最近在百度云做一些RTC大客户的项目,晚上边缘计算的一台宿主机由于CPU单核耗被打满,最后查到原因是网卡调优没有生效,今天查了一下网卡调优的资料,欢迎大家共同探讨。
一.网卡调优方法
1、Broadcom的网卡建议关闭GRO功能
- ethtool -K eth0 gro off
-
- ethtool -K eth1 gro off
-
- ethtool -K eth2 gro off
-
- ethtool -K eth3 gro off
2、关闭irqbalance服务并手动分配网卡中断
- #关闭 软IRQ服务
- service irqbalance stop
- chkconfig irqbalance off
- # 查看网卡中断号,ens33是网卡名称,对应的中断号是19
- cat /proc/interrupts
- CPU0 CPU1
- 0: 72 0 IO-APIC-edge timer
- 1: 11 143 IO-APIC-edge i8042
- 8: 1 0 IO-APIC-edge rtc0
- 9: 0 0 IO-APIC-fasteoi acpi
- 12: 17 2966 IO-APIC-edge i8042
- 14: 0 0 IO-APIC-edge ata_piix
- 15: 8343 176 IO-APIC-edge ata_piix
- 16: 826 0 IO-APIC-fasteoi vmwgfx, snd_ens1371
- 17: 12896 3063 IO-APIC-fasteoi ehci_hcd:usb1, ioc0
- 18: 147 296 IO-APIC-fasteoi uhci_hcd:usb2
- 19: 287 9931 IO-APIC-fasteoi ens33
- 24: 0 0 PCI-MSI-edge PCIe PME, pciehp
- 25: 0 0 PCI-MSI-edge PCIe PME, pciehp
- 26: 0 0 PCI-MSI-edge PCIe PME, pciehp
- smp_affinity的值可以用下面脚本算哈
- #!/bin/bash
- #
- echo "统计cpu的16进制"
- [ $# -ne 1 ] && echo ‘$1 is Cpu core number’ && exit 1
- CCN=$1
- echo “Print eth0 affinity”
- for((i=0; i<${CCN}; i++))
- do
- echo ==============================
- echo "Cpu Core $i is affinity"
- ((affinity=(1<<i)))
- echo "obase=16;${affinity}" | bc
- done
-
- 使用方法:sh 脚本名字 空格 cpu核数
- [root@localhost ~]# sh 12.sh 2
- 统计cpu的16进制
- “Print eth0 affinity”
- ==============================
- Cpu Core 0 is affinity
- 1
- ==============================
- Cpu Core 1 is affinity
- 2
-
- # 例如,有多颗CPU和多块网卡,将网卡绑定到每颗CPU核上
- cat /proc/irq/{84,85,86,87,88,89,90,91,92,93}/smp_affinity
- echo 1 > /proc/irq/84/smp_affinity
- echo 2 > /proc/irq/85/smp_affinity
- echo 4 > /proc/irq/86/smp_affinity
- echo 8 > /proc/irq/87/smp_affinity
- echo 10 > /proc/irq/88/smp_affinity
- echo 20 > /proc/irq/89/smp_affinity
- echo 40 > /proc/irq/90/smp_affinity
- echo 80 > /proc/irq/91/smp_affinity
- echo 100 > /proc/irq/92/smp_affinity
- echo 200 > /proc/irq/93/smp_affinity
-
3、开启网卡的RPS功能 (Linux内核2.6.38或以上版本支持)
- # Enable RPS (Receive Packet Steering)
-
- rfc=4096
-
- cc=$(grep -c processor /proc/cpuinfo)
-
- rsfe=$(echo $cc*$rfc | bc)
-
- sysctl -w net.core.rps_sock_flow_entries=$rsfe
-
- for fileRps in $(ls /sys/class/net/eth*/queues/rx-*/rps_cpus)
-
- do
-
- echo fff > $fileRps
-
- done
-
- for fileRfc in $(ls /sys/class/net/eth*/queues/rx-*/rps_flow_cnt)
-
- do
-
- echo $rfc > $fileRfc
-
- done
-
- tail /sys/class/net/eth*/queues/rx-*/{rps_cpus,rps_flow_cnt}
献上一个完整的脚本:
- vi /opt/sbin/change_irq.sh
-
- #!/bin/bash
-
- ethtool -K eth0 gro off
-
- ethtool -K eth1 gro off
-
- ethtool -K eth2 gro off
-
- ethtool -K eth3 gro off
-
- service irqbalance stop
-
- chkconfig irqbalance off
-
- cat /proc/irq/{84,85,86,87,88,89,90,91,92,93}/smp_affinity
-
- echo 1 > /proc/irq/84/smp_affinity
-
- echo 2 > /proc/irq/85/smp_affinity
-
- echo 4 > /proc/irq/86/smp_affinity
-
- echo 8 > /proc/irq/87/smp_affinity
-
- echo 10 > /proc/irq/88/smp_affinity
-
- echo 20 > /proc/irq/89/smp_affinity
-
- echo 40 > /proc/irq/90/smp_affinity
-
- echo 80 > /proc/irq/91/smp_affinity
-
- echo 100 > /proc/irq/92/smp_affinity
-
- echo 200 > /proc/irq/93/smp_affinity
-
- # Enable RPS (Receive Packet Steering)
-
- rfc=4096
-
- cc=$(grep -c processor /proc/cpuinfo)
-
- rsfe=$(echo $cc*$rfc | bc)
-
- sysctl -w net.core.rps_sock_flow_entries=$rsfe
-
- for fileRps in $(ls /sys/class/net/eth*/queues/rx-*/rps_cpus)
-
- do
-
- echo fff > $fileRps
-
- done
-
- for fileRfc in $(ls /sys/class/net/eth*/queues/rx-*/rps_flow_cnt)
-
- do
-
- echo $rfc > $fileRfc
-
- done
-
- tail /sys/class/net/eth*/queues/rx-*/{rps_cpus,rps_flow_cnt}
-
- chmod +x /opt/sbin/change_irq.sh
-
- echo "/opt/sbin/change_irq.sh" >> /etc/rc.local
- PS:记得修改网卡中断号,别直接拿来用哦
二. 网络性能理论极限
网络数据包处理的性能指标,一般包括吞吐、延时、丢包率、抖动等。
数据包有大有小,数据包的大小对这些性能指标有很大的影响。
一般认为服务器处理能力很强,不是数据包处理的瓶颈,而通过物理线路能够传送数据包的最大速率,即线速(Wire Speed)才是网络性能的瓶颈点。
随着物理线路和网卡的不断发展,这个线速不断增大,带宽从100Mpbs、1Gbpbs、10Gbpbs、25Gbpbs、40Gbpbs,甚至到100Gpbs。此时服务器数据包处理能力越显重要。原有的服务器数据包处理方式已不能满足要求,一方面服务器硬件需要更新,另一个方面软件处理方式也需要变化。
物理线路上传送的这些0、1电或光信号,当有了格式规定就有了意义,我们知道以太网中有OSI七层模型和简化的TCP/IP四层模型,这些模型规定了一个数据包的格式,下面是一个以太帧(Ethernet frame,俗称二层)格式。


由于物理线路的信号冲突问题(https://en.wikipedia.org/wiki/Ethernet_frame#cite_note-7),一个以太帧(不带vlan)最小为7+1+6+6+2+46+4+12=84B,即我们常说的最小数据包64B,指的是6+6+2+46+4=64B。
根据以太帧的大小,我们就可以算出来,不同的以太帧大小在不同的物理线路上传输的速率,比如10Gbps的物理线路,一个10Gbps的网卡1秒内可以接收的64B的数据包的个数(packet per seconds,即pps)为
14.88Mpps(10^10/84/8),每个以太帧到达网卡的时间为67.20(10^9/14.88/10^6)纳秒,下图可以看出以太帧越大,pps越低,到达时间越长。
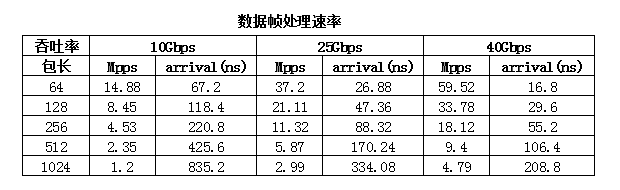 由于物理服务器处理数据包是一个一个处理,包括数据包的校验,数据包每一层包头的处理,所以数据包越小,到达时间就越短,服务器处理数据包要求就越高。比如64B的小包,如果处理数据包要达到线速,那么就要求服务器67.20纳秒就要处理完一个包,随着物理线路速率越大,处理时间就要求越短,这也就要求服务器硬件和软件都要相应的发展和升级来应对越来越多的数据包处理需求。
由于物理服务器处理数据包是一个一个处理,包括数据包的校验,数据包每一层包头的处理,所以数据包越小,到达时间就越短,服务器处理数据包要求就越高。比如64B的小包,如果处理数据包要达到线速,那么就要求服务器67.20纳秒就要处理完一个包,随着物理线路速率越大,处理时间就要求越短,这也就要求服务器硬件和软件都要相应的发展和升级来应对越来越多的数据包处理需求。
三.网卡接收与发送流程
![]() 发送流程如下:
发送流程如下:
1. CPU通知网卡控制器发送内存中的数据
2. 网卡控制器使用DMA将内存中的数据拷贝到网卡本地内存的发送队列
3. 网卡的MAC单元等待数据拷贝完成,准备发送
4. 网卡MAC单元通过PHY(PortPhysical Layer)单元将数据的数字信号转换为对应的电信号或光信号从线缆发送出去
5. 网卡控制器通知CPU数据发送完成
接收流程如下:
1. 网卡的PHY单元接收到数据包信号,将其转换为数字信号
2. 网卡的MAC单元将数据包存储在本地内存的接收队列上
3. 网卡控制器使用DMA将数据拷贝到系统内存上
4. 网卡控制器以中断方式告诉CPU数据包已放在了指定的内存空间
网卡连接主板接口的发展
1. 主板内置网卡(LAN OnMotherboard, LOM),一般为100Mbps或1Gbps,速度慢
2. PCI:也叫传统PCI,速度比较慢
3. PCI Express:支持热插拔,提供更高的总线传输率和带宽
网口的发展
常见接口:电口(RJ-45),光口,InfiniBand
速度发展从100Mbps到100Gbps快速发展
四.网卡控制器的发展
目前常用的网卡控制器都是ASIC(专用集成电路)芯片,该芯片固化了网络的功能,速度快,设计完成后,成本低。但不可编程。
现在FPGA的可编程控制器也越来越流行,原来FPGA是作为实验和研究的平台,比如设计和实验新的网络功能,之后使用ASIC实现。随着虚拟化,云计算的发展,FPGA成本的降低,FPGA的使用也越来越多。
还有一种是ASIC和FPGA混合方案,力图做到兼顾两者的优点。
ASIC芯片控制器的发展使得网卡的功能越来越强大,之前很多数据包处理的功能都是CPU来完成,占用大量CPU时间,很多重复简单的工作被网卡芯片来处理大大减轻了CPU的负担,这就是网卡offload功能。
我们使用 ethtool -k eth0 命令可以看到网卡支持的offload功能。
- Checksumming:TCP,UDP数据包都有checksum字段,这些checksum的计算和校验交由网卡处理。
- segmentation-offload:由于MTU的限制,从网卡发出去的包中PDU(ProtocolData Unit)需要小于等于MTU,所以网卡发出去的数据包的大小都有限制。用户态应用程序发送数据时,不会关心MTU,一个IP数据包最大可以是65535B,即MTU最大可以是65535,但是这个数据包要从网卡发出必须要切分为1500的小包。这个切分过程如果CPU来做会占用大量CPU时间,segmentation-offload就是网卡来做这件事。当然如果你将MTU设置为9000(jumbo frame),CPU和网卡都会少处理一些。MTU理论上虽然可以设置更大,但是9000是一个标准,交换机、网卡等都支持,为什么不能设置更大,一个原因是设备不支持,另一个原因是太大的话数据包传输过程中出错几率就变大,数据包处理慢,延时也变高。
- receive-offload:这个和segmentation-offload刚好相反,网卡收到小包之后,根据包的字段知道可以合成为一个大包,就会将这些小包合成为大包之后给到应用程序,这样既减少了CPU的中断,也减少了CPU处理大量包头的负担。
- scatter-gather:DMA将主存中的数据包拷贝到网卡内存时,由于主存中的数据包内容在物理内存上是分散存储的,如果没有scatter-gather,DMA没法直接拷贝,需要kernel拷贝一次数据让地址连续,有了scatter-gather,就可以少一次内存拷贝。
- tx-fcoe-segmentation,tx-gre-segmentation,tx-ipip-segmentation,tx-sit-segmentation,tx-udp_tnl-segmentation,tx-mpls-segmentation: 这些基本是overlay或其他类型的数据包网卡是否支持的offload,比如udp_tnl就是指vxlan是否支持offload。
- ntuple-filters,receive-hashing:如果网卡支持多队列,ntuple-filters使得用户可以设置不同的数据包到不同的队列,receive-hashing根据从网卡进来的数据包hash到不同的队列处理,实现并发接收数据包。
还有很多offload,都对性能有或多或少的影响。
随着网卡的不断发展,智能网卡会承载越来越多的功能,以减轻CPU的负担。
比如:
- 将安全相关的处理(SSL/IPsec,防火墙,入侵检测,防病毒)集成在网卡中
- 将协议栈实现在网卡中
- 将虚拟交换机功能实现在网卡中(ASAP2)
- 使用FPGA的网卡实现用户对网卡的自定义。
五.网卡offload
对于云计算中虚拟机的网络,首先充分利用网卡的Offload功能,性能会有很大提升,其次从虚拟机网卡到物理网卡的这段路径如何实现也会对性能产生很大影响,目前有四种方式。
1. Passthrough方式:直接把物理网卡映射给虚机,虽然这种性能是最好的,但是丧失了虚拟化的本质,一个物理网卡只能被一个虚机使用。
2. SR-IOV方式:物理网卡支持虚拟化功能,能将物理网卡虚拟成多个网卡,让多个虚机直接使用,相当于虚拟机直接使用物理网卡功能,性能很好。但是对于虚拟机的防火墙,动态迁移等不好实现。
3. Virtio半虚拟化方式:Vritio是Hypervisor中IO设备的抽象层,虚拟机的网卡是Virtio的前端驱动实现,而后端驱动实现可以是Linux kernel中的vhost-net,也可以用户态的vhost-user。后端驱动实现的方式对Virtio性能影响很大。
4. 全虚拟化方式:完全由QEMU纯软件模拟的设备,性能最差。
六.网卡调优
硬件调优尽量使用网卡的offload,offload的成本是低的,效果是明显的。
Offload的一些参数调优
1. 查看设置网卡队列个数
ethtool -l eth0
2.查看设置ring buffer大小
ethtool -g eth0
3. 查看设置RSS的hash策略,比如vxlan的数据包,两个物理节点的mac和ip是不变的,我们在进行hash时可以算上port,这样两个物理节点之间vxlan也能使用网卡多队列。
ethtool -N eth0 rx-flow-hash udp4 sdfn
七.软件优化
标准Linux网络栈设计复杂,但也是最通用的。下面是一些优化点.
1. 软中断的优化处理
网卡的每个队列会对应一个CPU来处理数据包到达的软中断,合理的将网卡队列绑定到指定的CPU能更好的并发处理数据包,比如将网卡队列绑定到离网卡近的CPU上。
2. 减少不必要的网络栈处理,比如如果不使用ipv6,可以disable掉,如果不使用iptables,清空规则。
3. 网络参数的优化,比如调整socketbuffer,txqueuelen的大小等等。
b. OvS+DPDK
DPDK是Intel实现的一个用户态高速数据包处理框架,相比于Linux内核实现的数据包处理方式,有以下优势。
1. 用户态驱动程序,避免不必要的内存拷贝和系统调用。
2. 使用轮询方式从网卡获取数据包,避免中断方式的上下文切换开销。
3. 独占CPU处理数据包,虽然在网络流量低的时候浪费CPU资源,但是网络流量高的时候处理数据包性能很好,可以避免CPU切换导致的cache miss和上下文切换。最新DPDK可以实现流量小的时候使用中断方式,流量大的时候使用轮询方式。
4. 内存访问优化,充分利用NUMA架构,大页内存,无锁队列实现数据包的并发高效处理。
5. 软件的优化,比如cache line对齐,CPU预取数据,充分利用IntelCPU的网络相关新指令来提升性能。
6. 充分利用网卡的Offload功能实现硬件加速。
虽然DPDK对于数据包处理性能很好,但是它只是将数据包高效的送给用户态,而没有网络栈去处理数据包,社区版DPDK也无法与Linux网络栈很好结合,所以基于Linux网络栈实现的网络应用程序无法直接使用DPDK,如果要使用DPDK,应用程序需要重写。当然如果是全新的网络程序,基于DPDK开发是个不错的选择。
OvS是目前主流的虚拟交换机,支持主流的交换机功能,比如二层交换、网络隔离、QoS、流量监控等,而其最大的特点就是支持openflow,openflow定义了灵活的数据包处理规范,通过openflow流表可以实现各种网络功能,并且通过openflow protocol可以方便的实现控制+转发分离的SDN方案。
OvS丰富的功能和稳定性使得其被部署在各种生产环境中,加上云计算的快速发展,OvS成为了云网络里的关键组件。随着OvS的广泛使用,对OvS的性能也提出了更高的要求。
标准OvS的数据包处理是在kernel中有个datapath,缓存流表,实现快速数据包转发。Kernel中数据包的处理复杂,效率相比DPDK慢不少,因此使用DPDK加速能有效的提升OvS数据包处理的能力。
虽然DPDK没有用户态网络栈支撑,但是OvS提供的基于流表的交换机,负责连通虚机和网卡,不需要网络栈的更多功能,通过DPDK加速,云环境中虚机到网卡的性能得到了很大提升。
</article>复制