一、问题描述
某天,SRE 部门观察到一个非常重要的应用里面有一台服务器的业务处理时间(Transaction time)在某个时间点变为平时的 3 倍。虽然只持续了短暂的 2 秒,但是如果观察其一周的指标曲线,就会发现在这一周之内,同应用的其它服务器也出现过类似现象。
进一步分析,发现该应用服务器在那个时间点之后立马被重启了。从公司的 PaaS 平台上看,并没有发现人工或者自动化运维机器人引起重启。看来这是一次非正常重启。
如图 1 所示,从 JVM 的系统日志中,我们发现了重启的原因: 无法申请到更多的原生内存,也就是说:内存被用光了。
JVM 系统日志:

图 1(点击可查看大图)
内存被用光之后,JVM 发生了 OOM(Out of memory,内存溢出),系统配置的自动重启服务就把这个应用重启了。
二、初步分析
从上面的日志中,虽然可以明显看到是原生内存被耗光,却不能找出更明确的耗光原因。在同应用的其他服务器上,如果观察内存的使用情况,能明显看到空闲内存逐渐变少。
从下图 2 可以看到,在一个拥有 8G 内存的服务器上,只空闲了 288M。其中,JVM 的年轻代占用 260M 左右,老年代占用 1.3G 左右,而元数据区竟然使用了 2G 多的内存,这在一般的 Java 应用程序里面很少见。
JVM 内存占用情况及系统内存空闲情况:
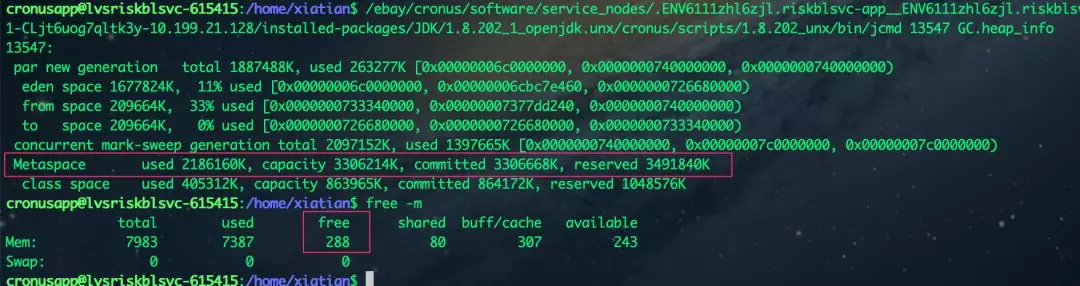
图 2(点击查看大图)
所以我们锁定了可能出问题的方向:元数据区。
为了查明是何原因导致占据如此之多的内存,SRE 侦探们请出了好帮手:heap dump 分析。
我们通过 jcmd 命令做了一个 heap dump。遗憾的是,似乎没有从中发现什么有用的信息。
但是细心的 SRE 侦探不会放过任何蛛丝马迹。
三、进一步分析
我们注意到这个 heap dump 其实非常小,只有 285M 左右。从上述 JVM 的内存占用信息来看,这个 heap dump 的大小实在是不太匹配。
一个可能的原因是: 有些内存在做 heap dump 的过程中被释放了。因为使用 jcmd 默认参数做 heap dump 之前会做一次 Full GC,然后内存就基本只剩下活着的对象了。Full GC 也会对元数据区里面的内存做回收,所以很有可能一些原本占用元数据区内存的数据被回收了。
我们对另外一台服务器使用带-all 参数的 jcmd 命令(jcmd <pid> GC.heap_dump -all), 进行了一次不做 Full GC 的 heap dump。如下图 3 所示,这次的 heap dump 相对大很多。
两次 heap dump 文件:

图 3(点击可查看大图)
由于元数据区和永久代里面大部分都是与 Class 相关的元数据信息,加之所有的类都是由各种 ClassLoader 加载的,所以我们首先分析 ClassLoader。
我们使用 MAT 对 heap 里面的 ClassLoader 进行分析。运用 MAT 的 ClassLoader Explorer 工具后,发现这份 heap dump 里面,竟然有 17 万多的 ClassLoader。具体如图 4 所示:
使用 MAT 的 Class Loader Explorer 分析:
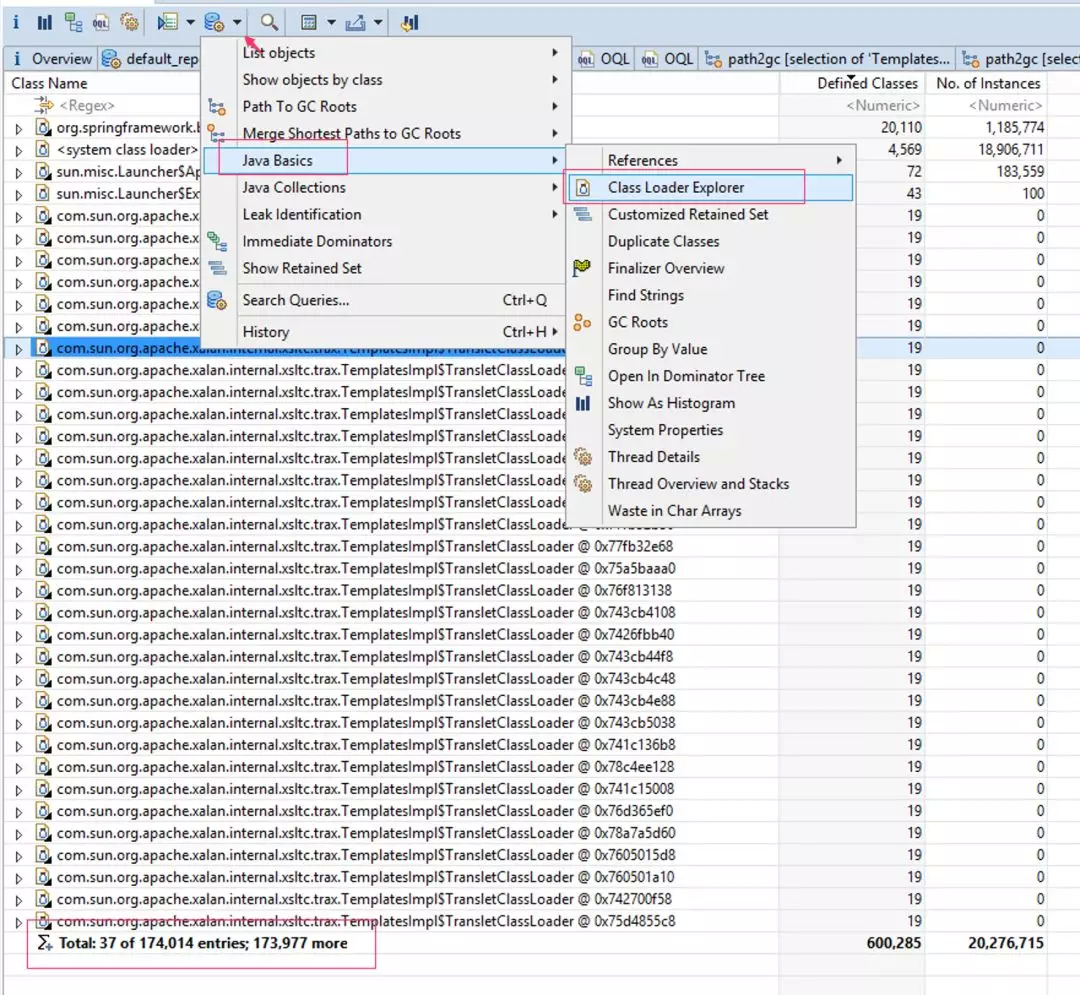
图 4(点击可查看大图)
其中非常可疑的就是:

如图 5 所示,通过 OQL 查询可以看到,这个 ClassLoader 非常之多(17 万+),并且很多都是 Unreachable(不可达),也就是说如果这时候发生一次 Full GC,它们将会被回收掉。
使用 OQL 查询特定的 ClassLoader:
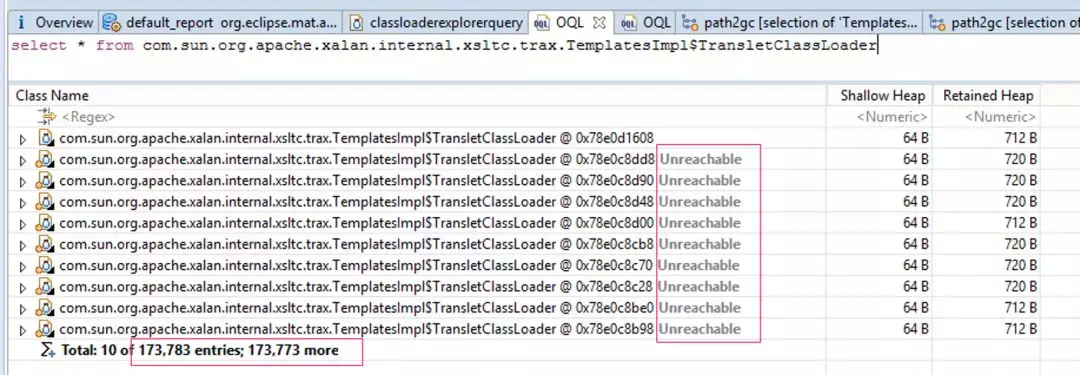
图 5(点击可查看大图)
那么接下来的问题就是:
为什么会产生这么多的 TransletClassLoader 呢?
对这些 TransletClassLoader 以及相关联的类/实例进行分析,并没有发现有用的线索。
即使对上面没有标明 Unreachable 的 TransletClassLoader 进行分析,也会发现它关联的其他类/实例很快也变成了 Unreachable。从这个方向进行追踪,很难发现到底是哪一步创建了这些 TransletClassLoader。
不过,在 JVM 因为内存溢出而退出的时候,它生成了一个 hs_err_pid21618.log 日志文件,该文件详细记录了系统崩溃时间点的所有 Java 线程栈和 native 线程栈,以及当时操作系统的一些其他信息。
导致系统崩溃的线程栈,就在所有线程栈的最上方,可以告诉我们当时这个线程正在做什么。如下图 6 所示:
JVM 崩溃时产生的 hs_err_pid 文件片段:
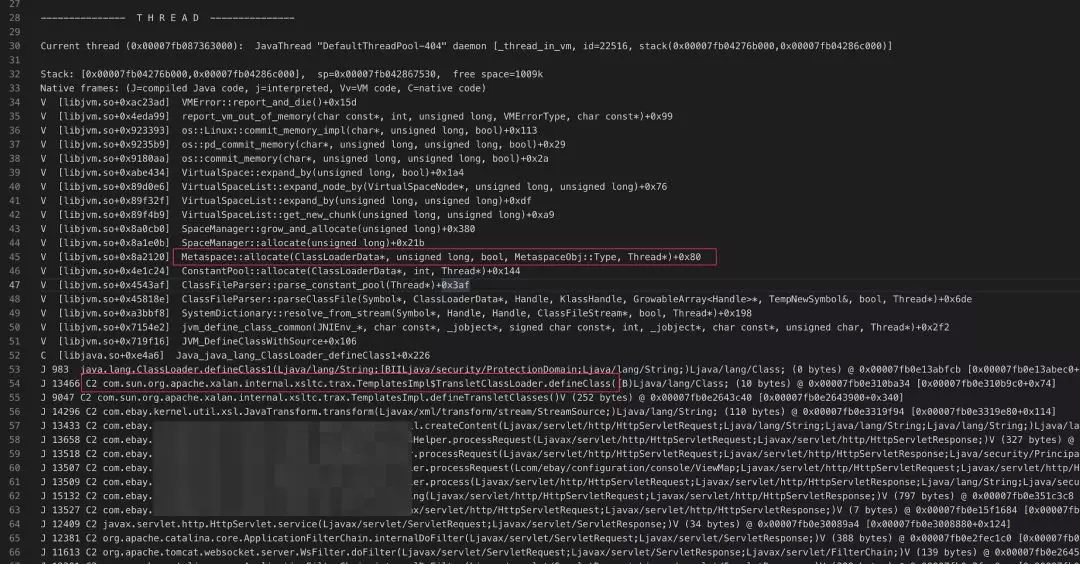
图 6(点击可查看大图)
线程栈的最底层是一些 native 代码,从中我们可以看出这正是为元数据区申请内存的线程。下面的 Java 线程栈告诉了我们这个请求是从哪里一步步进入到某个方法。其中正有我们上面查到的:
尽管这和 heap dump 分析中的一致,但并不能代表 heap dump 中的那些都是该类请求造成的,不过也确实给了我们一些提示。
接下来,我们可以根据这个线程栈给的提示,通过重现的方式去验证猜想。
四、场景重现
根据上面线程栈提供的信息,我们找出了对应的请求。根据它运行的路径,我们找出了一种特定的请求及其参数和请求数据。同时我们把相关的应用代码在本地以调试(debug)模式启动。在 TemplatesImpl$TransletClassLoader.defineClass()方法上添加断点,发现该类请求每次都创建一个新的 ClassLoader,并且这个 ClassLoader 还会创建新的 Class。
除此之外,我们还对调试服务器大量发出这种特殊请求, 用来观察 JVM 内存各个区域的使用情况.
如图 7 所示,通过 jcmd<pid>GC.heap_info 命令去查看其元数据空间的使用情况,能明显观察到它在慢慢增长。如果中间强制做一次 Full GC,能看到元数据空间被大量释放。
观察短时间内元数据空间的变化及 Full GC 后空间的变化:
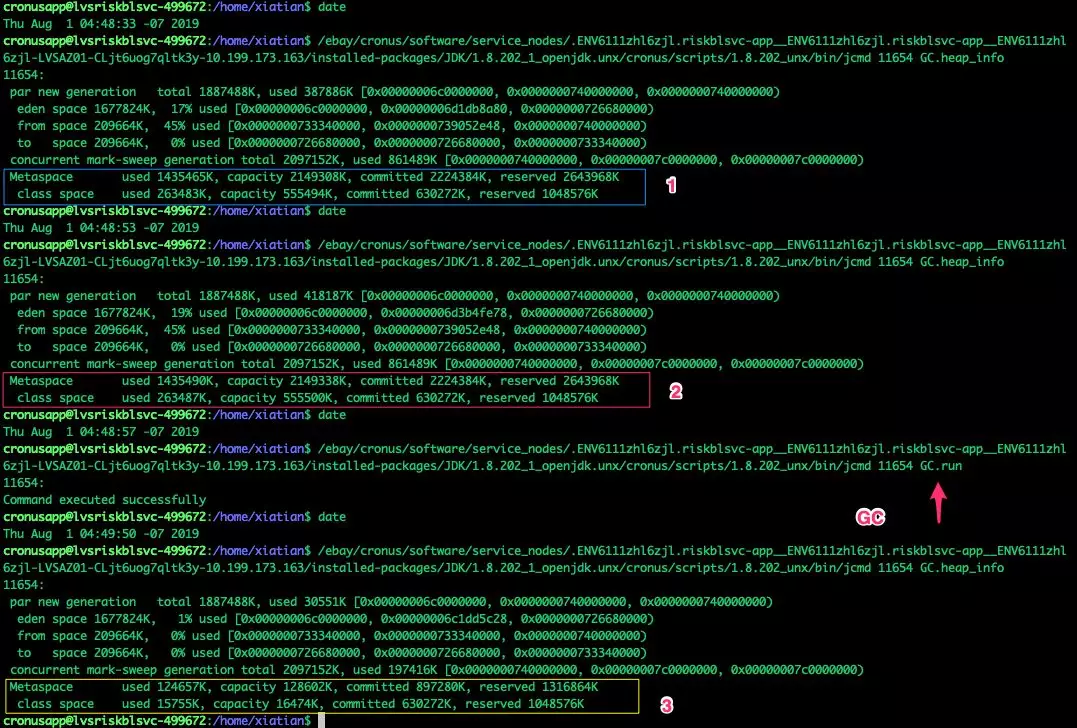
图 7(点击可查看大图)
五、代码分析
对业务逻辑代码分析发现,当这种特定的请求进来之后,处理过程中会每次创建一个 ClassLoader,而这个 ClassLoader 在仅仅创建一个相关的类之后,就永远不会被使用。久而久之,这个 ClassLoader 及相关的 Class 会越来越多。而元数据区默认使用操作系统所有可用内存,直到内存完全被耗尽。
六、解决方案
01 临时方案
通过设置 JVM 参数“-XX:MaxMetaspaceSize =***M”,可以在元数据区快要到达这个大小的时候,让 JVM 去做 Full GC 来回收元数据,这样就不会导致 OOM。这也是为什么相同的代码在使用 Java 7 的应用里没有发生该问题的原因。因为 Java 7 使用的是 PermGen(永久代),必须设置 MaxPermSize 来限定它的最大值。但缺点是该临时方案中的 Full GC 会导致较长时间的业务停顿。
02 长期方案
每次都创建一个 ClassLoader 的代码是不正确的,通过重用,让所有的请求共用一份 ClassLoader。
七、总结
从 Java 8 开始的元数据区默认是没有最大空间限制的,这是因为在 Java 代码稳定运行前,很难确定需要加载多少类,因此也就很难确定元数据区的大小。
正因为没有设置最大值,所以会有耗尽内存的潜在可能。当应用程序大概知道需要使用多少元数据的时候,为了让元数据区内存保持在合理的大小范围之内,不至于耗尽所有可用内存,可以设置以下参数:

同时,如果有自定义的 ClassLoader,一定要注意是否会创建 N 个实例,从而造成元数据空间的不断消耗。
本文转载自公众号 eBay 技术荟(ID:eBayTechRecruiting)。
原文链接: