正文
ARM下KVM虚拟化的损耗验证
摘要
看Windows 上面的 Workstation的虚拟机的 网络层的延迟特别高.
突然想之前统计都是直接在本地验证的, 只考虑了虚拟化CPU的性能损耗
没有考虑虚拟化层网络层的损耗.
所以想验证完了 Windows 和 intel平台 再抓紧验证一下
ARM平台的宿主机和KVM下面的虚拟机的redis性能比较
复制
比较结果
测试命令:
虚拟机, 物理机使用类似的命令
./redis-benchmark -h 10.110.xxx.xxx -p 16379 -a xxxxx -n 200000 -c 20 -q
测试结果:
出去MSET 虚拟机比物理机性能好之外.
都是物理机比虚拟机性能好很多.
算数平均值是 95.5%
感觉KVM的损耗还是非常低的.
复制
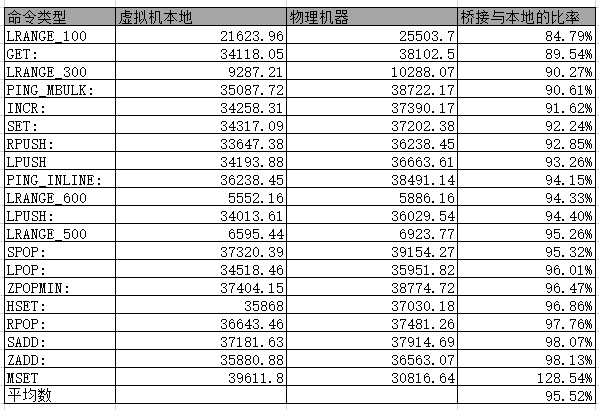
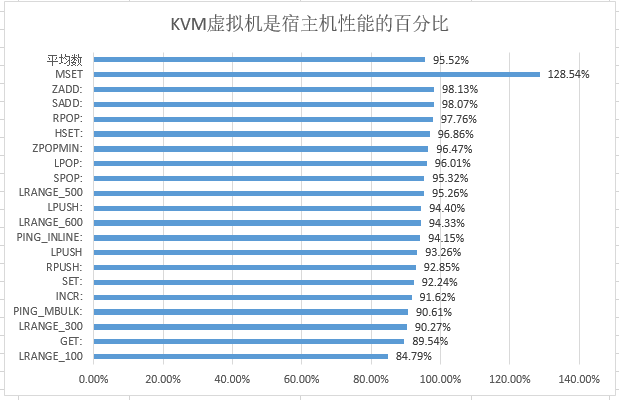
测试原始数据-物理机
PING_INLINE: 38491.14 requests per second, p50=0.455 msec
PING_MBULK: 38722.17 requests per second, p50=0.439 msec
SET: 37202.38 requests per second, p50=0.479 msec
GET: 38102.50 requests per second, p50=0.479 msec
INCR: 37390.17 requests per second, p50=0.487 msec
LPUSH: 36029.54 requests per second, p50=0.503 msec
RPUSH: 36238.45 requests per second, p50=0.503 msec
LPOP: 35951.82 requests per second, p50=0.503 msec
RPOP: 37481.26 requests per second, p50=0.479 msec
SADD: 37914.69 requests per second, p50=0.479 msec
HSET: 37030.18 requests per second, p50=0.487 msec
SPOP: 39154.27 requests per second, p50=0.463 msec
ZADD: 36563.07 requests per second, p50=0.495 msec
ZPOPMIN: 38774.72 requests per second, p50=0.463 msec
LPUSH (needed to benchmark LRANGE): 36663.61 requests per second, p50=0.495 msec
LRANGE_100 (first 100 elements): 25503.70 requests per second, p50=0.575 msec
LRANGE_300 (first 300 elements): 10288.07 requests per second, p50=1.023 msec
LRANGE_500 (first 500 elements): 6923.77 requests per second, p50=1.455 msec
LRANGE_600 (first 600 elements): 5886.16 requests per second, p50=1.711 msec
MSET (10 keys): 30816.64 requests per second, p50=0.591 msec
复制
测试原始数据-虚拟机
PING_INLINE: 36238.45 requests per second, p50=0.439 msec
PING_MBULK: 35087.72 requests per second, p50=0.463 msec
SET: 34317.09 requests per second, p50=0.479 msec
GET: 34118.05 requests per second, p50=0.479 msec
INCR: 34258.31 requests per second, p50=0.471 msec
LPUSH: 34013.61 requests per second, p50=0.487 msec
RPUSH: 33647.38 requests per second, p50=0.479 msec
LPOP: 34518.46 requests per second, p50=0.479 msec
RPOP: 36643.46 requests per second, p50=0.479 msec
SADD: 37181.63 requests per second, p50=0.471 msec
HSET: 35868.00 requests per second, p50=0.487 msec
SPOP: 37320.39 requests per second, p50=0.471 msec
ZADD: 35880.88 requests per second, p50=0.487 msec
ZPOPMIN: 37404.15 requests per second, p50=0.471 msec
LPUSH (needed to benchmark LRANGE): 34193.88 requests per second, p50=0.495 msec
LRANGE_100 (first 100 elements): 21623.96 requests per second, p50=0.591 msec
LRANGE_300 (first 300 elements): 9287.21 requests per second, p50=1.159 msec
LRANGE_500 (first 500 elements): 6595.44 requests per second, p50=1.567 msec
LRANGE_600 (first 600 elements): 5552.16 requests per second, p50=1.831 msec
MSET (10 keys): 39611.80 requests per second, p50=0.415 msec
复制