https://zhuanlan.zhihu.com/p/612752963?utm_id=0复制
最近,FacebookResearch 开源了他们最新的大规模语言模型 LLaMA,包含从 7B 到 65B 的参数范围,训练使用多达 14,000 亿 tokens 语料。其中,LLaMA-13B 在大部分基准测评上超过了 GPT3(175B),与目前最强的语言模型 Chinchilla-70B 和 PaLM-540B 相比,LLaMA-65B 也具有竞争力。因此,LLaMA 可能是目前公开模型权重中效果最好的语言模型。
论文:https://arxiv.org/abs/2302.13971
代码:https://github.com/facebookresearch/llama
在论文中,作者针对常识推理、问答、数学推理、代码生成、语言理解等能力对 LLaMA 进行了评测。结果显示,LLaMA 以相对少量的参数获得了媲美超大模型的效果,这对 NLP 社区的研究者们更加友好,因为它可以在单个 GPU 上运行。开源代码提供 LLaMA 的文本生成示例,可以直接用于一些 Zero/Few-Shot Learning 任务。也有许多用户关心如何使用自己的数据微调或增量训练LLaMA模型,然而Facebook目前还没有提供对应的训练代码。在本文中,我们介绍如何基于 TencentPretrain 预训练框架训练 LLaMA 模型。
TencentPretrain 是 UER-py 预训练框架的多模态版本,支持 BERT、GPT、T5、ViT、Dall-E、Speech2Text 等模型,支持文本、图像和语音模态预训练及下游任务。TencentPretrain 基于模块化设计,用户可以通过模块组合的方式构成各种模型,也可以通过复用已有的模块进行少量修改来实现新的模型。例如,LLaMA 的模型架构基于 Transformer 有三项改动:
得益于模块化特性,我们在 TencentPretrain 中基于 GPT2 模型的已有模块,仅添加约 100 行代码就能实现以上三个改动从而训练 LLaMA 模型。具体的使用步骤为:
git clone https://github.com/Tencent/TencentPretrain.git复制2. 下载 LLaMA 模型权重(7B),可以向 FacebookResearch 申请模型,或者从 Huggingface 社区获取;将模型权重转换为 TencentPretrain 格式
cd TencentPretrain
python3 scripts/convert_llama_to_tencentpretrain.py --input_model_path $LLaMA_7B_FOLDER/consolidated.00.pth --output_model_path models/llama-7b.bin --layers_num 32复制3. 调整配置文件
将 tencentpretrain/utils/constants.py 文件中 L4: special_tokens_map.json 修改为 llama_special_tokens_map.json
4. 语料预处理:使用项目自带的语料作为演示,也可以使用相同格式的语料进行替换
python3 preprocess.py --corpus_path corpora/book_review.txt --spm_model_path $LLaMA_7B_FOLDER/tokenizer.model \
--dataset_path dataset.pt --processes_num 8 --data_processor lm复制5. 启动训练,以8卡为例
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_config.json \
--pretrained_model_path models/llama-7b.bin \
--dataset_path dataset.pt --spm_model_path $LLaMA_7B_FOLDER/tokenizer.model \
--config_path models/llama/7b_config.json \
--output_model_path models/output_model.bin \
--world_size 8 --learning_rate 1e-4 \
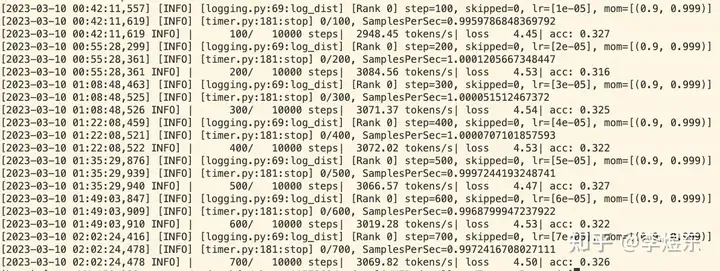
--data_processor lm --total_steps 10000 --save_checkpoint_steps 2000 --batch_size 24复制启动训练后,可以看到模型的 loss 和准确率:
类似 facebookresearch/llama ,TencentPretrain 也提供语言模型推理代码。例如,使用单卡进行 LLaMA-7B 推理,prompt 在文件beginning.txt 中:
python3 scripts/generate_lm.py --load_model_path models/llama-7b.bin --spm_model_path $LLaMA_7B_FOLDER/tokenizer.model \
--test_path beginning.txt --prediction_path generated_sentence.txt \
--config_path models/llama/7b_config.json 复制
开源的 LLaMA 模型在预训练阶段主要基于英语训练,也具有一定的多语言能力,然而由于它没有将中文语料加入预训练,LLaMA在中文上的效果很弱。利用 TencentPretrain 框架,用户可以使用中文语料增强 LLaMA 的中文能力,也可以将它微调成垂直领域模型。
目前,TencentPretrain 只支持 LLaMA-7B 训练,我们将会持续改进以支持所有规模的 LLaMA 模型训练/微调并分享更多实验结果。欢迎大家分享使用 TencentPretrain 训练的模型权重或提交 Pull Request 贡献代码。
其他预训练模型权重例如中文 BERT、GPT、T5 等可以在我们的 Model Zoo 或者 Huggingface 仓库下载。
更新:LLaMA中文权重以及对话模型
