一、前言
参考资料:
https://blog.csdn.net/QTM_Gitee/article/details/100067724
https://github.com/intel-cloud/cosbench/blob/master/COSBenchUserGuide.pdf
COSBench测Ceph对象存储:那些网上找不到的细节
1、介绍
cosbench - Cloud Object Storage Beachmark,是Intel开发的一个对象存储基准性能测试工具,支持OpenStack* Swift, Amazon* S3, Amplidata v2.3, 2.5 and 3.1, Scality*, Ceph, CDMI, Google* Cloud Storage, Aliyun OSS对象存储
2、组件
cosbench可以联机测试,主要有以下两个关键组件:
-
driver
cosbench负载生成器,主要负责工作负载生成,发布针对云对象存储的操作和收集性能统计信息
可以通过http://{driver-ip}:18088/driver地址访问 -
controller
cosbench控制器,主要负责协调负载生成器共同执行工作负载,收集来自负载生成器的基准性能测试结果
可以通过http://{controller-ip}:19088/controller地址访问
注:controller和driver角色可以部署在同一个节点上
二、安装部署
1、软件包安装
1.1、部署jre环境
下载jre版本包,解压缩至/opt目录下
wget https://javadl.oracle.com/webapps/download/AutoDL?BundleId=242050_3d5a2bb8f8d4428bbe94aed7ec7ae784 -O jre-8u251-linux-x64.tar.gz
tar -zxvf jre-8u251-linux-x64.tar.gz -C /opt/
- 1
- 2
配置jre环境变量
echo "export JAVA_HOME=/opt/jre1.8.0_251/" >> /etc/profile
echo "export CLASSPATH=/opt/jre1.8.0_251/lib" >> /etc/profile
echo "export PATH=/opt/jre1.8.0_251/bin:$PATH" >> /etc/profile
source /etc/profile
- 1
- 2
- 3
- 4
1.2、安装nmap-ncat
controller和driver之间通信需要依赖nc环境
执行 yum install -y nmap-ncat命令在线安装ncat包
1.3、安装curl
通常情况下,系统默认已经安装curl包
如系统未安装,可通过yum install curl -y命令在线安装
1.4、部署cosbench环境
官方提供的最新版本
v0.4.2存在无法启动问题MESSAGE Bundle plugins/cosbench-log4j not found.,具体详见Github-Issues#383
为规避此问题,此处选择的是v0.4.2.c4版本
wget https://github.com/intel-cloud/cosbench/releases/download/v0.4.2.c4/0.4.2.c4.zip
unzip 0.4.2.c4.zip
- 1
- 2
2、其他调整
2.1、关闭防火墙
使用过程中需要关闭防火墙或者开放指定端口,通过以下任意一种方法均可以
-
关闭防火墙
执行systemctl stop firewalld命令即可 -
开放指定端口
driver角色需要使用到18089及18088端口
controller角色需要使用到19089及19088端口
#开放driver角色服务端口
firewall-cmd --zone=public --add-port=18088/tcp --permanent
firewall-cmd --zone=public --add-port=18089/tcp --permanent
systemctl reload firewalld
#开放controller角色服务端口
firewall-cmd --zone=public --add-port=19088/tcp --permanent
firewall-cmd --zone=public --add-port=19089/tcp --permanent
systemctl reload firewalld
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2、关闭MD5校验功能
参考Github-Issues#320,基于0.4.2.c4版本,读文件测试过程中会出现无法验证下载文件完整性错误(Unable to verify integrity of data download),导致读取测试任务中断(Terminate),故此处关闭S3的MD5校验功能
修改所有节点0.4.2.c4/cosbench-start.sh配置文件,在java后添加参数-Dcom.amazonaws.services.s3.disableGetObjectMD5Validation=true
[root@node241 0.4.2.c4]# cat cosbench-start.sh | grep java
/usr/bin/nohup java -Dcom.amazonaws.services.s3.disableGetObjectMD5Validation=true -Dcosbench.tomcat.config=$TOMCAT_CONFIG -server -cp main/* org.eclipse.equinox.launcher.Main -configuration $OSGI_CONFIG -console $OSGI_CONSOLE_PORT 1> $BOOT_LOG 2>&1 &
- 1
- 2
此处,在测试过程中发现如果不关闭MD5校验功能,实际执行读成功率近乎为0,读性能数据也接近为0;关闭MDS校验功能后读成功率为100%,读性能数据正常展示。
三、配置使用
cosbench工具使用按照流程可分为以下几个步骤:参数配置–服务启动–提交测试–分析结果
示例使用三个节点联机测试,配置示意如下:
| 节点主机名 | 节点IP地址 | cosbench角色 |
|---|---|---|
| node241 | 66.66.66.241 | controller、driver |
| node242 | 66.66.66.242 | driver |
| node243 | 66.66.66.243 | driver |
1、参数配置
controller和driver依赖不同系统配置来启动服务,在启动controller和driver服务时,需要先行定义角色配置
1.1、controller配置
controller在初始化时读取conf/controller.conf配置文件启动控制器服务
[root@node241 0.4.2.c4]# cat conf/controller.conf
[controller]
concurrency=1
drivers=3
log_level=INFO
log_file=log/system.log
archive_dir=archive
[driver1]
name=driver1
url=http://66.66.66.241:18088/driver
[driver2]
name=driver2
url=http://66.66.66.242:18088/driver
[driver3]
name=driver3
url=http://66.66.66.243:18088/driver

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
[controller]
- concurrency
默认值为1,表示可以同时执行的工作负载数量 - drivers
默认值为1,表示此controller控制的driver数量 - log_level
默认值为INFO,可选值为TRACE、DEBUG、INFO、WARN、ERROR,表示日志打印等级 - log_file
默认值为log/system.log,表示日志文件存放位置 - archive_dir
默认值为archive,表示工作负载结果存放位置,当参数值为archive,则工作负载结果存放于0.4.2/archive目录内
- concurrency
-
[driverx]
当有多个driver时,第{n}个driver命名为[driver{n}]- name
用于标识driver节点的标签,名称可以自定义 - url
访问driver节点的地址
- name
1.2、driver配置
driver在初始化时读取conf/driver.conf配置文件启动负载器服务
[root@node241 0.4.2.c4]# cat conf/driver.conf
[driver]
name=127.0.0.1:18088
url=http://127.0.0.1:18088/driver
- 1
- 2
- 3
- 4
- [driver]
- name
用于标识driver节点的标签,名称可以自定义 - url
访问driver节点的地址
- name
2、服务启动
2.1、controller启动
在controller角色节点执行以下命令启动controller
[root@node241 0.4.2.c4]# sh start-controller.sh
检查controller服务启动情况
[root@node241 0.4.2.c4]# lsof -i:19088
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 30012 root 88u IPv6 184509 0t0 TCP *:19088 (LISTEN)
[root@node241 0.4.2.c4]# ps -aux | grep 30012
root 30012 0.6 4.2 4585852 165528 pts/0 Sl 15:51 0:06 java -Dcosbench.tomcat.config=conf/controller-tomcat-server.xml -server -cp main/org.eclipse.equinox.launcher_1.2.0.v20110502.jar org.eclipse.equinox.launcher.Main -configuration conf/.controller -console 19089
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注:若节点需要同时启动controller和driver角色,也可以使用sh start-all.sh命令启动(start-all.sh=start-driver.sh+start-controller.sh)
2.2、driver启动
在所有driver角色节点执行以下命令启动driver
[root@node242 0.4.2.c4]# sh start-driver.sh
检查driver服务启动情况
[root@node242 0.4.2.c4]# lsof -i:18088
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 23102 root 100u IPv6 161668 0t0 TCP *:18088 (LISTEN)
[root@node242 0.4.2.c4]# ps -aux | grep 23102
root 23102 0.2 5.2 4597000 203344 pts/0 Sl 15:12 0:07 java -Dcosbench.tomcat.config=conf/driver-tomcat-server.xml -server -cp main/org.eclipse.equinox.launcher_1.2.0.v20110502.jar org.eclipse.equinox.launcher.Main -configuration conf/.driver -console 18089
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3、提交测试
可以使用以下两种方法提交测试(示例测试参数文件为config.xml)
- 使用命令行接口
在controller节点cosbench目录下,使用sh cli.sh submit {test.xml}命令提交测试
[root@node241 0.4.2.c4]# sh cli.sh submit conf/config.xml
- 1
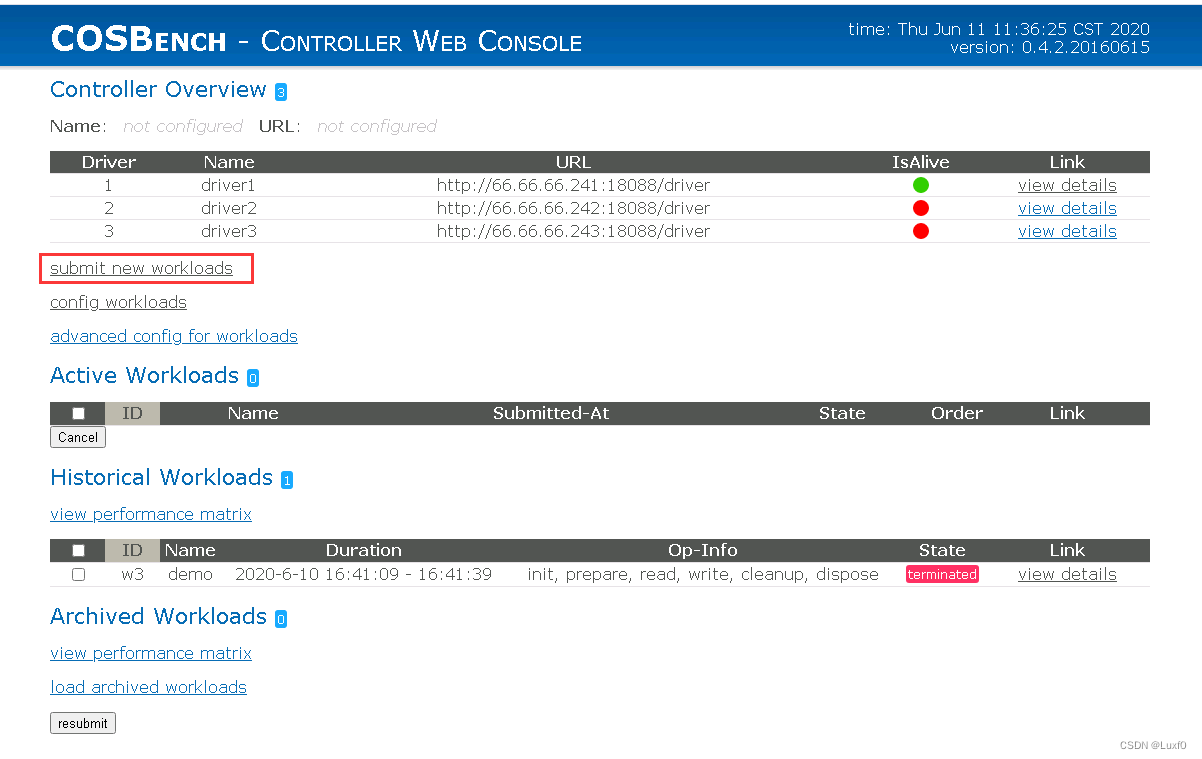
- 使用web控制台
web访问控制台地址http://{controller-ip}:19088/controller,点击submit new workloadsurl,提交测试文件即可
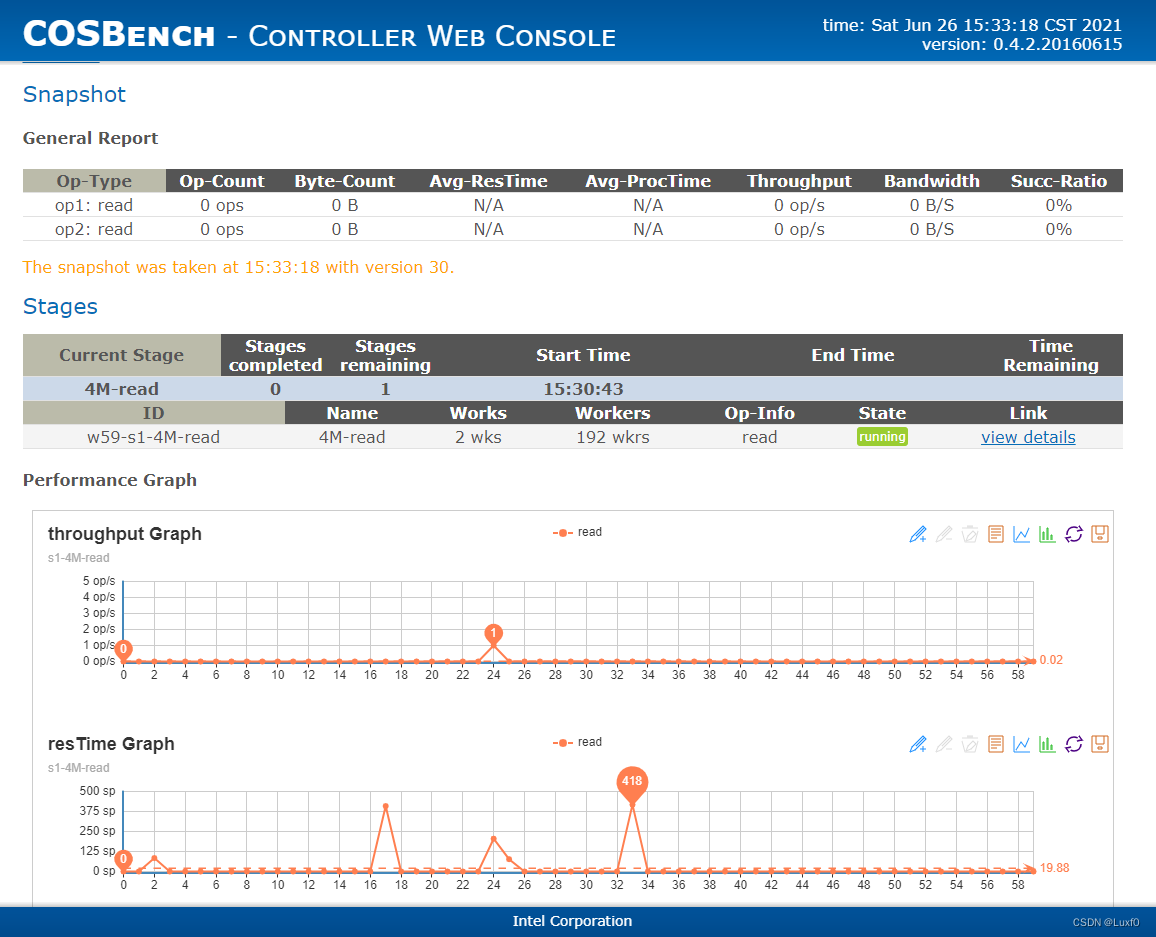
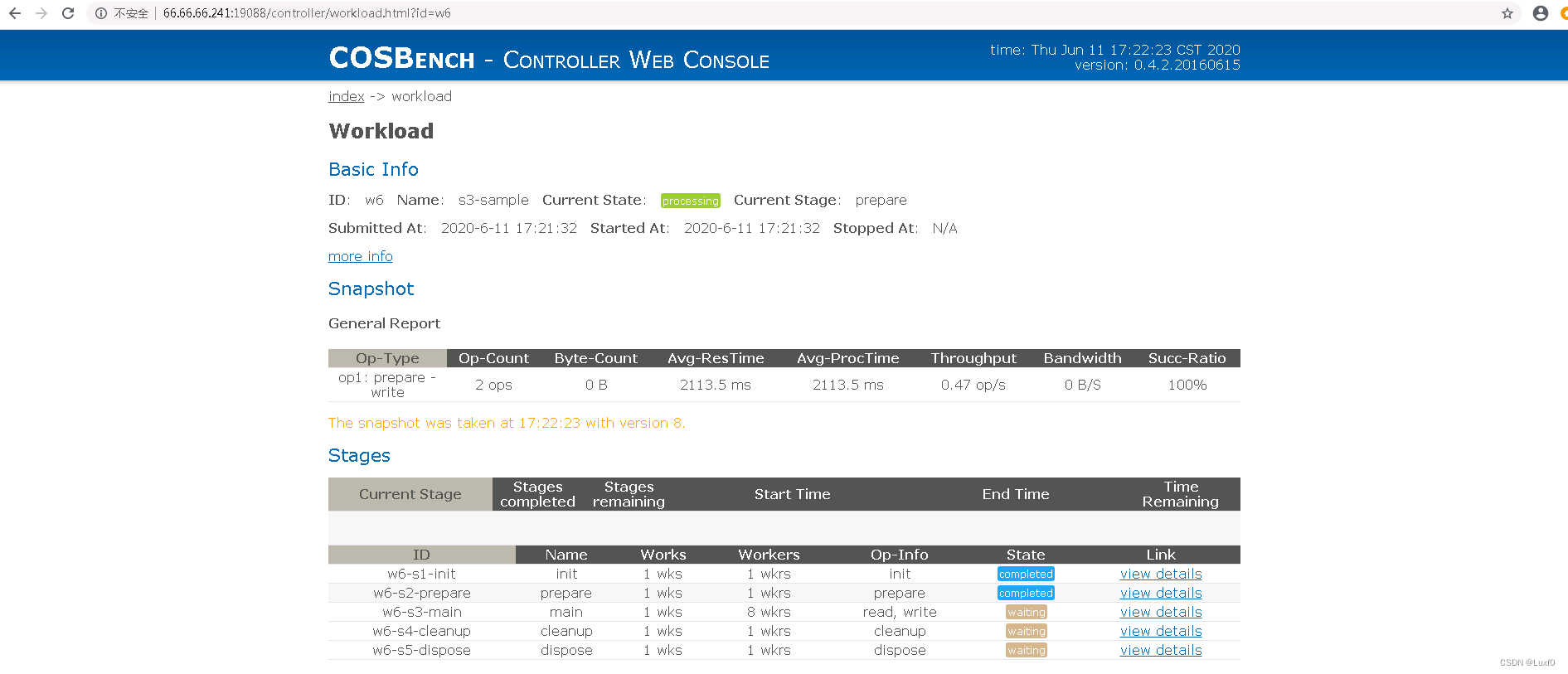
4、分析结果
-
使用命令行接口
在controller节点cosbench目录下,使用sh cli.sh info命令查看当前运行任务 -
使用web控制台
web访问控制台地址http://{controller-ip}:19088/controller,点击对应任务view detailsurl,查看当前运行状态及结果
四、选择表达式
1、概述
在测试参数文件中,auth、storage、storage、work定义中支持config属性配置,该属性包含一个可选的参数列表(使用键值对格式表示,如"a=a_val;b=b_val")
在这里插入图片描述

- 在参数列表中,常用的键包括containers、objects、sizes,用来指定如何选择容器、对象、大小
2、选择器
| 表达式 | 格式 | 注释 |
|---|---|---|
| constant | c(number) | 仅使用指定数字 一般在常用于对象大小定义,如sizes=c(512)KB,则表示对象大小为512KB |
| uniform | u(min, max) | 从(min,max)中均匀选择 u(1,100)表示从1到100中均匀地选取一个数字,选择是随机的,有些数字可能被选中多次,有些数字永远不会被选中 |
| range | r(min,max) | 从(min,max)递增选择 r(1,100)表示从1到100递增地选取一个数字(每个数字只被选中一次),这通常被用于特殊work(init、prepare、cleanup、dispose) |
| sequential | s(min,max) | 从(min,max)递增选择 s(1,100)表示从1到100递增地选取一个数字(每个数字只被选中一次),这通常被用于常规work |
| histogram | h(min1|max1|weight1,…) | 它提供了一个加权直方图生成器,要配置它,需要指定一个逗号分隔的桶列表,其中每个桶由一个范围和一个整数权重定义。例如: h(1|64|10,64|512|20,512|2048|30)KB 其中定义了一个配置文件,其中(1,64)KB被加权为10,(64,512)KB被加权为20,(512,2048)KB被加权为30.权重之和不一定是100 |
注:一般常用的选择器通常为c(number)、u(min,max)、s(min,max)
3、参数组合
基于元素类型和工作类型的选择器有额外的约束,下面两个表列出了允许的组合
- 元素类型选择器
| Key | constant (c(num)) | uniform (u(min,max)) | range (r(min,max)) | sequential (s(min,max)) | histogram(h(min|max|ratio)) |
|---|---|---|---|---|---|
| containers | ✔ | ✔ | ✔ | ✔ | |
| objects | ✔ | ✔ | ✔ | ✔ | |
| sizes | ✔ | ✔ | ✔ | ✔ |
- 工作类型选择器
| Key | init | prepare | normal (read) | normal (write) | normal (delete) | cleanup | dispose |
|---|---|---|---|---|---|---|---|
| containers | r(), s() | r(), s() | c(), u(), r(), s() | c(), u(), r(), s() | c(), u(), r(), s() | r(), s() | r(), s() |
| objects | r(), s() | c(), u(), r(), s() | c(), u(), r() | c(), u(), r(), s() | r(), s() | ||
| sizes | c(), u(), h() | c(), u(), h() |
五、负载配置详解
本小节主要介绍工作负载参数定义,通常为标签对目录结构的xml文件,目录结构示意如下:
<workload>
<auth /> #可选项
<storage />
<workflow>
<workstage>
<auth /> #可选项
<storage /> #可选项
<work />
<auth /> #可选项
<storage /> #可选项
<operation />
</workstage>
</workflow>
</workload>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
相关说明:
- 参数定义可分为多个级别,具体流程为
workload-workstage-work-operation - 身份验证定义(auth)和存储定义(storage)可以在多个级别中定义
- 通常只在workload工作负载级别定义即可
- 当在多个级别定义,低级别定义优先于高级别定义,如在workload和work两个级别分别定义不同的auth和storage,最终以最低级别(work)定义为准
- 一个workload可以定义一个或多个workstage(多个测试项时指定多个workstage),一个workstage可以定义一个或多个work(多个客户端测试时指定多个work),一个work可以定义一个或多个operation(混合读写操作时指定多个operation)
- 多个workstage执行顺序是串行的,当执行完一个之后才会执行下一个
- 多个work执行顺序是并行的,当执行到具体workstage时,其定义的多个work同时执行
<?xml version="1.0" encoding="UTF-8" ?>
<workload name="s3-sample" description="sample benchmark for s3">
<storage type="s3" config="accesskey=<accesskey>;secretkey=<scretkey>;proxyhost=<proxyhost>;proxyport=<proxyport>;endpoint=<endpoint>" />
<workflow>
<workstage name="init">
<work type="init" workers="1" config="cprefix=s3testqwer;containers=r(1,2)" />
</workstage>
<workstage name="prepare">
<work type="prepare" workers="1" config="cprefix=s3testqwer;containers=r(1,2);objects=r(1,10);sizes=c(64)KB" />
</workstage>
<workstage name="main">
<work name="main" workers="8" runtime="30">
<operation type="read" ratio="80" config="cprefix=s3testqwer;containers=u(1,2);objects=u(1,10)" />
<operation type="write" ratio="20" config="cprefix=s3testqwer;containers=u(1,2);objects=u(11,20);sizes=c(64)KB" />
</work>
</workstage>
<workstage name="cleanup">
<work type="cleanup" workers="1" config="cprefix=s3testqwer;containers=r(1,2);objects=r(1,20)" />
</workstage>
<workstage name="dispose">
<work type="dispose" workers="1" config="cprefix=s3testqwer;containers=r(1,2)" />
</workstage>
</workflow>
</workload>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
workload定义(工作负载)
<?xml version="1.0" encoding="UTF-8" ?>
<workload name="s3-sample" description="sample benchmark for s3">
</workload>
- 1
- 2
- 3
- name:工作负载名称定义
- description:工作负载一些相关描述
1、auth定义(认证机制)
cosbench认证机制有none、mock、swauth、keystone、httpauth
- none (do nothing, default)
默认值,不进行任何操作
<auth type="none" config="" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| logging | 布尔型 | false | 将信息打印到日志 |
| retry | 整型 | 0 | 指定认证失败时的重试次数 |
| Caching | 布尔型 | false | 是否缓存认证信息 |
| 参数 | 类型 | 默认值 | 注释 |
| — | — | — | — |
| type | 字符串 | “cdmi” | 选项:“cdmi”或“non-cdmi”,它表示要使用的内容类型,“cdmi”表示存储访问将遵循cdmi内容类型,“non-cdmi”表示存储访问将遵循非cdmi内容类型. |
| Customer_headers | 字符串 | 这是一个实验参数,用于查看是否可能支持cdmi衍生物,这可能需要额外的标头。 可以在不通知的情况下移除该参数。 |
- mock (delay specified time)
延迟指定时间
<auth type="mock" config="" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| token | 字符串 | “token” | Token字符串 |
| delay | 长整型 | 20 | 延迟时间(以毫秒为单位) |
| retry | 整型 | 0 | 指定认证失败时的重试次数 |
- swauth (for OpenStack Swift)
适用于OpenStack Swift
<auth type="swauth" config="username={username};password={password};url=http://{controller-ip}:8080/auth/v1.0 />"
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| url | 字符串 | http:/{controller-ip}:8080/auth/v1.0 | auth节点的URL,一般为controller节点 |
| username | 字符串 | 用于认证的用户名,语法account:user | |
| password | 字符串 | 用于认证的密码 | |
| timeout | 整型 | 30,000 | 连接超时值(以毫秒为单位) |
| retry | 整型 | 0 | 指定认证失败时的重试次数 |
- keystone (for OpenStack Swift)
适用于OpenStack Swift
<auth type="keystone" config="username={username};password={password};tenant_name={tenant_name};url=http://{controller-ip}:8080/v2.0;service=swift"/>
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| url | 字符串 | http://{controller-ip}:8080/auth/v2.0 | auth节点的URL |
| username | 字符串 | 用于认证的用户名。 语法account:user | |
| password | 字符串 | 用于认证的密码 | |
| tenant_name | 字符串 | 用户所属的租户名称 | |
| service | 字符串 | swift | 请求的服务 |
| timeout | 整型 | 30,000 | 连接超时值(毫秒) |
| retry | 整型 | 0 | 指定认证失败时的重试次数 |
- httpauth (Http BASIC/DIGEST)
<auth type="httpauth" config="username={username};password={password};auth_url=http://{controller-ip}:8080/" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| auth_url | 字符串 | http://{controller-ip}:8080/ | auth节点的URL |
| username | 字符串 | 用于认证的用户名。 | |
| password | 字符串 | 用于认证的密码 | |
| timeout | 整型 | 30,000 | 连接超时值(毫秒) |
| retry | 整型 | 0 | 指定认证失败时的重试次数 |
2、storage定义(存储系统)
- none (do nothing, default)
默认值,不进行任何操作
<storage type="none" config="" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| logging | 布尔型 | false | 将信息打印到日志 |
- delay specified time
<storage type="mock" config="" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| logging | 布尔型 | false | 将信息打印到日志 |
| size | 整型 | 1024 | 对象大小(字节) |
| delay | 整型 | 10 | 延迟时间(毫秒) |
| errors | 整型 | 0 | 设置错误限制以模拟失败 |
| printing | 布尔型 | False | 是否打印出数据内容 |
- Swift (OpenStack Swift)
<storage type="swift" config="" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| timeout | 整型 | 30,000 | 连接超时值(毫秒) |
| token | 字符串 | AUTH_xxx | 认证令牌,只有在用户希望绕过认证时才需要此参数。 |
| storage_url | 字符串 | http://127.0.0.1:8080/auth/v1.0 | 存储URL,只有在用户希望绕过认证时才需要此参数。 |
| policy | 字符串 | 存储策略是Swift 2.0中引入的一项功能,允许应用程序在每个容器的基础上为其存储选择一组不同的特征。 有关完整信息,请参阅最新的Swift文档:http://docs.openstack.org/developer/swift/overview_architecture.html. 只有当用户希望利用不同的存储策略而不是默认存储策略时,才需要它。 |
- Ampli (Amplidata)
<storage type="ampli" config="host={controller-ip};port=8080;nsroot=/namespace;policy={policy-id}" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| timeout | 整型 | 30,000 | 连接超时值(毫秒) |
| host | 字符串 | 要连接的controller节点IP | |
| port | 整型 | 端口 | |
| nsroot | 字符串 | “/namespace” | 命名空间root |
| policy | 字符串 | 命名空间将访问的策略ID |
- S3 (Amazon S3)
<storage type="s3" config="accesskey={accesskey};secretkey={scretkey};endpoint={endpoint}; proxyhost={proxyhost};proxyport={proxyport}" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| timeout | 整型 | 30,000 | 连接超时值(毫秒) |
| accesskey | 字符串 | base64编码的用户名 | |
| secretkey | 字符串 | base64编码的密码 | |
| endpoint | 字符串 | http://s3.amazonaws.com | 端点url(s3存储公开以供外部访问的url). |
| proxyhost | 字符串 | 非必选项,按需配置,http代理主机名或IP地址 | |
| proxyport | 整型 | 非必选项,按需配置,http代理端口。 |
- Sproxyd (Scality)
<storage type="sproxyd" config="hosts={host1,host2,…};port={port};base_path={path};pool_size={maxTotal,maxPerRoute}" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| hosts | 字符串 | 127.0.0.1 | 以逗号分隔的主机名/IP地址列表。 使用简单的循环算法在所有主机上实现请求的负载平衡 |
| port | 整型 | 81 | connector使用的端口 |
| base_path | 字符串 | /proxy/chord | sproxyd配置文件的路径(此配置文件必须具有by_path_enabled=1) |
| pool_size | 整型或逗号分隔的整数对 | 60,10 | 第一个值是连接池的大小。 第二个值(如果提供)是给定HTTP路由的最大连接数。 |
- Cdmi (SNIA CDMI)
<storage type="cdmi" config="type=<cdmi|non-cdmi;custom_headers=<header:value_reference>" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| type | 字符串 | “cdmi” | 选项:“cdmi”或“non-cdmi”,它表示要使用的内容类型,“cdmi”表示存储访问将遵循cdmi内容类型,“non-cdmi”表示存储访问将遵循非cdmi内容类型 |
| Customer_headers | 字符串 | 这是一个实验参数,用于查看是否可能支持cdmi衍生物,这可能需要额外的标头。 可以在不通知的情况下移除该参数 |
- Cdmi_swift (SNIA CDMI for swift)
<storage type="cdmi_swift" config="" />
- 1
config参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| timeout | 整型 | 30,000 | 连接超时值(毫秒) |
- librados (for Ceph)
<storage type="librados" config="endpoint={endpoint};accesskey={accesskey};secretkey={secretkey}" />
- 1
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| endpoint | 字符串 | 127.0.0.1 | 端点可以是例如监视器节点。 |
| accesskey | 字符串 | 用户名如“admin”。 | |
| secretkey | 字符串 | secretkey是admin keyring的key。 |
3、workstage定义(工作阶段)
<workstage name="<name>" >
</workstage>
- 1
- 2
- name:阶段的一个名字
4、work定义
4.1、通用格式
<work name="main" type="normal" workers="128" interval="5" division="none" runtime="60" rampup="0" rampdown="0" totalOps="0" totalBytes="0" afr=”200000” config="" >
. . .
</work>
- 1
- 2
- 3
有一种常规work(normal)和四种特殊work(init、prepare、cleanup、dispose),上面示例参数针对所有组合情况,不同工作类型会有不同的参数组合,一般规则如下:
- 通常使用
workers控制负载情况 - 通常使用
runtime(包括rampup和rampdown)、totalOps、totalBytes控制负载什么时候结束,一般一个work定义只能设置其中一种,特殊work不需要定义此项参数
参数列表如下:
| 属性 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| name | 字符串 | work的一个名称 | |
| type | 字符串 | normal | work的类型,可选参数为normal、init、prepare、cleanup、dispose、delay |
| workers | 整型 | 并行进行work的workers数量,即同时起多少个线程运行负载 | |
| interval | 整型 | 5 | 性能快照之间的间隔,即多久统计一次性能数据 |
| division | 字符串 | none | 控制workers之间的work分配方式,可选参数为none、container、object |
| runtime | 整型 | 0 | 结束选项,work将执行多少秒 |
| rampup | 整型 | 0 | 结束选项,加速工作负载的秒数(需要多少秒来增加工作负载);此时间不包括在runtime中 |
| rampdown | 整型 | 0 | 结束选项,减速工作负载的秒数(需要多少秒来减少工作负载);此时间不包括在runtime中 |
| totalOps | 整型 | 0 | 结束选项,将执行多少个操作;应该是workers的倍数 |
| totalBytes | 整型 | 0 | 结束选项,要传输多少字节,应该是workers和size的乘积的倍数。 |
| driver | 字符串 | 将执行此work的driver,默认情况下,所有driver都将参与执行,可手动指定该work由哪个driver执行负载测试 | |
| afr | 整型 | 200000(常规work类型)0(特殊work类型) | 可接受的失败率,是百万分之一。 |
参数解释
- division(划分策略)
1.1. division用于将一个work划分为多个不重叠区域,这些区域有着较小的容器或者对象范围,支持的策略有none、container、object
1.2. 不同阶段有不同的默认划分策略
对于init/dispose,默认的划分策略为container
对于prepare/cleanup,默认的划分策略为object
对于常规work,默认划分策略为none
#示例参数如下:
<work name="main" workers="4" runtime="300" division="?">
<operation type="read" ratio="100" config="containers=u(1,8);objects=u(1,1000)" />
</work>
- 1
- 2
- 3
- 4
若
division="container",则表示在当前work中,worker通过container划分负载区域范围,访问模式示例如下:
注:workers数量不允许超过container
| Worker | Container Range | Object Range |
|---|---|---|
| #1 | 1-2 | 1-1000 |
| #2 | 3-4 | 1-1000 |
| #3 | 5-6 | 1-1000 |
| #4 | 7-8 | 1-1000 |
若
division="object",则表示在当前work中,worker通过object划分负载区域范围,访问模式示例如下:
注:wrokers数量不允许超过objects
| Worker | Container Range | Object Range |
|---|---|---|
| #1 | 1-8 | 1-250 |
| #2 | 1-8 | 251-500 |
| #3 | 1-8 | 501-750 |
| #4 | 1-8 | 751-1000 |
4.2、特殊work
4.2.1、通用格式
<work type="init|prepare|cleanup|dispose|delay" workers="{number}"
config="{key}={value};{key}={value}" />
- 1
- 2
特殊work与常规work有以下不同的地方:
- 它内部采用
totalOps并计算具体数值来控制负载运行时长,因此不需要额外去定义结束选项 - 它有隐形定义的操作,因此不需要额外再定义具体操作内容(
operation) - "delay"与其他不同,这会导致work只休眠指定的秒数
4.2.2、支持的特殊work
- init(批量创建特定桶)
<work type="init" workers="4" config="containers=r(1,100)" />
- 1
参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| containers | 字符串 | 容器选择表达式;例如: c(1), r(1,100) | |
| cprefix | 字符串 | mycontainers_ | 容器前缀 |
| csuffix | 字符串 | 容器后缀 |
- prepare(批量创建特定对象)
<work type="prepare" workers="4" config="containers=r(1,10);objects=r(1,100);sizes=c(64)KB" />
- 1
参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| containers | 字符串 | 容器选择表达式;例如: c(1), u(1,100) | |
| cprefix | 字符串 | mycontainers_ | 容器前缀 |
| csuffix | 字符串 | 容器后缀 | |
| objects | 字符串 | 对象选择表达式;例如 c(1), u(1,100) | |
| oprefix | 字符串 | myobjects_ | 对象前缀 |
| osuffix | 字符串 | 对象后缀 | |
| sizes | 字符串 | 带单位(B/KB/MB/GB)的大小选择表达式;例如: c(128)KB, u(2,10)MB | |
| chunked | 布尔型 | False | 是否以chunked模式上传数据 |
| content | 字符串 | random | 使用随机数据或全零填充对象内容,可选参数为random、zero |
| createContainer | 布尔型 | False | 创建相关容器(如果不存在) |
| hashCheck | 布尔型 | False | 做与对象完整性检查相关的工作 |
- cleanup(批量删除特定对象)
<work type="cleanup" workers="4" config="containers=r(1,10);objects=r(1,100)" />
- 1
参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| containers | 字符串 | 容器选择表达式;例如 c(1), u(1,100) | |
| cprefix | 字符串 | mycontainers_ | 容器前缀 |
| csuffix | 字符串 | 容器后缀 | |
| objects | 字符串 | 对象选择表达式;例如 c(1), u(1,100) | |
| oprefix | 字符串 | myobjects_ | 对象前缀 |
| osuffix | 字符串 | 对象后缀 | |
| deleteContainer | 布尔型 | False | 删除相关容器(如果存在) |
- dispose(批量删除特定桶)
<work type="dispose" workers="4" config="containers=r(1,100)" />
- 1
参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| containers | 字符串 | 容器选择表达式;例如 c(1), u(1,100) | |
| cprefix | 字符串 | mycontainers_ | 容器前缀 |
| csuffix | 字符串 | 容器后缀 |
- delay(插入几秒的延迟)
<workstage name=”delay” closuredelay=”60” >
<work type="delay" workers="1" />
</workstage>
- 1
- 2
- 3
注:closuredelay即延迟时间(单位为秒)
5、operation定义
注:ratio为当前操作数占总操作数的比例,单个work定义中,所有operation的ratio之和为100
- read(读)
<operation type="read" ratio="70" config="containers=c(1);objects=u(1,100)" />
- 1
参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| containers | 字符串 | 容器选择表达式;例如 c(1), u(1,100) | |
| cprefix | 字符串 | mycontainers_ | 容器前缀 |
| csuffix | 字符串 | 容器后缀 | |
| objects | 字符串 | 对象选择表达式;例如 c(1), u(1,100) | |
| oprefix | 字符串 | myobjects_ | 对象前缀 |
| osuffix | 字符串 | 对象后缀 | |
| hashCheck | 布尔型 | False | 做与对象完整性检查相关的工作 |
- write(写)
<operation type="write" ratio="20" config="containers=c(2);objects=u(1,1000);sizes=c(2)MB" />
- 1
参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| containers | 字符串 | 容器选择表达式;例如 c(1), u(1,100) | |
| cprefix | 字符串 | mycontainers_ | 容器前缀 |
| csuffix | 字符串 | 容器后缀 | |
| objects | 字符串 | 对象选择表达式;例如 c(1), u(1,100) | |
| oprefix | 字符串 | myobjects_ | 对象前缀 |
| osuffix | 字符串 | 对象后缀 | |
| sizes | 字符串 | 带单位(B/KB/MB/GB)的大小选择表达式;例如: c(128)KB, u(2,10)MB | |
| chunked | 布尔型 | False | 是否以chunked模式上传数据 |
| content | 字符串 | random | 使用随机数据或全零填充对象内容,可选参数为random、zero |
| hashCheck | Boolean | False | 做与对象完整性检查相关的工作 |
- filewrite(上传)
<operation type="filewrite" ratio="20" config="containers=c(2);fileselection=s;files=/tmp/testfiles" />
- 1
参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| containers | 字符串 | 容器选择表达式;例如 c(1), u(1,100) | |
| cprefix | 字符串 | mycontainers_ | 容器前缀 |
| csuffix | 字符串 | 容器后缀 | |
| fileselection | 字符串 | 哪种选择器应该只使用put选择器标识符(例如,s代表顺序)。* | |
| files | 字符串 | 包含要上载的文件的文件夹的路径,路径必须存在 | |
| chunked | 布尔型 | False | 是否以chunked模式上传数据 |
| hashCheck | 布尔型 | False | 做与对象完整性检查相关的工作 |
注:对象不按文件名读取。Java以随机方式读取文件夹中的文件。在第一个对象第二次被选中之前,使用“Sequential”选择器确保每个对象将被选中一次。在工作定义中使用totalOps或runtime限制对象的数量
- delete(删除)
<operation type="delete" ratio="10" config="containers=c(2);objects=u(1,1000)" />
- 1
参数列表如下:
| 参数 | 类型 | 默认值 | 注释 |
|---|---|---|---|
| containers | 字符串 | 容器选择表达式;例如 c(1), u(1,100) | |
| cprefix | 字符串 | mycontainers_ | 容器前缀 |
| csuffix | 字符串 | 容器后缀 | |
| objects | 字符串 | 对象选择表达式;例如 c(1), u(1,100) | |
| oprefix | 字符串 | myobjects_ | 对象前缀 |
| osuffix | 字符串 | 对象后缀 |
六、测试结果分析
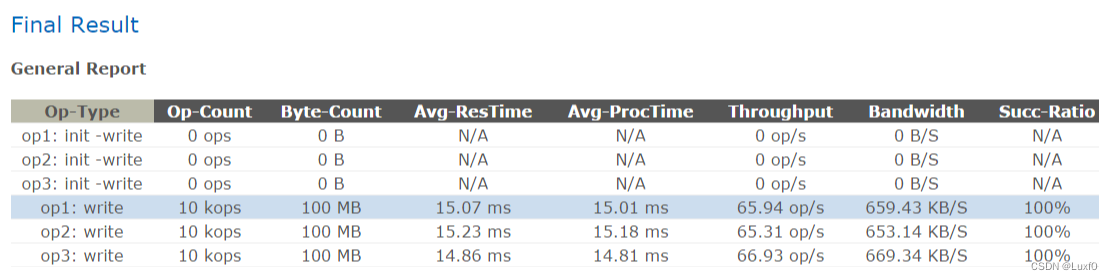
-
Op-Type
操作类型,常用操作类型有read、write、filewrite、delete,具体详见operation定义(type=“”) -
Op-Count
总操作数 -
Byte-Count
总字节数 -
Avg-ResTime
时延(平均响应时间,请求开始到请求完成的持续时间) -
Throughput(Operations/s)
IOPS(每秒完成的操作总数)
注:此处的值由总操作成功请求数除以总运行时间计算而来 -
Bandwidth
带宽(每秒传输的数据量)
注:此处数据量进制换算跟实际有所不同(1 MB = 1000 × 1000 bytes),故测试的性能值要高于实际值 -
Succ-Ratio
操作成功率(成功请求数/总请求数)
七、其他
1、测试总结
1、为实现最大性能,此处endpoint指向的为haproxy端口(后端使用均衡模式roundrobin,指向三个集群节点不同网关)
2、所有测试模型执行前需手动清理下缓存sudo sync && echo 3 | sudo tee /proc/sys/vm/drop_caches
3、workers一般设置为客户端CPU线程数总大小 grep 'processor' /proc/cpuinfo | sort -u | wc -l
4、objects对象数需为wokers并发数的整数倍,否则会因为线程数无法除尽,出现文件上传不全的情况
如并发数为32,上传对象10000个,实际上传对象为9984个
2、测试模型
| 序号 | 客户端个数 | 客户端driver个数 | 单driver并发数 | 对象数量 | 对象大小 | 读写类型 | 读结果标识 | 写结果标识 |
|---|---|---|---|---|---|---|---|---|
| 1. | 1 | 1 | 32 | 200000 | 4KB | 读写 | OR1 | OW1 |
| 2. | 3 | 1 | 32 | 600000 | 4KB | 读写 | OR2 | OW2 |
| 3. | 1 | 1 | 32 | 60000 | 4MB | 读写 | OR3 | OW3 |
| 4. | 3 | 1 | 32 | 180000 | 4MB | 读写 | OR4 | OW4 |
2.1、单客户端4K读写测试
单个客户端,单个客户端线程数32、100个桶、单桶2000个对象(共20w个对象)、单个对象大小4KB
<?xml version="1.0" encoding="UTF-8" ?>
<workload name="4k-rw-1driver" description="sample benchmark for s3">
<storage type="s3" config="accesskey={userak};secretkey={usersk};endpoint=http://{haproxy-ip}:{port};timeout=300000;max_connections=400" />
<workflow>
<workstage name="init">
<work type="init" workers="10" config="cprefix=test4kbucket;containers=r(1,100)" />
</workstage>
<workstage name="write test4k">
<work type="prepare" workers="32" driver="driver1" config="cprefix=test4kbucket;containers=r(1,100);objects=r(1,2000);sizes=c(4)KB" />
</workstage>
<workstage name="read test4k">
<work name="read" workers="32" driver="driver1" runtime="300">
<operation type="read" ratio="100" config="cprefix=test4kbucket;containers=u(1,100);objects=u(1,2000)" />
</work>
</workstage>
<workstage name="cleanup">
<work type="cleanup" workers="32" config="cprefix=test4kbucket;containers=r(1,100);objects=r(1,2000)" />
</workstage>
<workstage name="dispose">
<work type="dispose" workers="10" config="cprefix=test4kbucket;containers=r(1,100)" />
</workstage>
复制
</workflow>
</workload>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.2、多客户端4K读写测试
三个客户端,单个客户端线程数32、100个桶、单桶2000个对象(共60w个对象)、单个对象大小4KB
<?xml version="1.0" encoding="UTF-8" ?>
<workload name="4k-rw-3driver" description="sample benchmark for s3">
<storage type="s3" config="accesskey={userak};secretkey={usersk};proxyhost=;proxyport=;endpoint=http://{haproxy-ip}:{port};timeout=300000;max_connections=400" />
<workflow>
<workstage name="init">
<work type="init" workers="10" config="cprefix=test4kbucket;containers=r(1,300)" />
</workstage>
<workstage name="write test4k">
<work type="prepare" workers="32" driver="driver1" config="cprefix=test4kbucket;containers=r(1,100);objects=r(1,2000);sizes=c(4)KB" />
<work type="prepare" workers="32" driver="driver2" config="cprefix=test4kbucket;containers=r(101,200);objects=r(1,2000);sizes=c(4)KB" />
<work type="prepare" workers="32" driver="driver3" config="cprefix=test4kbucket;containers=r(201,300);objects=r(1,2000);sizes=c(4)KB" />
</workstage>
<workstage name="read test4k">
<work name="read" workers="32" driver="driver1" runtime="300">
<operation type="read" ratio="100" config="cprefix=test4kbucket;containers=u(1,100);objects=u(1,2000)" />
</work>
<work name="read" workers="32" driver="driver2" runtime="300">
<operation type="read" ratio="100" config="cprefix=test4kbucket;containers=u(101,200);objects=u(1,2000)" />
</work>
<work name="read" workers="32" driver="driver3" runtime="300">
<operation type="read" ratio="100" config="cprefix=test4kbucket;containers=u(201,300);objects=u(1,2000)" />
</work>
</workstage>
<workstage name="cleanup">
<work type="cleanup" workers="32" config="cprefix=test4kbucket;containers=r(1,300);objects=r(1,2000)" />
</workstage>
<workstage name="dispose">
<work type="dispose" workers="10" config="cprefix=test4kbucket;containers=r(1,300)" />
</workstage>
复制
</workflow>
</workload>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
2.3、单客户端4M读写测试
一个客户端,单个客户端线程数32、100个桶、单桶600个对象(共6w个对象)、单个对象大小4MB
<?xml version="1.0" encoding="UTF-8" ?>
<workload name="4m-rw-1driver" description="sample benchmark for s3">
<storage type="s3" config="accesskey={userak};secretkey={usersk};proxyhost=;proxyport=;endpoint=http://{haproxy-ip}:{port};timeout=300000;max_connections=400" />
<workflow>
<workstage name="init">
<work type="init" workers="10" config="cprefix=test4mbucket;containers=r(1,100)" />
</workstage>
<workstage name="write test4m">
<work type="prepare" workers="32" driver="driver1" config="cprefix=test4mbucket;containers=r(1,100);objects=r(1,600);sizes=c(4096)KB" />
</workstage>
<workstage name="read test4m">
<work name="read" workers="32" driver="driver1" runtime="300">
<operation type="read" ratio="100" config="cprefix=test4mbucket;containers=u(1,100);objects=u(1,600)" />
</work>
</workstage>
<workstage name="cleanup">
<work type="cleanup" workers="32" config="cprefix=test4mbucket;containers=r(1,100);objects=r(1,600)" />
</workstage>
<workstage name="dispose">
<work type="dispose" workers="10" config="cprefix=test4mbucket;containers=r(1,100)" />
</workstage>
复制
</workflow>
</workload>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.4、多客户端4M读写测试
三个客户端,单个客户端线程数32、100个桶、单桶600个对象(共18w个对象)、单个对象大小4MB
<?xml version="1.0" encoding="UTF-8" ?>
<workload name="4m-rw-3driver" description="sample benchmark for s3">
<storage type="s3" config="accesskey={userak};secretkey={usersk};proxyhost=;proxyport=;endpoint=http://{haproxy-ip}:{port};timeout=300000;max_connections=400" />
<workflow>
<workstage name="init">
<work type="init" workers="10" config="cprefix=test4mbucket;containers=r(1,300)" />
</workstage>
<workstage name="write test4m">
<work type="prepare" workers="32" driver="driver1" config="cprefix=test4mbucket;containers=r(1,100);objects=r(1,600);sizes=c(4096)KB" />
<work type="prepare" workers="32" driver="driver2" config="cprefix=test4mbucket;containers=r(101,200);objects=r(1,600);sizes=c(4096)KB" />
<work type="prepare" workers="32" driver="driver3" config="cprefix=test4mbucket;containers=r(201,300);objects=r(1,600);sizes=c(4096)KB" />
</workstage>
<workstage name="read test4m">
<work name="read" workers="32" driver="driver1" runtime="300">
<operation type="read" ratio="100" config="cprefix=test4mbucket;containers=u(1,100);objects=u(1,600)" />
</work>
<work name="read" workers="32" driver="driver2" runtime="300">
<operation type="read" ratio="100" config="cprefix=test4mbucket;containers=u(101,200);objects=u(1,600)" />
</work>
<work name="read" workers="32" driver="driver3" runtime="300">
<operation type="read" ratio="100" config="cprefix=test4mbucket;containers=u(201,300);objects=u(1,600)" />
</work>
</workstage>
<workstage name="cleanup">
<work type="cleanup" workers="32" config="cprefix=test4mbucket;containers=r(1,300);objects=r(1,600)" />
</workstage>
<workstage name="dispose">
<work type="dispose" workers="10" config="cprefix=test4mbucket;containers=r(1,300)" />
</workstage>
复制
</workflow>
</workload>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
3、Q&A
- cosbench高并发时,会出现上传、删除文件不完全的情况,若读取未上传完全的数据,则会出现
Terminate错误
如读取模型测试中断,则使用以下命令查看,检查各个bucket对象个数与测试模型预定数据规模一致
radosgw-admin bucket stats --bucket={bucket-name} | grep num_objects
- 1
注:一般测试读模型时,需要预填准备测试数据,此时上传对象需要使用
s(min,max)表达式顺序执行,从而保证读取的对象数据完全
- 如测试过程中出现
terminated错误导致测试中断,可查看controller节点的日志打印(/root/0.4.2.c4/log/system.log),查看具体错误信息,而后根据错误打印进行配置文件修改,重新提交任务
如
[root@node40 0.4.2.c4]# cat /root/0.4.2.c4/log/system.log
2020-10-29 13:34:17,010 [INFO] [StageRunner] - successfully booted all tasks in stage s2-4K-write
2020-10-29 13:34:17,023 [ERROR] [AbstractCommandTasklet] - driver report error: HTTP 400 - illegal uniform distribution pattern: u(0,100002)
2020-10-29 13:34:17,031 [ERROR] [AbstractCommandTasklet] - driver report error: HTTP 400 - illegal uniform distribution pattern: u(0,100002)
2020-10-29 13:34:17,031 [ERROR] [AbstractCommandTasklet] - driver report error: HTTP 400 - illegal uniform distribution pattern: u(0,100002)
2020-10-29 13:34:17,031 [ERROR] [StageRunner] - detected tasks [t1, t2, t3] have encountered errors
- 1
- 2
- 3
- 4
- 5
- 6
八、使用建议
注:此处引用文章
**COSBench测Ceph对象存储:那些网上找不到的细节**
1、cosbench部署建议
- 根据实际情况决定客户端数量,以能压满带宽为准;
- 运行COSBench的节点需要万兆网或更大带宽。为测试出性能瓶颈,客户端出口应大于或等于集群入口;
- 运行COSBench的节点为专用集群外测试节点或至少是业务网与存储网分离的纯OSD节点(没有其它任何服务);
2、测试用例设计建议
- 进行预测试,对各规模用例在集群中的表现进行预估,为正式测试用例和压力测试用例的设计与选取作参考;
- 并发数的选取,应以能够执行完成为准。其标准是,大规模文件数量的上传测试能够上传完全;
- 文件大小的选取,如无特殊要求,下限为分片后大于磁盘条带宽度,上限为大于rgw分片大小一倍,并应考虑横向对比需要;
- 文件数的选取,应以用例执行时间为准,以单个用例执行时间在30分钟至90分钟为佳。选取标准参考预测试的结果;
- 调优用例设计应选取低并发用例,不能触及带宽与磁盘I/O等物理瓶颈。
- 一组同时测写读删时Workload各使用一个桶进行操作,分离任务;
3、用例执行建议
- 执行前务必确认桶存在;
- 对于所有测试用例,建议先依次执行全部写用例,清缓存后再依次执行全部读用例,再依次删除;
- 将大规模用例拆分成多个相同的小用例,确保单个桶内的对象不会太多,上限可定为1千万;
- 写完成后,务必使用
radosgw-admin bucket stats –bucket={bucket-name}查看桶内对象数是否达到指定用例规模; - 读之前,应手动清除内存缓存;
- 用例执行过程中,应不时监看用例执行情况,若发现性能表现异常,应及时进行调整并重新提交执行测试用例;
- 删除完成后,务必查看桶内对象数,以确认删除干净;
4、结果分析建议
- 确认结果的合理性:执行时间过短不可用(数据不准),数据异常不可用(计算错误),运行时间不成比例不可用(说明有性能显著升降),上传不完全不可用(导致结果异常);
- 带宽需要手动计算,提取COSBench中的原始网速数据(以字节为单位)进行手工换算即可;
- 在混合操作测试中,操作数不会严格按照比例分布,但不影响性能结果;
</article>复制