1. 问题背景
上周线上某模块出现锁等待超时,如下图所示:
我虽然不是该模块负责人,但出于好奇,也一起帮忙排查定位问题。
这里的业务背景就是在执行到某个地方时,需要去表中插入一批数据,这批数据需要根据数据类型分配流水号。这与我的select for update引发死锁分析提到的流水号分配差不多:通过数据库悲观锁实现多实例部署的流水号生成与分配。
2. 问题排查
那么需要排查的问题很简单,为什么获取流水号的时候会发生锁等待超时?
从上面截图中的异常栈中,我们也可以看出:首先进入了带有@Transactional注解的方法,进入业务事务。而在需要分配流水号的时候通过IdManager分配流水号。
这里的getNextIdFromDb是由同一个类的getIdsBySize方法调用的,因此使用了编程式事务的方式来开启一个新事务。TransactionHelper是对Spring的TransactionTemplate的封装,callInNewTransaction方法就是使用一个传播行为为PROPAGATION_REQUIRES_NEW的TransactionTemplate。
很显然,获取流水号走的是一个很小的事务,与业务事务并没有混在一起。理论上来说不应该出现有线程锁等待超时。
那么线上锁等待超时的时间是多少呢?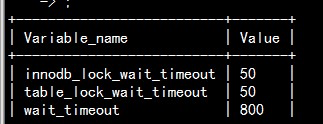
询问dba,从给出结果来看是默认的50秒。
此时,陷入僵局。这看起来很不科学,那么小的事务怎么会有线程50秒拿不到锁?线上的并发度不可能导致这样的结果。
2.1 重新搜索
联系该模块负责的同事,要了服务器host和部署路径,登上去仔细查看日志。

有一个重要的发现是,在上面的异常log前一些时候,有大量线程出现事务异常。其中包括文章一开始截图中的pool-32-thread-1,但其中有一个线程pool-8-thread-1在2018-04-12 13:21:23,066打出了事务成功的日志。
这里就产生了一个猜想,这里所有的线程都是在争取流水号表上的锁,而此刻大量的事务在大约77秒后失败,只有一个事务成功了。这并不科学,因为线上数据库的锁等待超时时间为50秒。
顺藤摸瓜,往上面搜索pool-8-thread-1的日志。
可以看到在2018-04-12 13:20:05,146的时候pool-8-thread-1已经获取到了id_record表的锁。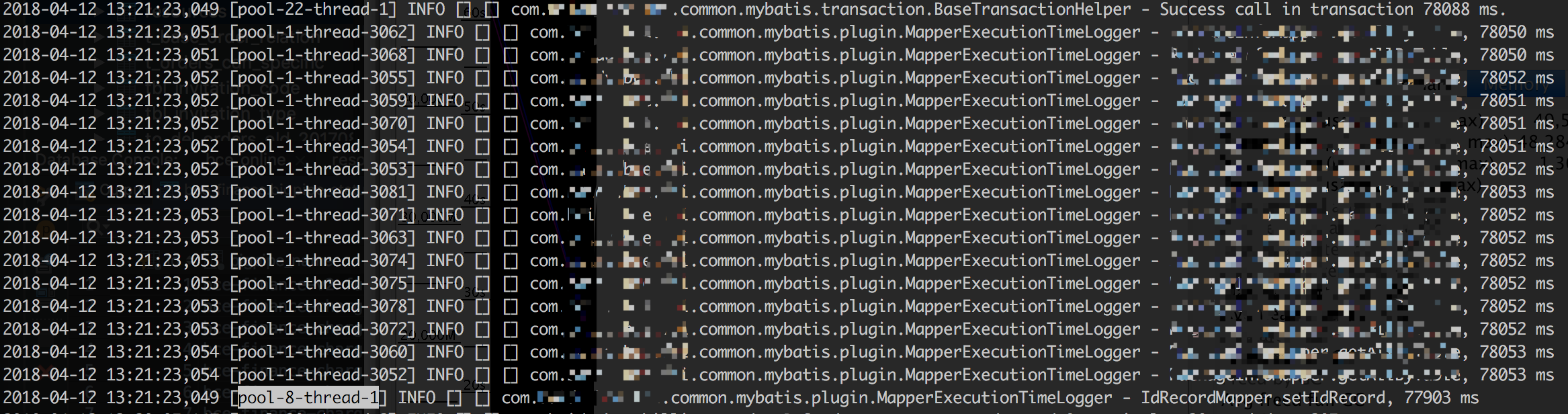
而在2018-04-12 13:21:23,049的时候,pool-8-thread-1才刚刚完成对id_record的更新。
MapperExecutionTimeLogger是项目中的mybatis拦截器,用于在日志中打印sql执行耗时。
这里发现两个问题
pool-8-thread-1更新流水号,很简单的一个sql用了将近78秒。- 大量其它线程同样耗费78秒才完成sql语句的执行。
2.2 水落石出
这78秒到底发生了什么?
继续仔细翻阅,发现有两条相邻的日志时间差了78秒左右,前一条时间戳为2018-04-12 13:20:05,147,后一条为2018-04-12 13:21:23,048。这78秒内没有任何日志。
此时,已基本可以猜到可能是Full GC,stop the world了。
通过公司的监控平台,观测该服务的堆内存使用情况如下: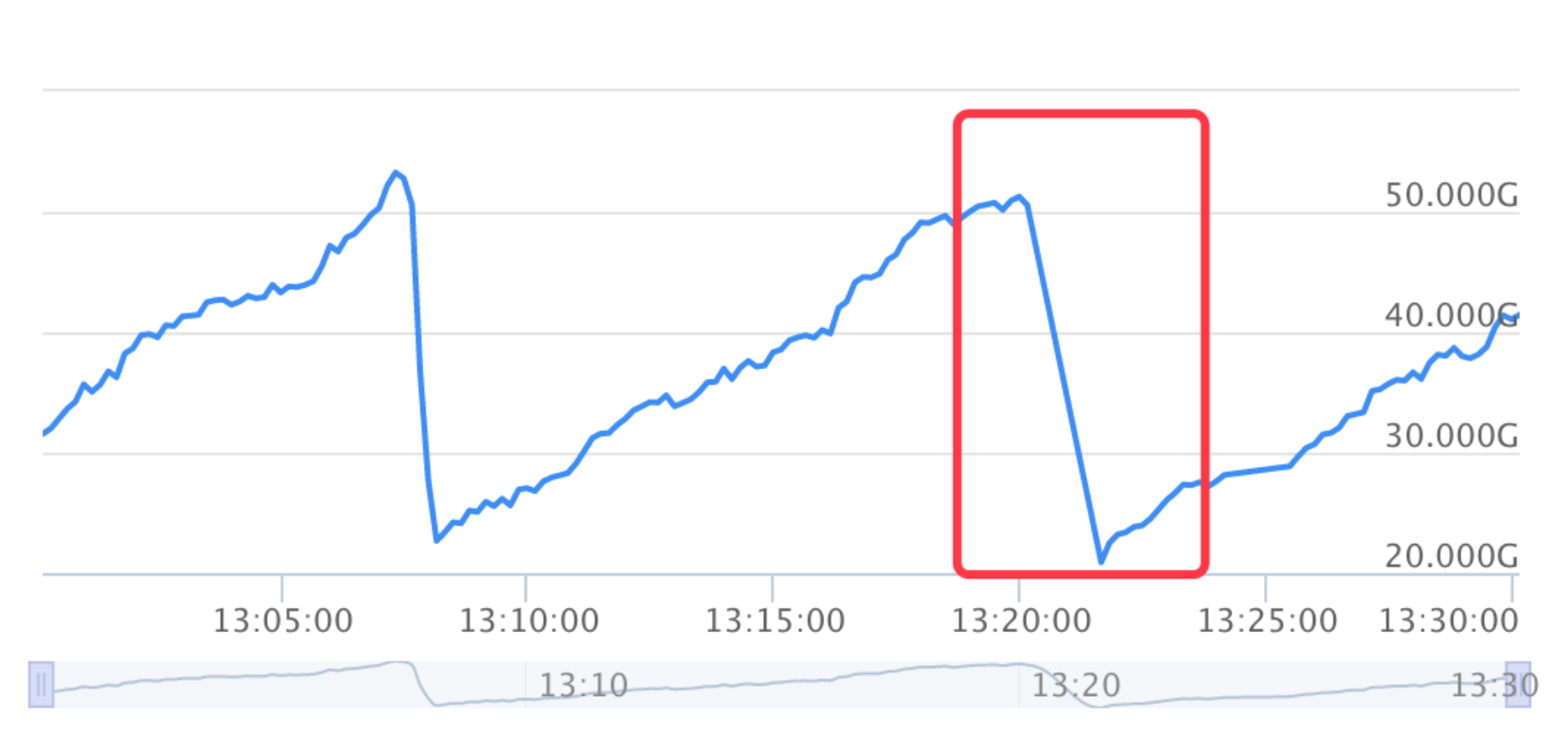
在13:20分前后确实发生了一次很夸张的Full GC:从50g清理到20g。更可怕的是从图中可以看出,Full GC的频率相当高,大约每10多分钟就要来一次。
然后登陆服务部署的服务器,翻阅GC日志,确定当时存在一次Full GC。log如下所示
2018-04-12T13:20:05.151+0800: 870750.291: [GC (Allocation Failure) 2018-04-12T13:20:05.151+0800: 870750.291: [ParNew (promotion failed): 1341118K->1337043K(1380160K), 0.6976067 secs]2018-04-12T13:20:05.849+0800: 870750.989: [CMS: 49443246K->19463735K(61381056K), 77.1977735 secs] 50784220K->19463735K(62761216K), [Metaspace: 78507K->78507K(81920K)], 77.8959574 secs] [Times: user=85.78 sys=0.13, real=77.89 secs]
复制耗时77.89秒,与前面的日志排查中种种迹象吻合。
遂紧急联系同事,告知锁等待超时原因与事务生效、表的大小都无关,乃Full GC所致,赶紧分析下GC日志调优。
3. 详细分析
导出线上的JVM参数来看:
-XX:MaxHeapSize=64424509440 最大堆大小60G
-XX:MaxNewSize=1570308096 最大新生代1.5G
-XX:MaxTenuringThreshold=6 进入老年代的前Minor GC次数
-XX:NewSize=528482304 新生代初始值大小
复制3.1 这新生代也太小了吧
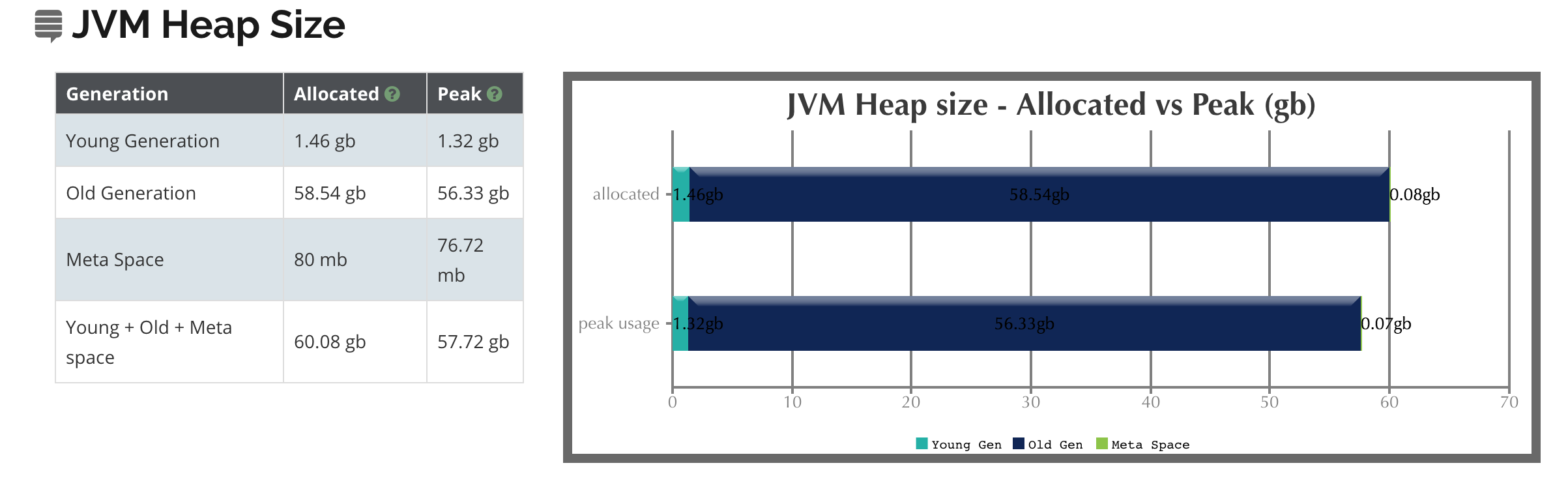
新生代:
总大小为1380160K(eden+一个survivor),其中eden区的大小为1226816K,一个survivor区的大小为153344K。
这里eden+两个survivor就构成了参数中的MaxNewSize=1570308096也就是1533504K。
老年代:
大小为61381056K。
这里已经可以看出young和old的比例非常夸张。
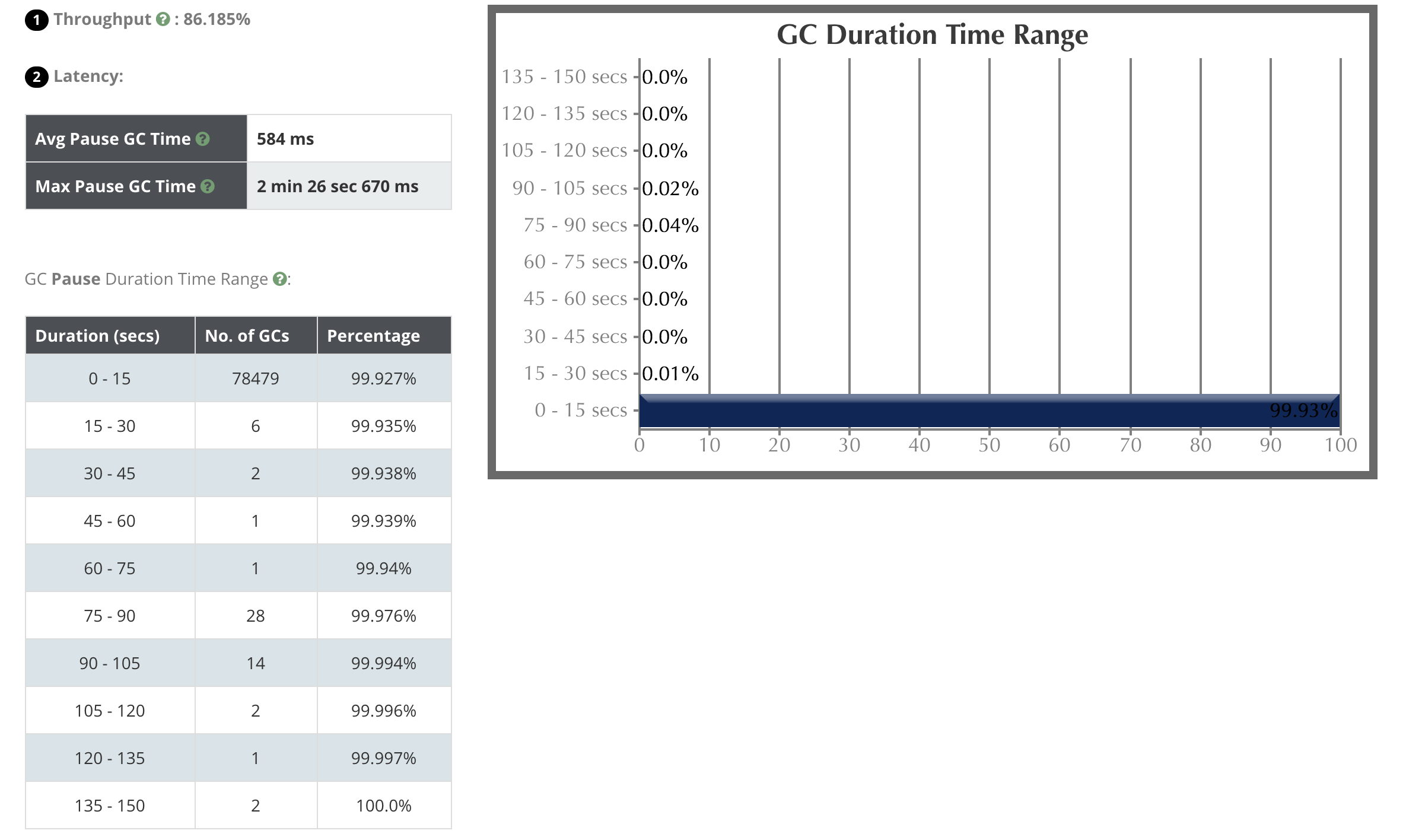
使用GCViewer工具可以分析GC日志(从2018-04-09 14:19:23到2018-04-13 10:33:33大约4天不到)。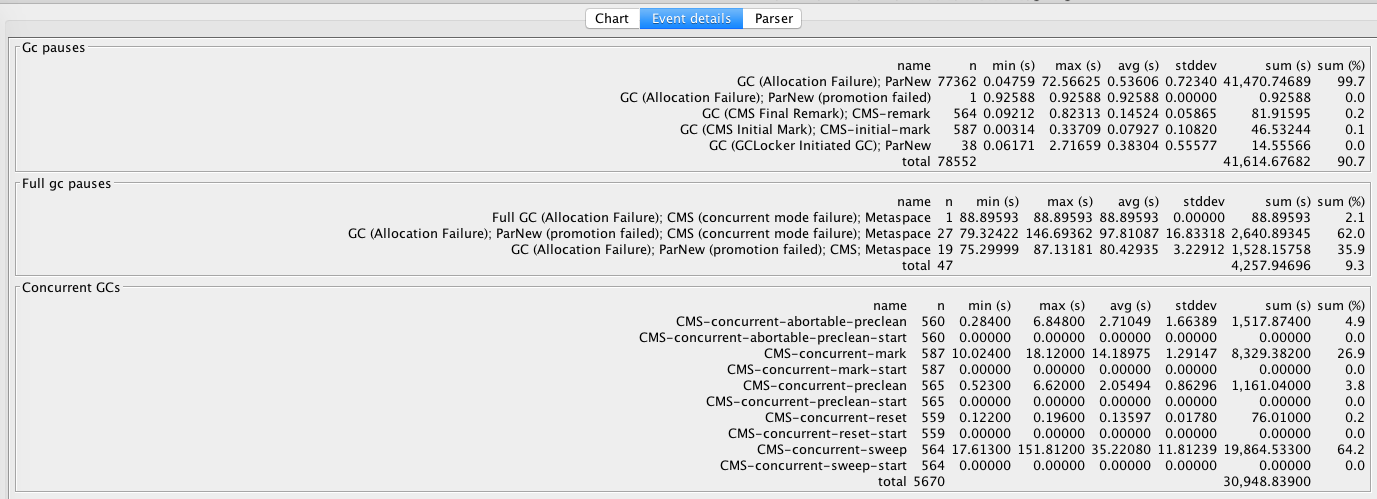
可以看到有非常多的Full GC。
再来看一下导致锁等待超时的那次Full GC。
图中黑色的柱形代表的就是Full GC,横轴表示持续时长,高度中可以对应查看差不多在75-80秒之间。
蓝色线代表了使用的堆大小。而上下两块染色区域分别表示新生代和老年代的大小,可以看到比例非常夸张
另外,推荐一个分析GC的网站,非常好用。


3.2 谁动了参数?
查看build.gradle,配置的参数如下(和jcmd pid VM.flags相同):
applicationDefaultJvmArgs = ['-Xmx60G', '-XX:MaxPermSize=512M', '-XX:+UseConcMarkSweepGC',
'-XX:+PrintGCDetails', '-XX:+PrintGCDateStamps', '-Xloggc:log/gc.log', '-XX:+UseGCLogFileRotation',
'-XX:NumberOfGCLogFiles=10', '-XX:GCLogFileSize=20M']
复制而查看gc日志,可以看到
CommandLine flags: -XX:CICompilerCount=12 -XX:GCLogFileSize=20971520 -XX:InitialHeapSize=1585446912 -XX:MaxHeapSize=64424509440 -XX:MaxNewSize=1570308096 -XX:MaxTenuringThreshold=6 -XX:MinHeapDeltaBytes=1
96608 -XX:NewSize=528482304 -XX:NumberOfGCLogFiles=10 -XX:OldPLABSize=16 -XX:OldSize=1056964608 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseConcMarkSweepGC -XX:+
UseFastUnorderedTimeStamps -XX:+UseGCLogFileRotation -XX:+UseParNewGC
复制-
-XX:MaxHeapSize
64424509440=60G,没啥问题 -
-XX:MaxNewSize
1570308096=1.46G,什么鬼
在调研之后发现,这个其实是JVM Ergonomics自动调的参数。Ergonomics是一种自适应调节策略,可以根据Java应用运行的系统自动的选择GC收集器的类型和堆大小以及工作模式(client or server),还会自动调节垃圾收集的参数。
由于我们使用了CMS收集器,所以参考hotspot中src/share/vm/runtime/arguments.cpp中void Arguments::set_cms_and_parnew_gc_flags方法: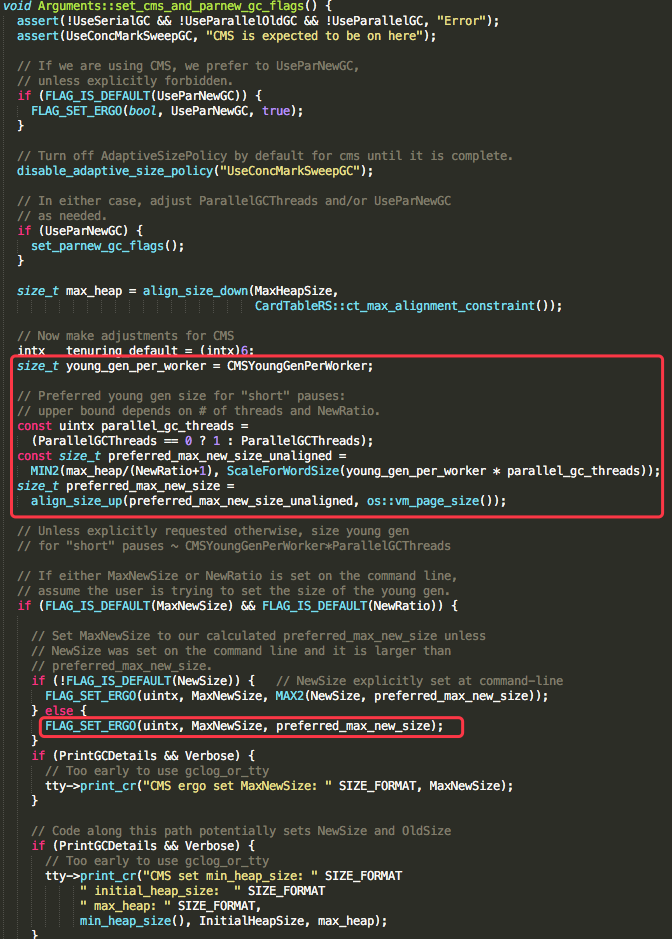
可以看到MaxNewSize的计算大致分为两步:
- preferred_max_new_size_unaligned 等于 【堆内存/3(NewRatio默认是2)】与【young_gen_per_worker(一般是67108864也就是64M)*13/10与4(HeapWordSize)作一次下对齐】
- 再将preferred_max_new_size_unaligned与 os::vm_page_size()(虚拟内存的分页大小,默认4K)作一次上对齐得到preferred_max_new_size
其中下对齐和上对齐的函数定义如下:
#define align_size_up_(size, alignment) (((size) + ((alignment) - 1)) & ~((alignment) - 1))
#define align_size_down_(size, alignment) ((size) & ~((alignment) - 1))
复制通过jinfo -flag ParallelGCThreads [pid]和jinfo -flag CMSYoungGenPerWorker [pid]确认线上服务-XX:ParallelGCThreads=18以及-XX:CMSYoungGenPerWorker=67108864
那么下面的计算就很显然了:
preferred_max_new_size_unaligned = 1570347416
preferred_max_new_size = 1570349056
MaxNewSize = preferred_max_new_size = 1570349056
复制接下去在堆初始化的时候,还会再去做一次参数调整。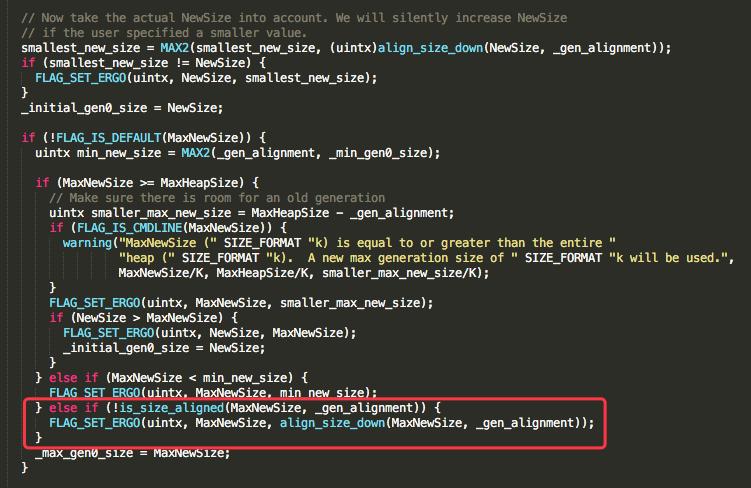
此时MaxNewSize与65536作一次下对齐,就算出最终MaxNewSize为1570308096,这与前面贴的参数一致。
说到底,其实是没有显示设置新生代大小,踩了JVM Ergonomics在使用CMS收集器时自动调参的坑,调出了一个太小的(相比整个60G的堆)新生代容量。并且MaxTenuringThreshold=6,也就是说会有两个性能问题
- 新生代太小,频繁Minor GC
- 大部分对象很快会进入老年代
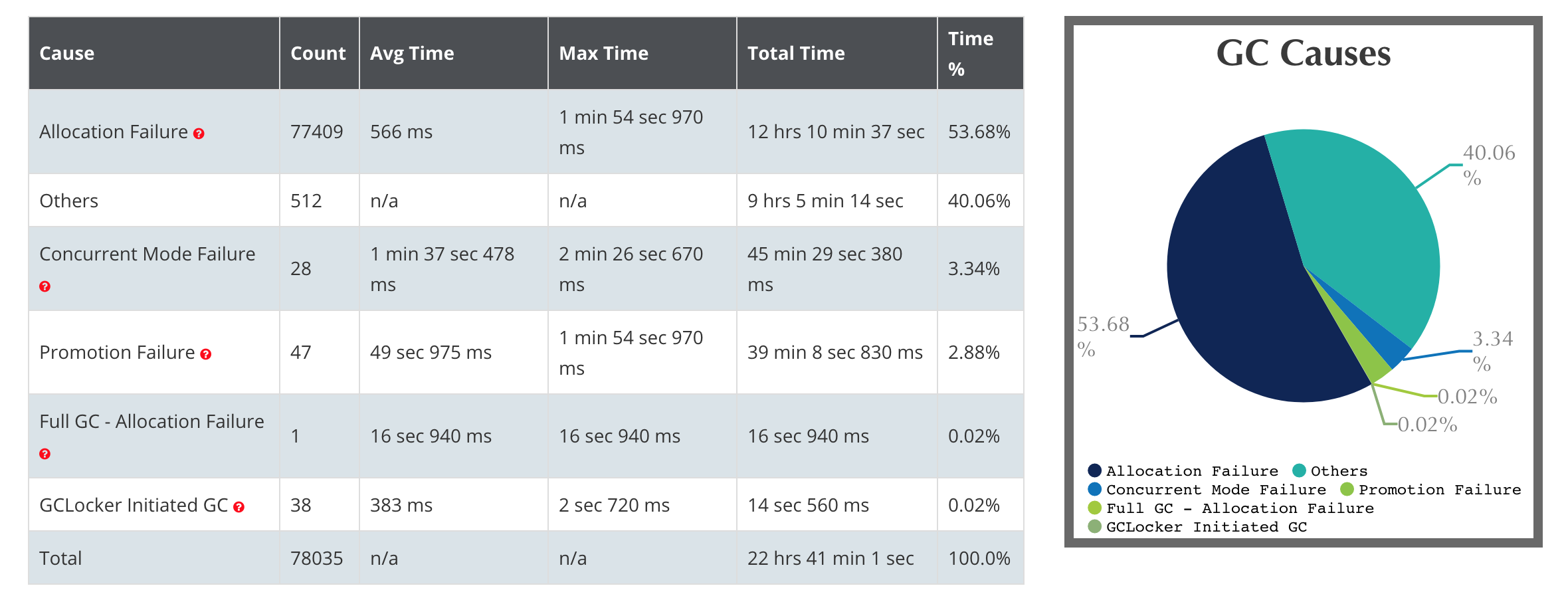
整个GC日志中出现大量的promotion failed 和concurrent mode failure。
4. 后记
模块负责人已经修改启动参数,显式指定新生代大小,并进行调优效果观察。目前已无Full GC的情况出现。
5. 总结
回顾:
现象是锁等待超时,而原因却与数据库本身表大小、流水号事务是否生效全然无关。而是由于Full GC导致。
从Full GC日志来看,出现promotion failure,原因无非两点:新生代太小survivor放不下,老年代碎片太多也放不下,触发Full GC。
再推一步,发现新生代大小实在太夸张,疑似是因为没有设置。
再往后面推,发现其实是JVM Ergonomics对于使用CMS收集器的情况下自动进行参数设定所致。
启示:
- 要关注服务的内存使用与GC情况,根据情况进行调优
- 要关注JVM启动参数,可以加上-XX:+PrintFlagsFinal观察各种参数,看看是否有参数冲突、JVM作了什么预期外的调整等