https://zhuanlan.zhihu.com/p/613592552
针对HotSpot VM的实现,它里面的GC按照回收区域又分为两大种类型:一种是部分收集(Partial GC),一种是整堆收集(Full GC)
GC日志大概可以分成两类:MinorGC(或Young GC或YGC)日志和Full GC日志。


/**
* 在jdk7 和 jdk8中分别执行
* -verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8 -XX:+UseSerialGC
*/
public class GCLogTest1 {
private static final int _1MB = 1024 * 1024;
public static void testAllocation() {
byte[] allocation1, allocation2, allocation3, allocation4;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[2 * _1MB];
allocation4 = new byte[4 * _1MB];
}
public static void main(String[] agrs) {
testAllocation();
}
}JDK7 中的情况
1、首先我们会将3个2M的数组存放到Eden区,然后后面4M的数组来了后,将无法存储,因为Eden区只剩下2M的剩余空间了,那么将会进行一次Young GC操作,将原来Eden区的内容,存放到Survivor区,但是Survivor区也存放不下,那么就会直接晋级存入Old 区

2、然后我们将4M对象存入到Eden区中
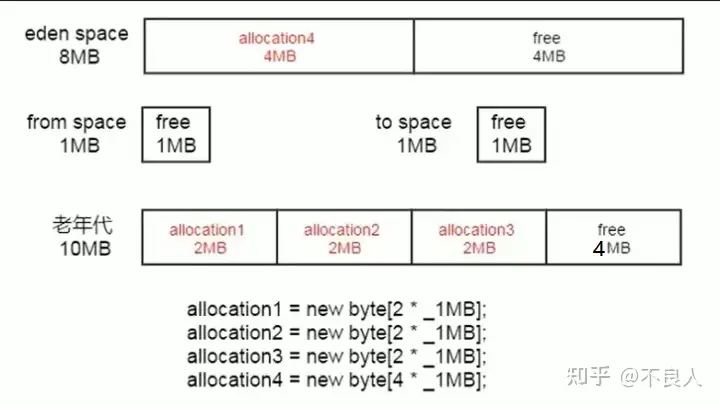
JDK8 中的情况
com.atguigu.java.GCLogTest1
[GC (Allocation Failure) [DefNew: 6322K->668K(9216K), 0.0034812 secs] 6322K->4764K(19456K), 0.0035169 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K, used 7050K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 77% used [0x00000000fec00000, 0x00000000ff23b668, 0x00000000ff400000)
from space 1024K, 65% used [0x00000000ff500000, 0x00000000ff5a71d8, 0x00000000ff600000)
to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
tenured generation total 10240K, used 4096K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 40% used [0x00000000ff600000, 0x00000000ffa00020, 0x00000000ffa00200, 0x0000000100000000)
Metaspace used 3469K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 381K, capacity 388K, committed 512K, reserved 1048576K
Process finished with exit code 0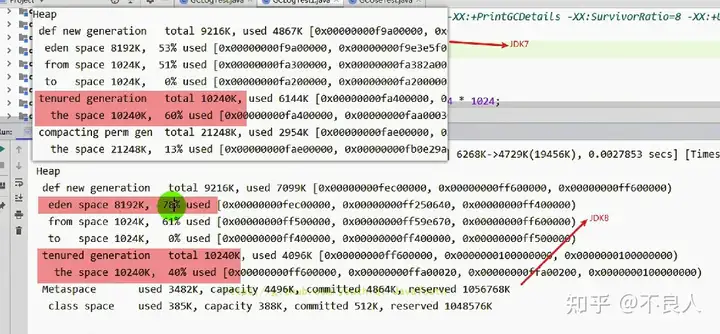
与 JDK7 不同的是,JDK8 直接判定 4M 的数组为大对象,直接怼到老年区去了
可以用一些常用的工具分析保存下来的GC日志:GCViewer、GCEasy、
GCEasy:GCEasy是一款在线的GC日志分析器,可以通过GC日志分析进行内存泄露检测、GC暂停原因分析、JVM配置建议优化等功能,大多数功能是免费的。
GCViewer:GCViewer是一款离线的GC日志分析器,用于可视化Java VM选项 -verbose:gc 和 .NET生成的数据 -Xloggc:<file>。还可以计算与垃圾回收相关的性能指标(吞吐量、累积的暂停、最长的暂停等)。当通过更改世代大小或设置初始堆大小来调整特定应用程序的垃圾回收时,此功能非常有用。
还有一些其他的分析工具,如GCHisto、GCLogViewer、Hpjmeter、garbagecat等等,这里不一一列举。
-XX:+PrintGC: 输出GC日志。类似:java -verbose:gc-XX:+PrintGCDetails : 输出GC的详细日志-XX:+PrintGCTimestamps : 输出GC的时间戳(以基准时间的形式)-XX:+PrintGCDatestamps : 输出GcC的时间戳(以日期的形式,如2013-05-04T21:53:59.234+0800)-XX:+PrintHeapAtGC: 在进行GC的前后打印出堆的信息-Xloggc:../logs/gc.log: 日志文件的输出路径类似:java -verbose:gc,这个只会显示总的GC堆的变化,如下:
[GC (Allocation Failure) 80832K->19298K(227840K),0.0084018 secs]
[GC (Metadata GC Threshold) 109499K->21465K(228352K),0.0184066 secs]
[Full GC (Metadata GC Threshold) 21465K->16716K(201728K),0.0619261 secs]参数解析:
GC、Full GC:GC的类型,GC只在新生代上进行,Full GC包括永生代,新生代,老年代。
Allocation Failure:GC发生的原因。
80832K->19298K:堆在GC前的大小和GC后的大小。
228840k:现在的堆大小。
0.0084018 secs:GC持续的时间。输出GC的详细日志:
[GC (Allocation Failure) [PSYoungGen:70640K->10116K(141312K)] 80541K->20017K(227328K),0.0172573 secs] [Times:user=0.03 sys=0.00,real=0.02 secs]
[GC (Metadata GC Threshold) [PSYoungGen:98859K->8154K(142336K)] 108760K->21261K(228352K),0.0151573 secs] [Times:user=0.00 sys=0.01,real=0.02 secs]
[Full GC (Metadata GC Threshold)[PSYoungGen:8154K->0K(142336K)]
[ParOldGen:13107K->16809K(62464K)] 21261K->16809K(204800K),[Metaspace:20599K->20599K(1067008K)],0.0639732 secs]
[Times:user=0.14 sys=0.00,real=0.06 secs]参数解析:
GC,Full FC:同样是GC的类型
Allocation Failure:GC原因
PSYoungGen:使用了Parallel Scavenge并行垃圾收集器的新生代GC前后大小的变化
ParOldGen:使用了Parallel Old并行垃圾收集器的老年代GC前后大小的变化
Metaspace: 元数据区GC前后大小的变化,JDK1.8中引入了元数据区以替代永久代
xxx secs:指GC花费的时间
Times:user:指的是垃圾收集器花费的所有CPU时间,sys:花费在等待系统调用或系统事件的时间,real:GC从开始到结束的时间,包括其他进程占用时间片的实际时间。显示GC的时间信息,例如打开如下的日志配置:
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimestamps -XX:+PrintGCDatestamps输出信息如下:
2019-09-24T22:15:24.518+0800: 3.287: [GC (Allocation Failure) [PSYoungGen:136162K->5113K(136192K)] 141425K->17632K(222208K),0.0248249 secs] [Times:user=0.05 sys=0.00,real=0.03 secs]
2019-09-24T22:15:25.559+0800: 4.329: [GC (Metadata GC Threshold) [PSYoungGen:97578K->10068K(274944K)] 110096K->22658K(360960K),0.0094071 secs] [Times: user=0.00 sys=0.00,real=0.01 secs]
2019-09-24T22:15:25.569+0800: 4.338: [Full GC (Metadata GC Threshold) [PSYoungGen:10068K->0K(274944K)][ParoldGen:12590K->13564K(56320K)] 22658K->13564K(331264K),[Metaspace:20590K->20590K(1067008K)],0.0494875 secs] [Times: user=0.17 sys=0.02,real=0.05 secs]说明:带上了日期。
如果想把GC日志存到文件的话,是下面的参数:
-Xloggc:/path/to/gc.log[GC和[Full GC说明了这次垃圾收集的停顿类型,如果有Full则说明GC发生了"Stop The World"
Serial收集器在新生代的名字是Default New Generation,因此显示的是[DefNewParNew收集器在新生代的名字会变成[ParNew,意思是Parallel New GenerationParallel Scavenge收集器在新生代的名字是[PSYoungGenParallel Old收集器收集器在老年代显示[ParoldGen"G1收集器的话,会显示为garbage-first heapGC日志格式的规律一般都是:GC前内存占用->GC后内存占用(该区域内存总大小)
[PSYoungGen:5986K->696K(8704K) ] 5986K->704K(9216K)
- 中括号内:GC回收前年轻代大小,回收后大小,(年轻代总大小)
- 括号外:GC回收前年轻代和老年代大小,回收后大小,(年轻代和老年代总大小) 注意:Minor GC堆内存总容量 = 9/10 年轻代 + 老年代。原因是Survivor区只计算from部分,而JVM默认年轻代中Eden区和Survivor区的比例关系,Eden:S0:S1=8:1:1。
GC日志中有三个时间:user,sys和real
由于多核的原因,一般的GC事件中,real time是小于sys time+user time的,因为一般是多个线程并发的去做GC,所以real time是要小于sys+user time的。如果real>sys+user的话,则你的应用可能存在下列问题:IO负载非常重或CPU不够用。
简单来说就是,user代表用户态回收耗时,sys内核态回收耗时,rea实际耗时。由于多核的原因,时间总和可能会超过real时间。
日志分析例子:
Heap(堆)
PSYoungGen(Parallel Scavenge收集器新生代)total 9216K,used 6234K [0x00000000ff600000,0x0000000100000000,0x0000000100000000)
eden space(堆中的Eden区默认占比是8)8192K,768 used [0x00000000ff600000,0x00000000ffc16b08,0x00000000ffe00000)
from space(堆中的Survivor,这里是From Survivor区默认占比是1)1024K, 0% used [0x00000000fff00000,0x00000000fff00000,0x0000000100000000)
to space(堆中的Survivor,这里是to Survivor区默认占比是1,需要先了解一下堆的分配策略)1024K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000)
ParOldGen(老年代总大小和使用大小)total 10240K, used 7001K [0x00000000fec00000,0x00000000ff600000,0x00000000ff600000)
object space(显示个使用百分比)10240K,688 used [0x00000000fec00000,0x00000000ff2d6630,0x00000000ff600000)
PSPermGen(永久代总大小和使用大小)total 21504K, used 4949K [0x00000000f9a00000,0x00000000faf00000,0x00000000fec00000)
object space(显示个使用百分比,自己能算出来)21504K, 238 used [0x00000000f9a00000,0x00000000f9ed55e0,0x00000000faf00000)