https://zhuanlan.zhihu.com/p/333201734复制
前不久,一个朋友所在的公司,业务人员整天都喊慢。
朋友是搞开发的,不是很懂DB,他说他们应用的其实没什么问题,但是就是每天一到高峰期就办理特别的慢啊,各种堵塞,一堆请求无法完成。他们没有专门的DBA,想找我帮忙看看。
我下班后打开他们的数据库看了几眼,让我大跌眼睛,数据库全部都是默认配置的参数。然后就给他们随便修改了一通,告诉他们重启了一下数据库。到了第二天他反映,大哥,你也太神了,昨天做了什么操作,我们的数据库就突然就变快了。
我说:啥也没做啊,就是根据经验值把默认参数调了一下,草率的很! 你们参数都是开箱即用的默认值。当做生产使用肯定不行。
允许的最大客户端连接数。这个参数设置大小和work_mem有一些关系。配置的越高,可能会占用系统更多的内存。通常可以设置数百个连接,如果要使用上千个连接,建议配置连接池来减少开销。
PostgreSQL使用自己的缓冲区,也使用Linux操作系统内核缓冲OS Cache。这就说明数据两次存储在内存中,首先是PostgreSQL缓冲区,然后是操作系统内核缓冲区。与其他数据库不同,PostgreSQL不提供直接IO,所以这又被称为双缓冲。PostgreSQL缓冲区称为shared_buffer,建议设置为物理内存的1/4。而实际配置取决于硬件配置和工作负载,如果你的内存很大,而你又想多缓冲一些数据到内存中,可以继续调大shared_buffer。
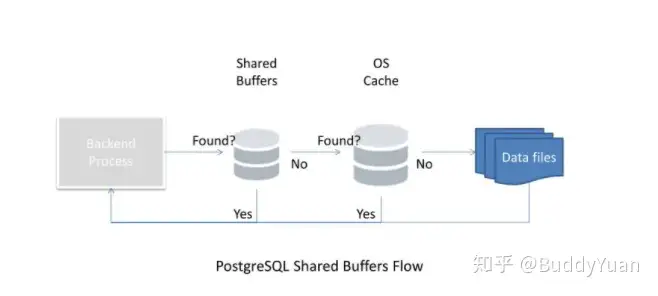
这个参数主要用于Postgre查询优化器。是单个查询可用的磁盘高速缓存的有效大小的一个假设,是一个估算值,它并不占据系统内存。由于优化器需要进行估算成本,较高的值更有可能使用索引扫描,较低的值则有可能使用顺序扫描。一般这个值设置为内存的1/2是正常保守的设置,设置为内存的3/4是比较推荐的值。通过free命令查看操作系统的统计信息,您可能会更好的估算该值。
[pg@e22 ~]$ free -g
total used free shared buff/cache available
Mem: 62 2 5 16 55 40
Swap: 7 0 7复制这个参数主要用于写入临时文件之前内部排序操作和散列表使用的内存量,增加work_mem参数将使PostgreSQL可以进行更大的内存排序。这个参数和max_connections有一些关系,假设你设置为30MB,则40个用户同时执行查询排序,很快就会使用1.2GB的实际内存。同时对于复杂查询,可能会运行多个排序和散列操作,例如涉及到8张表进行合并排序,此时就需要8倍的work_mem。
如下面案例所示,该环境使用4MB的work_mem,在执行排序操作的时候,使用的Sort Method是external merge Disk。
kms=> explain (analyze,buffers) select * from KMS_BUSINESS_HALL_TOTAL order by buss_query_info;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=262167.99..567195.15 rows=2614336 width=52) (actual time=2782.203..5184.442 rows=3137204 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=68 read=25939, temp read=28863 written=28947
-> Sort (cost=261167.97..264435.89 rows=1307168 width=52) (actual time=2760.566..3453.783 rows=1045735 loops=3)
Sort Key: buss_query_info
Sort Method: external merge Disk: 50568kB
Worker 0: Sort Method: external merge Disk: 50840kB
Worker 1: Sort Method: external merge Disk: 49944kB
Buffers: shared hit=68 read=25939, temp read=28863 written=28947
-> Parallel Seq Scan on kms_business_hall_total (cost=0.00..39010.68 rows=1307168 width=52) (actual time=0.547..259.524 rows=1045735 loops=3)
Buffers: shared read=25939
Planning Time: 0.540 ms
Execution Time: 5461.516 ms
(14 rows)复制当我们把参数修改成512MB的时候,可以看到Sort Method变成了quicksort Memory,变成了内存排序。
kms=> set work_mem to "512MB";
SET
kms=> explain (analyze,buffers) select * from KMS_BUSINESS_HALL_TOTAL order by buss_query_info;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=395831.79..403674.80 rows=3137204 width=52) (actual time=7870.826..8204.794 rows=3137204 loops=1)
Sort Key: buss_query_info
Sort Method: quicksort Memory: 359833kB
Buffers: shared hit=25939
-> Seq Scan on kms_business_hall_total (cost=0.00..57311.04 rows=3137204 width=52) (actual time=0.019..373.067 rows=3137204 loops=1)
Buffers: shared hit=25939
Planning Time: 0.081 ms
Execution Time: 8419.994 ms
(8 rows)复制指定维护操作使用的最大内存量,例如(Vacuum、Create Index和Alter Table Add Foreign Key),默认值是64MB。由于通常正常运行的数据库中不会有大量并发的此类操作,可以设置的较大一些,提高清理和创建索引外键的速度。
postgres=# set maintenance_work_mem to "64MB";
SET
Time: 1.971 ms
postgres=# create index idx1_test on test(id);
CREATE INDEX
Time: 7483.621 ms (00:07.484)
postgres=# set maintenance_work_mem to "2GB";
SET
Time: 0.543 ms
postgres=# drop index idx1_test;
DROP INDEX
Time: 133.984 ms
postgres=# create index idx1_test on test(id);
CREATE INDEX
Time: 5661.018 ms (00:05.661)复制可以看到在使用默认的64MB创建索引,速度为7.4秒,而设置为2GB后,创建速度是5.6秒
每次发生事务后,PostgreSQL会强制将提交写到WAL日志的方式。可以使用pg_test_fsync命令在你的操作系统上进行测试,fdatasync是Linux上的默认方法。如下所示,我的环境测试下来fdatasync还是速度可以的。不支持的方法像fsync_writethrough直接显示n/a。
postgres=# show wal_sync_method ;
wal_sync_method
-----------------
fdatasync
(1 row)
[pg@e22 ~]$ pg_test_fsync -s 3
3 seconds per test
O_DIRECT supported on this platform for open_datasync and open_sync.
Compare file sync methods using one 8kB write:
(in wal_sync_method preference order, except fdatasync is Linux's default)
open_datasync 4782.871 ops/sec 209 usecs/op
fdatasync 4935.556 ops/sec 203 usecs/op
fsync 3781.254 ops/sec 264 usecs/op
fsync_writethrough n/a
open_sync 3850.219 ops/sec 260 usecs/op
Compare file sync methods using two 8kB writes:
(in wal_sync_method preference order, except fdatasync is Linux's default)
open_datasync 2469.646 ops/sec 405 usecs/op
fdatasync 4412.266 ops/sec 227 usecs/op
fsync 3432.794 ops/sec 291 usecs/op
fsync_writethrough n/a
open_sync 1929.221 ops/sec 518 usecs/op
Compare open_sync with different write sizes:
(This is designed to compare the cost of writing 16kB in different write
open_sync sizes.)
1 * 16kB open_sync write 3159.780 ops/sec 316 usecs/op
2 * 8kB open_sync writes 1944.723 ops/sec 514 usecs/op
4 * 4kB open_sync writes 993.173 ops/sec 1007 usecs/op
8 * 2kB open_sync writes 493.396 ops/sec 2027 usecs/op
16 * 1kB open_sync writes 249.762 ops/sec 4004 usecs/op
Test if fsync on non-write file descriptor is honored:
(If the times are similar, fsync() can sync data written on a different
descriptor.)
write, fsync, close 3719.973 ops/sec 269 usecs/op
write, close, fsync 3651.820 ops/sec 274 usecs/op
Non-sync'ed 8kB writes:
write 400577.329 ops/sec 2 usecs/op复制事务日志缓冲区的大小,PostgreSQL将WAL记录写入缓冲区,然后再将缓冲区刷新到磁盘。在PostgreSQL 12版中,默认值为-1,也就是选择等于shared_buffers的1/32 。如果自动的选择太大或太小可以手工设置该值。一般考虑设置为16MB。
客户端执行提交,并且等待WAL写入磁盘之后,然后再将成功状态返回给客户端。可以设置为on,remote_apply,remote_write,local,off等值。默认设置为on。如果设置为off,会关闭sync_commit,客户端提交之后就立马返回,不用等记录刷新到磁盘。此时如果PostgreSQL实例崩溃,则最后几个异步提交将会丢失。
PostgreSQL使用统计信息来生成执行计划。统计信息可以通过手动Analyze命令或者是autovacuum进程启动的自动分析来收集,default_statistics_target参数指定在收集和记录这些统计信息时的详细程度。默认值为100对于大多数工作负载是比较合理的,对于非常简单的查询,较小的值可能会有用,而对于复杂的查询(尤其是针对大型表的查询),较大的值可能会更好。为了不要一刀切,可以使用ALTER TABLE .. ALTER COLUMN .. SET STATISTICS覆盖特定表列的默认收集统计信息的详细程度。
了解这两个参数以前,首先我们来看一下,触发检查点的几个操作。
使用默认值,检查点将在checkpoint_timeout=5min。也就是每5分钟触发一次。而max_wal_size设置是自动检查点之间增长的最大预写日志记录(WAL)量。默认是1GB,如果超过了1GB,则会发生检查点。这是一个软限制。在一个特殊的情况下,比如系统遭遇到短时间的高负载,日志产生几秒种就可以达到1GB,这个速度已经明显超过了checkpoint_timeout ,pg_wal目录的大小会急剧增加。此时我们可以从日志中看到相关类似的警告。
LOG: checkpoints are occurring too frequently (9 seconds apart)
HINT: Consider increasing the configuration parameter "max_wal_size".
LOG: checkpoints are occurring too frequently (2 seconds apart)
HINT: Consider increasing the configuration parameter "max_wal_size".复制所以要合理配置max_wal_size,以避免频繁的进行检查点。一般推荐设置为16GB以上,不过具体设置多大还需要和工作负荷相匹配。
min_wal_size参数是只要 WAL 磁盘使用量保持在这个设置之下,在做检查点时,旧的 WAL 文件总是被回收以便未来使用,而不是直接被删除。
而检查点的写入不是全部立马完成的,PostgreSQL会将一次检查点的所有操作分散到一段时间内。这段时间由参数checkpoint_completion_target控制,它是一个分数,默认为0.5。也就是在两次检查点之间的0.5比例完成写盘操作。如果设置的很小,则检查点进程就会更加迅速的写盘,设置的很大,则就会比较慢。一般推荐设置为0.9,让检查点的写入分散一点。但是缺点就是出现故障的时候,影响恢复的时间。
对于朋友这样的公司,没有DBA专业人士,我一般会建议他们使用PGTune来配置参数,这款工具是在线软件,链接。设置很简单,你只需要知道你的数据库版本,操作系统类型,内存数量,CPU数量,磁盘类型,连接数,还有应用的类型。就可以轻轻松松得到一些建议的参数值。
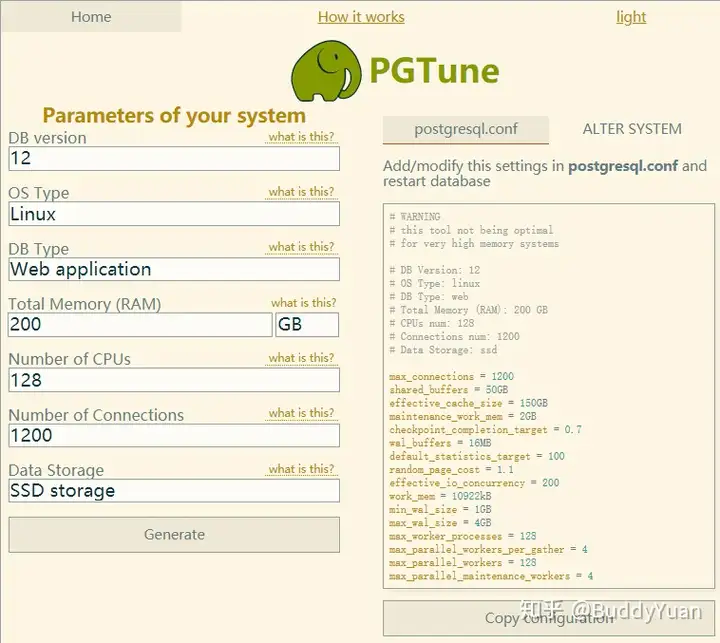
当然我们还可以使用postgresqltuner工具来优化参数,作者说受到了mysqltuner的启发,它是perl脚本写的。
这个软件使用起来也很简单,直接下载解压,执行脚本就行了。
postgresqltuner.pl --host=dbhost --database=testdb --user=username --password=qwerty复制执行输出结果如下:
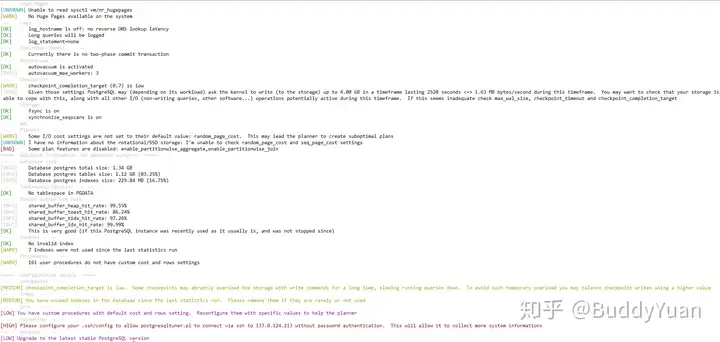
这个软件要比PGTune要专业一些,它还输出了一些操作系统的配置,同时它根据数据库当前的负载来判断内存参数是否合理,类似于Advisor。
最后来做个ending吧,系统默认的配置只适合自己玩玩,并不适合开箱即用。还是需要根据DBA的专业经验来进行相关参数的配置,如果没有专业的DBA童鞋,也可以使用PGTune或者是postgresqltuner脚本来进行一些优化,做完这些优化,系统性能将会大幅提升。