https://zhuanlan.zhihu.com/p/603709081复制
先看下GPT的发展时间线
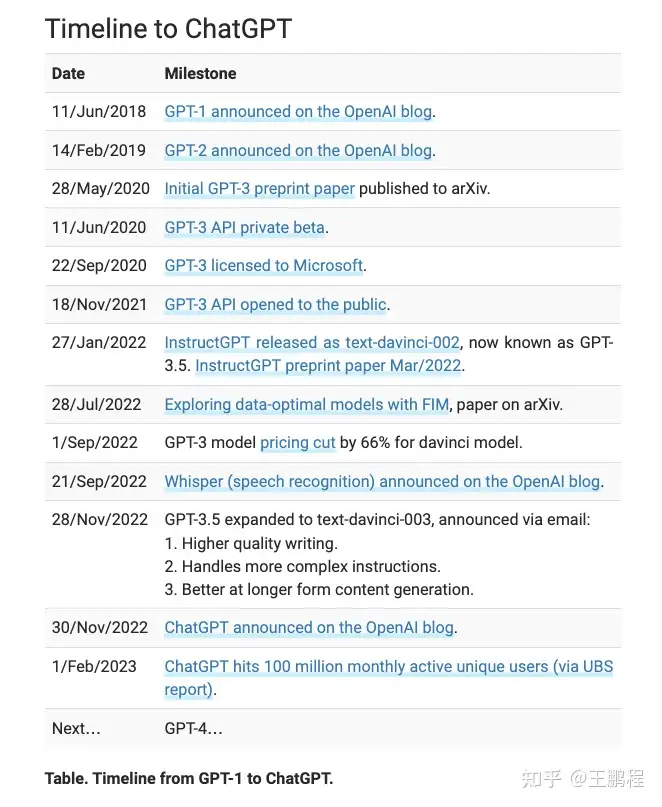
InstructGPT(2022 年 1 月)是一系列 GPT-3 模型(包括 text-davinci-001、text-davinci-002 和 text-davinci-003)统称,于GPT-3相比,它的最大不同是针对人类指令(reinforcement learning with human feedback, RLHF)进行了微调 ; InstructGPT 产生的幻觉更少,更真实,但它在生成的多样性或者说创意上相对更差,因为它们试图在“对齐”的前提下,将人类偏好/价值观硬塞进原始数据模型中。
ChatGPT(2022 年 11 月)更进一步。 为了训练 ChatGPT,OpenAI 对 InstructGPT 对话模型进行了微调(马斯克在Twitter上指出openai 使用了Twitter 数据)。 这种微调在一定程度上也是可以的。 区别在于使用的policy and reward model
我们可以先看下 DeepMind 如何构建policy和reward model,然后训练出的 Sparrow 70B取得了和 ChatGPT 相同的结果。下面列出了 DeepMind 用来让聊天机器人符合研究目标的 23 条规则:
http://lifearchitect.ai/sparrow/
OpenAI 也在做同样的事情,他们没有发表论文,但他们博客文章中的图表非常清楚了
也就是说,每次你向 ChatGPT 提出问题或发出提示时,输出只能与类似于上述的规则对齐(除非你找到一些对抗性入口点!)
ChatGPT 的输出更符合人类(这是重点!!!)但不如两年半前(2020 年 5 月)的原始 davinci 有用。感兴趣的朋友可以自己进行比较试试:chat.openai.com (ChatGPT) vs Leta Prompt (davinci classic)。
因此,总结一下,两者的主要区别如下:
参考:
- GPT-3.5 + ChatGPT: An illustrated overview
- Difference between ChatGPT and the new davinci 3 model?
- Which model is smarter: ChatGPT or Davinci-003?
- OpenAI InstructGPT paper (Mar/2022)