开源指令数据集
斯坦福数据
斯坦福52K英文指令数据:https://github.com/tatsu-lab/stanford_alpaca
52K 条指令中的每一条都是唯一的,答案由text-davinci-003模型生成得到的。
斯坦福52K中文指令数据:https://github.com/carbonz0/alpaca-chinese-dataset
与原始alpaca数据json格式相同,数据生成的方法是机器翻译和self-instruct。
斯坦福52K中文指令数据:https://github.com/hikariming/alpaca_chinese_dataset
经过人工精调的中文对话数据集,加入除了alpaca之外的其他中文聊天对话 人工微调,部分并不中文化的问题,我们将重新询问chatgpt或文心一言,重新获取回答并覆盖掉alpaca的回答.
基于GPT4的斯坦福英文数据及中文数据
基于GPT4生成的斯坦福52K指令数据,后用ChatGPT翻译得到的中文数据:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
链家数据
BELLE Group Dataset:https://huggingface.co/datasets?sort=downloads&search=BELLE+Group
链家基于ChatGPT用self-instruct生成的中文指令数据集,其中还包括中文数学题数据和多轮对话数据。由于数据是模型生成的,未经过严格校验!
BELLE项目生成的中文指令数据:https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
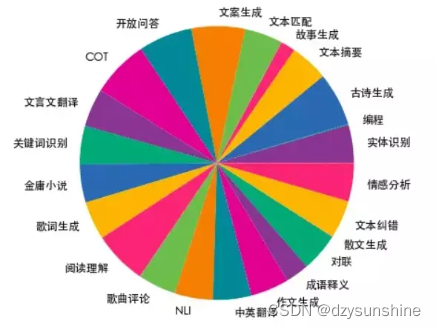
生成方式基于种子prompt,调用openai的api生成中文指令。包含了23个常见的中文数据集,对于每个任务,由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为115万 。数据分布如下图所示:
https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
包含约50万条由BELLE项目生成的中文指令数据。
多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
Baize(基于少量种子问题的对话数据)
Baize:使用少量“种子问题”,让 ChatGPT 自己跟自己聊天,并自动收集成高质量多轮对话数据集;加州大学圣迭戈分校(UCSD)与中山大学、MSRA合作团队把使用此法收集的数据集开源。
https://github.com/project-baize/baize-chatbot
垂直领域数据集
医疗领域的英文数据
chatDoctor:https://github.com/Kent0n-Li/ChatDoctor
HealthCareMagic-100k:来自 HealthCareMagic.com的患者和医生之间的 100k 真实对话。
icliniq-10k:来自icliniq.com的 10k 患者和医生之间的真实对话。
5K生成数据:5k 从 ChatGPT生成的GenMedGPT-5k和疾病数据库生成患者和医生之间的对话。
医疗领域的中文数据
Med-ChatGLM:https://github.com/SCIR-HI/Med-ChatGLM/tree/main/data
通过医学知识图谱和GPT3.5 API构建了中文医学指令数据集。
法律领域中文数据
中国法律数据资源,由上海交大收集和整理:https://github.com/pengxiao-song/awesome-chinese-legal-resources
COIG数据集(可商用的中文数据集)
https://hub.baai.ac.cn/view/25750
第一期总共发布了 5 个子数据集,包括翻译指令、考试指令、人类价值观对齐指令、反事实修正多轮聊天、Leetcode指令,总计 191k 数据,聚焦中文语料、数据类型多样、经过了人工质检与修正、数据质量可靠,而且可以商用。
论文标题:
Chinese Open Instruction Generalist: a Preliminary Release
论文机构:
北京智源人工智能研究院等
论文链接:
https://arxiv.org/pdf/2304.07987.pdf
数据链接:
https://huggingface.co/datasets/BAAI/COIG