kafka2.8之后不适用zookeeper进行leader选举,使用自己的controller进行选举
1.准备工作
准备三台服务器 192.168.3.110 192.168.3.111 192.168.3.112,三台服务器都要先安装好jdk1.8,配置好环境变量, 下载好kafka3.0.0二进制压缩包
解压后进入conf/kraft目录下,修改server.properties文件

2.修改配置文件
先修改110节点,主要修改下面的几个参数 node.id要唯一,跟leader选举有关系
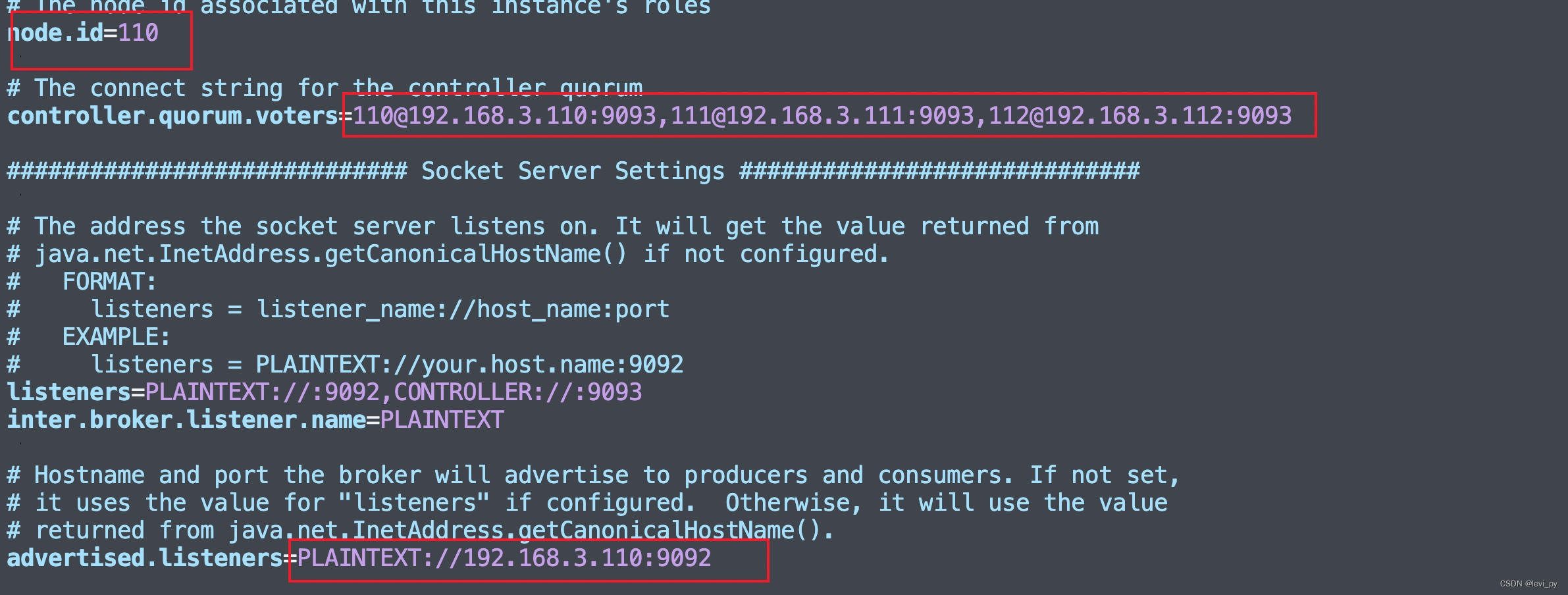
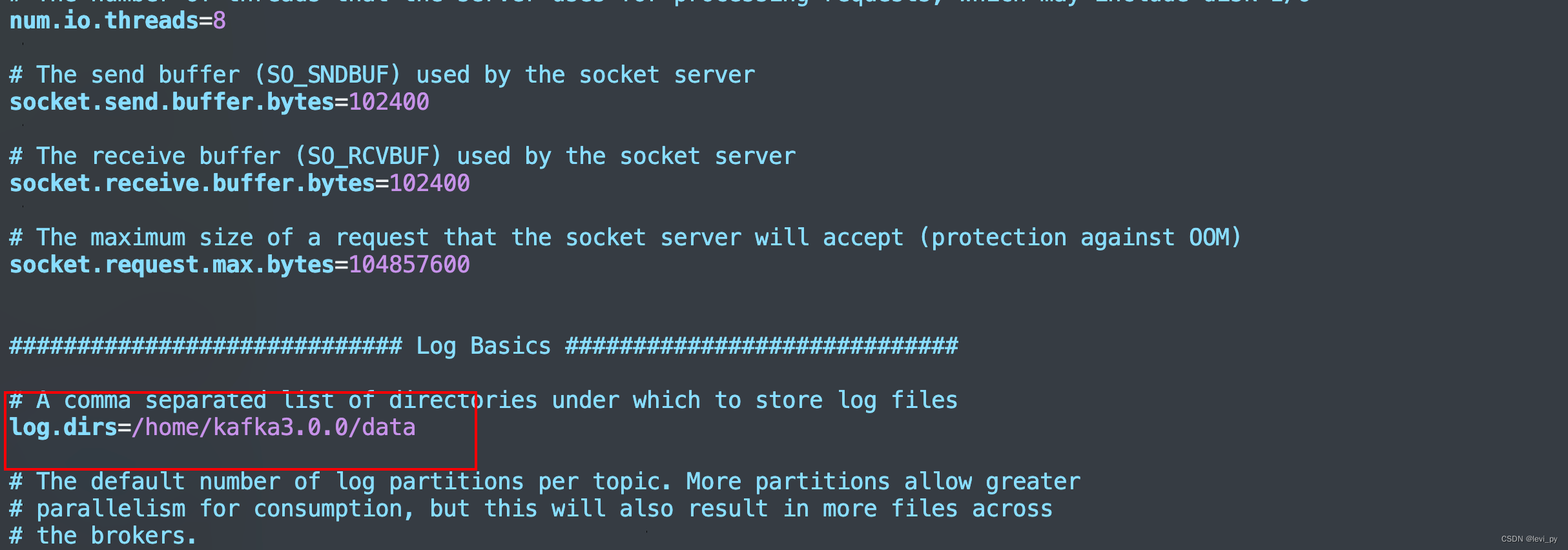
数据存储位置也要改一下
其他111和112服务器也按照改一下,把node.id改一下,ip也要改成对应的ip
3.初始化集群
在其中一台服务器上执行下面命令生成一个uuid
sh kafka3.0.0/bin/kafka-storage.sh random-uuid
- 1

用该uuid格式化kafka存储目录,三台服务器都要执行以下命令
sh kafka3.0.0/bin/kafka-storage.sh format -t 5Wr3UWh9SPGFUfX1WQlzAA -c kafka3.0.0/config/kraft/server.properties
- 1

三台服务器都启动kafka
sh kafka3.0.0/bin/kafka-server-start.sh -daemon kafka3.0.0/config/kraft/server.properties
- 1

集群启动之后,创还能一个tipic测试,在哪一台服务器上创建都行
sh kafka3.0.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic kafka --partitions 3 --replication-factor 3
- 1

查看tipoc分区情况
sh kafka3.0.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe kafka
- 1

这时候把111节点kafka关掉,会重新选举,从ar里面第一个,并且在isr中存活的副本成为leader,112成为分区2的leader
