最近在学习极客时间的《正则表达式入门课》,感觉很适合入门玩,所以简单作一些笔记方便查找参考。
正则,就是正则表达式,英文是 Regular Expression,简称 RE。顾名思义,正则其实就是一种描述文本内容组成规律的表示方式。在编程语言中,正则常常用来简化文本处理的逻辑。在 Linux 命令中,它也可以帮助我们轻松地查找或编辑文件的内容,甚至实现整个文件夹中所有文件的内容替换,比如 grep、egrep、sed、awk、vim 等。另外,在各种文本编辑器中,比如 Atom,Sublime Text 或 VS Code 等,在查找或替换的时候也会使用到它。总之,正则是无处不在的,已经渗透到了日常工作的方方面面。
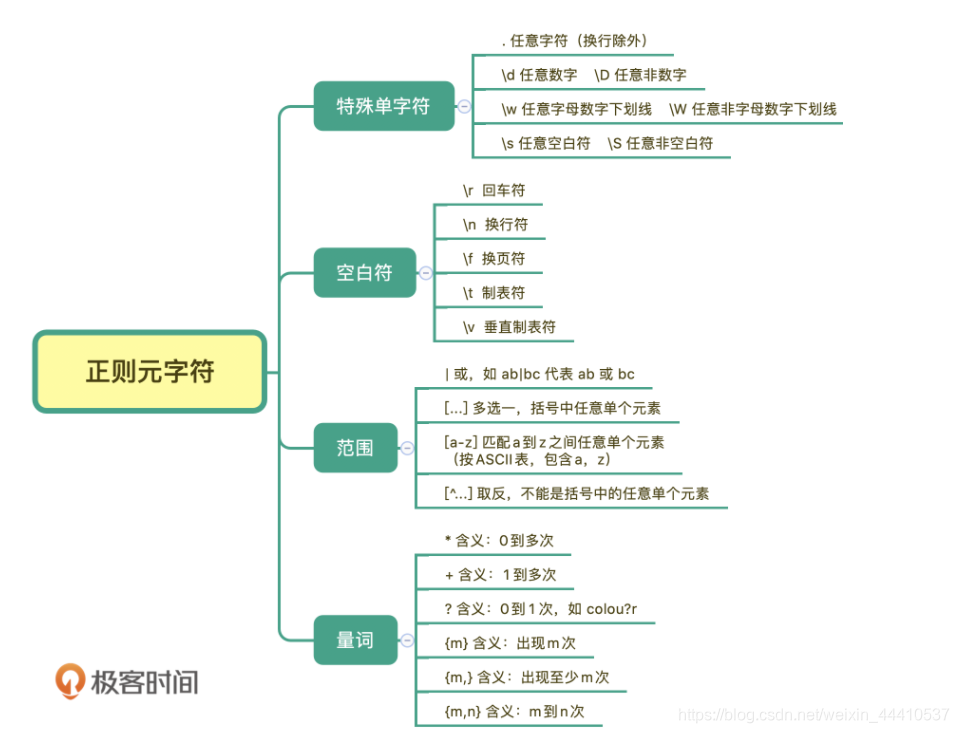
元字符
下图是正则表达式的部分元字符,包括特殊单字符、空白符、范围、量词等:
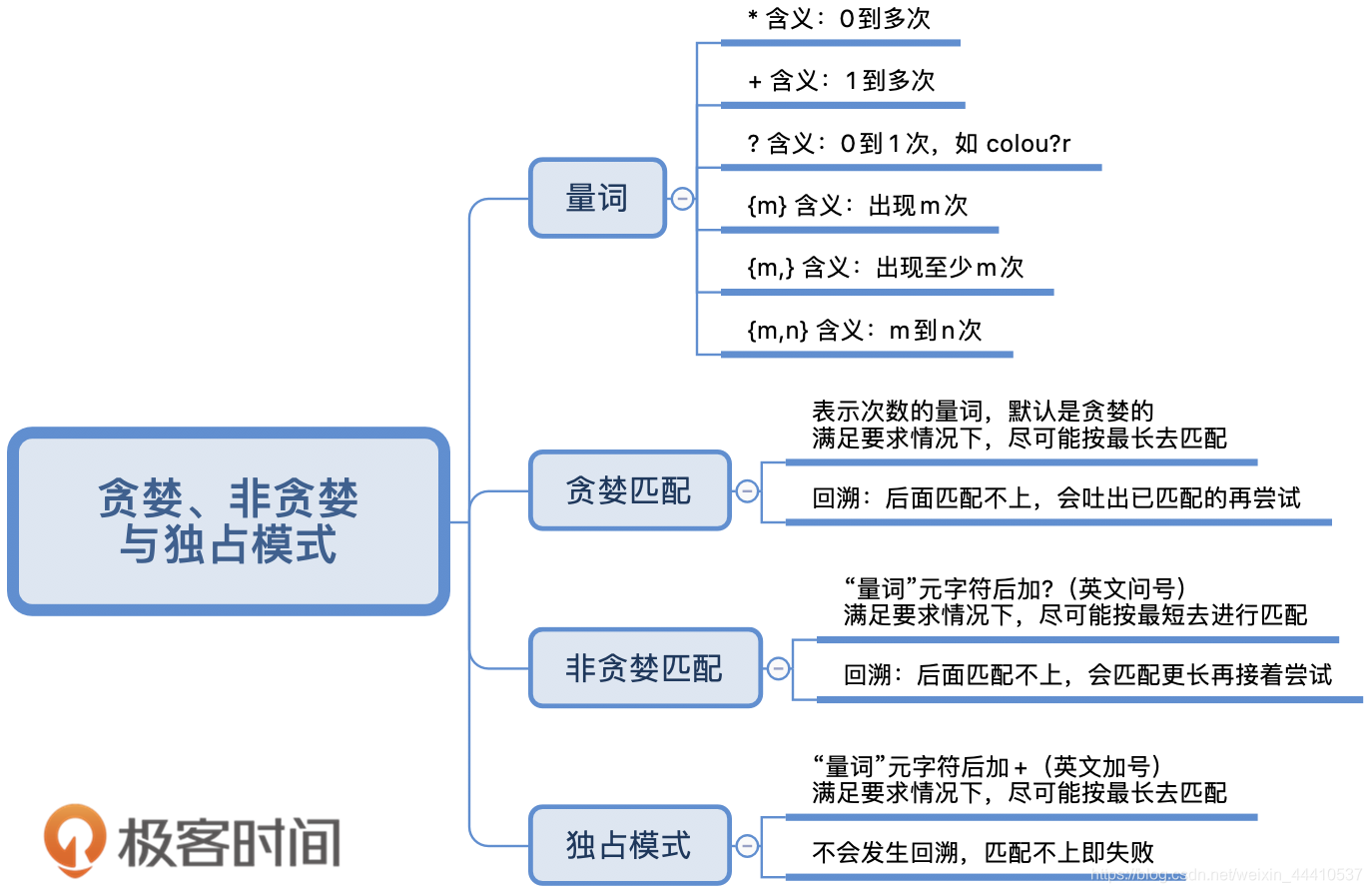
量词与贪婪
正则中量词默认是贪婪匹配,如果想要进行非贪婪匹配需要在量词后面加上问号。贪婪和非贪婪匹配都可能会进行回溯,独占模式也是进行贪婪匹配,但不进行回溯,因此在一些场景下,可以提高匹配的效率,具体能不能用独占模式需要看使用的编程语言的类库的支持情况,以及独占模式能不能满足需求。
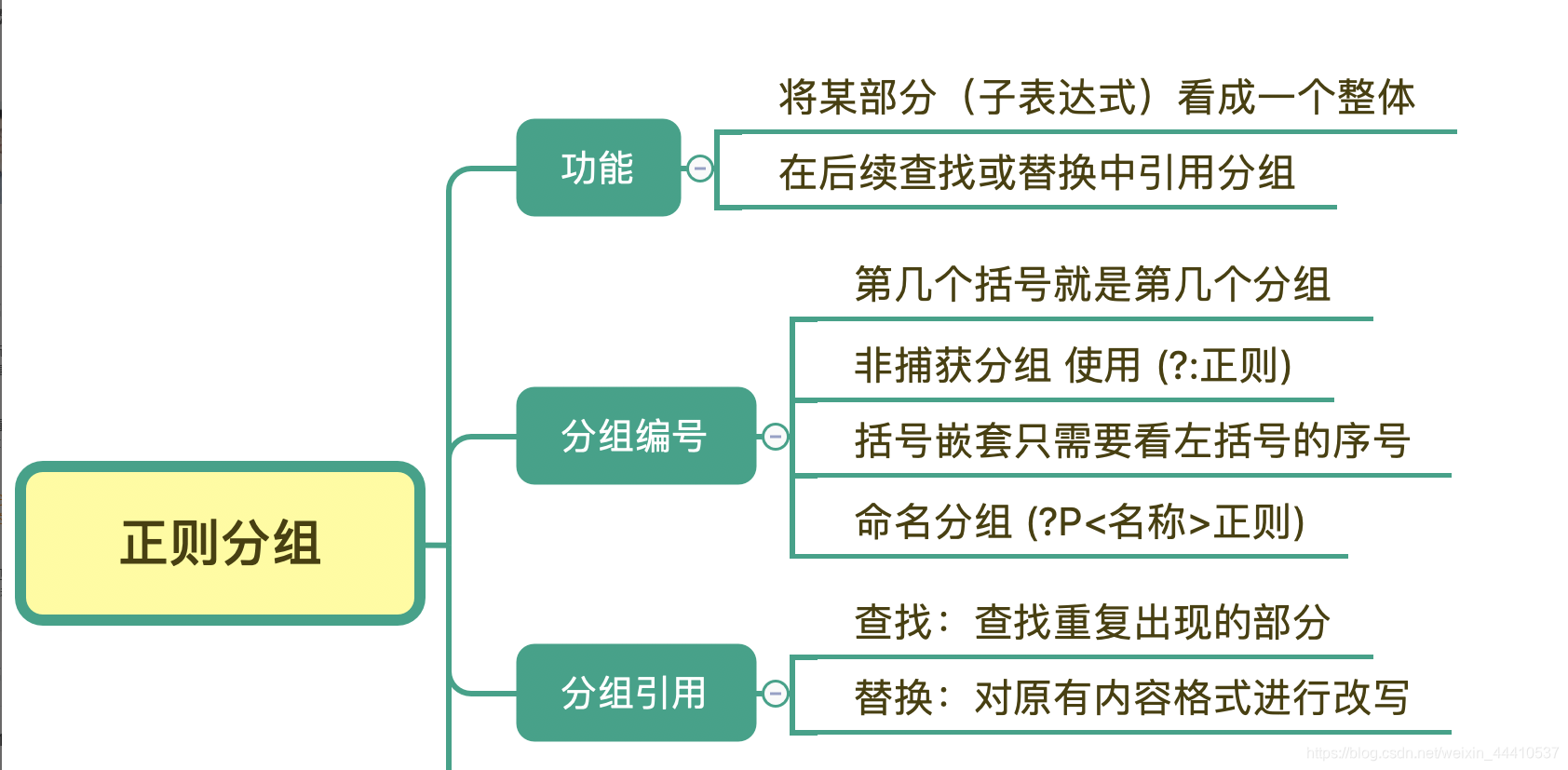
分组和引用
括号可以将某部分括起来,看成一个整体,也可以保存成一个子组,在后续查找替换的时候使用。分组编号是指,在正则中第几个括号内就是第几个分组,而嵌套括号我们只要看左括号是第几个就可以了。如果不想将括号里面的内容保存成子组,可以在括号里面加上?: 来解决。
搞懂了分组的内容,我们就可以利用分组引用,来实现将“原文本部分内容”,在查找或替换时进行再次利用,达到实现复杂文本的查找和替换工作。
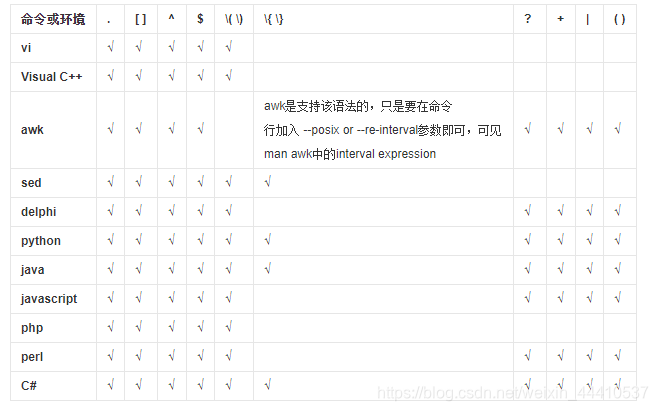
正则表达式语法支持情况