0、导读
用mysqldump备份数据时,加上 -w 条件选项过滤部分数据,发现导出结果比实际少了40万,什么情况?
本文约1500字,阅读时间约5分钟。
1、问题
我的朋友小文前几天遇到一个怪事,他用mysqldump备份数据时,加上了 -w 选项过滤部分数据,发现导出的数据比实际上少了40万。
要进行备份表DDL见下:
CREATE TABLE `oldbiao` (
`aaaid` int(11) NOT NULL,
`bbbid` int(11) NOT NULL,
`cccid` int(11) NOT NULL,
`time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`dddid` int(11) DEFAULT NULL,
KEY `index01` (`ccccid`),
KEY `index02` (`dddid`,`time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
顺便吐槽下,这个表DDL设计的真是low啊。没主键,允许NULL。
mysqldump备份指令增加的 -w/--where 选项是:
-w "time>‘2016-08-01 00:00:00'"
加上这个参数的作用是:只备份 2016-8-1 之后的所有数据,相当于执行了下面这样的SQL命令:
SELECT SQL_NO_CACHE * FROM t WHERE time>‘2016-08-01 00:00:00'
然后把导出的SQL文件恢复后,再随机抽查下数据看看是否有遗漏的。不查不知道,一查吓一跳,发现 2016-12-12 下午的数据是缺失的。经过仔细核查,发现比原数据大概少了40万条记录。
百思不得其解的小文请我帮忙排查问题。
2、排查
既然是少了一部分数据,那就要先定位到底是丢失了的是哪部分数据。
那么,如何定位呢?
搞数据库的人,应该都知道折半查找法,这是计算机科学里比较基础的概念之一。我们就利用这种方法来快速定位。
经过排查,发现是缺少的数据有个特点,根据时间排序,发现最早的数据是 2016-8-1 8点的,而我们上面设定的条件则是 2016-8-1 0点开始的所有数据,整整差了8个小时。
看到8小时这个特点,我想你应该大概想到什么原因了吧。对,没错,就是因为时区的因素导致的。
经过排查,发现是因为原先写数据时,是以 0时区 时间写入的,但执行mysqldump备份时则使用的是本地 东8区 的时间,所以就有了8小时的差距。
2、解决
知道了问题所在,方法就简单了。有两个方法:
1、修改mysqldump中的where条件时间值,减去8个小时。建议采用该方法。
mysqldump ... -w "time>‘2016-07-31 16:00:00'"
2、修改MySQL全局时区,从 0时区 改成 东8区,并且mysqldump加上 --skip-tz-utc 选项。这种方法需要修改MySQL的全局时区,可能会导致更多的业务问题,因此强烈不建议使用。
mysqldump ... --skip-tz-utc -w "time>‘2016-08-01 08:00:00'"
问题暂且按下,我们先来看下时区因素怎么影响查询结果的。
先看下系统本地时间:
[yejr@imsyql]$ date -R
Wed, 21 Dec 2016 14:04:51 +0800
测试表DDL:
CREATE TABLE `t1` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
...
`c1` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
查看MySQL的时区设置:
图1
然后写入一条数据: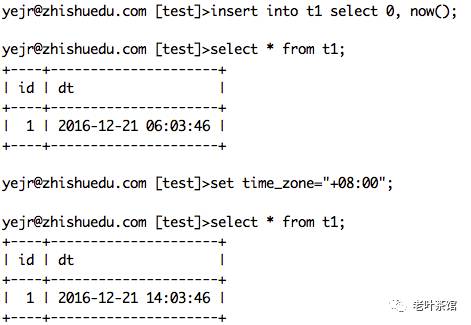
图2
第一次备份,用本地时间条件去过滤:
mysqldump -w "dt >= '2016-12-21 14:00:00'"
这种情况下,显然是没有结果的。
图3
第二次备份,用本地时间减去8小时再去过滤:
mysqldump -w "dt >= '2016-12-21 06:00:00'"
这种就可以备份出数据了。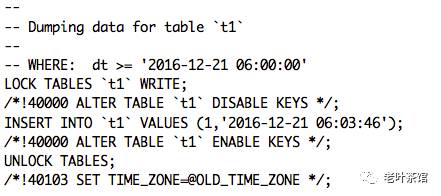
图4
此外,我们注意到mysqldump的 --tz-utc 选项,它是和时区设定有关系的:
--tz-utc
SET TIME_ZONE='+00:00' at top of dump to allow dumping of TIMESTAMP data when a server has data in different time zones or data is being moved between servers with different time zones.
(Defaults to on; use --skip-tz-utc to disable.)
这个选项的作用,就是以 0时区 备份数据,把所有时间都转换成 0时区 的数据。比如本来是在 东8区(+08:00) 的时间 14:00:00,转换成 0时区 后,会变成 06:00:00,原来是 西8区(-08:00) 的时间14:00:00,则转换成 22:00:00。这个选项是默认启用的。
在上面第一次备份时没有数据,就是因为MySQL里本身存储的就是 0时区 的数据,mysqldump也设定了转换成 0时区,我们传递进去的参数却是 东8区 的时间,因此没有数据。
3、总结
本来只想简单写一下的,结果啰里啰嗦写了好多。
其实我们只需要注意一点,服务器在哪里,就是用哪里的时区,也就是 SYSTEM 时区,在做SQL查询以及mysqldump备份数据时,也使用服务器上的时间,而不使用我们本地时间。
图5
老叶茶馆镇店之宝,扫码识别或访问 http://yejinrong.com 直达
</div><div><div></div></div>
</div>
</article>
复制