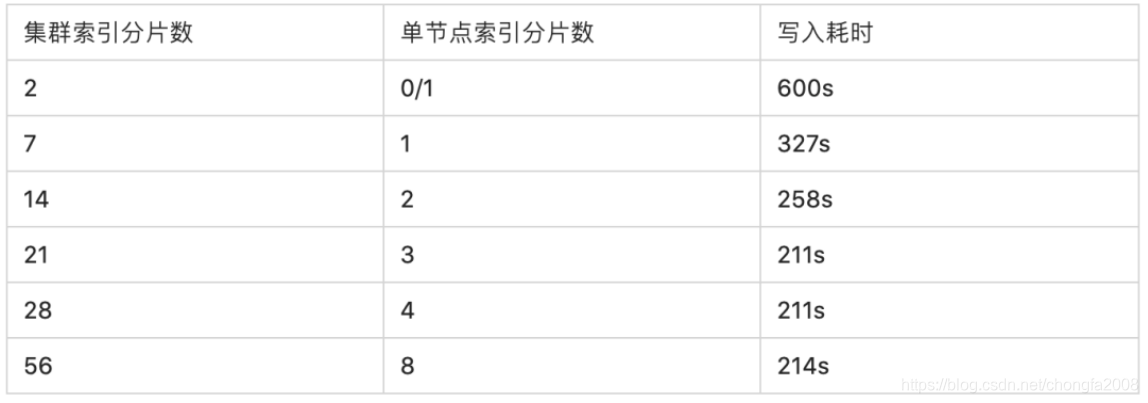
2:使用批量请求
使用批量请求将产生比单文档索引请求好得多的性能。写入数据时调用批量提交接口,推荐每批量提交5~15MB 数据。例如单条记录 1KB 大小,每批次提交 10000 条左右记录写入性能较优;单条记录 5KB大小,每批次提交 2000 条左右记录写入性能较优。
3:通过多进程/线程发送数据
单线程批量写入数据往往不能充分利用服务器 CPU 资源,可以尝试调整写入线程数或者在多个客户端上同时向 Elasticsearch 服务器提交写入请求。与批量调整大小请求类似,只有测试才能确定最佳的worker 数量。可以通过逐渐增加工作任务数量来测试,直到集群上的 I/O 或 CPU 饱和。
4:调大refresh interval
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是近实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件,你可能想优化索引速度而不是近实时搜索,可以通过设置 refresh_interval,降低每个索引的刷新频率。

refresh_interval 可以在已经存在的索引上进行动态更新,在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来。

5:配置事务日志参数
事务日志translog 用于防止节点失败时的数据丢失。它的设计目的是帮助 shard 恢复操作,否则数据可能会从内存 flush 到磁盘时发生意外而丢失。事务日志 translog 的落盘(fsync)是 ES 在后台自动执行的,默认每 5 秒钟提交到磁盘上,或者当 translog 文件大小大于 512MB 提交,或者在每个成功的索引、删除、更新或批量请求时提交。
索引创建时,可以调整默认日志刷新间隔 5 秒,例如改为 60 秒,index.translog.sync_interval:
"60s"。创建索引后,可以动态调整 translog 参数,"index.translog.durability":"async" 相当于关闭
了 index、bulk 等操作的同步 flush translog 操作,仅使用默认的定时刷新、文件大小阈值刷新的机制。

6:设计mapping配置合适的字段类型
Elasticsearch 在写入文档时,如果请求中指定的索引名不存在,会自动创建新索引,并根据文档内容猜测可能的字段类型。但这往往不是最高效的,我们可以根据应用场景来设计合理的字段类型。
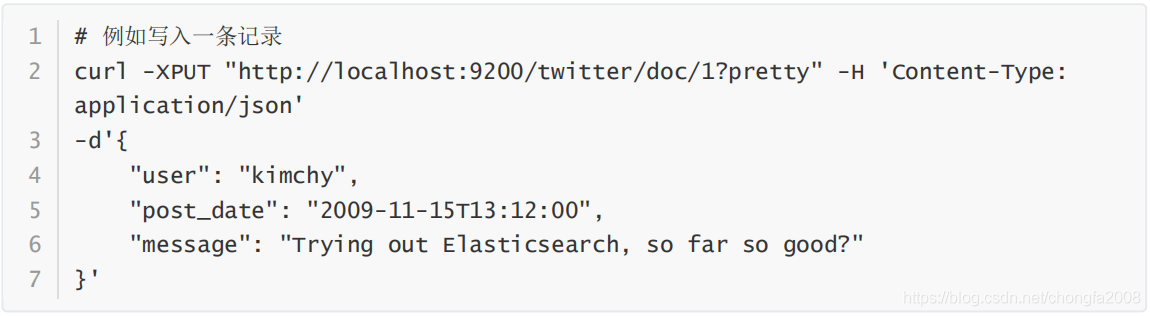
查询 Elasticsearch 自动创建的索引 mapping,会发现将 post_date 字段自动识别为 date 类型,但是message 和 user 字段被设置为 text、keyword 冗余字段,造成写入速度降低、占用更多磁盘空间。

根据业务场景设计索引配置合理的分片数、副本数,设置字段类型、分词器。如果不需要合并全部字段,禁用 _all 字段,通过 copy_to 来合并字段。
