正文
关于SPEC2006CPU和RedisBenchmark的理解
最近研究过硬件CPU的性能和Redis这样单线程重IO服务
突然想对比一下CPU算力提升占Redis性能提升的比率情况
性能很大程度由CPU决定,但是其他部分的提升也会有一些促进作用.
比如内存带宽,IO调度算法优化等.
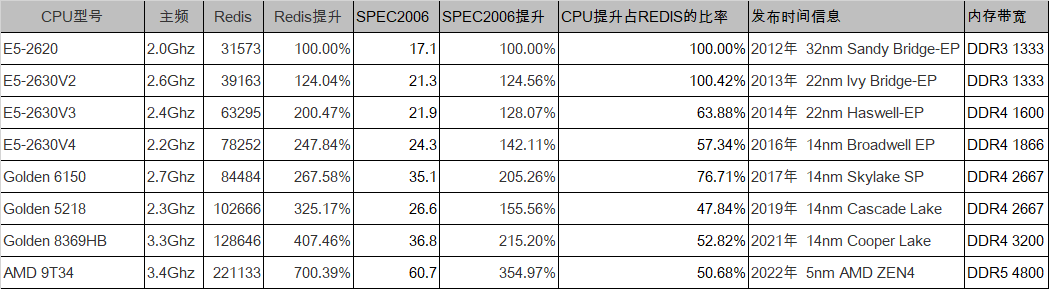
最近发现使用完全相同的SPECCPU2006进行计算的结果与redisbenchmark的结果其实并不是严格对应的.
所以进行了一下简单对比.发现一些小规律.
1. Intel的至强v1到v4世代的性能提升其实很慢.
因为AMD没有一战之力,导致Intel疯狂挤牙膏.
2. 当时的架构-制程的更新模式里面.制程升级带来的更多的是能耗而不是性能.
架构升级能够带来更多的IPC提升和性能优化.
3. 进入至强可扩展阶段后. Intel CPU因为有AMD ZEN家族的压力性能提升明显
但是三代可扩展依旧无法打赢ZEN4 EPYC
4. SPEC的提升占Redis benchmark的提升越来越少. 认为内存带宽以及其他
架构优化的提升能够比算力的提升带来更多的收益.
5. 国产CPU的比相同值的IntelCPU的benchmark值要低一点.还是有很大需要优化的路要走.
测试结果-SPEC
| CPU型号 |
主频 |
测试平均数 |
CPU信息 |
| E5-2620 |
2.0Ghz |
17.1 |
2012年 32nm Sandy Bridge-EP 物理机 |
| E5-2630V2 |
2.6Ghz |
21.3 |
2013年 22nm Ivy Bridge-EP 虚拟化平台 CentOS7有超售 |
| E5-2630V3 |
2.4Ghz |
21.9 |
2014年 22nm Haswell-EP 虚拟化平台 CentOS8有超售 |
| E5-2630V4 |
2.2Ghz |
24.3 |
2016年 14nm Broadwell EP 虚拟化平台 CentOS8 |
| Golden 5118 |
2.3Ghz |
28.7 |
2017年 14nm Skylake SP CentOS7物理机 |
| Golden 6150 |
2.7Ghz |
35.1 |
2017年 14nm Skylake SP CentOS8 |
| Golden 5218 |
2.3Ghz |
26.6 |
2019年 14nm Cascade Lake CentOS8 虚拟机SSD |
| Golden 8369HB |
3.3Ghz |
36.8 |
2021年 14nm Cooper Lake-SP CentOS8 阿里云 |
| AMD 9T34 |
3.4Ghz |
60.7 |
2022年Q4 5nm AMD ZEN4 CentOS8 阿里云 |
执行命令
cd /speccpu2006-v1.0.1/ && source shrc && bin/relocate && nohup runspec --reportable -c x86.cfg -n 1 -r 1 --tuning base int &
国产化的-SPEC
| CPU型号 |
主频 |
测试平均数 |
CPU信息 |
| 飞腾 2500 |
2.1Ghz |
13.3 |
飞腾最新CPU,双路128核心1T内存 |
| 海光7285 |
2.5Ghz |
25 |
中科曙光AMD ZEN1架构. 14nm 三星 |
| 鲲鹏920 |
2.6Ghz |
27.8 |
华为2019年发布 双路128核心1T内存 台积电7nm |
| 倚天710 |
2.7Ghz |
52 |
阿里平头哥2022年发布ArmV9.0 单路支持128核心 台积电5nm |
Redis benchmark与SPEC2006的结果总图