在 kafka3.0 中已经可以将 zookeeper 去掉,使用 kraft 机制实现 controller 主控制器的选举。所以我们先简单了解下 kafka2.0 和 3.0 在这方面的区别。
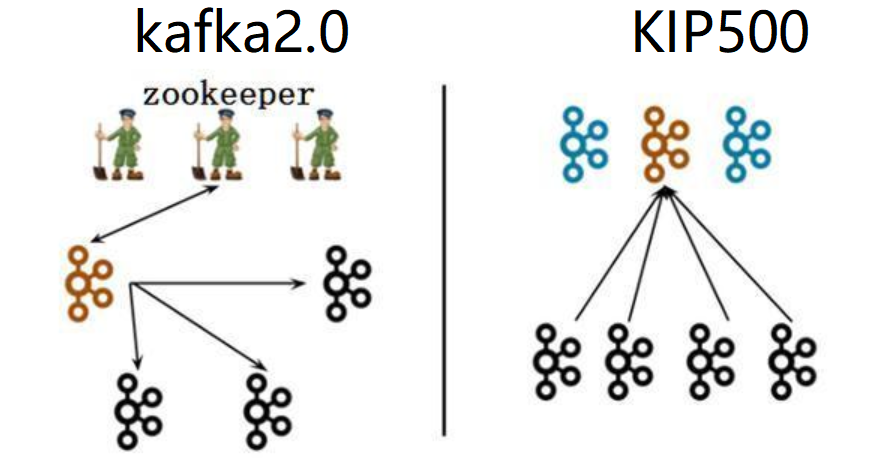
上图中黑色代表 Broker(消息代理服务),褐色/蓝色代表 Controller(集群控制器)
左图(kafka2.0):一个集群所有节点都是 Broker 角色,利用 zookeeper 的选举能力从三个 Broker 中选举出来一个 Controller 控制器,同时控制器将集群元数据信息(比如主题分类、消费进度等)保存到 zookeeper,用于集群各节点之间分布式交互。
右图(kafka3.0):假设一个集群有四个 Broker,配置指定其中三个作为 Conreoller 角色(蓝色)。使用 kraft 机制实现 controller 主控制器的选举,从三个 Controller 中选举出来一个 Controller 作为主控制器(褐色),其他的 2 个备用。zookeeper 不再被需要。相关的集群元数据信息以 kafka 日志的形式存在(即:以消息队列消息的形式存在)。
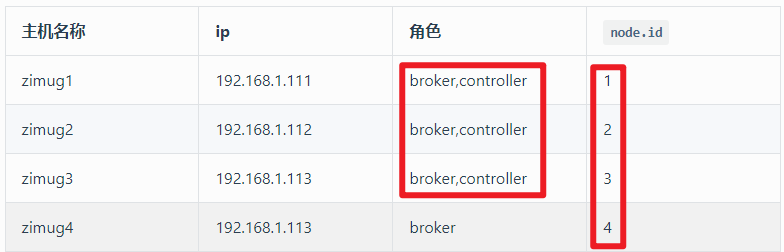
理解了上面的右图,我们就不难理解在搭建 kafka3.0 集群之前,我们需要先做好 kafka 实例角色规划。(四个 Broker,需要通过主动配置指定三个作为 Controller,Controller 需要奇数个,这一点和 zk 是一样的)
在 kafka 用户(新建的 kafka 用户,不要使用 root 用户)下新建一个目录作为 kafka3 安装目录,并使用 wget 下载一个 3.10 版本的安装包。
kafka3.0 不再支持 JDK8,建议安装 JDK11 或 JDK17,事先安装好。
新建 1 个目录用于保存 kafka3 的持久化日志数据,比如:mkdir -p /home/kafka/data/kafka3;,并保证安装 kafka 的用户具有该目录的读写权限。
(这里需要使用 root 用户)所有安装 kafka3 服务器实例防火墙开放 9092、9093 端口,使用该端口作为 controller 之间的通信端口。该端口的作用与 zk 的 2181 端口类似。
下载完成安装包之后,解压到/home/kafka目录下。也可以修改-C参数自定义解压路径,如果自定义路径,注意路径下的新建的 kafka 用户的操作权限。
在 kafka3.0 版本中,使用 Kraft 协议代替 zookeeper 进行集群的 Controller 选举,所以要针对它进行配置,配置文件在 kraft 目录下,这与 kafka2.0 版本依赖 zookeeper 安装方式的配置文件是不同的。
具体的配置参数如下:
node.id:这将作为集群中的节点 ID,唯一标识,按照我们事先规划好的(上文),在不同的服务器上这个值不同。其实就是 kafka2.0 中的broker.id,只是在 3.0 版本中 kafka 实例不再只担任 broker 角色,也有可能是 controller 角色,所以改名叫做 node 节点。
process.roles:一个节点可以充当 broker 或 controller 或两者兼而有之。按照我们事先规划好的(上文),在不同的服务器上这个值不同。多个角色用逗号分开。
listeners:broker 将使用 9092 端口,而 kraft controller 控制器将使用 9093 端口。
advertised.listeners:这里指定 kafka 通过代理暴漏的地址,如果都是局域网使用,就配置PLAINTEXT://:9092即可。
controller.quorum.voters:这个配置用于指定 controller 主控选举的投票节点,所有process.roles包含 controller 角色的规划节点都要参与,即:zimug1、zimug2、zimug3。其配置格式为:node.id1@host1:9093,node.id2@host2:9093
log.dirs:kafka 将存储数据的日志目录,在准备工作中创建好的目录。
所有 kafka 节点都要按照上文中的节点规划进行配置,完成config/kraft/server.properties配置文件的修改。
生成一个唯一的集群 ID(在一台 kafka 服务器上执行一次即可),这一个步骤是在安装 kafka2.0 版本的时候不存在的。
使用生成的集群 ID+配置文件格式化存储目录log.dirs,所以这一步确认配置及路径确实存在,并且 kafka 用户有访问权限(检查准备工作是否做对)。每一台主机服务器都要执行这个命令
格式化操作完成之后,你会发现在我们定义的log.dirs目录下多出一个 meta.properties 文件。meta.properties 文件中存储了当前的 kafka 节点的 id(node.id),当前节点属于哪个集群(cluster.id)
zimug1 zimug2 zimug3是三台应用服务器的主机名称(参考上文中的角色规划),在 linux 的`/etc/hosts`主机名与 ip 进行关系映射。将下面的命令集合保存为一个 shell 脚本,并赋予执行权限。执行该脚本即可启动 kafka 集群所有的节点,使用该脚本前提是:你已经实现了集群各节点之间的 ssh 免密登录。
如果你的安装路径和我不一样,这里/home/kafka/kafka_2.13-3.1.0需要修改一下。
一键停止 kafka 集群各节点的脚本,与启动脚本的使用方式及原理是一样的。使用该脚本前提是:你已经实现了集群各节点之间的 ssh 免密登录。