一.什么是RDMA
1.RDMA主要体现
2.如何理解RDMA和TCP技术的区别?
3.使用RDMA的好处包括:
二.什么是RoCE?
1. RDMA协议包含:
Infiniband(IB)
2. 为什么RoCE是目前主流的RDMA协议?
RoCEv1
RoCEv2
RoCE,无损先行
一.什么是RDMA
RDMA(Remote Direct Memory Access),全称远端内存直接访问技术,可以在极少占用CPU的情况下,把数据从一台服务器传输到另一台服务器,或从存储到服务器。
传统应用要发送数据,需要通过OS封装TCP/IP,然后依次经过主缓存、网卡缓存,再发出去。这样会导致两个限制。
- 限制一:TCP/IP协议栈处理会带来数10微秒的时延。TCP协议栈在接收发送报文时,内核需要做多次上下文的切换,每次切换需要耗费5-10微秒。另外还需要至少三次的数据拷贝和依赖CPU进行协议工作,这导致仅仅协议上处理就会带来数10微秒的固定时延,协议栈时延成为最明显的瓶颈。
- 限制二:TCP协议栈处理导致服务器CPU负载居高不下。除了固定时延较长的问题,TCP/IP网络需要主机CPU多次参与协议的内存拷贝,网络规模越大,网络带宽越高,CPU在收发数据时的调度负担越大,导致CPU持续高负载。
在数据中心内部,超大规模分布式计算存储资源之间,如果使用传统的TCP/IP进行网络互连,将占用系统大量的计算资源,造成IO瓶颈,无法满足更高吞吐,更低时延的网络需求。
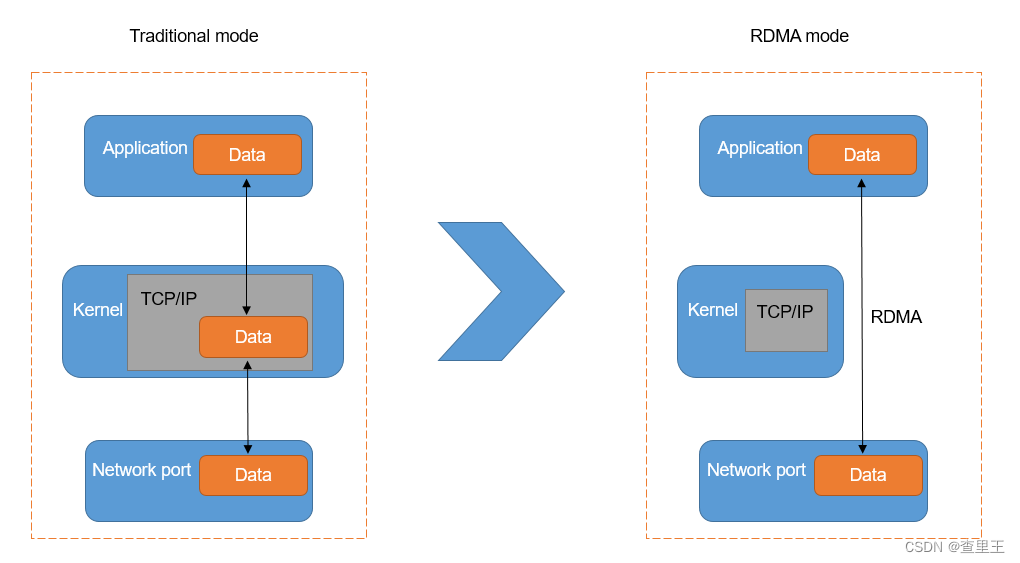
RDMA是一种高带宽、低延迟、低CPU消耗的网络互联技术,克服了传统TCP/IP网络的许多困难。
1.RDMA主要体现
Remote(远程):数据在网络中的两个节点之间传输。
Direct(直接):不需要内核参与,传输的所有处理都卸载到NIC硬件中完成。
Memory(内存):数据直接在两个节点的应用程序的虚拟内存间传输;不需要额外的复制和缓存。
Access(访问):访问操作有send/receive、read/write等。数据在网络中的两个节点之间传输。
2.如何理解RDMA和TCP技术的区别?
借用某个技术大牛举的一个例子:
传统的TCP/IP方式就像是人工收费一样,需要取卡,人工核实,手动缴费,找零钱等等才能完成汽车上下高速。在车辆很多的情况下就会出现排队的情况,很浪费时间。
而RDMA则像是ETC,跳过人工取卡,收费等步骤,直接刷卡,极速通过。既节省了时间,又节省了人力。
RDMA相比TCP/IP,既降低了对计算资源的占用,又提升了数据的传输速率。
RDMA的内核旁路机制允许应用与网卡之间的直接数据读写,这样可以将服务器内的数据传输时延降低到接近1微秒。
同时,RDMA的内存零拷贝机制允许接收端直接从发送端的内存读取数据,极大地减少了CPU的负担,提高了CPU的利用率。
3.使用RDMA的好处包括:
内存零拷贝(Zero Copy):
RDMA应用程序可以绕过内核网络栈直接进行数据传输,不需要再将数据从应用程序的用户态内存空间拷贝到内核网络栈内存空间。
内核旁路(Kernel bypass):RDMA应用程序可以直接在用户态发起数据传输,不需要在内核态与用户态之间做上下文切换。
CPU减负(CPU offload):RDMA可以直接访问远程主机内存,不需要消耗远程主机中的任何CPU,这样远端主机的CPU可以专注自己的业务,避免其cache被干扰并充满大量被访问的内存内容。
二.什么是RoCE?
从 2010 年开始,RMDA 开始引起越来越多的关注,当时IBTA发布了第一个在融合以太网 (RoCE) 上运行 RMDA 的规范。
然而,最初的规范将 RoCE 部署限制在单个第 2 层域,因为 RoCE 封装帧没有路由功能。
2014 年,IBTA 发布了 RoCEv2,它更新了最初的 RoCE 规范以支持跨第 3 层网络的路由,使其更适合超大规模数据中心网络和企业数据中心等。

1. RDMA协议包含:
Infiniband(IB)
- internet Wide Area RDMA Protocol(iWARP)
- RDMA over Converged Ethernet(RoCE):
1. InfiniBand:
设计之初就考虑了 RDMA,重新设计了物理链路层、网络层、传输层,从硬件级别,保证可靠传输,提供更高的带宽和更低的时延。但是成本高,需要支持IB网卡和交换机。
2. iWARP:
基于TCP的RDMA网络,利用TCP达到可靠传输。相比RoCE,在大型组网的情况下,iWARP的大量TCP连接会占用大量的内存资源,对系统规格要求更高。可以使用普通的以太网交换机,但是需要支持iWARP的网卡。
3. RoCE:
基于 Ethernet的RDMA,RoCEv1版本基于网络链路层,无法跨网段,基本无应用。RoCEv2基于UDP,可以跨网段具有良好的扩展性,而且可以做到吞吐,时延相对性能较好,所以是大规模被采用的方案。
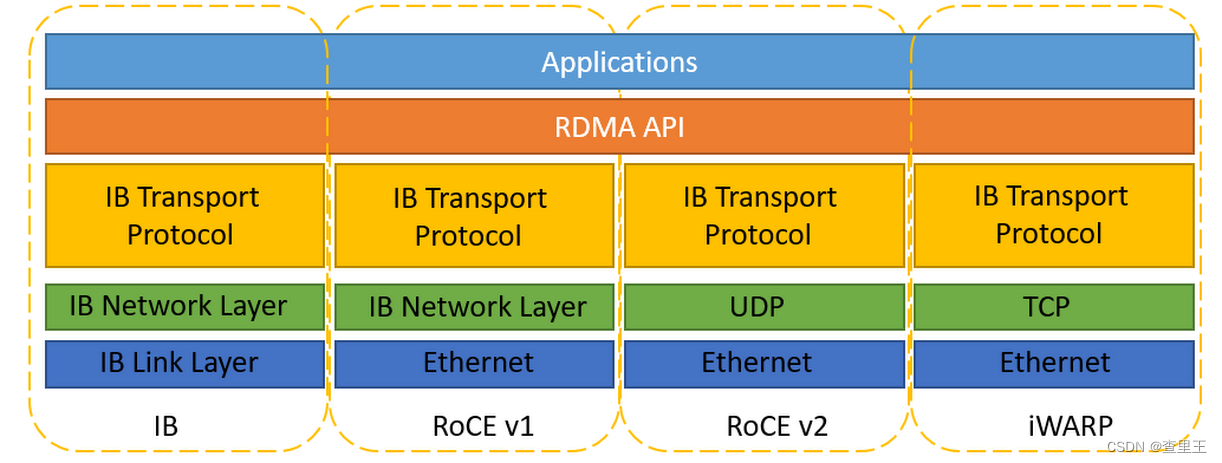
RoCE消耗的资源比 iWARP 少,支持的特性比 iWARP 多。可以使用普通的以太网交换机,但是需要支持RoCE的网卡。
2. 为什么RoCE是目前主流的RDMA协议?
先说iWARP,iWARP协议栈相比其他两者更为复杂,并且由于TCP的限制,只能支持可靠传输。所以iWARP的发展不如RoCE和Infiniband。
而Infiniband协议本身定义了一套全新的层次架构,从链路层到传输层,都无法与现有的以太网设备兼容。举例来看,如果某个数据中心因为性能瓶颈,想要把数据交换方式从以太网切换到Infiniband技术,那么需要购买全套的Infiniband设备,包括网卡、线缆、交换机和路由器等等,成本太高
RoCE协议的优势在这里就很明显了,用户从以太网切换到RoCE只需要购买支持RoCE的网卡就可以了,其他网络设备都是兼容的。所以RoCE相比于Infiniband主要优势在于成本更低。
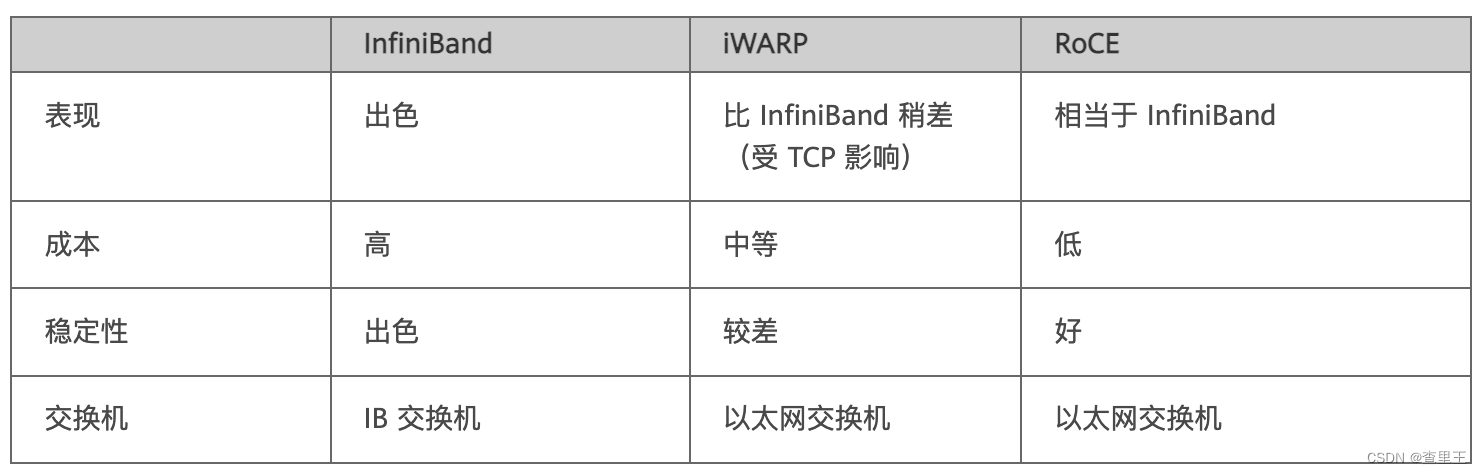
RoCEv1
2010年4月,IBTA发布了RoCE,此标准是作为Infiniband Architecture Specification的附加件发布的,所以也称为IBoE(InfiniBand over Ethernet)。这时的RoCE标准是在以太链路层之上用IB网络层代替了TCP/IP网络层,所以不支持IP路由功能。RoCE V1协议在以太层的typeID是0x8915。
在RoCE中,infiniband的链路层协议头被去掉,用来表示地址的GUID被转换成以太网的MAC。Infiniband依赖于无损的物理传输,RoCE也同样依赖于无损的以太传输,这一要求会给以太网的部署带来了成本和管理上的开销。
以太网的无损传输必须依靠L2的QoS支持,比如PFC(Priority Flow Control),接收端在buffer池超过阈值时会向发送方发出pause帧,发送方MAC层在收到pause帧后,自动降低发送速率。这一要求,意味着整个传输环节上的所有节点包括end、switch、router,都必须全部支持L2 QoS,否则链路上的PFC就不能在两端发挥有效作用。
RoCEv2
由于RoCEv1的数据帧不带IP头部,所以只能在L2子网内通信。为了解决此问题,IBTA于2014年提出了RoCE V2,RoCEv2扩展了RoCEv1,将GRH(Global Routing Header)换成UDP header + IP header,扩展后的帧结构如下图所示。
针对RoCE v1和RoCE v2,以下两点值得注意:
RoCE v1(Layer 2)运作在Ehternet Link Layer(Layer 2)所以Ethertype 0x8915,所以正常的Frame大小为1500 bytes,而Jumbo Frame则是9000 bytes。
RoCE v2(Layer 3)运作在UDP/IPv4或UDP/IPv6之上(Layer 3),采用UDP Port 4791进行传输。因为 RoCE v2的封包是在 Layer 3上可进行路由,所以有时又会称为Routable RoCE或简称RRoCE。

RoCE,无损先行
由于RDMA要求承载网络无丢包,否则效率就会急剧下降,所以RoCE技术如果选用以太网进行承载,就需要通过PFC,ECN以及DCQCN等技术对传统以太网络改造,打造无损以太网络,以确保零丢包。
PFC:基于优先级的流量控制。
PFC为多种类型的流量提供基于每跳优先级的流量控制。设备在转发报文时,通过在优先级映射表中查找报文的优先级,将报文分配到队列中进行调度和转发。当802.1p优先级报文的发送速率超过接收速率且接收端的数据缓存空间不足时,接收端向发送端发送PFC暂停帧。当发送端收到 PFC 暂停帧时,发送端停止发送具有指定 802.1p 优先级的报文,直到发送端收到 PFC XON 帧或老化定时器超时。配置PFC时,特定类型报文的拥塞不影响其他类型报文的正常转发,
ECN:显式拥塞通知。
ECN 定义了基于 IP 层和传输层的流量控制和端到端拥塞通知机制。当设备拥塞时,ECN 会在数据包的 IP 头中标记 ECN 字段。接收端发送拥塞通知包(CNP)通知发送端放慢发送速度。ECN 实现端到端的拥塞管理,减少拥塞的扩散和加剧。
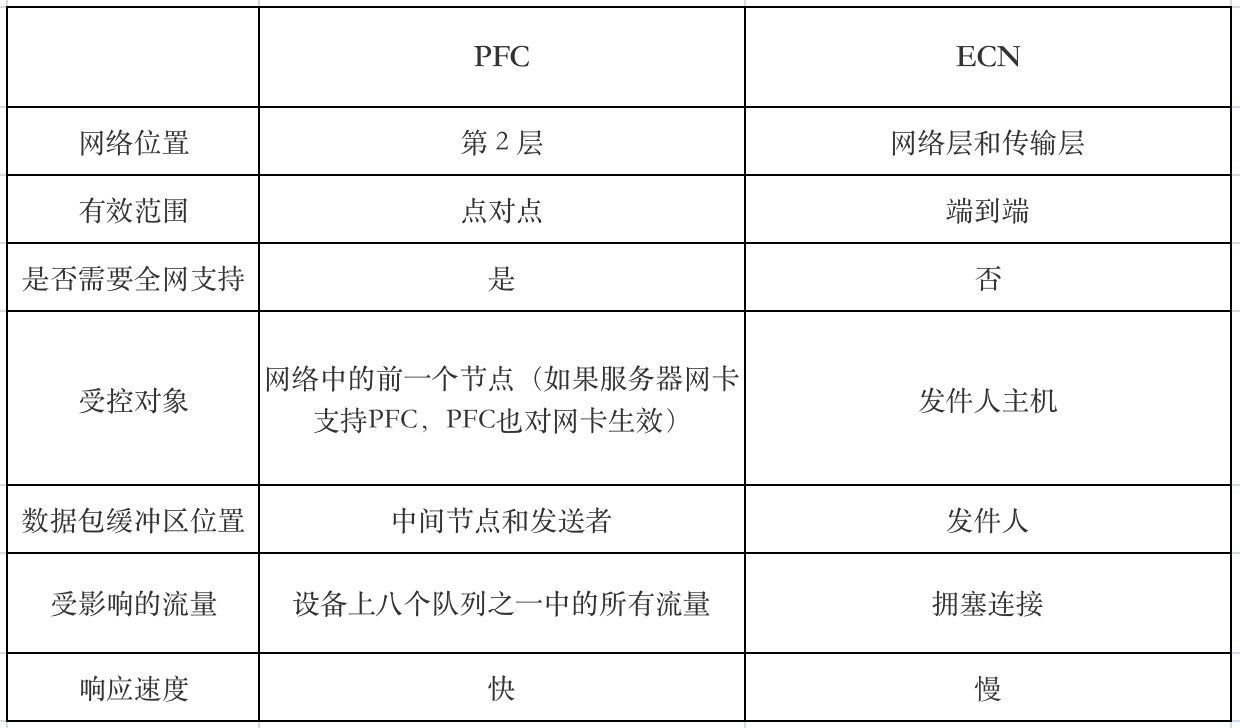
DCQCN(Data Center Quantized Congestion Notification):目前在RoCEv2网络种使用最广泛的拥塞控制算法。融合了QCN算法和DCTCP算法,需要数据中心交换机支持WRED和ECN。DCQCN可以提供较好的公平性,实现高带宽利用率,保证低的队列缓存占用率和较少的队列缓存抖动情况。
目前许多厂家已经有了自己的无损网络方案。
华为
华为iLossless智能无损算法方案是一个通过人工智能实现网络拥塞调度和网络自优化的AI算法,其以Automatic ECN为核心,并在超高速数据中心交换机引入深度强化学习DRL(Deep Reinforcement Learning)。基于iLossless智能无损算法,华为发布了超融合数据中心网络CloudFabric 3.0解决方案,引领智能无损进入1.0时代。
2022年,华为超融合数据中心网络提出了智能无损网算一体技术和创新直连拓扑架构,可实现270k大规模算力枢纽网络,时延在智能无损1.0的基础上,可进一步降低25%。
华为智能无损2.0基于在网计算(In-network computing)和拓扑感知(Topology-Aware Computing)实现网络和计算协同。网络参与计算信息的汇聚和同步,减少计算信息同步的次数;同时,通过调度确保计算节点就近完成计算任务,减少通信跳数,进一步降低应用时延。
新华三
新华三推出的AI ECN智能无损算法,能根据网络流量模型(N打1的Incast值、队列深度、大小流占比等流量特征),通过强化学习算法对流量模型进行AI训练,实时感知和预测网络流量变化趋势,自动调节出最优的ECN水线,进行队列的精确调度。在尽量避免触发网络PFC流控的同时,兼顾时延敏感小流和吞吐敏感大流的转发,进一步保障整网的最优性能。
新华三AD-DC SeerFabric无损网络解决方案。基于云边AI协同架构,通过对业界AI ECN调优算法的优化创新,结合新华三数据中心交换机的本地AI Inside能力,在保障零丢包的情况下,尽可能提升吞吐率、降低时延,保障网络业务的精确转发和网络服务质量的确定性。同时,通过精细化的智能运维,实现RoCE网络的业务体验可视。
浪潮
2022年4月,浪潮网络以支持RoCE技术的数据中心以太网交换机为核心,推出了典型的无损以太网解决方案,具备以下优势:
1)计算、存储、网络、AIStation无缝融合。支持PFC、ECN等网络流控技术,以构建端到端、无损、低延时的RDMA承载网络。而交换机完美的缓存优势,可平滑吸收突发流量,有效应对TCP incast。
2)故障主动发现、自动倒换。RoCE-SAN网络与存储业务协同、故障快速感知,交换机快速检测到故障状态,并通知给相关业务域内订阅通知消息的服务器,以便业务快速切换到冗余路径,降低对业务的影响。针对大型无损以太网环境下PFC死锁的问题,可以提供芯片级防PFC死锁机制,实现自动检测PFC死锁及恢复。
3)存储即插即用。RoCE-SAN网络能够自动发现设备服务器与存储设备的接入,并通知服务器自动建立与存储设备的连接关系。
参考
15. RDMA之RoCE & Soft-RoCE - 知乎
Basic Knowledge and Differences of RoCE, IB, and TCP Networks - Huawei
Understanding real RoCEv2 performance
高性能网络及优化:RDMA/RoCEv2、AWS SRD & Aliyun HPCC - 极术社区 - 连接开发者与智能计算生态