数据表如何用索引快速查找
索引是 排好序的快速查找的数据结构
索引存储在文件系统中
索引的文件存储形式与存储引擎有关
索引数据结构:可以是二叉树、红黑树、Hash表、B-Tree、B+Tree
1、二叉树
使用索引的如下图:(如果是使用二叉树结构)每一个节点都存放数据行的磁盘地址【快速定位到数据】

虽然索引不是使用的二叉树,而是使用B+Tree结构,为什么不使用二叉树呢?
如果索引是连续的数字,二叉树就会蜕变成链表,访问的速度还是和没加索引一样

这时再查找效率就变低了
2、红黑树
红黑树作为索引的数据结构呢,其实红黑树是二叉平衡树,到某个节点数值的绝对值超过2,就会重新排列(该节点不平衡),但是为什么索引还没 有选择红黑树呢,原因是树的高度比较高(一直是二叉),索引树的高度比较高,和磁盘进行IO操作比较多

3、BTree
BTree又叫多路平衡搜索树,就是一个节点开辟更大的空间,(横向)存放多个索引
- 叶子节点具有相同的深度,叶子节点的指针为空
- 节点中的数据从左到右递增排列

这样树的高度就解决了,横向存储更多,但是为什么不选择BTree呢,因为页节点有默认大小的,如果每个节点都存储数据data,这时页节点就存储的个数不多,这样会增加树的高度.
4、B+Tree
B+Tree对BTree做了点优化,非叶子节点不存data数据,一个节点MySQL底层叫做页节点(默认分配16KB大小)
SHOW GLOBAL STATUS like 'Innodb_page_size';
- 1
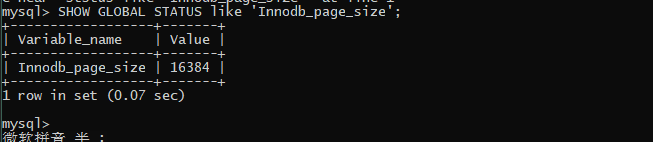

索引一般使用int 默认是8B,指针是存储下一个页节点的地址大小为6B,所以一个页节点可以存放 16KB /(6+8)B = 1170 个 高度为3 的可以存放 = 1170 * 1170 * 16 差不多两千万多
5、MyISAM存储引擎实现
MyISAM不支持事务、也不支持外键,其优势是访问的速度快,对事务的完整性没有要求

创建一个存储引擎是MyISAM的test_MyISAM表

【注意】
MySQL8开始删除了原来的frm文件,并采用 Serialized Dictionary Information (SDI), 是MySQL8.0重新设计数据词典后引入的新产物
myIsam.MYD:存储表的数据信息
myIsam.MYI:存储表的索引信息(index)
从上面的索引中可以看到,通过索引查找数据,最后是定位到物理地址(MYD文件)所在的位置
比如通过where条件查询时,会判断是不是索引,如果是索引,每次查找时,把当前的页子节点从磁盘中(.MYI文件)加载到内存中【这是一个比较耗时的操作,该操作也是一次IO操作】,这也是典型的非聚集索引(索引文件和数据文件分离的)
6、InnoDB存储引擎实现
InnoDB存储引擎是MySQL默认存储引擎,InnoDB存储引擎提供了具有提交、回滚、崩溃恢复能得事务安全
聚集索引:数据和索引存放在一起
InnoDB存储引擎的表必须建立主键,建立了主键,主键就是聚集索引
聚集索引查找数据的图结构如下:

创建以InnoDB存储引擎的表test_InnoDB,查看表结构
在MySQL8就只有一个.ibd文件,之前的版本是有.frm文件的

数据和索引都存放在.ibd文件中,就如上图一样,主键索引(聚集索引)自带完整的数据,普通的索引是自带id主键,再通过id主键获取数据data
如图:先定位id主键值,再回表查询(通过id值查询–》聚集索引)

1)为什么建议InnoDB表必须建立主键,并且推荐使用整型自增主键?
如果不建立主键,数据库会找一个唯一区别的列作为主键,如果没找到就增加一个隐藏列rowid来维护索引(使用B+Tree),我们尽量节省MySQL的性能,不要它帮我们建立。
推荐使用整型的自增主键,因为如果使用字符串查询时是逐位比较每一位字符,比较慢
2)为什么非主键索引结构叶子节点存储的是主键值?
- 保持一致性
当数据库表进行DML操作时,同一行记录的页地址会发生改变,因此非主键索引保存的是主键值,无需要进行改变
- 节省存储空间
InnoDB数据本身就是汇聚到主键索引所在的B+Tree上了,如果普通索引还继续再保存一份数据,就会出现有多少索引就会存多少份数据
7、Hash表
索引也是可以设定位Hash表,但是使用不多

对索引的key进行hash计算确定数据存储的位置(数组下标位置),如果出现hash冲突时,通过链地址法解决冲突

- Hash索引无法被用来避免数据的排序操作
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
- 但是Hash索引仅能满足 “=” ,“in” ,不支持范围查询
由于Hash索引比较的是进行Hash运算之后的Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的Hash算法处理之后的Hash值的大小关系,并不能保证和Hash运算前完全一样。
-
还有Hash冲突问题,如果冲突很多维护代价很高
-
Hash索引不能利用部分索引键查询
对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用
- Hash索引在任何时候都不能避免表扫描
Hash索引是将索引键通过Hash运算之后,将 Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
- Hash索引遇到大量Hash值相等的情况后性能并不一定就会比BTree索引高
如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
上面的两点算是不选择Hash索引的原因
通过Hash索引怎么查找数据呢???
比如使用Hash索引时,查找数据,首先计算hash值,再到链表查询数值,在定位到物理地址,才算是查找成功
哈希碰撞很多时,查询还是会变的缓慢,因为必须要遍历链表中对应的所有数据行进行匹配,同样更新索引的效率也会受到影响,导致数据的新增、修改、删除速度变慢。
既然Hash索引是不支持范围查找,那么B+Tree是怎么范围查询的呢??
8、B+Tree的范围查找
叶子节点用指针连接,提高区间访问的性能
比如查找 范围在20-50的数据,首先查找20,之后通过20后面的指针指向后面的往后查找,直到查找到大于50的为止(通过这个叶子节点的指针可以看出,连续且自增的主键好处),使用主键自增的可以避免页节点的元素分裂导致范围查询效率低。
复合索引的最左前缀优化原则
对于复合索引,它的索引B+Tree是怎么样构建的呢?

联合索引首先按照第一个字段排序,如果第一个相同再按照第二个字段排序,依次类推