据外媒CNBC报道,随着对训练和部署人工智能软件所需芯片需求的飙升,英伟达的最先进的显卡在eBay上的售价超过 40,000 美元。
3D 游戏先驱和前META咨询技术主管约翰卡马克在 Twitter 上注意到 Nvidia H100 处理器的价格。周五,eBay 上至少有 8 台 H100 挂牌,价格从 39,995 美元到略低于 46,000 美元不等。过去一些零售商的售价约为36,000 美元。
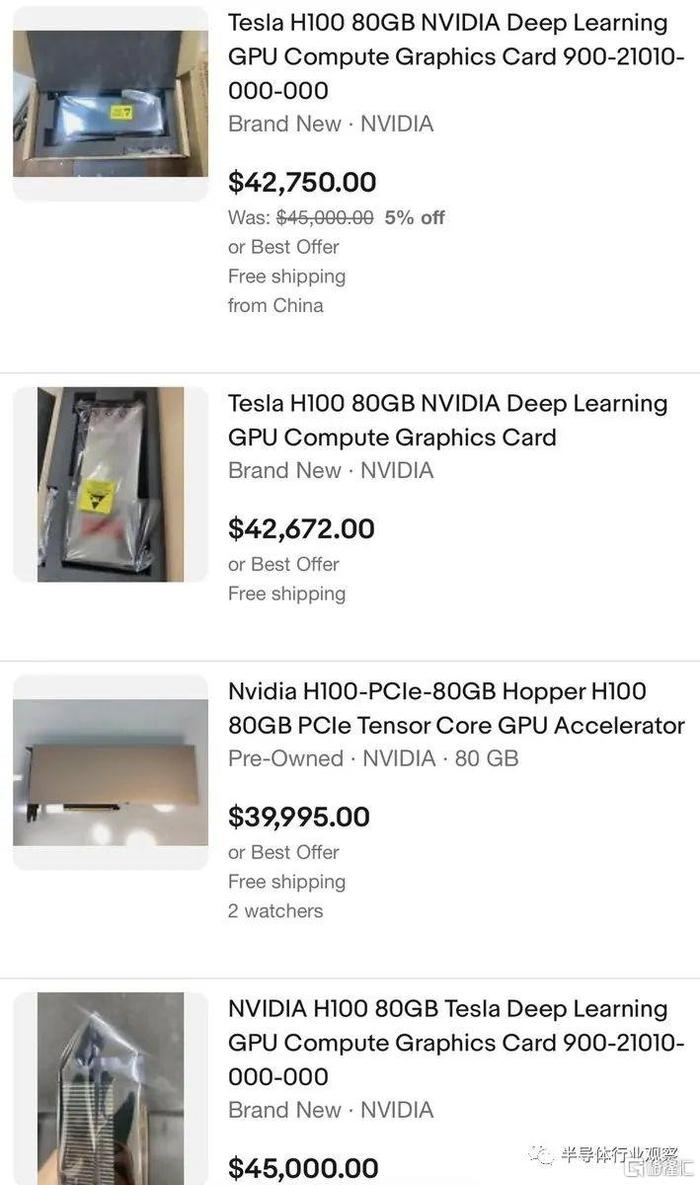
去年发布的 H100 是 Nvidia 最新的旗舰 AI 芯片,它是 A100 的继任者,A100 是一款价值约 10,000 美元的芯片,被称为 AI 应用的“主力军”。
开发人员正在使用 H100 构建所谓的大型语言模型 (LLM),这是 OpenAI 的 ChatGPT 等人工智能应用程序的核心。运行这些系统非常昂贵,并且需要强大的计算机一次处理数 TB 的数据数天或数周。他们还依赖强大的计算能力,因此人工智能模型可以生成文本、图像或预测。
训练 AI 模型,尤其是像 GPT 这样的大型模型,需要数百个高端 Nvidia GPU 协同工作。例如微软就斥资数亿美元购买了数万颗 Nvidia A100 芯片,帮助打造 ChatGPT。Nvidia 控制着 AI 芯片的绝大部分市场。
Nvidia 还提供了一台带有八个 GPU 的超级计算机,称为 DGX。今年早些时候,该公司宣布推出新服务,允许公司以每月 37,000 美元的价格租用 DGX 计算机。以这个价格,该系统将使用 Nvidia 的旧 A100 处理器。
Nvidia 表示,H100 是第一款针对特定 AI 架构进行优化的芯片,该架构支撑着 AI 的许多最新进展,称为 transformers。行业专家表示,要构建比目前可用的模型更大、数据需求量更大的模型,将需要更强大的芯片。
ChatGPT引爆算力需求
今年以来,ChatGPT的火爆已经席卷了全球,而这火爆背后就需要GPU的强力支持。
早在2020年五月,微软就披露,公司已经建造了世界上公开披露的前五名超级计算机之一,在 Azure 中提供新的基础设施来训练超大型人工智能模型。“托管在 Azure 中的超级计算机与 OpenAI 合作并专为OpenAI构建,专为训练该公司的 AI 模型而设计。”微软强调。
据当时的文章介绍,为 OpenAI 开发的超级计算机是一个单一系统,具有超过 285,000 个 CPU 内核、10,000 个 GPU 和每个 GPU 服务器每秒 400 GB 的网络连接。微软表示,与全球TOP500超级计算机上的其他机器相比,它名列前五。托管在 Azure 中的超级计算机还受益于强大的现代云基础设施的所有功能,包括快速部署、可持续数据中心和对 Azure 服务的访问。
到了今年三月,微软又在另外一篇文章中进行了更多的披露。
微软负责战略合作伙伴关系的高级主管Phil Waymouth强调,OpenAI 训练其模型所需的云计算基础设施的规模是前所未有的——网络 GPU 集群的规模呈指数级增长,超过了业内任何人试图构建的规模。
为了满足对更复杂和更大模型的日益增长的需求,微软宣布了新的功能强大且可大规模扩展的虚拟机,这些虚拟机集成了最新的 NVIDIA H100 Tensor Core GPU 和 NVIDIA Quantum-2 InfiniBand 网络。虚拟机是 Microsoft 向客户提供基础设施的方式,可以根据任何 AI 任务的规模进行扩展。据微软称,Azure 的新 ND H100 v5 虚拟机为 AI 开发人员提供了卓越的性能和跨数千个 GPU 的扩展。
微软 Azure 高性能计算和人工智能产品负责人 Nidhi Chappell说,这些突破的关键是学习如何构建、操作和维护数万个在高吞吐量、低延迟 InfiniBand 网络上相互连接的共置 GPU。她解释说,这个规模甚至比 GPU 和网络设备供应商测试过的还要大。这是一片未知的领域。没有人确切知道硬件是否可以在不损坏的情况下被推到那么远。
她解释说,为了训练一个大型语言模型,计算工作量被分配到一个集群中的数千个 GPU 上。在此计算的某些阶段(称为 allreduce),GPU 会交换有关它们已完成工作的信息。InfiniBand 网络加速了这一阶段,该阶段必须在 GPU 开始下一个计算块之前完成。
“因为这些工作涉及数千个 GPU,所以你需要确保拥有可靠的基础设施,然后你需要在后端拥有网络,这样你才能更快地沟通,并能够连续几周这样做,”Chappell 说。“这不是代表这你只需购买一大堆 GPU,将它们连接在一起就可以开始协同工作的东西。为了获得最佳性能,需要进行大量系统级优化,这需要几代人积累的丰富经验。”
庞大的算力要求的背后,必然是GPU需求的急升和成本的增加。
根据semianalysis在今年二月的一篇文章中披露,ChatGPT 每天在计算硬件成本方面的运营成本为 694,444 美元。OpenAI 需要约 3,617 台 HGX A100 服务器(28,936 个 GPU)来为 Chat GPT 提供服务,估计每次查询的成本为 0.36 美分。
但是,ChatGPT仅仅是一个开始。
大模型浪潮需要更多的GPU
在ChatGPT爆火之后,谷歌Bard迅速发布,微软和亚马逊等巨头也不甘人后。在国内,巨头也纷纷涌入,初创公司也迅速崛起。就连在早前呼吁暂停人工智能研发的Elon Musk也开始加入了大模型的混战。
据报道,在聘请了几位前 DeepMind 研究人员一个多月后,Twitter 正在推进一个内部人工智能项目。Business Insider则透露,Elon Musk 最近购买了 10,000 个 GPU,用于公司剩余的两个数据中心之一。据报道,该项目涉及创建一个生成式人工智能,该公司将根据自己的海量数据进行训练。
与此同时,据金融时报报道,Elon Musk还计划成立一家新的AI公司,与OpenAI竞争。
据熟悉这位科技企业家计划的人士透露,特斯拉和 Twitter 的负责人正在组建一个由人工智能研究人员和工程师组成的团队。
据一位直接了解谈判情况的人士透露,马斯克还在与 SpaceX 和特斯拉的一些投资者讨论将资金投入他的新企业的事宜。“一群人正在投资它。. . 这是真实的,他们对此很兴奋,”该人士说。
据知情人士透露,对于新项目,马斯克已经从 Nvidia 获得了数千个高性能 GPU 处理器。GPU 是 Musk 建立大型语言模型的目标所需的高端芯片——人工智能系统能够摄取大量内容并产生类似人类的文字或逼真的图像,类似于为 ChatGPT 提供支持的技术。
而在在本周的 Twitter Spaces 采访中,马斯克被问及 Business Insider 的一份报告,该报告称 Twitter 购买了多达 10,000 个 Nvidia GPU,“似乎每个人和他们的狗此时都在购买 GPU,”( “It seems like everyone and their dog is buying GPUs at this point”)马斯克说。“Twitter 和特斯拉肯定会购买 GPU。
这引爆的GPU需求显而易见。
据《财经十一人》在三月份的报道,截止当时,微软的Azure云服务为ChatGPT构建了超过1万枚英伟达A100 GPU芯片的AI计算集群。多位云计算技术人士对《财经十一人》表示,运行ChatGPT至少需要1万枚英伟达的A100芯片。然而,GPU芯片持有量超过1万枚的企业不超过5家。其中,拥有1万枚英伟达A100 GPU的企业至多只有1家。
TrendForce集邦咨询则表示,由于生成式AI必须投入巨量数据进行训练,为缩短训练就得采用大量高效能GPU。以ChatGPT背后的GPT模型为例,其训练参数从2018年约1.2亿个到2020年已暴增至近1800亿个,TrendForce集邦咨询预估GPU需求量约2万颗,未来迈向商用将上看3万颗(计算基础以NVIDIA A100为主)。
而英伟达成为背后几乎的唯一GPU赢家,H100则成为了大家争夺的新目标。
计算力暴涨的H100是救星
在算力需求剧增下,英伟达的GPU几乎成为了唯一的硬通货,而去年年初发布,并在九月量产的H100最新、最强的救星。
作为一个专为专注于 AI 功能的超级计算机而设计的产品。与当前的 A100 相比,H100包括了大量更新和升级,所有设计均达到新的性能和效率水平。Hopper 包含 800 亿个晶体管,它是使用定制的 TSMC 4N 工艺制造的。值得一提的是,这是一个针对 Nvidia而优化的4nm工艺,不要将其与 TSMC 也提供的通用 N4 4nm 工艺混淆。作为对比,A100 GPU“仅”有 540 亿个晶体管。
H100 支持 Nvidia 第四代 NVLink 接口,可提供高达 900 GB/s 的带宽。对于不使用 NVLink 的系统,它还支持 PCIe 5.0,最高可达 128 GB/s。更新的 NVLink 连接提供比 A100 多 1.5 倍的带宽,而 PCIe 5.0 提供的带宽是 PCIe 4.0 的两倍。
H100 还将默认支持 80GB 的 HBM3 内存,带宽为 3 TB/s——比 A100 的 HBM2E 快 1.5 倍。虽然 A100 有 40GB 和 80GB 两种型号,后者在生命周期的后期出现,但 H100 和 A100 仍然使用多达六个 HBM 堆栈,显然禁用了一个堆栈(即使用虚拟堆栈)。一般来说,H100 的内存和接口带宽比其前身多 50%。
可以肯定的是,这是一个很好的改进,但 Hopper 的其他方面涉及更大的改进。
H100 可以提供高达 2,000 TFLOPS 的 FP16 计算和 1,000 TFLOPS 的 TF32 计算,以及 60 TFLOPS 的通用 FP64 计算——这在所有三种情况下都是 A100 性能的三倍。Hopper 还增加了改进的 FP8 支持,计算能力高达 4,000 TFLOPS,比 A100 快六倍(A100 由于缺乏原生 FP8 支持而不得不依赖 FP16)。为了帮助优化性能,Nvidia 还有一个新的transformer引擎,可以根据工作负载自动在 FP8 和 FP16 格式之间切换。
Nvidia 还将添加旨在加速动态编程的新 DPX 指令。这些可以帮助广泛的算法,包括路线优化和基因组学,Nvidia 声称这些算法的性能比上一代 GPU 快 7 倍,比基于 CPU 的算法快 40 倍。Hopper 还包括改进安全性的更改,多实例 GPU (MIG) 现在允许在单个 H100 GPU 上运行七个安全租户。
所有这些变化对于 Nvidia 的超级计算和 AI 目标都很重要。然而,这些变化并不都是为了更好。尽管转移到更小的制造节点,但 SXM 变体的 H100 TDP 已增加到 700W,而 A100 SXM 模块为 400W。这是 75% 以上的功率,根据工作负载,改进范围似乎在 50% 到 500% 之间。总的来说,我们预计性能将比 Nvidia A100 快两到三倍,因此效率应该仍有净提升,但这进一步证明了摩尔定律正在放缓。
总体而言,Nvidia 声称 H100 的扩展性优于 A100,并且可以在 AI 训练中提供高达 9 倍的吞吐量。它还使用 Megatron 530B 吞吐量作为基准,提供 16 到 30 倍的推理性能。最后,在 3D FFT(快速傅立叶变换)和基因组测序等 HPC 应用程序中,Nvidia 表示 H100 比 A100 快 7 倍。
写在最后
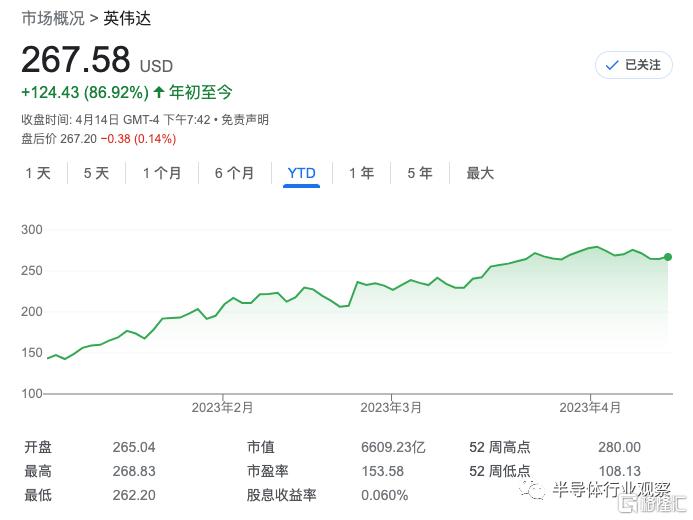
其实从去年下半年开始,因为行业的下行,英伟达的数据中心业务一直下滑,公司市值也不仅是腰斩。但随着ChatGPT的火热,英伟达又逆风翻盘,上涨了超过80%。从最早的显卡,到AI加速,到挖矿,再到现在的ChatGPT,英伟达正在抓住一波又一波的机遇。
英伟达CEO黄仁勋则表示:“世界对数据中心的需求量将会增长。这对世界来说是一个真正的问题。我们应该做的第一件事是:世界上的每个数据中心,无论你决定做什么,为了可持续计算的好处,尽你所能加速。”
“我们现在有 700 多家客户在尝试,从汽车行业到物流仓库再到风力涡轮机工厂,”黄仁勋说。“它可能代表了英伟达所有技术中最伟大的容器:计算机图形学、人工智能、机器人技术和物理模拟,集于一身。我对它寄予厚望。”
过去几十年的技术积累和开拓是黄仁勋说出这样的话的底气。